醫保欺詐行為的主動發現
2016-08-06 09:40:21唐璟宜孫有坤周海林
合作經濟與科技 2016年16期
□文/唐璟宜 孫有坤 周海林
(安徽財經大學金融學院 安徽·蚌埠)
?
醫保欺詐行為的主動發現
□文/唐璟宜 孫有坤 周海林
(安徽財經大學金融學院 安徽·蚌埠)
[提要] 針對在醫療行業中存在的醫療保險欺詐行為,應當有合適的方法去及時發現并制止,只有這樣才能使醫療保險金能真正落到實處。本文使用主成分分析、K-m eans聚類分析等方法,并運用M A TLA B、SPSS等軟件對數據進行分析,并對我國醫保行業現狀進行分析,為相關部門自動識別醫保詐騙提供具體的模型及識別方法。
關鍵詞:醫保欺詐;主動發現;主成分分析;K-m eans聚類
收錄日期:2016年6月13日
一、數據挖掘預處理
由于本文主要研究的是醫保欺詐行為,所以數據處理中只保留所有參保人員,將非參保人員的就診拿藥數據剔除,減少無關數據的干擾。
(一)數據清洗。針對本文的研究目的,有目的地進行數據清洗。首先是刪除大量對于本次數據挖掘沒有用的數據,只保留相關數據列;其次是對于缺失的必要數據采用數據歸約的方法填補空缺。
(二)數據轉換。將文本型、字符型數據轉換為數字型數據,以方便后續研究。如用“1”和“0”代替性別的“男”、“女”;將出生日期轉換為患者年齡等。
二、醫保欺詐行為主動發現模型
(一)類型Ⅰ:醫保卡持有人已死亡。這是最容易發現的騙保行為,故優先考慮該種類型的騙保行為主動發現。通過MATLAB編程對醫保卡和身份證號列進行篩選處理,找到一個醫保卡ID對應多個醫保手冊號的情況。利用MATLAB軟件進行篩選,將篩選出的ID利用Excel的vlookup函數查找出對應的身份證號,找出嫌疑人的關鍵信息。可以將一卡兩人用、一卡三人用的醫保卡ID和醫保手冊號篩選出來。而病人也有死亡標志說明,可以查出死亡病人的ID再查找其醫保卡消費情況,對比病人的死亡時間以及賬單號的交易時間,若病人的死亡時間在前而交易時間在后,則為醫保欺詐記錄。根據所使用的數據表,暫未發現這類醫保欺詐,但仍應該警惕,及時把死亡者的醫保卡注銷,避免這類醫保欺詐的發生。
