基于運動和空間方向一致性的視頻顯著性檢測
2016-08-05 07:58:06陳耀武
計算機應用與軟件 2016年7期
韓 冬 田 翔 陳耀武
(浙江大學數字技術與儀器研究所 浙江 杭州 310027) (浙江省網絡多媒體技術重點實驗室 浙江 杭州 310027)
?
基于運動和空間方向一致性的視頻顯著性檢測
韓冬田翔陳耀武
(浙江大學數字技術與儀器研究所浙江 杭州 310027) (浙江省網絡多媒體技術重點實驗室浙江 杭州 310027)
摘要根據人眼的視覺特點,提出一種基于對比運動和空間方向一致性的算法,用來檢測視頻序列的顯著性區域。在該算法中,首先針對每一幀圖像利用sobel算子計算其水平梯度、垂直梯度,然后用光流法計算運動矢量;接著構建三維張量結構,得到每個像素點與周圍點的水平、垂直梯度和運動矢量一致性,并對比每個像素點與周邊點的一致性;最后把對比結果轉化為視頻顯著圖。將該方法與已經存在的方法進行比較,實驗結果表明,該方法可以很好地排除背景紋理區域的運動所帶來的影響,能夠準確地檢測出各種運動場景的顯著性區域。
關鍵詞視頻顯著性空間方向梯度運動矢量三維張量結構一致性對比
0引言
視頻顯著性與人體視覺系統密切相關。它使得人們能夠在一個視頻場景中快速地找到所關注的區域,有助于我們對視頻圖像的理解,可以用于感興趣區域檢測、目標分割、識別與跟蹤等[1]。目前,視頻顯著性分析已經成為了圖像處理和計算機視覺領域的一個重要研究課題。
在過去的十幾年里,研究者發明了許多應用于靜止圖像的顯著性檢測算法。Itti等人[2]于1998年提出了一種基于多尺度圖像特征融合的顯著性檢測方法。Harel等人[3]于2006年提出了一種基于圖的抖動的自底向上的視覺顯著性模型。2007年Hou等人[4]通過計算傅里葉譜殘差,得到了顯著性圖。2009年Achanta等人[5]結合顏色與亮度等信息來進行顯著性檢測。Cheng等人[6]在2011年提出了一種基于區域對比度的方法,利用直方圖與空間信息得到了視頻顯著圖。Perazzi等人[7]在2012年提出了一種基于對比的顯著性模型,它抽取了圖像的超像素成分,并通過對比其獨特性和空間分布性來得到顯著性圖。
根據人體視覺系統的特性,人眼對正在運動的物體更加敏感,使得視頻序列的顯著性與靜止圖像的顯著性有著一定的不同。對于視頻序列來說,一個好的顯著性檢測算法應該更加關注于正在運動的物體。最早的方法是通過混合高斯模型[8]來得到顯著性圖。它用多個高斯模型來表征圖像中各個像素點,在每一幀圖像更新高斯模型,通過像素點與模型匹配得到視頻顯著圖。Zhai等人[9]提出了一種基于時空信息的顯著性檢測方法。它通過圖像的顏色距離差來計算空域顯著性,通過SIFT點對來計算時域顯著性,并將二者動態融合成為最后的視頻顯著圖。Guo等人[10]計算每個像素點的灰度、顏色和運動特征,組成四元組,通過四維傅里葉變換的相位譜來得到視頻顯著圖。Fang等人[11]于2014年提出了一種融合時空信息與統計學不確定性的顯著性檢測方法。它首先提取運動特征進行時間顯著性評估,提取光照、顏色和紋理特征進行空間顯著性評估;然后分別進行時間、空間不確定性評估;最終將時空的顯著性、不確定性進行加權融合得到視頻顯著圖。
