基于字形與語音的音譯單元對齊方法
2016-10-12 08:29:09劉博佳徐金安陳鈺楓張玉潔
北京大學學報(自然科學版) 2016年1期
劉博佳 徐金安 陳鈺楓 張玉潔
?
基于字形與語音的音譯單元對齊方法
劉博佳 徐金安?陳鈺楓 張玉潔
北京交通大學計算與信息技術學院, 北京 100044; ?通信作者, E-mail: jaxu@bjtu.edu.cn
為了解決僅采用基于語音或基于字形的音譯方法造成的誤差過大問題, 以漢英音譯為主要研究對象, 運用統計與規則的理論思想, 提出融合基于語音和字形的音譯單元對齊方法, 設計了4個實驗, 與傳統方法進行對比。實驗結果顯示, 該方法能夠很好地提高機器音譯的準確性。
機器音譯; 對齊; N-gram 模型; 基于語音的音譯方法; 基于字形的音譯方法
在自然語言處理應用中, 機器音譯常被用于解決未登錄詞(out-of-vocabulary, OOV)的問題, 音譯結果的準確度直接影響到實際應用[1]。對于采用不同字母表和發音系統的不同語系之間(如英語與漢語, 英語與日語, 英語與阿拉伯語等), 機器音譯的難度往往很大。根據音譯的方向, 可以分為正向音譯(forward-transliteration)和反向音譯(backward-transliteration), 也可分為基于規則的方法和基于統計的方法。經過歷年的發展, 音譯的主流方法經歷了從基于規則到基于統計的發展過程[1]。根據音譯要素分類, 主要分為基于語音(phoneme-based)的音譯框架[2]和基于字形(grapheme-based)的音譯框架[3]。
基于規則的方法需要人工針對特定的語言對和音譯方向建立音譯規則[4]。Wan等[4]提出從英文到中文的基于規則的正向音譯方法, 該方法的思想被大量應用在規則音譯系統中。蔣龍等[5]指出, 規則的音譯框架采用跨語言的語音對應表, 這種方法的典型不足就是不能為表中的每一種對應提供一個概率值, 以便排序選擇最優翻譯。同時, 由于完備的規則系統需要完全通過手工撰寫語言規則, 需要很大的人力投入, 且獲取的規則不容易泛化。因此, 隨著NLP領域的發展, 機器音譯的方法逐漸向統計方法靠攏。
在基于統計方法的音譯中, 經常使用對齊模型 IBM model 1-3和HMM[3]。GIZA++①是一個融合了IBM model 1-5 和 HMM 模型的開源對齊工具。很多音譯方法將一個音譯人名對看做SMT中的一個句子對[6], 將每個音譯單元看做句子中的單詞, 并直接使用 GIZA++進行對齊, 取得較好的翻譯效果。
理論上, 基于語音的音譯框架能夠更好地提高準確率。Gao等[7]在2004年提出一種不同于噪聲信道模型的基于音素的音譯模型, 直接使用源語言到目標語言的生成概率計算音譯結果。但是, 由于一個音譯單元可能存在多種發音形式, 并且由于不同語系之間拼寫規則的不同, 從源語言的語音轉化成目標語言語音的步驟之間存在很大誤差。基于字形的音譯框架能夠避免從字形轉換到語音, 從語音再還原成字形的音譯單元的誤差, 擺脫對發音規則的依賴。李海舟研究小組[6,8–9]在英到中的音譯中使用直接對齊, 采用基于噪聲信道模型進行音譯, 取得較好的效果, 但是由于跳過了語音環節, 會不可避免地產生信息丟失。
綜合考慮以上方法的優缺點, 本文在構建基于統計機器音譯框架后, 引入音譯方法中的規則, 在使用基于字形的音譯框架的同時, 融合語音要素的音譯方法, 提出音譯單元的融合對齊方法。
1 流程描述
按本文方法構建的音譯系統的流程如圖1所示, 主要包括數據前處理、訓練音譯模型、解碼實驗及后處理4個部分。
首先, 在前處理階段, 數據來源分為訓練語料與測試語料。將雙語平行訓練語料分別按照基于字母的音節劃分規則和基于字形與字音并結合漢語與英語音節細劃分規則, 進行音譯單元的粗劃分與細劃分。將測試語料也依據給出的音節劃分規則進行相應的音譯單元的劃分操作。第2步, 將已劃分好音譯單元的訓練語料用提出的方法進行雙語音譯單元對的對齊。第3步, 用已對齊的平行語料訓練音譯模型。第4步, 對已劃分好音譯單元的源語言測試語料進行解碼實驗。第5步, 將解碼實驗之后輸出的目標語言音譯結果進行還原操作, 主要是進行音譯單元的還原與格式還原。同時, 倘若出現數據稀疏問題所造成的未登錄詞, 則引入維基百科的數據, 用于解決未登錄詞的翻譯問題, 有效地緩解數據稀疏問題。
本文主要論述音譯系統中前處理、訓練模型與解碼實驗的部分, 后處理部分只做簡單敘述。
2 數據前處理
前處理部分的重點在于對源語言語料與目標語言語料進行音譯單元的劃分。我們采取基于音節的音譯單元劃分規則, 將音譯單元的劃分過程分為粗劃分和細劃分兩個階段。
2.1 音譯單元粗劃分階段
英文名的音節劃分規則是按照文獻[5]給出的規則方法, 首先將英文26個字母進行分類, 分類情況如表1所示。完成對英文字母的分類后, 按照表2所示的音節劃分規則進行粗劃分。

表1 英文字母分類情況

表2 音譯單元粗劃分規則
2.2 音譯單元細劃分階段