(二)類型Ⅱ:醫保卡持有人未亡。對預處理后的數據進行分析,可以發現病人的醫保費用與參保人的年齡、消費頻率、消費藥品的金額之間具有一定的關聯性。本文主要從病人年齡與消費金額、病人消費頻率與消費金額兩方面的聯系,發現異常可疑數據,并針對這些可疑數據進行分析,進一步鑒別其特征,判斷是否屬于醫保欺詐行為。
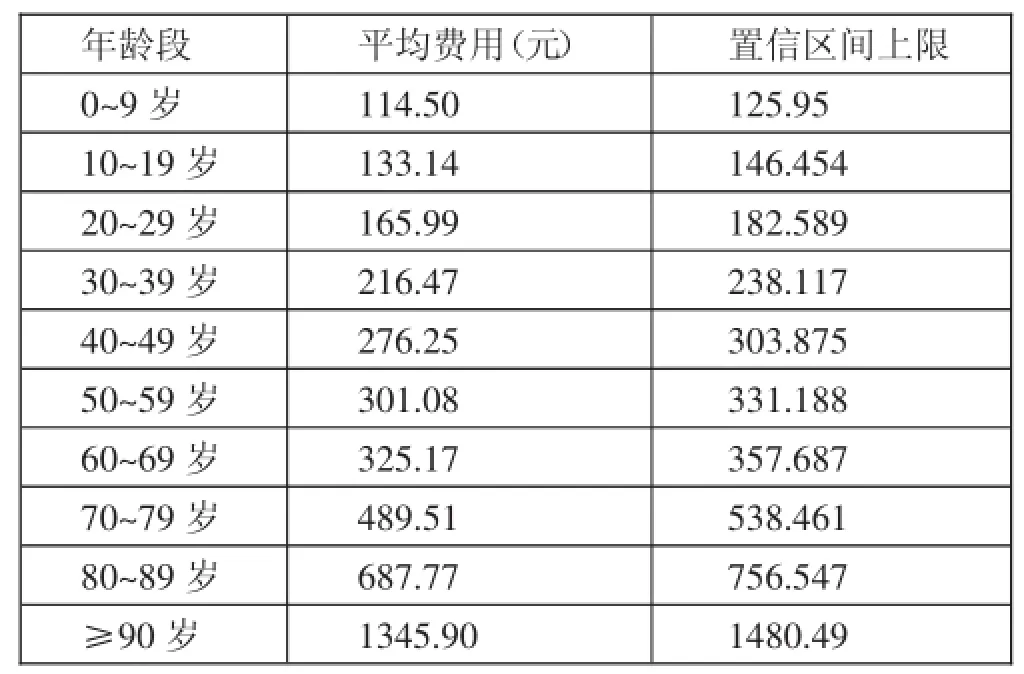
表1 各個年齡段對應的平均費用及其上限
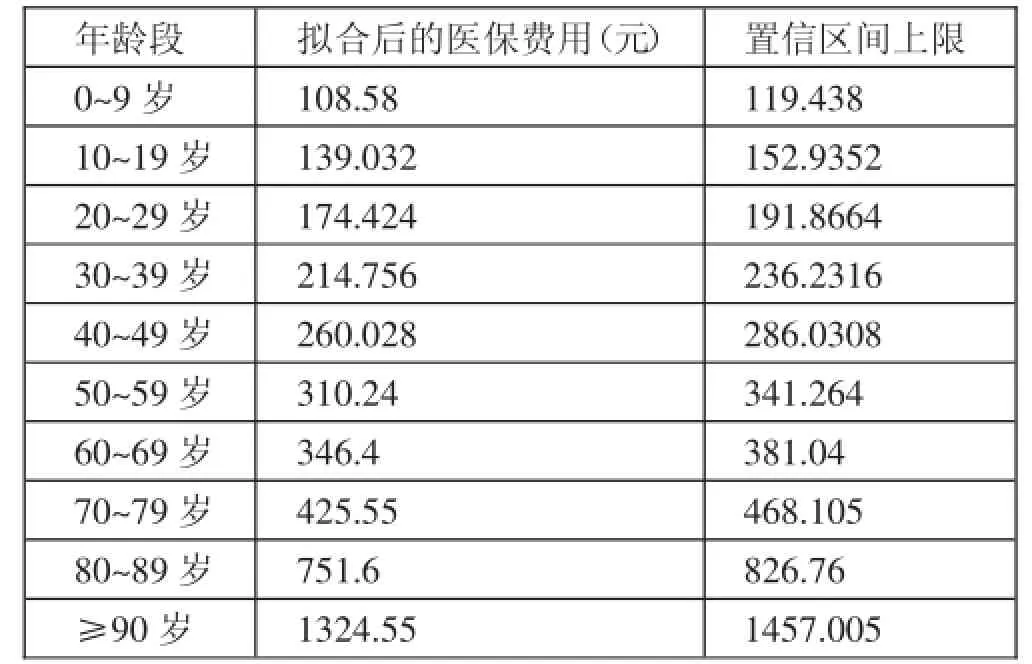
表2 擬合函數計算的各年齡段平均費用及其上限
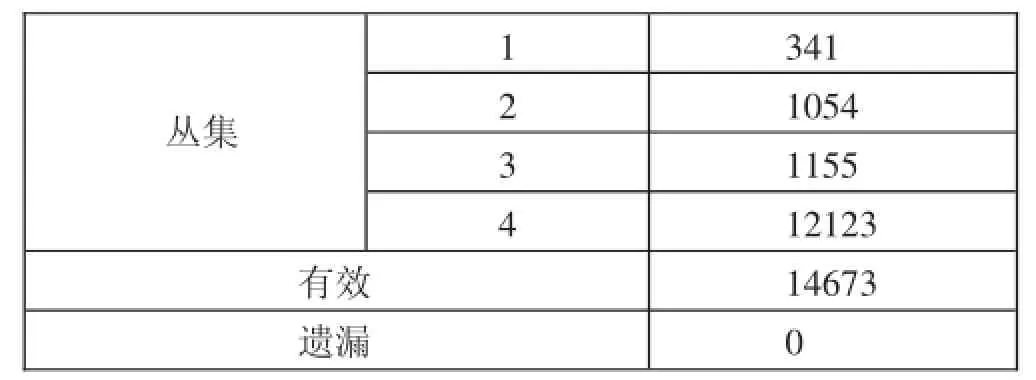
表3 各聚類對應的案例數(單位:個)
1、模型Ⅰ:年齡醫費模型。根據研究的數據對象,建立病人年齡與醫保費用的關系模型,使用SPSS軟件進行分析。首先將所有參保人的年齡分成十個階段:0~9歲、10~19歲、20~29歲、30~39歲、40~49歲、50~59歲、60~69歲、70~79歲、80~89歲、90歲以上。在此,根據醫保欺詐的特點,醫保欺詐的費用越高越有可能存在欺詐行為,故只考慮平均費用置信區間的上限無意義。人為將置信區間設定為向上浮動10%。在EXCEL表中使用分類匯總操作,計算出各階段醫保支付費用平均值及平均費用置信區間的上限,如表1所示。(表1)
利用EXCEL畫出圖形,通過觀測散點的分布情況來確定擬合函數,利用數理統計方法中的多元回歸統計方法可以得到因變量與自變量之間的回歸關系函數表達式。(圖1)
在圖中可以發現60歲以上的曲線呈明顯上升趨勢,于是建立分段函數,分別對0~59歲和60歲以上進行擬合,擬合的回歸曲線如圖2和圖3所示。(圖2、圖3)
于是建立得到醫保費用關于年齡的函數,如下:
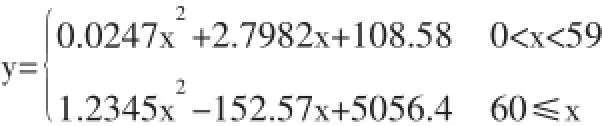
在上述方程的基礎上建立初步篩選規則:按病人的年齡找到對應的置信區間,若發現病人的實際花費其所在區間上限,則該病人醫保費用花費超過一般標準,具有醫保詐欺的嫌疑,將對這些病人進行進一步具體審查。(表2)