本文提出一種基于對比運動和空間方向一致性的算法,計算每一幀圖像的水平梯度、垂直梯度和運動矢量,并將每個像素點與周圍像素點進行對比,把對比圖轉換成為視頻顯著圖。實驗表明,該算法能夠很好地克服背景紋理區域的運動所帶來的影響,準確地檢測出各種運動場景的顯著性區域。
1顯著性檢測
本文中視頻顯著性檢測算法分為以下四個步驟:光流法計算運動矢量;利用Sobel算子計算圖像水平、垂直梯度;利用三維結構張量模型計算每個像素點與周圍像素點的水平、垂直梯度與運動矢量的一致性;通過對比一致性獲得視頻顯著圖。算法框架如圖1所示。
圖1 算法流程圖
1.1計算運動矢量與空間梯度
通過光流法[12]計算輸入視頻每幀圖像的運動矢量矩陣MVx、MVy,得到的運動矢量場與輸入視頻有著相同的分辨率。其中MVx表示水平方向運動矢量矩陣,MVy表示垂直方向運動矢量矩陣。計算運動矢量幅值,得到幅值矩陣,如式(1)所示:
(1)
為了方便后續處理,將運動矢量矩陣歸一化,得到歸一化后的運動矢量矩陣gt,如式(2)所示:
(2)
利用sobel算子[13]對輸入視頻灰度圖像進行掩膜濾波,得到與輸入視頻有著相同分辨率的水平梯度矩陣gx和垂直梯度矩陣gy,同樣進行歸一化處理。用于水平、垂直濾波的sobel算子分別為:
(3)
(4)
1.2構建三維結構張量
基于Laptev等人[14]時空域中感興趣區域點的特征的啟發,對每一幀圖像k中的每個像素點i,構建三維結構張量Sk(i),用來表示視頻圖像中的點在時空域的特征,如式(5)所示:
(5)

本文中使用三維結構張量矩陣Sk(i)的原因是:計算矩陣Sk(i)的最大特征值λ1和另外2個特征值λ2、λ3的差值,其差值可以表示局部區域中的像素點沿著三維時空方向(三個坐標軸分別為空間水平梯度、空間垂直梯度、運動矢量)分布的密集程度。差值越大,表示密集程度就越大,時空方向的一致性就越高。
因此,如式(6)所示,我們定義每個像素點的時空方向一致性c為:
c=(λ1-(λ2+λ3))2
(6)
如圖2所示,在輸入視頻灰度圖像中選取兩個矩形區域,船代表顯著性運動區域,水波代表非顯著性干擾區域。

圖2 coastguard視頻中選取的船和背景水波矩形區域
將所選取的兩個矩形區域中各個點繪制在三維時空方向圖中,三個坐標軸分別為空間水平梯度、空間垂直梯度、運動矢量。如圖3所示,在顯著性運動區域(船)中的像素點密集程度高,時空域方向的一致性高,而非顯著性干擾區域(水波)像素點密集程度低,一致性低。
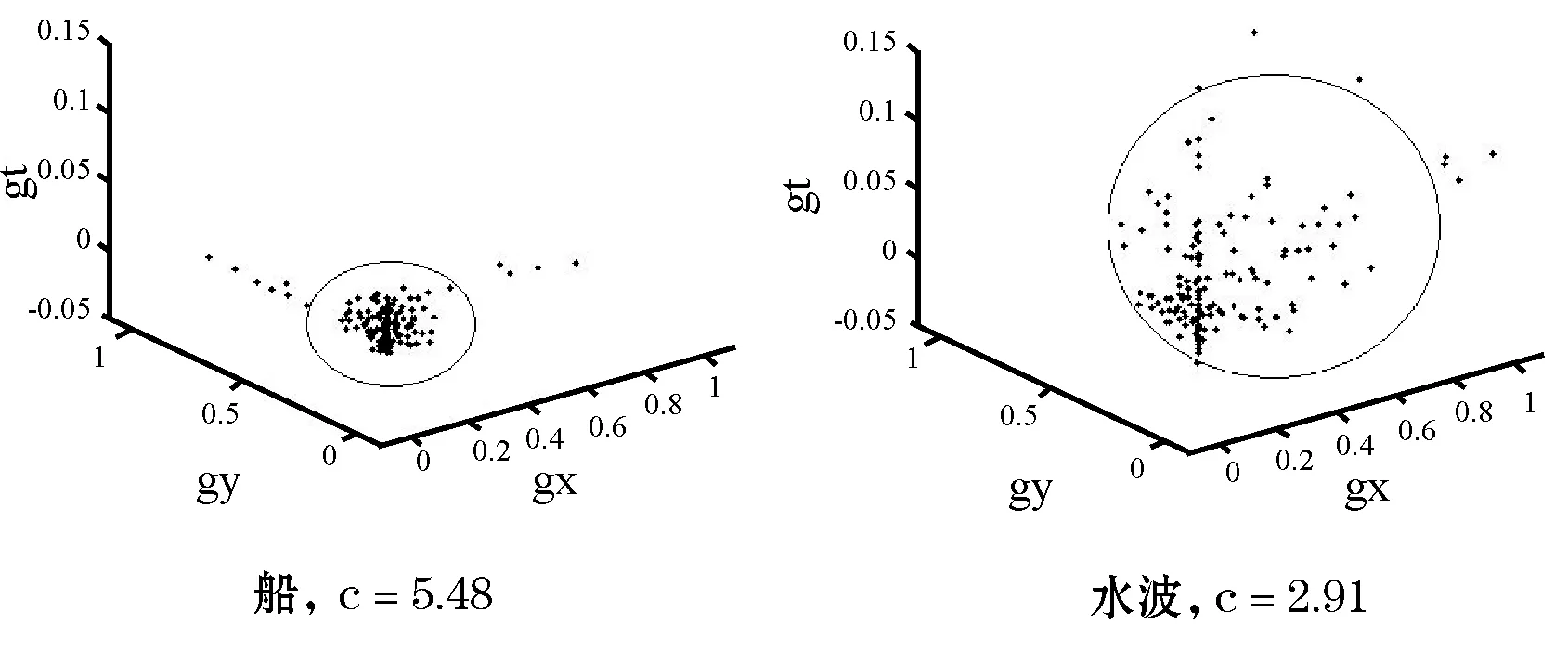
圖3 船和背景水波中的點的分布以及一致性c的值
1.3一致性對比
為了減少背景局部區域動態變化帶來的噪聲,體現出局部區域的一致性,我們將每個像素點的時空域方向一致性與其周圍像素點進行對比,得到對比值:
其中ck(i)、ck(j)分別為第k幀像素點i、j的時空方向一致性,Wi為以像素點i為中心的圖像矩陣,在本文中取7×7矩陣。計算可得,圖2中船的矩形區域V值為573.31,水波的矩形區域V值為145.38,二者的V值差異比一致性c差異更大一些。
2實驗結果與分析
