淺談基于Hadoop平臺的大規模數據排序
2016-11-02 06:44:03呂書林
智能計算機與應用 2016年3期
關鍵詞:排序
門 威,呂書林
(河南廣播電視大學信息技術中心,鄭州 450000)
淺談基于Hadoop平臺的大規模數據排序
門 威,呂書林
(河南廣播電視大學信息技術中心,鄭州450000)
據IDC統計,2011年全球處理的數據量達到1.8 ZB,預計到2020年達到40 ZB。如何對海量數據進行高效分析和有效管理已成為大數據時代亟需解決的問題之一。商業數據、科學數據和網頁數據這3類海量數據的異構性(充滿著非結構化、半結構化和結構化數據)進一步增加了海量數據的處理難度。海量數據排序是海量數據處理的基本內容之一。Hadoop曾利用3 658個節點的集群在16.25小時內完成1PB數據的排序,獲得Daytona類GraySort和MinuteSort級別的冠軍。本文在設計層面上對Hadoop平臺上海量數據排序策略進行分析。
Hadoop平臺;海量數據排序;基準排序;云計算
1 基準排序
Jim Gray基準排序包含若干種基準,每個基準由多個規則構成,用于度量不同記錄排序時間。約定情況下,每條記錄長度為100字節,其中前10個字節是鍵,后面部分是值。MinuteSort用于比較一分鐘內執行排序的數據量大小,而GraySort用于比較100TB以上的大規模數據的排序速度(TBs/minute)。基準規則約定如下:
1)輸入數據和生成數據匹配且輸入/輸出數據都是未壓縮的;
2)任務開始前不允許在操作系統內緩存數據;
3)分發程序到集群上的時間和抽樣時間都要計入總時長;
4)如果輸出多個文件,就必須是有序的;
5)必須計算出每個Key/Value對的CRC32校驗值(128位),保證輸入輸出相對應;
6)輸出文件保存到磁盤上;
7)輸出數據不能改寫輸入數據。
根據Yahoo!測試結果顯示:利用Hadoop平臺下3 658個集群節點排列1PB數據用了975分鐘,具體如表1所示。
2 Hadoop排序策略
首先設計3個Hadoop應用程序用于數據排序:TeraGen、 TeraSort和TeraValidate。在此,給出概括分析論述如下。
1)TeraGen。用于生成數據,可根據待執行任務數目給所有map分配任務,每個map生成所分配的行數范圍內的數據。TeraGen利用1 800個map任務產生100億行數據并存儲到HDFS中,每個存儲塊設定為512MB;
2)TeraSort。是map/reduce程序,用于數據排序。首先利用N-1個有序的抽樣值為reduce任務分配待排序數據行數范圍。比如,把鍵值在[sample[i-1],sample[i])范圍內的數據分配給第i個任務,因此第i個任務任意輸出數據比第i+ 1個任務輸出數據小。這里采用兩層索引樹策略加速數據分配。由于數據不需要復制到多個節點,可以將副本數設成1。在本實驗中,相應分配1 800個map和reduce任務進行排序,為防止中間數據溢出,需要為任務的棧分布足夠的空間;
3)TeraValidate。用于驗證輸出數據,具體為每個輸出文件分配一個map任務(如圖1所示),用于檢查當前值是否全部大于等于前面的值,同時驗證第i個輸出文件中的最小值是否大于等于第i-1個文件中的最大值,否則拋出錯誤。
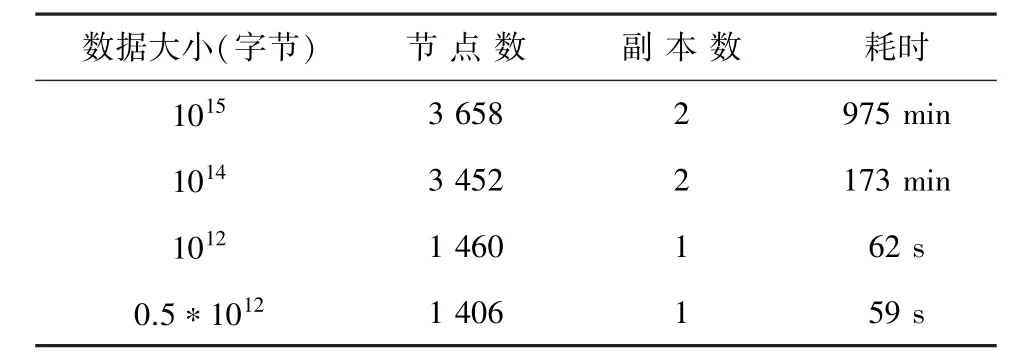
表1 排序時間和數據規模測驗表Tab.1 Test results of sorting time and data size
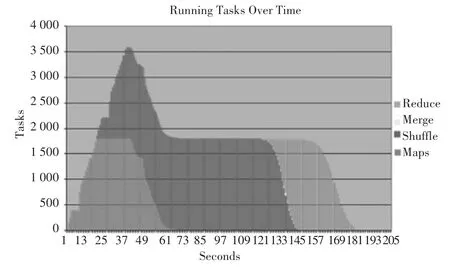
圖1 各個階段的任務量Fig.1 Number of tasks at each stage
該測試中,Hadoop集群配置如下:
1)910個節點;