根據以上粗劃分的結果, 我們發現劃分后的語料中存在一些不合理現象, 如音譯對“埃利歐/E LIOU”、“羅密歐/ROM MEO”、“阿布拉霍爾/A B RA HA L L”等, 通過日常的發音習慣可以清楚地分辨出, 此處出現的“歐”或單獨的“L”和“R”等均是用于輔助前一音節發音的作用, 此時將它們與前一音節合并為一個音節更符合發音規律。經統計, 此種情況不在少數。
因此, 我們依照數據統計結果改良發音規則, 對粗劃分的劃分結果進行細化, 如表3所示。例如, 對于給定英文名CHURTON, 它的音譯單元劃分過程如圖2所示。

表3 音譯單元細劃分規則
在以往的研究中, 對于音節的劃分方法常常局限在一個步驟上, 缺少相應的細化過程, 會對后面步驟的效果產生影響。本文采用兩個階段的劃分過程, 經實驗2和3 (見5.2節)論證, 能夠更好地提升音譯效果。
3 音譯模型
3.1 規則與統計相結合的自動對齊方法
音譯單元等級自動對齊的主要目的在于使漢英雙語名字各自的音譯單元相互對齊。例如上述例子“丘頓/CHUNTON”, 自動對齊的結果就是“丘/ CHUN”和“頓/TON”。在機器音譯中, 雙語音譯單元的對齊效果直接影響音譯結果的好壞, 同時由于在音譯過程中不存在音譯單元的調序問題, 通常情況下, 源語言音譯單元的對齊結果就是目標語言相同序號的音譯單元。
由于在上一步分詞過程中常存在源語言與目標語言劃分的音譯單元個數不同的情況, 一般的自動對齊常存在一對多與一對空的問題, 這樣的對齊結果往往不具有代表性, 對提升音譯效果起阻礙作用。因此, 自動對齊的難點在于選擇正確的音譯單元對, 盡量消除上述問題。我們采用基于規則的自動對齊算法, 具體步驟如下。
1)對于分詞后漢語與英語名字音譯單元個數相同的情況, 采取直接對齊的規則, 即將相同序號的音譯單元對齊, 形成音譯單元對, 例如: “歐文/ER WIN”。
2)對于分詞后漢語與英語名字音譯單元個數不相同的情況。
①首先將漢語名字分詞結果轉化成拼音的表示形式, 例如, “埃格德/AAGAARD”表示為“AI4 (1) GE2(2) DE2(3)/AA(1) GAA(2) R(3) D(4)”。
②根據音節首字母匹配規則, 以漢語的音譯單元首字母為準, 分別對應英語的音節首字母, 即用A, G, D這3個字母, 將英文名字“AAGAARD”重新劃分成“AA”、“GAAR”和“D”三部分。同時根據漢英字母發音的規律, 按照文獻[4]中的權重分配規則, 將劃分方式進一步細化。
③經過上述步驟, 將得到一個英語名字的一種或幾種的劃分方式<,>i, (=1,2, …,)。
⑤計算第種劃分方式中, 單個音譯單元對<c,e>的概率:
其中, |<c,e>|與|<c>|表示該音譯單元對在所有對齊方式中的統計與在所有名字中對應音譯單元的統計。
⑥計算第種劃分方式的概率:
比較種劃分方式的概率大小, 取概率值最大的劃分方式作為最終劃分方式。
3.2 N-gram音譯模型
對于漢英方向機器音譯, 假設中文名與英文名可以以字符序列的方式表示, 其中, 中文名表示為=123…x(表示中文名漢字數), 英文名表示為123…y(表示英文名字母數), 經過前處理與對齊的步驟后, 中、英人名對被分別表示為音譯單元的序列。
中文名字:=123…c;英文名字:123e。c和e(=1, 2, 3, …,=1, 2, 3, …)分別表示第或個中文或英文音譯單元, 即中英文音譯單元的數目相同。
由此, 中文音譯單元c與英文音譯單元e就形成對齊關系。與的對齊關系表示如下:
其中, 一個中文音譯單元中可能包含一個至多個漢字, 一個英文音譯單元中可能包含一個至多個英文字母。
根據上述,,的定義, 漢語到英語的音譯過程可以用下式推導:
其中,(,,)表示,,的聯合概率。
經過實驗對比, 我們采取N-gram的音譯模型, 其中=3, 式(3)重寫為
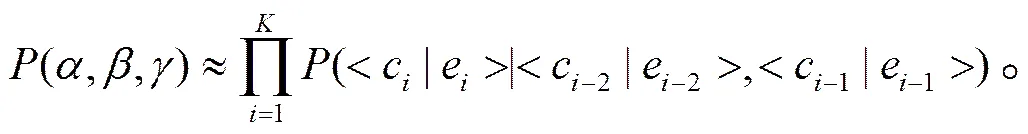
4 數據后處理
4.1 還原操作
經過解碼實驗, 輸出的最優結果是以音譯單元形式表示的目標語言人名(本文研究的音譯方向為漢到英, 因此輸出的目標語言為英語)的形式, 這并不是我們真正需要的音譯結果, 因此, 需要對該數據進行還原處理, 我們主要進行了兩個步驟的還原操作。
1)音譯單元還原操作。在音譯單元的劃分階段, 特別是在細劃分階段, 存在將鼻音{m, n}雙寫的情況, 所以在解碼實驗輸出結果的音譯單元中也存在這種情況。因此, 當出現“mm”或“nn”時, 若其前后是被元音包圍的情況, 將其改為“m”或“n”。
2)格式還原操作。在實際音譯單元劃分過程中, 音譯單元與音譯單元之間是以空格區分的。因此, 此處的格式還原操作為去除音譯單元之間的分隔符, 將其還原為一個單詞的形式。
4.2 數據稀疏處理
在音譯過程中不可避免地會產生數據稀疏問題, 本研究使用維基百科的數據來緩解這一問題。主要方法是, 將出現數據稀疏問題的源語言人名再次進行前處理操作, 同時從維基百科中抽取漢英人名對作為參考語料, 對其進行與之前的訓練語料相同的處理操作后, 利用式(1)和(2), 選取與問題人名中音譯單元對應的概率最大的目標語言音譯模型, 并將其作為新的解碼實驗的輸出結果, 再進行還原操作。
