基于隨機譯碼算法的全并行架構*
2016-11-30 01:02:44云飛龍朱宏鵬
通信技術 2016年7期
云飛龍,肖 銀,張 迅,朱宏鵬,呂 晶
(1.中國人民解放軍理工大學, 江蘇 南京 210001;2.中國人民解放軍75707部隊,廣西 南寧 530000)
基于隨機譯碼算法的全并行架構*
云飛龍1,肖 銀2,張 迅2,朱宏鵬1,呂 晶1
(1.中國人民解放軍理工大學, 江蘇 南京 210001;2.中國人民解放軍75707部隊,廣西 南寧 530000)
隨機譯碼算法因實現電路簡單,被廣泛應用于LDPC碼全并行譯碼架構。介紹幾種隨機譯碼架構,簡化基于MTFM(Majority-based Tracking Forecast Memories)的隨機譯碼架構,將MTFM架構中的加法器改為簡單的與門電路,進一步降低了資源消耗。同時,針對CCSDS標準(8176,7154)LDPC碼進行性能仿真分析,表明基于MTFM的隨機譯碼算法與最小和譯碼算法相比,只有0.2 dB的損失。此外,對改進前后的MTFM架構進行資源消耗比較,結果顯示每個變量節點改進后比改進前資源相比少了一個slice,且當碼長很長時,改進方案的資源消耗大幅降低。
隨機譯碼;全并行;簡化MTFM;LDPC
0 引 言
LDPC(Low-Density Parity-Check Code)是20世紀60年代初期由Gallager博士提出的[1]。由于優越的譯碼性能、可并行譯碼以及相對其他碼字較低的譯碼復雜度等特點,LDPC已經成為大部分通信系統的首選編碼方案,如CCSDS、DVB-S2、GPS和WiMAX等。
LDPC碼譯碼架構上共有3種,全串行、部分并行以及全并行譯碼架構。其中,全并行譯碼架構發揮了LDPC碼全并行譯碼的潛力。然而,由于全并行帶來的資源消耗巨大,尤其碼長較長時,其資源消耗會急劇增加,因此大部分譯碼架構都會避開全并行架構。鑒于此,本文引進隨機譯碼算法,同時介紹了幾種譯碼架構[2-4]。與傳統的基于最小和譯碼算法[5]的架構相比,本文的隨機譯碼架構能大幅度降低資源。其中,針對基于MTFM的全并行架構進行簡化,將MTFM架構中的n輸入加法器簡化為n輸入與門電路。結果顯示,一個變量節點減少了一個slice資源。而當LDPC碼長為幾千甚至幾萬時,簡化后的架構資源消耗將得到大幅度降低。
1 隨機計算概念及其譯碼算法
1.1 隨機計算概念
在隨機計算中,概率值用一串比特流表示,從而一些復雜的概率運算如采用隨機計算實現,只需簡單的門電路就可完成。同時,由于處理的單位是比特,因此大大降低了網絡布局布線復雜度,有效提高了硬件時鐘頻率[6]。
