基于馬爾科夫隨機場的非參數化RGB-D場景理解
2016-08-04 06:18:32費婷婷龔小謹
浙江大學學報(工學版) 2016年7期
費婷婷,龔小謹
(浙江大學 信息與電子工程學系,浙江 杭州 310027)
?
基于馬爾科夫隨機場的非參數化RGB-D場景理解
費婷婷,龔小謹
(浙江大學 信息與電子工程學系,浙江 杭州 310027)
摘要:針對RGB-D場景下的場景理解問題,提出高效的基于標簽傳遞機制的非參數化場景理解算法.該算法主要分為標簽源構建、超像素雙向匹配和標簽傳遞三個步驟.與傳統的參數化RGB-D場景理解方法相比,該算法不需要繁瑣的訓練,具有簡單高效的特點.與傳統的非參數化場景理解方法不同,該算法在系統的各個設計環節都有效利用了深度圖提供的三維信息,在超像素匹配環節提出雙向匹配機制,以減少特征誤匹配;構建基于協同表示分類(CRC)的馬爾科夫隨機場(MRF),用Graph Cuts方法求出最優解,獲得場景圖像每個像素的語義標簽.該算法分別在室內的NYU-V1數據集和室外的KITTI數據集上進行實驗.實驗結果表明,與現有算法相比,該算法取得了顯著的性能提升, 對室內、外場景均適用.
關鍵詞:場景理解;非參數化;RGB-D;馬爾科夫隨機場(MRF)
場景理解是用模式識別和人工智能的方法對場景圖像進行分析、描述、分類和解釋,最終得到場景圖像中每個像素語義標簽的技術,是計算機視覺的一個重要課題,在無人車駕駛、機器人導航、虛擬現實、安防監控等領域有著廣泛的應用.
近年來,隨著激光雷達[1]以及微軟Kinect[2]等距離傳感器的面世,場景深度信息的獲取變得更加容易,結合三維點云數據或致密深度等三維信息的場景理解方法引起了眾多學者的廣泛關注[3-6].譚倫正等[4-5]采用神經網絡訓練的方法來進行場景理解;Ren等[6]提出基于分割樹的參數化場景理解方法,對分割樹的每一層分別訓練一個支持向量機(supportvectormachine,SVM)分類器,結合馬爾科夫隨機場(Markovrandomfield,MRF)進行求解.這些參數化方法都依賴繁瑣的模型訓練,對場景類別的伸縮性非常差,一旦場景的語義類別發生增減,就需要對所有語義類別重新訓練模型,非常耗費運算時間和計算資源.本文設計一種無需依賴任何訓練、通過場景圖像間的相似性傳遞語義標簽的非參數化方法.
現有的非參數化場景理解方法主要在二維圖像上展開研究[7-13],Liu等[11]首先提出通過標簽傳遞進行場景理解的思路,將目標像素與標簽源像素SIFT特征的最小歐氏距離定義為似然函數,構建MRF求解目標圖像每個像素的標簽.由于基于像素的方法計算量太大,Tighe等[12]提出用超像素作為場景理解的基本處理單元,設計利用目標超像素標簽源中k近鄰(k-nearestneighbor,kNN)屬于各個語義類別的頻率,定義目標超像素屬于該語義類別的似然.Yang等[13]在文獻[12]的基礎上設計稀有類別的補充機制,提高了稀有類別的標注準確率.這些非參數化場景理解方法都利用像素或者超像素間的匹配度進行標簽傳遞,沒有考慮匹配到的各個近鄰對目標對象的貢獻差異.針對該問題,Eigen等[14]提出自適應近鄰的標簽傳遞方法,在文獻[12]的基礎上為目標待標注對象匹配到的各個近鄰分配權重,以度量各近鄰對目標對象的貢獻差異,但權重的獲得是通過訓練得到的.為了避免耗時繁瑣的訓練,本文創新性地設計了基于協同表示分類 (collaborativerepresentationbasedclassification,CRC)[15]的標簽傳遞機制,不僅充分考慮了標簽源中的不同超像素對目標超像素的貢獻差異,而且節省了運算時間和計算資源,使得整個算法更加簡單高效.
