基于可變點的數據展現子系統定制化開發方法
2016-09-26 07:19:51邢戎飛沈立煒趙文耘
計算機應用與軟件 2016年3期
邢戎飛 沈立煒 趙文耘
(復旦大學軟件學院 上海 201203) (上海市數據科學重點實驗室(復旦大學) 上海 200433)
?
基于可變點的數據展現子系統定制化開發方法
邢戎飛沈立煒趙文耘
(復旦大學軟件學院上海 201203) (上海市數據科學重點實驗室(復旦大學)上海 200433)
數據密集型系統已經廣泛應用于不同的行業與領域。在分層的數據密集型系統中,數據展現子系統是其重要的組成部分。使用軟件產品線的方法開發一組具有相似需求的數據展現子系統能夠有效提高開發人員的效率。然而,傳統的軟件產品線構造與定制方法并不能完全適用于該類子系統的可變性特性。針對這種情況,提出一套基于可變點的數據展現子系統定制化開發方法。該方法首先對軟件產品線特征元模型進行了擴展,并基于該元模型總結出一套面向需求文檔的特征建模過程和可變點實現技術方案。另外,該方法提出兩階段的定制過程支持子系統的定制化開發。最后,通過一個財務數據系統中的數據展現子系統實例驗證了方法的可行性與有效性。
軟件產品線數據展現子系統可變性
0 引 言
數據密集型系統是以數據為核心,對數據進行收集、分析、處理與展現的軟件應用系統[1]。當前,數據密集型系統已經廣泛應用于電信、金融、政府、制造等,積累了大規模數據的行業與領域。就數據密集型系統本身的結構而言,它一般具有系統規模大、多應用類型、多層次結構等特點。其中,多層次特性表示一個完整的數據密集型系統,可以被劃分為不同實現層次,并由不同的子系統按照一定的規則進行集成后得到。在組成數據密集型系統的一組子系統中,數據展現子系統主要負責以各種方式可視化地展現系統所處理的數據以及處理的結果,例如一種通行做法是以報表的形式展現數據。報表本身又可分為多種類型(由國家、行業規定的報表,或者企業自定義的報表),每種報表也可由不同的數據項組合而成。另外,圖表也是一種較為常見的數據展現形式。
通過分析不同的數據密集型系統,我們發現這些系統在數據展現方面具有類似的功能,例如類似的數據預處理以及數據集展現方式等。此外,還包括權限控制等這一類與數據處理、顯示無直接關聯,但影響子系統使用的功能[2,3]。另一方面,不同的應用對數據展現的需求也存在差異,例如商業報表系統主要以表格的形式展示數據,而地質信息展示平臺則需要根據地理坐標等數據在地圖上進行繪制。
為了降低重復開發數據展現子系統的工作量,保持數據展現效果的一致性,可以采用軟件產品線開發方法以定制化的方式來開發一個數據展現子系統。軟件產品線是針對特定領域的、具有一組相似特征,并從預先生產的核心資產開發而來的軟件產品的集合[4,5],其開發方法依賴于領域核心平臺,通過對領域內的可變性進行定制的方式開發出單個軟件產品。相比于傳統的面向領域的軟件產品線,集成在不同領域應用產品中的數據展現子系統可以視作為一種跨領域的特殊類型的軟件產品線。一方面,這種產品線同樣涉及需求的共性/可變性分析、可變點的定制方案設計等活動;另一方面,數據展現子系統中的可變性類型更為豐富,例如,商業報表系統在生成的報表范圍以及單個報表的內部結構等不同層次方面都存在可變性,同時針對這些可變點的定制也涉及更多的角色與時間點。因此,需要針對這些特性化的需求改造軟件產品線的分析與構建過程以及特定的數據展現子系統的定制化開發過程。