2)節點配置:8 GB內存、1 GB以太網帶寬,4個2.0 GHz雙核處理器和4個SATA硬盤;
3)40節點/rack,rack到核心有8 GB帶寬的以太網;
4)Red Hat Enterprise Linux Server 5.1操作系統;
5)JDK1.6.0,整個排序使用209 s。
依托910個節點的集群,Hadoop在209 s(3.48 min)完成了對1TB數據的排序。
3 Hadoop在GraySort基準排序中的改進
為適應于GraySort基準排序時,研究員在原map/reduce程序的基礎上,對Hadoop進行適應性修改,將整個程序劃分成4個模塊:TeraGen、TeraSort、TeraSum和TeraValidate。各模塊實現功能如下:
1)TeraGen利用map/reduce方法生成數據;
2)TeraSort負責數據取樣,并使用map/reduce進行數據排序;
3)TeraSum負責計算每個Key/Value對的CRC32校驗和,用于檢查排序輸出的正確性;
4)TeraValidate負責驗證輸出數據是否有序,計算校驗和之總和。
本次基準排序測試運行在Yahoo!的Hammer集群上,集群配置如下:
1)3800個節點(大規模集群下需要冗余節點);
2)每個節點配備4個SATA硬盤、2.5 GHz的Xeons CPU、8 GB內存、1 GB以太網;
3)每個rack放置40個節點,rack到核心以太網帶寬8 GB;
4)采用Red HatEnterprise Linux Server Realease 5.1操作系統;
5)采用Sun Java JDK 1.6.0 05(32 or 64 bit)。
在Hadoop平臺方面的改進主要呈現在如下研究設計中:
1)重新構建Hadoopshuffle階段的reducer部分,提高了shuffle性能,增加了代碼的可維護性和易讀性;
2)重構后shuffle過程可以從某一個節點獲取多個map結果,減少了連接和傳輸開銷;
3)允許配置shuffle連接建立時超時時間。小規模排序時減少shuffle超時時間,減少任務延遲時間;
4)把TCP設置成無延遲,增加JobTracker和TaskTracker之間的頻率(配置成默認值的2倍,2秒/1 000節點),減少延遲時間;
5)增加用于檢測shuffle數據正確性的代碼塊,防止reduce任務的失敗;
6)在map輸出時采用LZO壓縮;
7)在shuffle階段,在內存聚集輸出map結果集的時候實現內存到內存的聚集,減少reduce運行工作量;
8)使用多線程進行抽樣并建立一個基于鍵平均值的分配器;
9)JobTracker為TaskTracker分配任務的默認策略時先來先服務(FCFS),這種貪心算法不能很好地適應分布式數據。TeraSort實現了一次性分配的全局調度策略;
10)刪除硬編碼等待循環,禁用Hadoop 0.20的自動安裝/清除任務功能以減少開始和結束的任務延遲;
11)日志級別設置成WARN以減少日志內容,提高系統性能。
實驗表明,Hadoop經過改進后可以在更短時間內處理更多的數據。小規模的數據需要更快的網絡和更短的延遲,因此使用集群的小部分節點進行計算;小規模計算過程短、集群規模小,節點故障率低,因此可以把計算輸出副本數量設置為1。對于大規模計算,節點故障率高,需將輸出副本數量設成2,且放置在不同節點上,保證某個節點出現故障時,數據不致丟失。
圖2顯示了不同時間點下的任務數量。maps只有一個階段,reduces有shuffle、merge和reduce3個階段.其中,shuffle用于從maps中轉移數據,reduce負責將聚集數據寫入到HDFS中。在圖1中,Hadoop每次心跳只能建立一個任務,所有任務的建立需要40 s,而現在每次心跳可以設置一個TaskTracker,明顯降低了任務開銷。與圖1比較發現,任務建立的速度明顯變快了。