二維圖像包含的信息有限,單純利用二維圖像的信息進行場景理解難以取得令人滿意的效果,為了提升算法性能,在算法的各個步驟都充分利用了深度圖的三維幾何信息.
1) 在標簽源的構建過程中,設計了基于深度的法向量直方圖,用以檢索與目標圖像空間布局相似的圖像.
2) 在局部特征雙向匹配的過程中,從深度圖中提取了深度梯度核描述符.
3) 在MRF的平滑項中,設計了基于深度的表面法向量平滑項,用以懲罰為表面法向量夾角過大的相鄰超像素分配相同語義標簽的情況.
1算法概述
提出的非參數化的場景理解方法主要分為3個步驟:標簽源構建、超像素雙向特征匹配和基于馬爾科夫隨機場(MRF)的標簽傳遞.標簽源由相似圖像檢索集和稀有類別詞典兩部分組成,相似圖像檢索大大縮小了標簽源的范圍,不僅減少了場景不同的噪聲標簽的干擾,而且大幅提升了算法的運算速度.超像素雙向特征匹配的目的是衡量匹配的超像素對之間的相似度,為標簽的傳遞提供依據.考慮到圖像相鄰超像素間語義類別的平滑性,構建馬爾科夫隨機場(MRF),進一步提升算法的性能.如圖1所示為該算法的流程框圖.
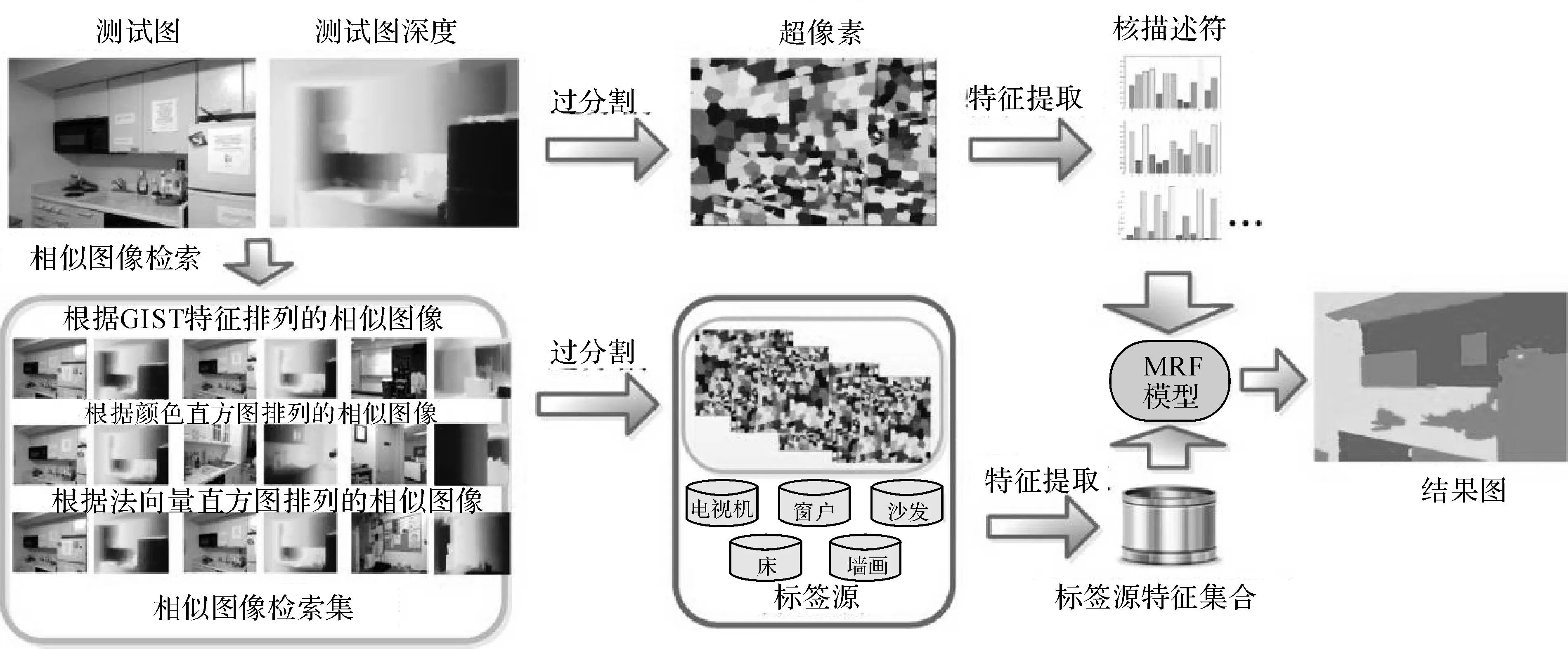
圖1 場景理解算法流程圖Fig.1 Flow chart of scene parsing algorithm
首先輸入目標待標注場景的RGB圖像和深度圖,結合RGB圖像中提取的外觀特征和深度圖中提取的三維幾何特征,將待標注的目標圖像與訓練集中已標注的圖像進行全局特征匹配,根據歐氏距離構建目標圖像的相似圖像檢索集.為了減少目標圖像中稀有類別標簽的丟失,根據各語義類別的超像素在訓練集中所占的比例,構建稀有類別詞典,與相似圖像檢索集一起作為待標注圖像的標簽源.結合RGB-D圖像的顏色信息和深度信息對目標圖像及目標圖像標簽源的超像素進行特征提取,并對提取的特征進行雙向特征匹配.構建基于協同表示分類(CRC)[15]的馬爾科夫隨機場(MRF),通過Graphcuts[16]的方法求解能量方程得到目標圖像每個超像素的語義標簽.