概率的比特流表示不是唯一的。例如,對于概率0.875=7/8,其比特流表示有以下幾種,如圖1所示。
比特流表示的意義是‘1’在比特流中出現的概率,而‘1’的位置不影響比特流的表示值。圖1中,比特流表示8個比特中有7個比特是1,即‘1’的概率是0.875。
隨機比特流一般用一個比較器產生,如圖2所示。用一個隨機數S與概率值P做比較,如果P>S,則輸出比特‘1’,否則輸出‘0’。若隨機數的序列夠長,則輸出的比特流中‘1’出現的概率就會近似接近概率P。
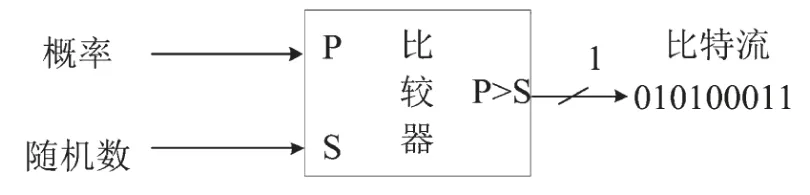
圖2 比特流產生
隨機計算的除法通過JK觸發器來實現。假設輸入的比特流概率為p1、p2,輸出的概率為p3,則JK觸發器如圖3所示。

圖3 JK觸發器
圖3所表示的除法公式為:
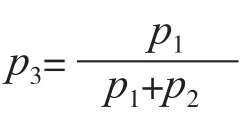
JK觸發器的真值表則如表1所示。

表1 JK觸發器真值表
1.2 隨機譯碼算法
LDPC碼譯碼算法基于因子圖,如圖4所示。

圖4 因子圖
圖4中,因子圖分為變量節點vi以及校驗節點ci,因此又被稱為二分圖。變量節點與校驗節點之間的連線稱為邊。譯碼過程就是變量節點與校驗節點之間信息傳遞的過程。隨機譯碼算法的特點是校驗節點與變量節點之間來回傳遞的信息是比特,因此大大降低了譯碼復雜度。
隨機譯碼算法主要包括譯碼信息的初始化、校驗節點運算、變量節點運算以及譯碼判決輸出[6]。具體過程如下:
(1)初始化:隨機譯碼算法的初始化,也就是產生所需要的隨機比特流,并將它傳遞給對應的變量節點。將譯碼概率值與隨機數比較,可得對應的隨機比特流,如圖2所示。在硬件設計中,通常隨機數用一個線性反饋移位寄存器產生,如圖5所示。
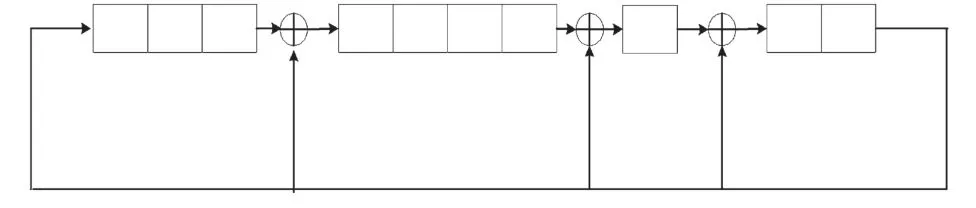
圖5 10比特的線性反饋移位寄存器
圖5給出了一個10比特的線性反饋移位寄存器,可產生210-1=1023個周期數。將接收到的譯碼概率值進行量化,并與寄存器中的值比較,每個時鐘周期輸出一個比特,最后可產生長度為1023的數據比特流。實驗表明,所有變量節點可采用同一個線性反饋移位寄存器,且初始化值的不同不影響最后的譯碼性能[7]。
(2)校驗節點運算:假設校驗節點的度dc為3,則校驗節點的運算電路如圖6所示。圖6中,a1、a2、a3為校驗節點的輸入比特信息,由對應的變量節點傳遞過來;b1、b2、b3為校驗節點的輸出比特信息,輸出給對應的變量節點。
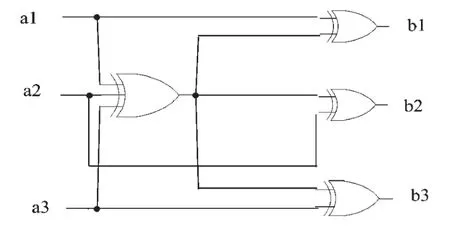
圖6 dc=3校驗節點電路