2、模型Ⅱ:消費頻率與金額模型。由于在醫保欺詐中,騙保人通常使用的手段包括兩種:一是拿著別人的醫保卡配藥;二是在不同的醫院和醫生處重復配藥。這些行為使有醫保欺詐嫌疑的病人所對應消費記錄中,某個醫保卡ID對應的藥費明細存在記錄多、頻率大、藥費總和高的特點。即消費金額高和消費頻率高是醫保欺詐一個最大的特征。于是,本文具體研究存在著這兩種消費特征的醫保記錄,具體識別其中的醫保欺詐行為,依據此種情況,可以將藥費和頻率等基于k-means算法進行聚類分析。
K-means算法是以數據點到原型的某種距離作為優化的目標函數,利用函數求極值的方法得到迭代運算的調整規則。本文使用的K-means算法以歐式距離作為相似度測度,通過對某一初始聚類中心向量的最優分類,得到對應評價指標最小。算法采用誤差平方和準則函數作為聚類準則函數。首先在ACCESS中進行數據預處理,再利用SPSS分析數據屬性的特征,選擇典型數據作為初始聚類中心,進行k-means聚類分析求出每個病人的消費頻率與消費藥品的總金額。
本文選擇四類數據作為初始的聚類中心:1、消費頻率高,消費金額大;2、消費頻率低,消費金額大;3、消費頻率高,消費金額小;4、消費頻率低,消費金額小。結果如表3所示。(表3)從表3中可以看出第一類數據含有341個樣本,這類病人消費頻率高且消費額大,可能存在醫保欺詐行為。用這種方法可以快速發現所有有欺詐嫌疑的記錄。
3、類型Ⅲ:醫師、科室參與欺詐。當找出所有可疑的欺詐記錄后,可以通過不同表之間的數據映射關系來找到與嫌疑人員有關的嫌疑科室、嫌疑醫生,從而可以確定協助作案的科室醫生,便于以后的重點監督和排查。
根據醫保詐騙的作案特點,在某些情況下,科室可以通過偽造病歷和票據通過醫保報銷,以騙取醫保金,造成某些患者費用和頻率較高。為了有針對性地對這類數據進行查找,根據這幾個表的映射關系,篩選出與嫌疑人員ID有關的科室并且統計他們與嫌疑人員進行操作的次數,以此進行查找。