2標簽源構建
通常相似的場景所包含的語義信息往往是相似的,在數據量足夠大的前提下,總是能夠找到與目標待標注圖像場景相似的圖像,這為利用圖像間的相似性進行語義標簽的傳遞提供了可能.
為了降低算法的運算量,減少場景不同的噪聲圖像標簽對目標圖像標注的干擾,首先根據全局特征匹配構建待標注目標圖像的相似圖像檢索集.為了充分表達圖像的全局特征,采用3種全局特征:GIST特征[17]、顏色直方圖hcol和法向量直方圖hnor.GIST特征[17]和顏色直方圖都從RGB圖像中提取,本文提取的GIST特征為960維,從目標圖像的R、G、B3個通道,在方向分別為8、8、4的3個尺度上提取,顏色直方圖分別將R、G、B三個通道的值量化到8個單位柱上生成一個24維的特征.
法向量直方圖是本文提出的一種新的三維全局特征,從圖像的深度圖中提取,先對深度圖中的每個像素計算對應的三維法向量n(x,y,z),然后將圖像所有像素的法向量的x、y、z三個維度的值分別量化到8個單位上,生成一個24維的特征.法向量直方圖能夠檢索出具有相似空間布局的圖像,但與GIST不同的是,在場景不十分雜亂,空間結構較規律的情況下,法向量直方圖能夠更好地描述圖像的整體空間布局,檢索到的相似圖像的空間布局與目標圖像更相近,對應的例子見圖2的測試圖像1.
在3種全局特征提取完成后,根據每種特征,分別將訓練集圖像按與目標圖像對應特征的歐氏距離升序排列.為了最大限度地剔除與目標圖像場景不同的圖像,以減少噪聲標簽的干擾,將排列好的3組圖像的前K1(K1=350)個圖像的交集作為目標圖像的相似圖像檢索集.