5 實驗分析
實驗使用的雙語語料來自I2R2009的音譯數據[6,8–9]。該數據包含31961條惟一的英文詞條及其對應的官方音譯結果, 各部分數據的使用量如表4所示。

表4 實驗數據
5.1 實驗評價
對于本次實驗結果的評價方法, 采用的是PRF系統評測模型, 其中(Precision)為準確率,(Recall)為召回率,值用于均衡準確率與召回率的誤差。本次實驗中對準確的定義是音譯結果與參考集中給定的參考結果完全一致。
5.2 實驗結果
為從整體上比較本文方法與只使用基于字形的音譯方法, 我們設計了以下4個實驗。
1)基線實驗。本文基線系統采用文獻[10]提出的方法, 以評價提出方法的性能。僅采用基于字形的音譯單元對齊方法, 對英文語料進行簡單的按音節的音譯單元劃分方法, 對中文語料采取按空格音譯劃分方法, 并用GIZA++工具進行音譯單元的對齊, 訓練音譯模型并輸出最好的一個結果, 將其實驗結果作為對比參照。
2)粗劃分實驗。將訓練語料只進行音譯單元的粗劃分, 并用GIZA++工具進行簡單的漢英音譯單元的對齊, 訓練我們的音譯模型, 并輸出最好的一個結果。
3)雙重劃分實驗。將訓練語料進行音譯單元的粗劃分與細劃分, 并使用GIZA++工具進行簡單的漢英音譯單元對齊, 訓練我們的音譯模型, 并輸出最好的一個結果。
4)對齊改進實驗。將訓練語料進行音譯單元的粗劃分與細劃分, 并使用我們提出的對齊改進方法處理對齊結果, 用該數據訓練我們的音譯模型, 并將Top1作為輸出結果。
與基線系統相比, 我們的系統得到較好的性能表現(表5), 分析如下。
1)單純的基于字形的音譯方法, 音譯效果不理想, 例如“斯滕尼/STENY”, 用該方法的輸出結果是“STENNY”, 而在其他兩個實驗中均能獲得正確結果。這種鼻音的單寫雙寫問題在現實應用中并不少見, 因此該方法不能直接用于機器音譯中。
2)引入新的劃分步驟之后, 音譯單元的劃分更加準確, 例如“斯托克邁/STOCKMAYER”, 在粗劃分時會被劃分成“斯托克邁/S TO C K MA YE R”, 英文音譯單元明顯劃分不夠準確, 在經過細劃分后, 成功地變為以“S TO CK MA YER”表示的更準確的形式。音譯系統的準確率、召回率與值均有提高, 足以證明該方法的可行性。
3)運用我們提出的對齊方法后,,和值都有明顯提升, 進一步驗證了字形與語音融合的音譯單元對齊方法既降低了語音轉換步驟中的誤差, 又減輕了僅采用基于字形的方法造成的信息對視問題。由此可以得出, 基于字形和語音的音譯單元對齊方法能夠提高音譯的效果。
6 總結及未來工作
本文提出一種新的融合的方法用于音譯單元的劃分與對齊過程。經過實驗驗證得知, 我們提出的方法能夠很好地提高音譯的準確率, 同時在解決音譯單元對齊的一對多與一對空問題方面表現較好。本研究有如下創新。
1)提出融合字形與語音的音譯單元對齊方法。在以往的研究成果中, 大部分的工作將關注點投放在字形或者語音音素一個縱向的方面。在本次研究中, 我們致力于將字形與語音的研究成果結合起來, 吸收兩者的優點, 彌補其中一方的缺點, 更好地提升音譯效果。
2)結合規則與統計音譯方法各自的優點, 提出規則與統計相結合的音譯單元劃分與自動對齊的方法, 將其運用在相應過程中, 并通過實驗驗證了該方法的可行性。
但是, 對于來源不同的英、漢人名, 存在不同的音譯習慣, 在我們的音譯過程中并沒有很好地解決這個問題。下一步的工作將引入更多的音譯單元劃分規則與對齊規則, 同時更好地利用維基百科的數據, 對來源不同的人名進行不同處理, 希望能夠進一步提高音譯的效果。
[1]李婷婷. 基于非參數貝葉斯學習的多語言人名音譯研究[D]. 哈爾濱: 哈爾濱工業大學, 2013
[2]Lin Weihao, Chen Hsin-Hsi. Backward machine transliteration by learning phonetic similarity // Pro-ceedings of the 6th Conference on Natural Language Learning. Taipei, 2002: 1–7
[3]Zaidan O. Z-MERT: a fully configurable open source tool for minimum error rate training of machine translation systems. Prague Bulletin of Mathematical Linguistics, 2009, 91: 79–88
[4]Wan S, Verspoor C M. Automatic English-Chinese name transliteration for development of multilingual resources // Processing of the 17th ICCL. 1998: 1352–1356
[5]蔣龍, 周明, 簡立峰. 利用音譯和網絡挖掘翻譯命名實體. 中文信息學報, 2007, 21(1): 23–29