基于以上實際需求,本文旨在搭建一個面向數據展現子系統的軟件產品線,并歸納出基于可變點的數據展現子系統的定制化開發方法。首先,本文提出一種擴展可變性類型的軟件產品線特征模型元模型,該元模型從數據功能維度和數據展現維度對特征屬性進行了擴充,涵蓋更多語義。其次,基于該元模型總結出一套針對需求文檔的特征建模過程,并為識別出的不同類型的可變性提出了相應的可變點實現技術方案。再次,為了支持基于可變點的子系統實例的定制化開發,提出一套兩階段(開發者定制和用戶定制)的可變點定制過程。該過程用于確定在某個階段應被定制的可變點,并且保證可變點定制結果的一致性。最后,本文基于兩階段定制過程,設計并實現一個半自動化的可變點定制工具。另外,使用該工具配置了一個數據示例系統,驗證了可變點實現方案與定制過程的可行性。
1 相關工作
與本文相關的工作分為數據展現子系統的構造以及軟件產品線開發方法兩個方面。
文獻[2,3]分別介紹了基于Web的多維數據平臺和地質數據平臺的構造過程。開發者基于分模塊的原則針對單個數據展現系統分析其需求并設計其架構,設計出的模塊包括數據收集、數據存儲、數據訪問、數據處理和數據展現等。與之相比,本文的工作面向一組具有相似需求的數據展現子系統,采用軟件產品線的方法分析其需求的共性與可變性,并以可變點定制的方式支持快速的應用產品開發。
傳統的軟件產品線開發方法涉及從需求文檔到特征模型、再到軟件體系結構的映射過程。在軟件產品線開發中,特征建模是反映產品線中共性和可變性的一種手段,目的是將領域需求映射為用分層的樹狀結構表示的特征模型[6,7]。特征建模中一項重要的工作是可變性識別。可變性是指產品線所涵蓋的各個產品之間的差異性[8]。可變性一般會關聯到某個可變點上。可變點是可變性在產品線所覆蓋的軟件產品中的具體體現,而變體則是軟件產品中各個可變點上各種特定的可變性實例[9]。Kang提出的FORM方法對從特征模型到系統設計的過程進行了細化[10],將領域工程劃分為領域分析和領域結構設計[11]。在領域分析中,開發者需要從特征模型中抽取候選對象,并將這些候選模塊組織成對象模型。在領域體系結構設計中,將不同層次的軟件體系結構抽象為逐步細化的不同層次的模型:子系統模型、進程模型和模塊模型。此外,不同的特征從不同的層次對問題域進行了抽象,對于這些不同的特征,可以將其建模為不同的對象。文獻[11]中,提出了一系列對不同類型特征建模的原則,如將服務特征建模為服務狀態隱藏對象,將操作特征建模為用戶角色對象等。文獻[12]提出了一種改進過的面向特征的模型映射方法,該方法將軟件體系結構分為三種視圖,使不同類型的特征對應于不同的視圖,即軟件開發的不同階段。
對已經建模完成的特征模型進行實現也是軟件產品線中一個重要的主題。在文獻[13]中,對影響可變性實現的因素進行了闡述,對從可變性的識別到實現的整個過程進行了詳細的介紹,并提出了一些對于不同可變性的實現技術,如常量條件、變量條件等。在文獻[14]中,針對不同的特征約束形式推薦了模塊的設計方法。在代碼級別的實現方面,文獻[15,16]進行了較為詳細的闡述,包括聚合/代理、繼承、框架、反射等面向對象的實現方法,也有面向方面的實現方法。
2 可變性擴展及特征元模型
2.1數據展現子系統的特點分析
基于對數據密集型系統的實際開發經驗,軟件開發人員發現這些不同的數據密集系統存在結構上的共性,總結出分層、分模塊開發的原則。這樣能夠使不同的層次/模塊之間只通過接口和固定的數據格式與約束進行通信,降低模塊之間的耦合度。與此同時,這種分層、分模塊的開發方式也能夠提高系統的可維護性和可復用性。當用戶需求發生變動、某個模塊的結構或功能發生變化時,其他模塊并不會受到影響。
在數據展現子系統中,數據展現部分,或者稱為數據展現模塊的主要功能是將從數據存儲模塊或者數據處理模塊中的得到的數據集合以約定好的方式展現給使用者。此外,還可能存在一些輔助功能,如用戶權限設置,打印格式設置等。本文認為,數據展現模塊的輸入是一個符合預先定義好的格式的數據集,輸出是不同類型的數據顯示。