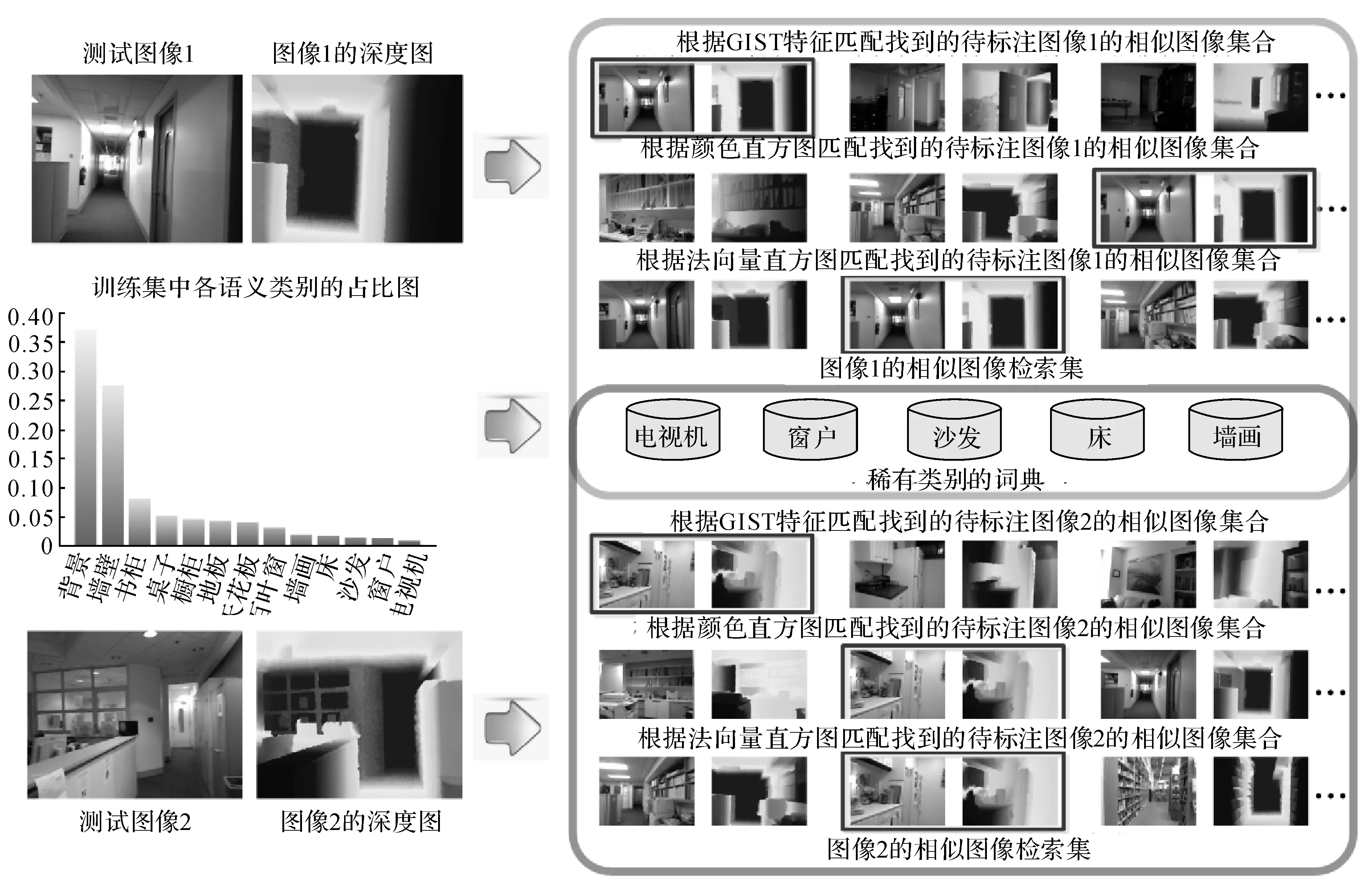
圖2 標簽源構建流程圖Fig.2 Flow chart of label pool construction
全局特征只能描述圖像的全局信息,因此目標圖像中的某些語義標簽,尤其是稀有類別的語義標簽很可能在其相似圖像檢索集中缺失,從而導致這些語義標簽無法通過標簽傳遞被準確標注.如圖2的測試圖像2,目標測試圖像中有一個小電視機,但3種全局特征檢索到的相似圖像檢索集中沒有“電視機”這個語義標簽.針對該問題,將各個語義類別的超像素在訓練集中占比低于3%的類別定義為稀有類別,分別對各稀有類別的超像素進行K-means聚類,聚類中心個數設置為100,這100個聚類中心構成的集合為該類別的詞典.將稀有類別超像素的詞典與相似圖像檢索集的超像素作為目標圖像的標簽源.標簽源的構建流程如圖2所示.