首先統計原始數據,原始數據有下醫囑科室與執行科室兩種科室,在醫保詐騙事件中,下醫囑科室的欺詐嫌疑較大,因此重點分析下醫囑科室信息。利用疑似人員的醫保卡號篩選出與之相關的科室,并統計出與這些疑似ID進行交易的次數來確定科室的嫌疑度。根據與嫌疑ID交易的次數進行排序,當某些科室的交易次數和與其相鄰的科室樣本突然發生較大變化,可以此作為分界點,劃分出嫌疑科室。與嫌疑科室同理,可以采用同樣的方法查詢出嫌疑醫生。由這種方法,可以找到醫保欺詐事件高發的重點科室,這些科室可能本身存在嫌疑,或是較為容易被不法分子利用空隙進行醫保欺詐。

圖1 各年齡段對應的平均費用散點圖
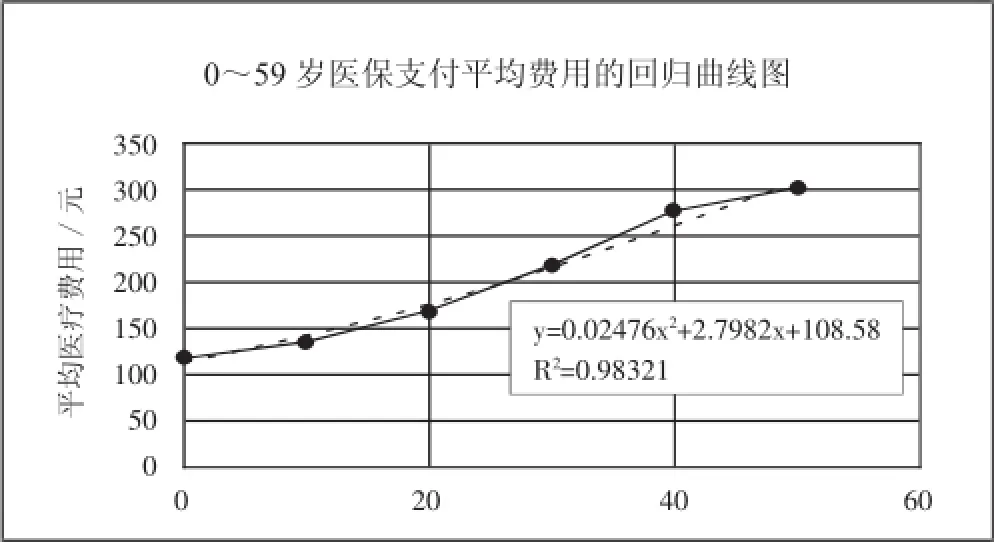
圖2 0~59歲醫保支付平均費用的回歸曲線圖
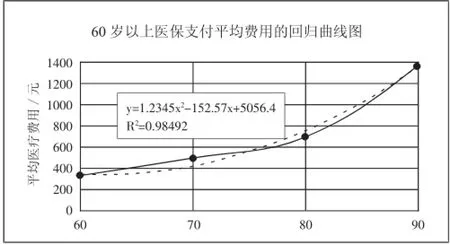
圖3 60歲以上醫保支付平均費用的回歸曲線圖
三、醫保欺詐數據分析
根據數據處理的結果,發現我國醫療保險存在如下三類的欺詐現象:(1)醫療保險需求方的欺詐違規行為。在現實情況中主要表現有:冒名頂替就醫、以藥換藥、倒賣藥品等;(2)醫療保險服務提供方的欺詐違規行為。主要可能表現為:重復收費、虛報醫療費用、倒賣醫療票據等;(3)醫療保險服務提供方與需求方聯合的欺詐違規行為。主要的欺騙手段有:在醫院掛床、用物充藥、幫助提供虛假證明、偽造虛假病歷等。其中,第一類行為最為普遍,第二、第三類行為較少,但一旦發生將會發生嚴重影響。這些行為對我國的醫療保險基金造成嚴重損失,危害我國醫療保險基金的公平性與公正性。
四、對完善醫保制度的建議
(一)進一步改革支付制度。在總額控制支付模式的框架下,應當以總額預付為主,結合多種付費方式的復合型支付制度,綜合考慮如按病種、床日、人頭、項目付費等因素,從多個角度來合理定價,減少由于藥費過高而使參保病人產生的騙保心理,讓參保病人住的安心,讓醫保基金用到實處。
(二)建立醫保信息智能網絡平臺。一個參保病人對應一個電子賬戶,將病例電子化,詳細記錄病人的一切看病用藥信息。該賬戶應做到全國甚至世界范圍內共享。