在開發的過程中,開發者需要和用戶合作對輸入數據集的格式進行定義。對于某個特定的數據展現子系統而言,會存在具有多個不同定義的數據集;而對于兩個或者一組數據展現子系統而言,會出現它們的數據集定義大部分相同,只存在少許差異的現象。圖1列出了兩個商業系統的數據集部分定義,該數據集以報表的形式出現。對比之后可以看出,兩個數據集定義大部分都相同,只是在“本月數”大項之下所細分的方式不同。當有多個用戶的數據集定義出現如示例1和示例2中所示的“大部分相同,少部分不同”的情況時,開發人員可以定制一個通用模版,將部分的數據集定義工作交由具體的用戶完成,減少開發人員的工作量。這在開發多個相似系統時對于人力成本的節約尤為突出。


圖1 數據集及模板示例
2.2特征元模型
本文的目的是使用產品線來進行面向不同領域,不同行業的數據展現子系統產品的開發。針對數據展現子系統的特點,我們對可變性類型和約束類型進行了不同維度上的擴展。加入擴展可變性類型和擴展約束類型的的特征元模型如圖2所示。在該元模型中,特征模型類FeatureModel代表著整個特征模型,其中包含若干對應單個特征的類Feature。一個Feature可以是復合的,即可以包含若干個其他Feature。當存在Feature間的聚集關系時,這個關系對應的是特征模型中特征之間的層次關系。和經典的特征模型相同,在本文提出的元模型中,層次關系分為Mandatory、Optional、Alternative與Or四種,由VariableType屬性進行描述。

圖2 擴展的特征模型元模型
首先,我們對特征的類型進行了擴展。在元模型中,特征類型由FeatureType屬性描述,分為數據集特征和非數據集特征。我們將描述數據集性質的特征稱為數據集特征。例如,對一張報表的表頭、細目等元素的展現等。相對地,描述系統中除數據集之外其他部分的特征稱為非數據集特征。不同領域的不同應用產品對數據集有不一樣的要求,根據前文所述數據集的特點,又可以將數據集特征細化為組級特征和組內特征。組級特征對應于數據集本身的定義,組級特征將數據集作為一個整體來分析,主要關注該數據集和數據展現子系統的關系;組內特征對應于數據集內部的定義,組內特征主要關注數據集內部的定義和不同數據集之間的相似關系。在元模型中,FeatureLayer屬性描述的是特征所處的層級,其取值范圍為NULL、GroupLevel和InGroupLevel。當特征不屬于數據集特征時,其取值為NULL;當特征屬于數據集特征時,則根據其描述的內容選擇取值為GroupLevel或者InGrouplevel。
其次,我們對特征的依賴關系進行了擴展。在元模型中,約束由Constraint關系描述,Target屬性指向和當前Feature存在約束關系的另一個Feature實體,其中的ConstraintType屬性取值在Require、Exclude、Influence和Sequence中選擇。在數據展現子系統產品線中,擴展增加了影響和順序關系。影響關系表示的是模型中一個特征變體的實現手段或者配置會對另一個特征變體的實現造成影響,但并沒有兩個變體必須同時綁定的限制。例如在數據展現子系統中,對數據集的合法性檢查公式會受到數據集自身定義的影響,那么可以稱“數據集定義”對“數據集合法性檢查”具有影響關系。順序關系表示的是兩個特征所對應的功能在軟件使用過程中固定的執行先后順序。例如,在每次進行數據集顯示之前必須對當前用戶的權限進行檢查,以確定該用戶可以查看哪些顯示的數據,那么稱“用戶權限檢查”和“數據集顯示”具有順序關系。