3超像素雙向特征匹配
3.1特征提取
標簽傳遞在像素或者超像素上都可以進行.本文采用超像素作為標簽傳遞的基本單元,一方面大大降低了算法的運算成本;另一方面,在特征提取的過程中,對像素的特征提取考慮的往往是以該像素為中心的固定尺寸的方格范圍,與之相比,超像素通常能夠將屬于同一個物體的區域聚集起來,為特征提取提供更好的空間支持.本文采用TurboPixel算法[18]對圖像進行過分割,利用核描述符(Kerneldescriptor)[19]對生成的超像素進行特征提取.核描述符是Bo等[19]提出的一種特征提取方法,本文從二維圖像中提取了梯度核描述符fgd和顏色核描述符fcol,從深度圖中提取了深度梯度核描述符fgd-d;然后將3種核描述符串聯,生成待匹配的局部特征f.
(1)
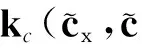
(2)
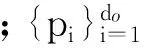
與SIFT、HOG等傳統特征相比,核描述符可以通過設計不同的核函數,將顏色、紋理、形狀等多種二維及三維特征整合成相同的形式,不僅能夠有效地利用二維圖像的外觀信息和三維圖像的幾何信息,對圖像進行更全面的表達,而且相同的特征形式能夠更好地進行特征融合,為后續的處理提供便利.
3.2雙向特征匹配
標簽傳遞的本質是根據超像素間的相似度,將標簽源中已標注的超像素的標簽通過某種傳遞機制傳遞給目標待標注的超像素.首先對目標圖像中待標注的超像素與標簽源中已標注的超像素進行相似度度量,傳統的方法主要通過超像素間的單向特征匹配來實現.為了有效減少單向特征匹配不可避免的誤匹配,本文設計了一種雙向匹配策略.
為了剔除集合SR(si)中誤匹配的超像素,設計將SR(si)中的超像素反向匹配到目標圖像.對于SR(si)中的每個超像素sq,根據核描述符的歐氏距離,在目標圖像的超像素ST中找出與其最相似的超像素N(sq).若si與N(sq)的二維歐氏距離太大或者三維高度相差太大,則把SR(si)中的超像素sq從中剔除,最后生成si的匹配集mi,描述如下.
(3)
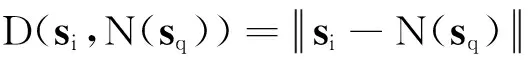
4基于馬爾科夫隨機場的標簽傳遞
考慮到超像素鄰域間的上、下文約束,構建基于馬爾科夫隨機場(MRF)的標簽傳遞模型.將為目標圖像每個超像素分配語義標簽的問題轉換成最小化如下能量函數的優化問題:
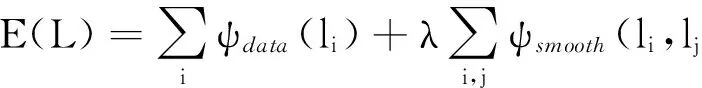
(4)
式中:L為目標待標注圖像所有超像素的標簽集;l為超像素的語義標簽;ψdata為馬爾科夫隨機場(MRF)的數據項;ψsmooth為馬爾科夫隨機場(MRF)的平滑項,主要對鄰域超像素對(si,sj)的語義標簽進行平滑,過分割后與目標超像素si有公共邊的所有超像素集合組成該目標超像素的鄰域;λ為自定義的平衡系數,λ=10.式(4)的優化函數可以利用Graph Cuts[16]求解,Graph cuts是一種十分有用和流行的能量優化算法,該方法把圖像分割問題與圖的最小割(min cut)問題相關聯.首先用一個無向圖G=
GraphCuts中的Cuts是指這樣一個邊的集合,該集合中所有邊的斷開會導致殘留“S”和“T”圖的分開,所以就稱為“割”.若一個割的邊的所有權值之和最小,則稱為最小割,即圖割的結果.福特-富克森定理表明,網路的最大流(maxflow)與最小割(mincut)相等.由Boykov發明的max-flow/min-cut算法[16]可以用來獲得s-t圖的最小割.
雖然馬爾科夫隨機場模型已經在現有的非參數化場景理解方法中得到了廣泛使用[10-12],但與傳統的非參數化方法相比,本文數據項的設計更有效,在平滑項中增加的鄰域超像素間的三維幾何約束進一步提升了算法性能.具體的構建方法詳述如下.
4.1MRF數據項構建
在傳統的非參數化場景理解方法中,MRF數據項的構建一般都直接利用各近鄰與目標超像素的歐氏距離來構建數據項,這樣的處理方式忽視了不同近鄰對目標超像素的貢獻差異.針對該問題,采用基于協同表示分類(CRC)[15]的匹配殘差來構建數據項.