(三)完善對醫保定點醫院的內部管理。合理劃分基金管理機構的職責并做到權力制衡,建立醫療服務監督評價體系和獎懲制度。
(四)完善對醫保定點醫院的外部監督。加大對醫保定點醫院、醫師以及各類機構的違規行為的查懲力度,如發現有醫保違規行為,將取消涉案醫保醫師的執業資質。
五、總結
前人的研究包括采用基于統計回歸或神經網絡思想的優化改進方法,而這些方法都屬于輔助學習方法,需要基于一定量的已知數據,或擁有較為豐富的先驗知識,以獲取識別因子作為學習材料,用以主動識別其他大量數據中包含的可能欺詐數據。該方法的問題在于欺詐樣本點的選取過于依賴人的主觀性,對于普遍意義上欺詐數據的識別不具備較強的參考價值。
為避免人工篩選欺詐數據帶來的主觀誤差,需要找到非輔助學習的方法。聚類分析法可以滿足這一條件,但傳統的聚類分析采用歐氏距離作為分類標準,不足之處在于將各種影響因素的重要程度視為相同的,會造成一些不重要的參量(如年齡)卻和一些重要的參量(如病人一個月之內的開藥次數)同等的影響著最后的分類。
為解決該問題,本文將主成分分析引進聚類分析,成為基于主成分分析的聚類分析算法。主成分分析模型是一種降維的算法,可以有效地將存在欺騙行為的數據范圍縮小化,減少數據的冗余性,并保持數據的有效性。同時,聚類分析能夠很好的反映類之間的關系,本文中的各個因素雖然是彼此獨立的,但是對于存在欺詐行為的情況時,數據內部會產生相關性,通過聚類分析可以快速有效地掌握它們之間的關系。在改進的主成分聚類分析法中,將這兩種統計方法的優勢結合,相輔相成,以達到綜合評價的目的。
主要參考文獻:
[1]殷瑞飛.數據挖掘中的聚類方法及其應用——基于統計學視角的研究[D].廈門:廈門大學,2008.
[2]江小平,李成華,向文,張新訪,顏海濤.K-m eans聚類算法的M apReduce并行化實現[J].華中科技大學學報(自然科學版),2011.6.39.
[3]王文華.基于蟻群算法模糊聚類的圖像分割[D].重慶:重慶大學,2009.
基金項目:國家級大學生創新項目(編號:201510378153)
中圖分類號:D 9
文獻標識碼:A