最后,我們對特征的綁定屬性進行了擴展。在元模型中,綁定屬性由BindOption關系描述,其中包含BindTime和BindRole屬性。BindTime屬性代表著該特征的綁定時間,其取值范圍為Compile-Time、Load-time和Run-Time。BindRole屬性代表著該特征的綁定者,其取值在Developer和User中選擇,分別代表著開發者綁定該特征和用戶綁定該特征。通常來講,產品的組裝及變體的綁定是根據各個可變點約定的綁定時間由開發者進行定制。在實際的應用場景中,會出現通過交互性機制使用戶決定可變點變體綁定的情況。對這類可變點的分析、建模及實現不能僅僅依靠可變點綁定時間屬性,因為這樣并不能識別該可變點是由用戶負責選擇變體還是由程序根據條件自行選擇。在本文中我們擴展增加了綁定角色屬性。
3 面向文檔的特征建模過程及特征實現設計
數據展現子系統產品線的開發流程總體遵循經典軟件產品線的開發流程,需要經過需求規約、明確數據展現子系統范圍、特征建模、特征實現等一系列活動。首先,通過分析功能描述文檔和數據集定義文檔,可以得到特征的規約描述及特征之間的層次關系。其次,通過對用例文檔進行分析,可以得到特征之間的約束關系。通過這兩步分析,開發者可以確定數據展現子系統的特征模型并將特征模型以特定方式進行存儲。最終可根據存儲的特征模型采取不同的策略提出特征的實現方案。
在具體的執行過程中,相比經典軟件產品線,數據展現子系統產品線對數據集特征和非數據集特征需要有不同的規約和實現策略,這是由數據集本身的性質所決定的。數據集特征有以下兩個特點:(1) 包含的特征數量大。在數據密集型系統中,需要被處理并顯示的數據集其類型和數量都可能會很龐大。(2) 數據集定義變化迅速。數據密集型系統的業務覆蓋面和業務邏輯通常會不斷的變化,導致在業務中使用的數據集集合持續的發生改變。
3.1特征規約
對于非數據集特征,其特征規約的來源為功能描述文檔。功能描述文檔主要包含對數據展現子系統所能完成的功能的列舉,對應于一組能夠滿足用戶需求的功能項。開發人員遵循一定的規則對特征進行規約,如將功能描述對應為功能特征,將功能或整個系統的約束描述對應為非功能特征等。隨后通過產品—特征矩陣方法確定特征之間的層次關系,以及每個特征的可變性類型,初步確定特征模型。
對于數據集特征,其特征規約的來源為數據集定義文檔。數據定義文檔不僅和需求文檔一樣描述了該數據集的名稱和在系統中表示的含義,而且定義了數據集內部的具體組織方式。對數據集特征的規約也要分為兩部分:數據集描述和內部結構定義。數據集介紹部分的規約可以參照非數據集特征的規約方法。對于數據集內部結構,可以使用XML進行定義。一個使用XML的數據集內部結構定義應如下所示。
…
…
…
我們使用
在對于數據展現子系統的分析中,曾經提到在實際場景中會出現需要對多個數據集抽象出一個模版,在不同用戶對系統的使用過程中各自進行定制的情況。在數據集定義中本文引入了抽象類型的概念,類似于面向對象技術中的抽象類,對于抽象部分可以通過不同的實現手段形成用戶需要的不同的數據集。如果一個
若要確定哪些塊、復合屬性、單個屬性屬于抽象類型,那么需要由開發人員對相似的數據集進行分析,并對其中數據集定義的重合部分進行提取,得到帶有抽象部分的數據集定義。本文把每個數據集看作一個特征,被提取出的數據集模版成為這些相似數據集的父特征,這些父特征覆蓋了多個產品。在產品的定制中,存在抽象部分的特征需要被其覆蓋的一組產品分別定制,即對組內特征進行的定制。而由于在定義中不存在抽象部分的數據集一般對應于單個產品,因此它們不需要被再次定制。
3.2特征約束確定
表示需求的特征之間的約束關系能夠從用例文檔中獲得。首先對于需求文檔中的每一個用例,要分析出該用例對應哪些特征以及特征的執行順序。其次,要對該用例所包含的特征進行分析,確定是否存在約束關系。開發者可以根據以下用例場景來識別約束關系的類型。