當目標超像素si及局部特征fi確定后,在si的匹配集mi與稀有類別詞典共同構建的標簽源的標簽類別C(si)中為目標超像素分配一個語義標簽.CRC模型假設目標超像素位于標簽源超像素的子空間,先通過求解L2正則化的最小二乘問題來估計系數矩陣:
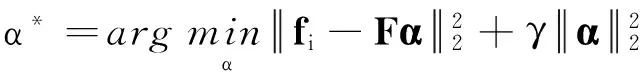
(5)
式中:F為標簽源中所有超像素的特征排列堆疊構建得到的測量矩陣;γ為一個自定義的正則系數,γ=10-3.Zhang等[15]指出,式(5)中由L2范數正則化的協同表示問題可以通過矩陣法得到如下形式的解:
α*=(FTF+γI)-1FTfi.
(6)
令P=(FTF+γI)-1FT,因為P與樣本無關,可以預計算成一個投影矩陣,每當要計算待標注目標超像素si的系數α*時,只需將超像素的特征fi投影到矩陣P,無需再次計算P,所以運算速度非常快.
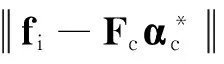
設計如下形式的數據項:
(7)
設計的基于CRC的數據項本質上是通過α*為目標超像素標簽源中的各個超像素分配了自適應的權重,充分考慮了標簽源中不同超像素對目標超像素的貢獻差異.與其他通過離線訓練來分配權重的方法[14]相比,本文的方法更加簡單、高效.
4.2MRF平滑項構建
本文算法的平滑項主要根據相鄰超像素間的相似度進行構建,結合二維圖像信息和三維幾何信息,構建如下形式的平滑項:
(8)
式中:φnor為相鄰超像素si與sj表面法向量的內積,是利用從深度圖中提取的表面法向量ni和nj,設計的一種新的平滑項.通常,表面法向量夾角大的相鄰超像素屬于相同語義類別的可能性較小,因此,設計該平滑項來對表面法向量夾角過大的相鄰超像素分配到相同的語義標簽進行懲罰.φfea利用相鄰超像素特征的相似度對語義標簽進行平滑,趨向于使特征相似的相鄰超像素具有相同的語義標簽,特征fi和fj的提取如前文所述,融合了二維圖像的顏色信息和三維圖像的幾何信息.φnor的內積形式本質上是一個夾角余弦函數,是普適的向量相似度的度量標準;φfea采用徑向基函數的形式,是普適的特征相似度的度量標準.因為兩者都是歸一化后的結果,具有可比性,共同平滑鄰域超像素語義標簽的平滑性.
5實驗結果與分析
5.1室內場景
首先在室內場景的NYU-V1數據集[5]上進行實驗.NYU-V1數據集[5]包含2 284幅由Kinect采集得到的480×640像素的圖像,每幅圖像對應有人工標注的語義標簽,經過WordNet的處理,將所有的語義標簽種類縮減至12個語義類別,除此之外的所有類別都歸到“背景”一類.在實驗過程中,隨機選取數據集中60%的圖像作為訓練集,剩下的40%作為測試集.根據12個語義類別的超像素在數據集中的占比,選取占比不超過3%的語義類別作為稀有類別,得到的稀有類別為“電視機”、“窗戶”、“沙發”、“床”和“墻畫”.
表1將本文算法與現有的幾個前沿場景理解算法進行像素準確率pp的性能對比.分析表1可以發現,不管與現有的參數化的RGB-D場景理解算法[6]還是非參數化的RGB場景理解算法[12]相比,該算法的像素準確率都得到了顯著的提高,在性能上取得了長足的進步.