(3)變量節點運算:假設變量節點的度dv為2,則變量節點電路圖如圖7所示。
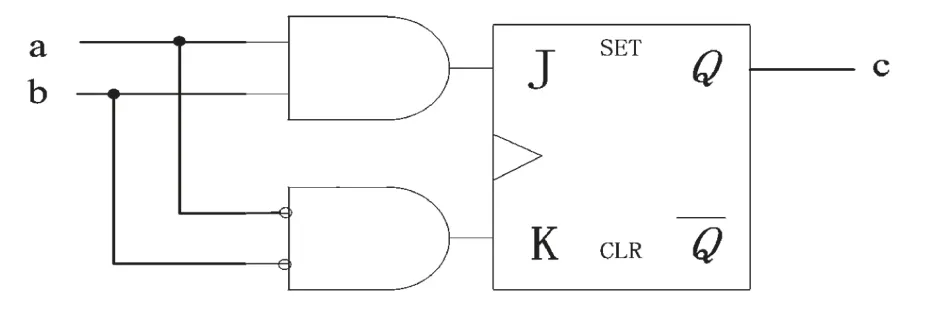
圖7 dv=2變量節點電路
圖7中,a、b為變量節點的輸入比特信息,由對應的校驗節點傳遞過來(在初始化過程中,由初始化模塊傳遞過來),c為變量節點的輸出比特信息,輸出給對應的校驗節點。于是,從表1可得到基于變量節點a、b、c的真值表,如表2所示。
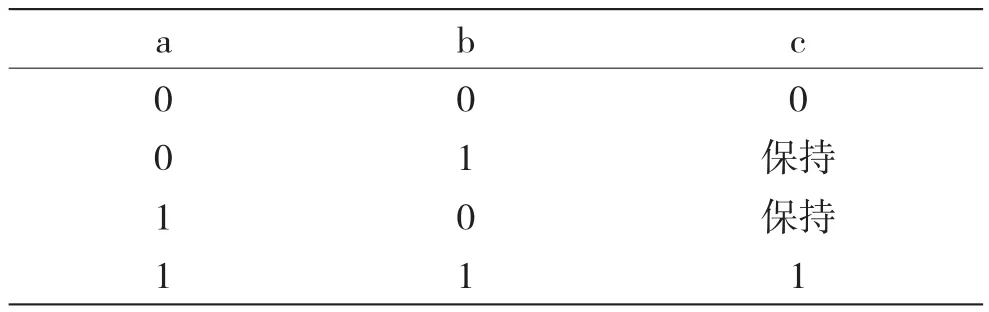
表2 變量節點真值表
(4)譯碼判決輸出:在隨機譯碼中,每個變量節點對應一個有符號位的加/減計數器,每個時鐘周期計數器接收到變量節點傳遞過來的比特信息,初始值一般設為0。如果接收到的變量節點值為‘1’,則計數器加1;如果接收到的為‘0’,則計數器減1。最后,判斷計數器的值,若大于0,則輸出譯碼信息為1,否則為0。
2 譯碼架構的改進
由表2可知,對變量節點的運算,當輸入節點值a、b不同時,輸出值c保持不變,等于上一時鐘周期的值,稱為鎖存狀態。只有當輸入值a、b都相等時,輸出值c才會等于輸入值a、b,稱為正常狀態。JK觸發器的這種特性對譯碼性能有很大影響。如果出現了誤碼,即輸入節點值不等,則JK觸發器就會處于保持狀態。而LDPC碼中存在環,環會使得這種狀態被保持,尤其當高信噪比時,此時概率要么趨近于1,要么趨近于0,從而使得產生的比特流為全1或全0。長時間處于這種狀態,導致比特間的信息交換緩慢,最后導致譯碼性能很差。因此,早期的隨機譯碼算法主要應用于無環的LDPC短碼,而LDPC長碼對應的環路較多,嚴重影響隨機譯碼算法的性能[8]。
針對這一問題,Tehrani引入邊存儲器(Edge Memories,EM)和內部存儲器(Internal Memories,IM),打亂比特流間的關系,有效改善了譯碼性能[2]。
隨后,Tehrani又提出了資源更少的預測追蹤存儲器架構TFM(Tracking Forecast Memories)[3],用來代替EM。由于TFM與EM一樣,都是以二分圖中的邊為基礎,資源消耗仍舊較多。于是人們又提出了一種基于大數邏輯的預測追蹤存儲器的架構(Majority-based Tracking Forecast Memories,MTFM)[4]。它以變量節點為基礎,變量節點的架構如圖8所示。

圖8 基于MTFM的變量節點結構