1) 如果某個特征A在執行中需要“用到”其他的特征B或者B的執行結果,即在用例流程中去掉B后,A不能正確運行,則認為特征A依賴特征B,記作require(A,B)。
2) 如果某個特征A和特征B同時出現在一個用例之中時,A和B的執行關系總是確定的,并且A總是在前或者B總是在前,則認為特征A和特征B具有順序關系,記作Sequence(A,B)或Sequence(B,A)。
3) 如果在用例中,特征A的變體或者參數選擇會對特征B的執行邏輯或順序產生影響,則認為特征A影響特征B,記作Influence(A,B)。
在對每一個用例進行分析后,我們可以得到特征—特征約束對,并對特征的Constraint屬性集進行賦值。此外,在該步驟中還可以確定Bind-Time和Bind-Role的值。通常在為用戶部署該子系統之前就需要確認的變體所在可變點的Bind-Role為Developer,用戶在得到該子系統之后才能決定的變體所在可變點的Bind-Role為User。在系統開始運行前就需要確定的變體所在可變點的Bind-Time一般為Compile-time,在系統啟動時才進行一次或者永久設置的變體所在可變點的Bind-time為Load-Time,在系統運行中需要用戶動態地進行設置變體所在可變點的Bind-Time為Run-time。
3.3特征模型存儲
軟件產品線是在不斷演化的,需要對這些可變點進行管理使之能適應未來可能的演化。同時,用戶的需求也會發生變化,這有可能造成所綁定變體的改變。本文中使用特征配置庫對特征進行管理。該配置庫可以存儲可變點的位置和對變體的選擇,并保證了系統本身的相對獨立。當變體綁定發生改變時,可以只對配置庫進行改變而不侵入代碼本身。
一般來說,特征配置庫要存儲以下四種內容:(1) 存儲特征模型,具體的定義如圖2中的元模型所示,包括特征的層次關系、特征的屬性以及特征之間的約束關系。(2) 數據展現子系統產品線所覆蓋的專業領域軟件產品,它體現為一個產品列表。(3) 存儲特征的范圍矩陣,即每個特征覆蓋的產品。(4) 特征實現方法,不同類型可變特征的存儲方式與內容各不相同,例如可通過配置文件、參數或者數據集定義的方式。一個較為完整的特征配置庫定義如下所示。
//具體定義見特征模型元模型定義
其中,
3.4特征實現
對特征的實現同樣要針對數據集特征和非數據集特征兩部分分別進行。對于非數據集特征,其實現方式可以借鑒文獻[15-17]中提出的原則,對不同類型的特征,如Mandatory、Optional、Or和Alternative可以使用不同的方法。例如,可以使用設計模式、繼承、參數化方法和面向方面編程等方法進行實現。
對數據集特征的實現指的是對組內特征的定制,即對帶有抽象塊、抽象復合屬性和抽象屬性的數據集模版的定制。通常來說對于這樣的組內特征的定制場景都是相對一致的,即改變數據集中部分內容的定義。對于這樣的場景可以使用配置文件進行實現,數據集特征可以通過對配置文件的修改完成對變體的綁定。一段典型的數據集特征實現代碼如下所示。每個數據集實例對應一個ConfigFile配置文件,當該實例初始化時,讀入數據集模版DataSetTemplate,并由用戶配置其中的抽象部分。初始化完畢之后,基于該數據集可執行填表、顯示等一系列操作。
Public Class DataSetTemplate{
Static ConfigFile template;
}
Public Class DataSet{
DataSet(){
ConfigFile AFile = DataSetTemplate.template;
AFile.ConfigAbstract();
//配置抽象部分