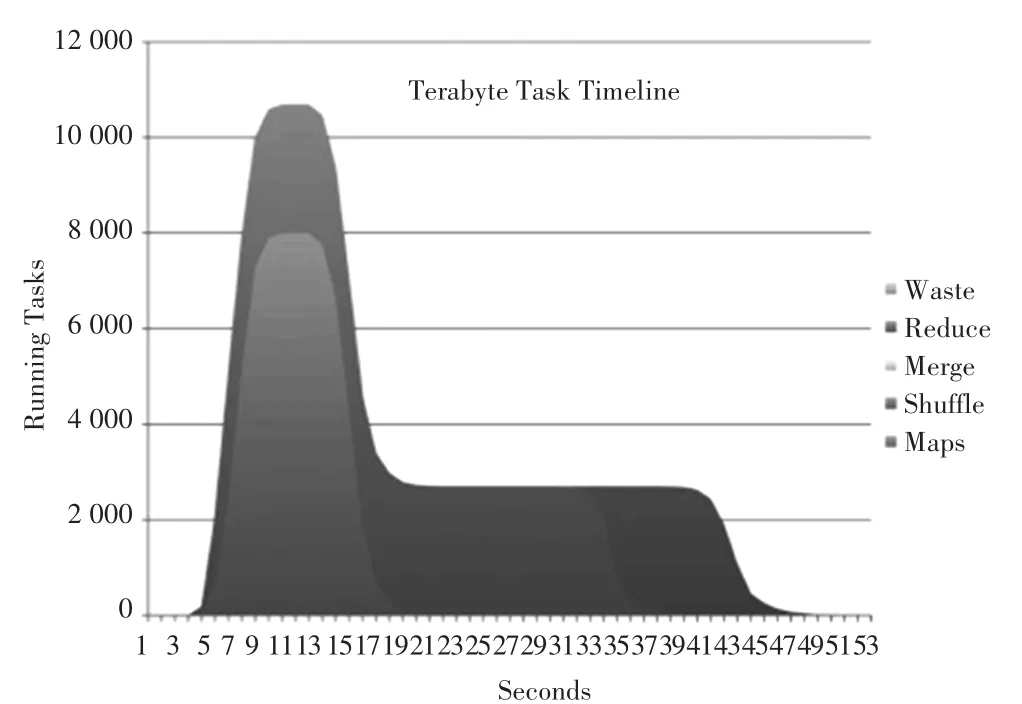
圖2 不同時間段的任務數(1TB數據量)Fig.2 Number of tasks in different time periods
值得注意的是,數據傳輸規模和次數對數據排序性能的影響很大。例如在PB級別的數據排序中,把每個map處理的數據設成15GB,而不是默認的128 MB。因此,為了增加吞吐量,拓延每個塊容量則至關重要。隨著Hadoop的不斷改進和優化,其在處理大規模數據排序方面的能力也將不斷完善與增強。
[1]陸嘉恒.Hadoop實戰[M].北京:機械工業出版社,2011.
[2]Tom White.Hadoop權威指南[M].2版.北京:清華大學出版社,2011.
[3]蔡斌,陳湘萍.Hadoop技術內幕[M].北京:機械工業出版社,2013.
Research on large scale data sorting based on Hadoop platform
MEN Wei,LV Shulin
(Information Technology Centre,Henan Radio and Television University,Zhengzhou 450000,China)
According to IDC statistics,in 2011 the amount of data processing in the world has reached 1.8ZB,and is expected to reach 40ZB in 2020.It is an urgent problem how to analyze and manage the massive data efficiently during the time of big data.The heterogeneity of these 3 kinds of massive data,such as business data,scientific data,and web data(full of unstructured,semi-structured and structured data),has further increased the difficulty of processing massive data.The sorting of massive data is one of the basic contents of massive data processing.Hadoop has used the cluster with 3 658 nodes in 16.25 hours to complete the sorting of 1PB data,and gotten the champion of the Daytona class GraySort and Minutesort level.This paper designs and analyzes the massive data scheduling strategy based on Hadoop platform.
Hadoop platform;the sorting of massive data;benchmark sorting;cloud computing
TP391
A
2095-2163(2016)03-0130-03
2016-05-03
門 威(1988-),男,碩士,助教,主要研究方向:軟件工程、云計算;呂書林(1987-),男,碩士,助教,主要研究方向:軟件工程。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