圖8中,度為4的變量節點分成2級處理,第一級由2個度為2的節點構成。這2個子節點處理完后,將信息傳遞給第二級度為2的子節點,度為2的節點可由IM架構實現。2級處理完后輸出比特si(t)和ri(t),其中si(t)=0表示第i條邊處于鎖存狀態,si(t)=1表示第i條邊處于正常狀態,而ri(t)為第i條邊子節點輸出的比特信息。4個si(t)比特和4個ri(t)比特送入MTFM進行處理,會發現一個變量節點處理單元中,只有一個MTFM,而不像EM和TFM架構,變量節點的每條邊都對應一個。因此,MTFM比較節省資源。MTFM具體架構如圖9所示。
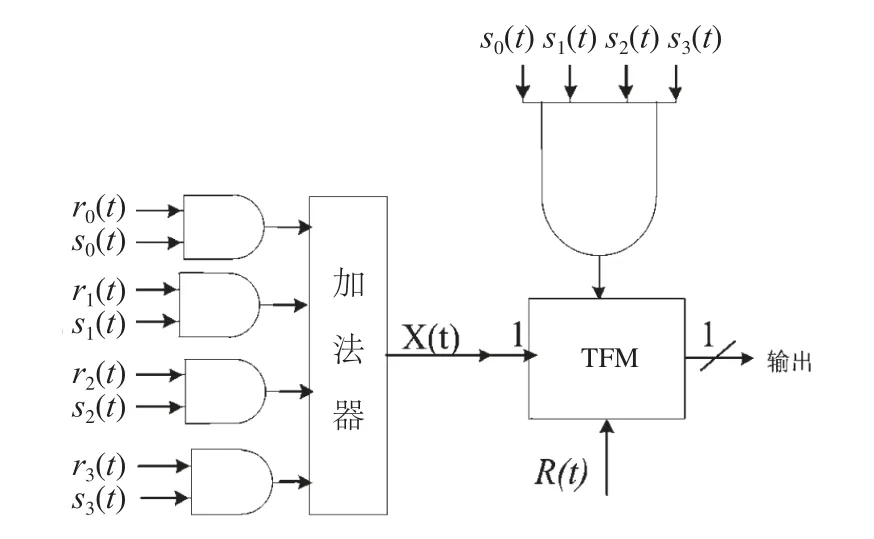
圖9 MTFM架構
圖9中,4個si(t)比特和4個ri(t)相加得X(t)值,取其量化后的最高位作為TFM的更新數據,而4個si(t)經過與門操作得到的值作為TFM更新使能信號。
對CCSDS標準的(8176,7154)碼字,其每個變量節點的度dv=4。通過觀察分析圖9發現,若將變量節點的度4量化,則量化后為”100”,即X(t)最高位為1的唯一條件是圖9中加法器的4個輸入數據都為1。又因只有當4個si(t)都為1時,更新數據值才有效,而此時4輸入加法器的4個輸入數據都為1的唯一條件是4個ri(t)都為1。因此可將圖9中的dv個與門和dv輸入加法器直接改為一個dv輸入的與門,見圖10,dv輸入的與門輸出為1的唯一條件是dv個ri(t)都為1,而簡化后的性能不變。

圖10 本文改進的MTFM架構
3 性能分析與資源比較
圖11給出了傳統的歸一化最小和譯碼算法(NMSA)、分層歸一化最小和譯碼算法(LNMSA)和基于MTFM的隨機譯碼算法的性能比較,仿真條件為AWGN信道和BPSK調制。其中,NMSA和LNMSA算法采用10次迭代,譯碼6比特量化,同時歸一化因子設為0.812 5,而MTFM采用改進后的圖10架構進行500次迭代,輸入的概率信息8比特量化,β為1/16,λ為5.22,β與λ可參見文獻[6]。從圖11可看出,MTFM與LNMSA算法相比,性能只有約0.2 dB的損失,而與NMSA算法相比,性能損失更少,不到0.1 dB。對于全并行譯碼架構,NMSA算法和MTFM可實現;就復雜度來說,MTFM的復雜度遠遠小于NMSA算法的復雜度。
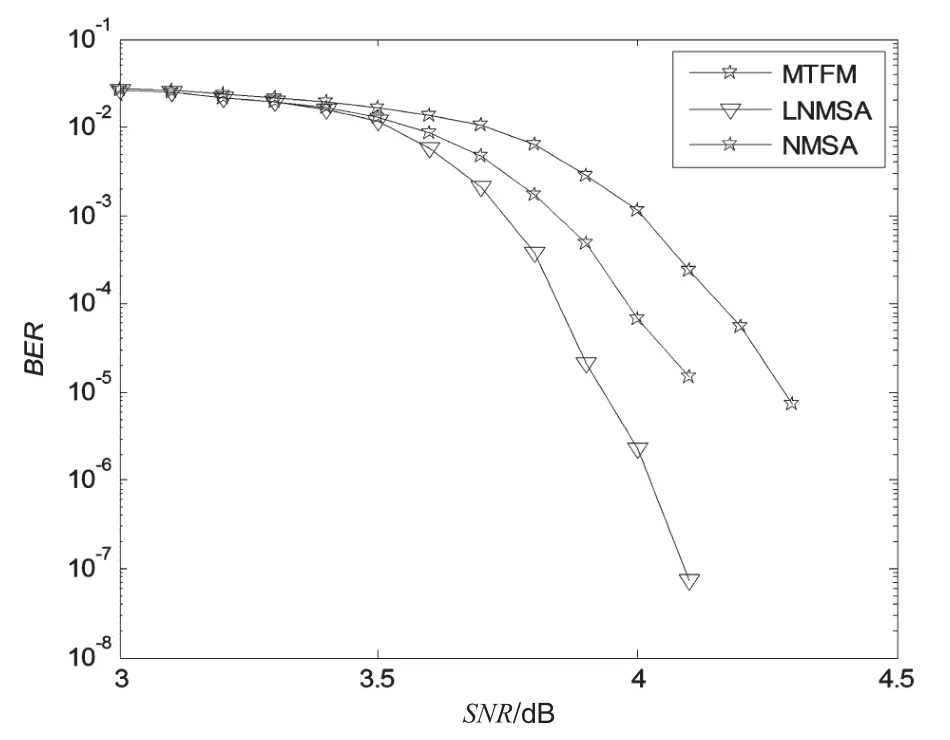
圖11 算法性能比較