AFile.SaveAs(filename);
//存儲配置文件
}
}
Public Class Report{
CreateDataSet(){
DataSet D;
D.ReadConfigFile(filename)
D.Fill();
//填表
D.Show();
//顯示
}
}
4 兩階段可變點定制過程
本文提出了兩階段配置數據展現子系統的策略,即開發者配置和用戶配置,分別通過開發者配置工具和用戶配置工具完成。開發者配置工具主要完成的工作有兩項:(1) 對Bind-Role屬性值為Developer的特征進行配置。(2) 選擇用戶配置工具可以選擇的變體范圍。而用戶配置工具的主要工作就是從開發者配置工具選擇的變體范圍中進行選擇和配置。兩階段的可變點定制流程如圖3所示。

圖3 兩階段的定制流程
從兩個角度來明確特征的總體定制順序。一方面,對于綁定角色不同的特征存在定制順序。在產品線的每一次迭代過程中,開發者定制在前,用戶定制在后,開發者定制的結果是用戶定制的前提。另一方面,具有關聯的特征之間存在定制順序。對綁定角色的定制順序算法如算法4所示,該算法根據特征的綁定角色屬性對特征進行分類。首先,要獲得標注為開發者配置的特征列表DevConfigList,由開發者按照該特征列表進行配置。其次,需要獲得覆蓋了當前專業領域產品的特征列表UserConfigList,該列表根據特征配置庫中的特征范圍部分得到。最后用戶根據UserConfigList列表對相應特征進行定制。
For each Feature in Repository.Featuremodel
If Feature.Bind-Role = Developer
Add Feature to DevConfigList
Else If Feature.Bind-Role = User
Add Feature to UserConfigList
ConfigFeature(DevConfigList
For each Feature in UserConfigList
If Product not in FeatureScope.Feature.Product
Delete Feature from UserConfigList
ConfigFeature(UserConfigList
而對于已經確定的特征列表,如DevConfigList,UserConfigList的特征定制順序算法如算法5所示。在定制中,有以下幾個原則可以作為確定特征順序的參考。(1) 對于特征層次關系,定制的順序為先定制子特征,再定制父特征。(2) 對于特征依賴關系 require(A,B),定制的順序為先定制被依賴特征B,再定制特征A。(3) 對于特征順序關系A 和特征B之間的順序關系Sequence(A,B),按照其順序的先后關系對特征A、B進行定制。(4) 對于特征影響關系influence(A,B),按照先定制影響特征A,后定制被影響特征B的順序進行。
Set 0 to SeqMatrix
For each Feature in List
Set 1 to SeqMatrix(Feature, Father(Feature))
For each Constraint in Feature
If Constraint.ConstaintType is require or Sequence or influence
Set 1 to SeqMatrix(Feature, Constraint.target)
For each Feature in List
If Colomn(Feature) = 0
Set Feature to StartList