為了驗證本文算法的有效性,將本文算法(MSC)與以下方法進行比較:基于譜殘差的顯著性模型(SR)[4]、基于空間區域對比度與顏色信息的顯著性模型(RC)[6]、混合高斯模型(GMM)[8]。基于譜殘差的顯著性模型(SR)[4]是靜態空間信息模型;基于空間區域對比度與顏色信息的顯著性模型(RC)[6]是結合顏色信息的顯著性模型;混合高斯模型(GMM)[8]是結合了時空信息的顯著性模型。在本文實驗中,選取5類不同場景的視頻進行測試:(1)有單個運動的物體,背景不動,且背景包含大塊平坦信息和紋理區域;(2)有2個運動的物體,背景不動,且背景紋理比較復雜;(3)有2個運動的物體,背景在運動,且背景紋理比較復雜;(4)有1個運動的物體,背景在運動,且背景紋理比較復雜;(5)鏡頭在運動,體現為背景在運動。實驗結果如圖4所示。

圖4 實驗結果
由圖4可以看出,本文算法與其他方法相比,能夠準確地檢測出顯著性區域,并能夠很好地克服背景區域運動帶來的影響。具體來看,由于背景紋理區域運動的影響,SR模型算法并不能很好地區分顯著性運動的物體與背景;RC算法能夠很好地區分顏色信息,但是對運動的物體并不敏感,也不能很好地將運動的物體分離出來;GMM算法結合了時間信息,相對SR和RC要好一些,能夠檢測出顯著運動的物體,但是仍不能完全排除背景信息的干擾。這些算法并不能很好地排除背景區域運動帶來的噪聲,如水波和觀眾等。而本文算法結合了運動矢量和空間梯度,利用三維結構張量模型,對比運動與空間方向的一致性,能夠很好地排除背景噪聲。
為了更加直觀地評價本文提出的方法,我們通過準確率(precision)、召回率(recall)、加權調和均值指標(F值)來比較本文算法與上述方法。其中準確率(precision)定義為檢測到正確顯著點的數目與檢測到所有顯著點的數目之比,召回率(recall)定義為檢測到正確顯著點的數目與實際顯著點的數目之比。加權調和均值指標(F值)的定義如式(8)所示。
(8)
一般而言,準確率和召回率通常是矛盾的,所以采用F值來綜合表示顯著性檢測結果。在本文中,與文獻[6]相同,取λ2為0.3。檢測結果如圖5所示。我們可以看出,本文算法要好于其他方法。

圖5 顯著性檢測結果
利用coastguard視頻序列將本文算法的耗時與SR、RC、GMM算法進行比較,通過MATLAB 7.0計算各算法所耗時間。結果如圖6所示。我們可以看出本文算法(MSC)比其他算法耗時都要長,這是因為針對每個像素點都要計算三維張量結構、三維矩陣特征值,并對比每個像素點與周圍像素點的一致性,耗時較多。

圖6 各算法耗時結果
3結語
本文提出了一種基于對比運動和空間梯度一致性的視頻顯著性檢測算法。該算法首先用光流法計算運動矢量,接著計算每幀輸入圖像的水平、垂直梯度,通過構建三維張量結構,計算每個像素點水平梯度、垂直梯度和運動矢量三者與周圍點的一致性,并通過對比一致性構建出顯著性模型。實驗結果表明,本文算法能夠很好地排除背景紋理區域的運動帶來的噪聲,準確地檢測出視頻顯著性區域,優于其他方法。本文算法中計算三維張量結構耗時比較多,如何改善該算法是后續的研究方向。
參考文獻
[1] Liu T, Yuan Z, Sun J, et al. Learning to detect a salient object[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2):353-367.