圖10中,當X(t)=4時,最高位為1,即更新數據為1;當X(t)=0、1、2、3時,最高位為0,即更新數據為0。事實上,可能認為X(t)的取值長度不一樣,更新數據為1或0的概率也不一樣,從而影響最后的譯碼性能。為此對其進行性能仿真:第一種,當X(t)=4時,更新數據為1,當X(t)=0、1、2、3時,更新數據為0;第二種,當X(t)=3、4時,更新數據為1,當X(t)=0、1、2時,更新數據為0;第三種,當X(t)=2、3、4時,更新數據為1,當X(t)=0、1時,更新數據為0;第四種,當X(t)=1、2、3、4時,更新數據為1,當X(t)=0時,更新數據為0。圖12給出了對應的性能仿真圖,仿真條件在AWGN信道以及BPSK調制下,400次迭代,概率信息8比特量化,β為1/16,λ為5.22。從圖12可看出,4條性能曲線幾乎重合,因此針對CCSDS(8176,7154)的碼字而言,這4種情況對最后的譯碼性能影響不大。
下面進行進一步分析。因為所有si(t)都為1時,即輸入的dv個節點都處于正常狀態,X(t)值才有用。而此時所有輸入節點值都相等的概率很大,且隨著迭代次數的增加越來越大。因此,X(t)為最大值或者最小值的概率也越來越大。于是,在最大值與最小值之間的數對最后的譯碼性能影響不是很大。
事實上,變量節點度碼字只是一種特例,恰好滿足圖10的架構。而由上述分析可知,最大值與最小值間的數對譯碼性能影響不大,即度為其他值也可采用該架構。然而,如果度dv不同,對譯碼器設計來說,將會變得比較復雜,需不同的MTFM架構。因此,本文以變量節點度都為4的碼字矩陣為例。在文獻[4]中,作者同時指出,dv太小,會嚴重影響MTFM架構的性能。因此,MTFM的架構適用于度dv≥4的碼字矩陣。

圖12 不同X(t)取值長度的性能比較
通過上述分析,可以得出結論:當校驗矩陣的變量節點度dv≥4時,適用于MTFM架構,同樣也適用于本文改進后的MTFM架構。
表3給出了本文對MTFM架構改進后(圖10中四輸入與門)和改進前(圖9中四輸入加法器,4個二輸入與門)之間的資源消耗比較。

表3 改進前后的資源消耗比較
從表3可看出,改進后比改進前資源減少,而每一個變量節點都對應一個MTFM架構。因此,當變量節點較大時,改進后比改進前的資源將大大降低。
4 結 語
本文針對全并行譯碼架構資源消耗大的問題,介紹了一種隨機譯碼算法。算法實現只需簡單的邏輯運算,可大大降低資源消耗,且因處理單位是比特,能有效提高硬件時鐘頻率。同時,針對算法中變量節點的鎖存問題,引進幾種改進的譯碼架構,并基于MTFM的譯碼架構對其進行簡化,提出了一種資源消耗更低的譯碼架構。結果顯示,改進前后性能不變,而每個變量節點的資源消耗減少了一個slice,且LDPC碼長較大時,資源消耗將大幅降低。
[1] Gallager R G.Low-density Parity-check Codes[J]. IRE Trans. Inform. Theory,1962,8(01):21-28.