For each Feature in StartList
Config(Feature)
If SeqMatrix(Feature, NextFeature) = 1
Set NextFeature to StartList
Delete Feature from StartList
5 工具與實例
5.1工具實現
本文對數據展現子系統的定制需要經過開發者定制和用戶定制兩個階段,可變點定制工具也分為開發者定制工具和用戶定制工具兩部分來實現。開發者定制工具和用戶定制工具的設計結構如圖4所示。
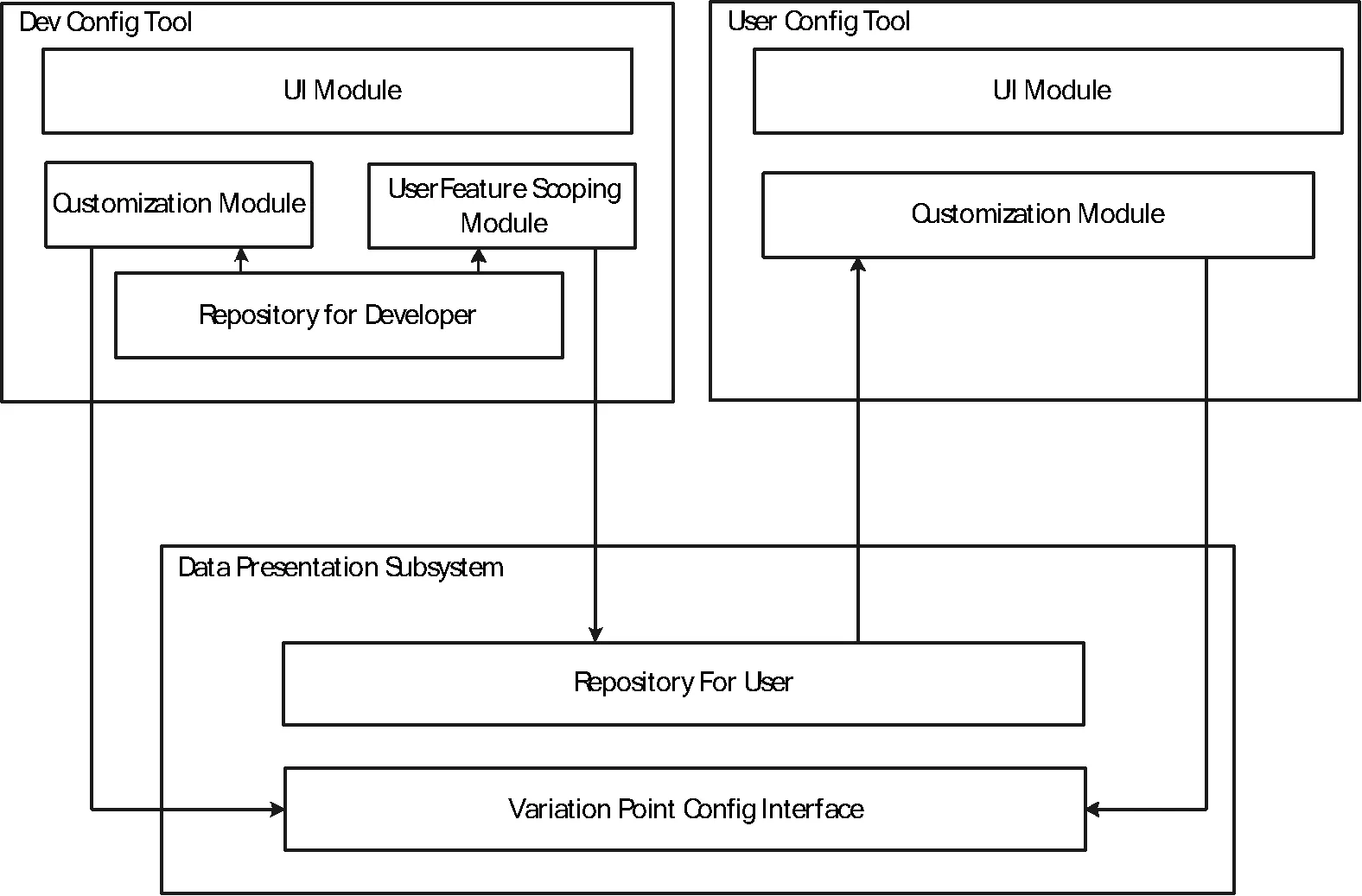
圖4 開發者定制工具和用戶定制工具的結構
在實際的定制流程中,數據展現子系統向定制工具提供一個定制接口,使定制工具可以對特征進行變體綁定。不同特征接口具有不同的實現方法,例如由開發者工具維護一個整體的特征庫,其中存放了覆蓋整個數據展現子系統產品線的特征定義。當需要進行某一個具體的數據展現子系統的定制時,首先由開發者工具在總體的特征庫中進行選擇,對Bind-Role屬性為Developer的特征進行定制,然后將選擇好的Bind-Role屬性為User的特征及其相關信息復制到特定的數據展現子系統中的特征庫,并把該未定制完成的子系統分發給用戶。用戶收到該子系統后,通過用戶配置工具讀取子系統中的配置庫信息,并根據工具提供的特征綁定順序依次進行定制。
5.2實例分析
商業報表系統是面向企業或事業單位的一個專業領域應用系統,其中存儲有大量以報表形式存在的數據集。同時,該系統具有數據展現的需求。本節以商業報表系統為示例進行系統定制,以驗證配置工具和配制方法的有效性。在進行定制之前,要先進行特征的建模和約束確定工作。對數據展現子系統的功能進行分類總結和分析建模后,生成的非數據集特征模型如圖5所示。由于篇幅原因,本文僅在圖6中展示數據集特征所對應的部分XML語句。

圖5 非數據集的特征模型

圖6 數據集特征的部分XML表示
對數據展現子系統的定制取決于存放在特征配置庫中的對數據集特征和非數據集特征的分析結果,由配置工具根據算法4和算法5中所述算法確定定制步驟,并引導開發者和用戶進行可變點配置工作。在開發者和用戶的兩階段定制完成后,我們對生成的數據展現子系統進行測試,其功能符合預期。
6 結 語
數據展現是普遍存在于數據密集型系統中的一類功能,其中包含了一些類似的對數據集的操作。基于此前提本文將數據展現模塊視為集成在其他數據密集型系統之中的、相對獨立的子系統,這些子系統具有功能上的相似性。基于這些系統間的共性與可變性,本文采用軟件產品線方法搭建可復用平臺并通過定制化的手段開發單個數據展現子系統。為了應對數據展現子系統需求的特性,本文對特征模型元模型進行了擴展,提出了對應的實現手段和兩階段的數據展現子系統定制方法。最后,通過一個定制的實例驗證了本文所提出方法的可行性。目前本文的工作涉及的需求場景較為簡單,而且在實際情況中數據展現子系統一般不會獨立存在,而是被集成在特定專業領域的數據密集型系統之中。在未來的工作中,不僅要對更復雜的需求場景進行深入分析,擴充相應的實現方案,而且需要考慮開發完成的子系統與其他系統的集成問題。
[1] Wang L Z,Tao J,Ranjan R,et al.G-Hadoop:MapReduce distributed data centers for data-intensive computing[J].Future generation computer systems-the international journal of grid computing and escience,2013,29(3):739-750.