[6]Li Haizhou, Kumaran A, Zhang Min, et al. Whitepaper of NEWS 2009 machine transliteration shared task // Proceedings of the 2009 Named Entities Workshop: Shared Task on Transliteration. Singapore: Association for Computational Linguistics, 2009: 19–26
[7]Gao Wei, Wong Kam-Fai, Lam Wai. Phoneme-based transliteration of foreign names for OOV problem // Proceedings of the 1st International Joint Conference on Natural Language Proceedings, Lecture Notes in Computer Science. Hainan, 2004: 110–119
[8]Li H, Zhang M, Su J. A joint source-channel model for machine transliteration // Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Barcelona, 2004: 1190–1194
[9]Zhang Min, Li Haizhou, Su Jian. Direct orthogra-phical mapping for machine transliteration // Proceed-ings of the 20th International Conference on Compu-tational Linguistics (COLING’04). Sydney, 2004: 716–722
[10]Wang Dandan, Yang Xiaohui, Xu Jin’an, et al. A hybrid transliteration model for Chinese/English named entities — BJTU-NLP Report for the 5th Named Entities Workshop. Beijin, 2015
Integrating of Grapheme-Based and Phoneme-Based Transliteration Unit Alignment Method
LIU Bojia, XU Jin’an?, CHEN Yufeng, ZHANG Yujie
School of Computer and Information, Beijing Jiaotong University, Beijing 100044; ? Corresponding author, E-mail: jaxu@bjtu.edu.cn
In order to solve the errors caused by only using the pheneme-based method or the grapheme-based method, applying the theory of statistics and rules, this paperproposes a new method for transliteration unit alignment which integrates the two main transliteration methods. Four experiments are designed to compare with the traditional methods. Experimental results show that proposed method outperforms other methods in terms of performance in machine transliteration.
machine transliteration; alignment; N-gram model; grapheme-based method; phoneme-based method
10.13209/j.0479-8023.2016.001
TP391
2015-06-18;
2015-08-16; 網絡出版日期: 2015-09-29
國家自然科學基金(61370130, 61473294)、中央高校基本科研業務費專項資金(2014RC040)和國家國際科技合作專項(2014DFA11350)資助
① http://www-i6.informatik.rwth-aachen.de/Colleagues/och/software/GIZA++.html
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