[2] Tehrani S S,Mannor S,Gross W J.Fully Parallel Stochastic LDPC Decoders[J].Signal Processi ng,2008,56(11):5692-5703.
[3] Tehrani S S,Naderi A,Kamendje G A,et al.Tracking Forecast Memories for Stochastic Decoding[J].Journal of Signal Processing Systems,2011,63(01):117-127.
[4] Tehrani S S,Naderi A,Kamendje G A,et al.Majoritybased Tracking Forecast Memories for Stochastic LDPC Decoding[J].IEEE Transactions on Signal Processing,2010,58(09):4883-4896.
[5] 姜明.低密度奇偶校驗碼譯碼算法及其應用研究[D].南京:東南大學,2006. JIANG Ming.Decoding Algorithm and Applied Research of Low-Density Parity-Check Code[D].Nanjing:Southeast University,2006.
[6] 朱行信.LDPC碼的隨機譯碼研究[D]西安:西安電子科技大學,2013. ZHU Xing-xin.The Research on Stochastic Decoding Algorithm based on LDPC[D].Xian:Xidian University,2013.
[7] Sarkis G,Gross W J.Reduced-latency Stochastic Decoding of LDPC Codes over GF(q)[C].Proc.2010 European Wireless Conf,2010:994-998.
[8] 任祥維,文紅,張頌.LDPC碼的全并行概率譯碼[J].通信技術,2011,44(08):42-44. REN Xiang-wei,WEN Hong,ZHANG Song. The All-parallel Probability Decoding Architecture based on LDPC[J].Communication Technology,2011,44(08):42-44.

云飛龍(1990—),男,碩士,主要研究方向為信道編碼;
肖 銀(1986—),男,學士,工程師,主要研究方向為通信技術;
張 迅(1987—),男,學士,工程師,主要研究方向為通信技術;
朱宏鵬(1982—),男,博士,講師,主要研究方向為信道編碼;
呂 晶(1965—),男,博士,教授,主要研究方向為衛星通信。
Full-Parallel Architecture based on Stochastic Decoding Algorithm
YUN Fei-long1, XIAO Yin2, ZHANG Xun2, ZHU Hong-peng1, LV Jing1
(1.PLA University of Science and Technology,Nanjing Jiangsu 210001,China; 2.Unit 75707 of PLA,Nanning Guangxi 530000, China)
LDPC is applied in full-parallel architecture for its simple implementation of stochastic decoding algorithm.This paper introduces several stochastic decoding architectures and simplifies stochastic decoding architecture based on MTFM(Majority-based Tracking Forecast Memories) which is proposed by the former .In the improved architecture,the adding circuit is replaced by the AND circuit,which reduces the resources effectively.Meanwhile, aiming at the simulation analysis based on the (8176,7154)LDPC in the CCSDS standard, the result suggests that the performance is 0.2 dB close to the Min-Sum algorithm. Besides, the resources of the architecture between the old and the new are compared,and the result suggests that the proposed architecture saves one slice than before.When the length of the LDPC code is long , the resources of the proposed architecture could be decreased significantly.
stochastic decoding algorithm;full-parallel;fimplifying MTFM;LDPC
National Natural Science Foundation of China(No.61401507)
?TN911.22
A
1002-0802(2016)-07-0821-05
10.3969/j.issn.1002-0802.2016.07.005
2016-03-13;
2016-06-09 Received date:2016-03-13;Revised date:2016-06-09
國家自然科學基金(No.61401507)