[2] 曹劍.基于Web的多維數據工具的設計與實現[D].華中科技大學,2009.
[3] 林關煜.地質數據的展現,傳輸及格式轉換的相關研究[D].中國地質大學,2013.
[4] Clements P,Northrop L.Software product lines: practices and patterns[M].Reading:Addison-Wesley,2002.
[5] Nyholm C.Product line development-an overview[R].Extended report for “Building reliable component-based systems”,I. Crnkovic, M. Larsson (eds), Artech House,2002.
[6] Reid Turner C,Fuggetta A,Lavazza L,et al.A conceptual basis for feature engineering[J].Journal of Systems and Software,1999,49(1):3-15.
[7] Chen K,Zhang W,Zhao H,et al.An approach to constructing feature models based on requirements clustering[C]//Requirements Engineering,2005.Proceedings.13th IEEE International Conference on.IEEE,2005:31-40.
[8] Jaring M,Bosch J.Representing variability in software product lines:A case study[M]//Software product lines,Springer Berlin Heidelberg,2002:15-36.
[9] Van der linden F,Pohl K.Software product line engineering:foundations,principles,and techniques[M].Springer-Verlag Berlin and Heidelberg GmbH & Co.K,2005.
[10] Lee K,Kang K C,Chae W,et al.Feature-based approach to object-oriented engineering of applications for reuse[J].Software-Practice and Experience,2000,30(9):1025-1046.
[11] Kang K C,Kim S,Lee J,et al.FORM:A feature-oriented reuse method with domain-specific reference architectures[J].Annals of Software Engineering,1998,5(1):143-168.
[12] 劉東云,梅宏.從需求到軟件體系結構:一種面向特征的映射方法[J].北京大學學報:自然科學版,2004,40(3):372-378.
[13] Lee K,Kang K C.Feature dependency analysis for product line component design[M]//Software reuse: methods, techniques, and tools. Springer Berlin Heidelberg,2004:69-85.
[14] Svahnberg M,Van Gurp J,Bosch J.A taxonomy of variability realization techniques[J].Software:Practice and Experience,2005,35(8):705-754.
[15] Gacek C,Anastasopoules M.Implementing product line variabilities[J].ACM SIGSOFT Software Engineering Notes,ACM,2001,26(3):109-117.
[16] 祝家意,彭鑫,趙文耘.基于OOP和AOP的軟件產品線實現技術研究[J].計算機科學,2009,36(7):120-123.
A CUSTOMISED DEVELOPMENT METHOD FOR DATA PRESENTATION SUBSYSTEM BASED ON VARIATIONS
Xing RongfeiShen LiweiZhao Wenyun
(SchoolofSoftware,FudanUniversity,Shanghai201203,China) (ShanghaiKeyLaboratoryofDataScience,FudanUniversity,Shanghai200433,China)
Data-intensive systems have been widely used in different industries and sectors. Data presentation subsystem is an important constituent element of the layered data-intensive system. To develop a group of data presentation subsystems with similar requirements based on the software product line method can effectively helps to increase the efficiency of developers. However, traditional construction and customisation methods for software product line are not fully applicable to such data presentation subsystem due to its variation characteristics. In view of this, we propose a variations-based customised development method for data presentation subsystems. First, the method extends the feature meta-model of software product line. Based on it, the method summarises a set of required documents-oriented feature modelling processes and technical solutions for variations implementation. Besides, the method proposes a two-step customisation process to support the customised development of subsystems. In end of the paper, we verify the feasibility and effectiveness of the method through an example of data presentation subsystem in a financial data system.
Software product lineData presentation subsystemVariability
2014-11-28。邢戎飛,碩士生,主研領域:軟件工程。沈立煒,講師。趙文耘,教授。
TP3
A
10.3969/j.issn.1000-386x.2016.03.007
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
山東青年(2016年1期)2016-02-28 14:25:25
創業家(2015年5期)2015-02-27 07:53:25
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2014年3期)2014-01-21 02:30:44