[2] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254-1259.
[3] Harel J, Koch C, Perona P. Graph-based visual saliency[C]// Proceedings of Neural Information Processing Systems. Vancouver: MIT Press, 2006:545-552.
[4] Hou X, Zhang L. Saliency detection: a spectral residual approach[C]// IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis: IEEE, 2007:1-7.
[5] Achanta R, Estrada E, Wils P, et al. Salient region detection and segmentation[C]// International Conference in Computer Vision System. Santorini: Springer, 2008:66-75.
[6] Cheng M, Zhang G, Mitra N J, et al. Global contrast based salient region detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs: IEEE, 2011:409-416.
[7] Perazzi F, Krahenbuhl P, Pritch Y, et al. Saliency filters: contrast based filtering for salient region detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012:733-740.
[8] Zivkovic Z. Improved adaptive Gaussian mixture model for background subtraction[C]// IEEE Conference on Pattern Recognition. Cambridge: IEEE, 2004:28-31.
[9] Zhai Y, Shan M. Visual attention detection in video sequences using spatiotemporal cues[C]// International Conference on Multimedia. Santa Barbara: ACM, 2006:815-824.
[10] Guo C, Ma Q, Zhang L. Spatiotemporal saliency detection using phase spectrum of quaternion Fourier transform[C]// IEEE Conference on Computer Vision and Pattern Recognition. Anchorage: IEEE, 2008:1-8.
[11] Fang Y, Wang Z, Lin W, et al. Video saliency incorporating spatiotemporal cues and uncertainty weighting[J]. IEEE Transaction on Image Processing, 2014, 23(9):3910-3921.
[12] Sun D, Roth S, Black M J. Secrets of optical flow estimation and their principles[C]// IEEE Conference on Computer Vision and Pattern Recognition. San Francisco: IEEE, 2010:2432-2439.
[13] Rafael C Gonzalez, Richard E Woods. 數字圖像處理[M]. 阮秋琦,阮宇智,等譯. 3版. 北京:電子工業出版社, 2011.
[14] Laptev I, Lindeberg T. On space-time interest points[J]. International Journal of Computer Vision, 2005, 64(2):107-123.
收稿日期:2015-02-10。浙江省重點科技創新團隊項目(2011R0 9021)。韓冬,碩士生,主研領域:網絡視頻編解碼。田翔,副教授。陳耀武,教授。
中圖分類號TP391.4
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.07.037
VIDEO SALIENCY DETECTION BASED ON CONTRASTING COHERENCE OF MOTION AND SPATIAL DIRECTION
Han DongTian XiangChen Yaowu
(InstituteofAdvancedDigitalTechnologyandInstrumentation,ZhejiangUniversity,Hangzhou310027,Zhejiang,China) (ZhejiangProvincialKeyLaboratoryforNetworkMultimediaTechnologies,Hangzhou310027,Zhejiang,China)
AbstractAccording to the characteristics of human visual system (HVS), we proposed an algorithm to detect the salient region of video sequence, which is based on contrasting the coherence of motion and spatial direction. In this algorithm, it first uses Sobel operator to calculate the horizontal gradient and vertical gradient for each frame, and then calculates the motion vector by the method of optical flow. After that, it builds a 3D tensor structure to obtain the coherence of each pixel with its surrounding pixels in regard to the horizontal and vertical gradients and the motion vector, as well as contrasts the coherence of each pixel with its surrounding pixels. Finally it converts the contrasting results to video saliency map. Comparing this algorithm with existing methods, experimental result showed that it could well exclude the impact of motion in background texture region and accurately detect the salient regions of all kinds of motion scenes.
KeywordsVideo saliencySpatial directionGradientMotion vector3D tensor structureContrast of coherence
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
燕山大學學報(2015年4期)2015-12-25 02:19:49