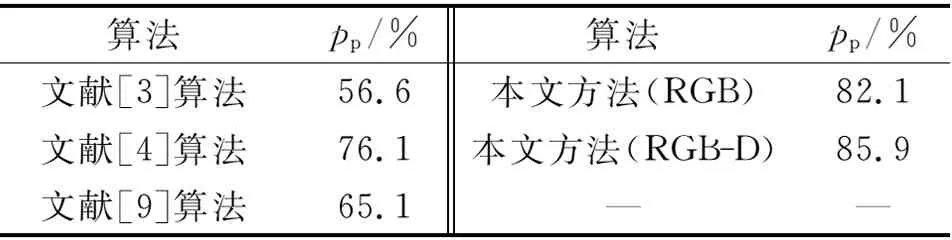
表1 像素準確率結果的對比
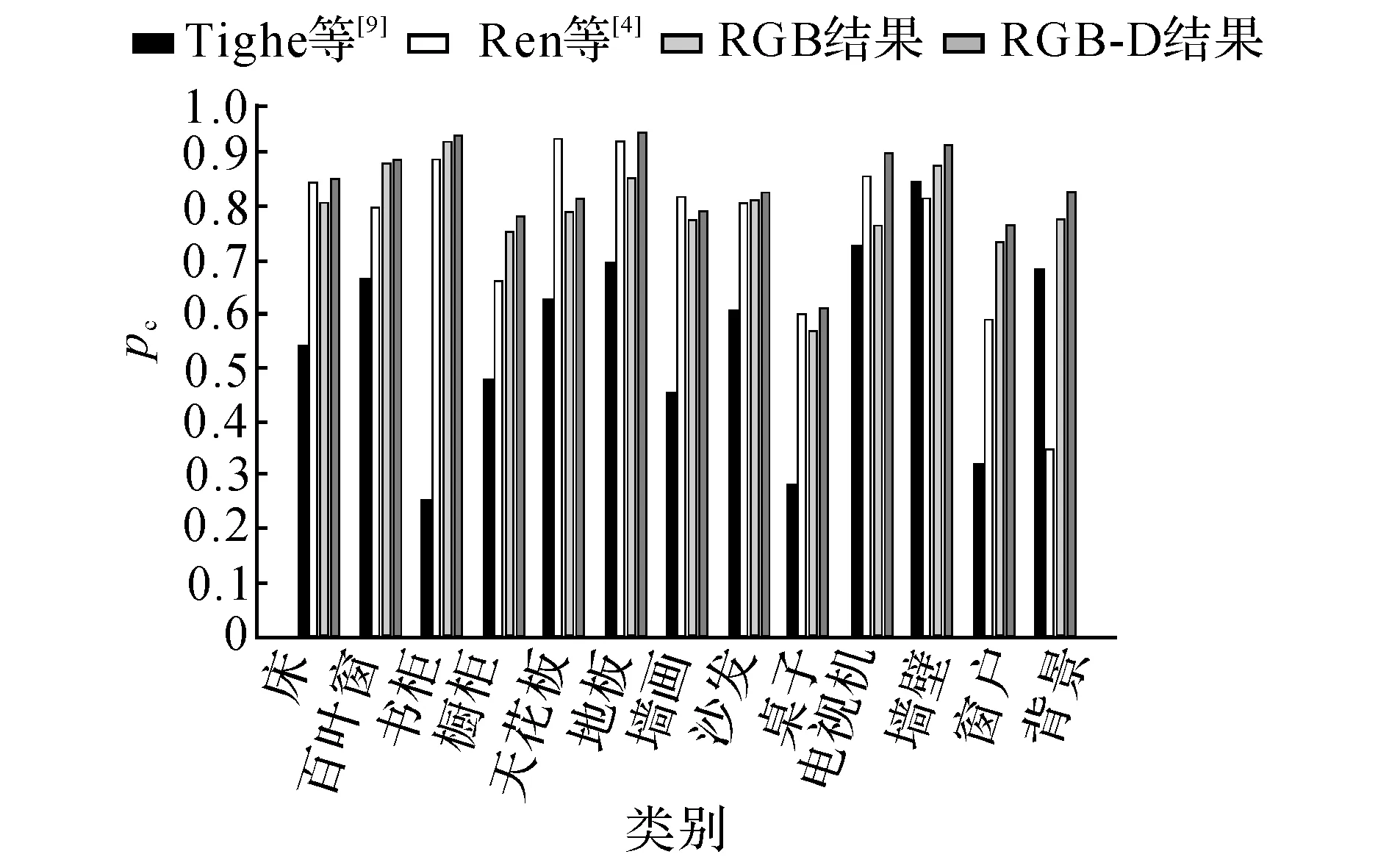
圖3 語義類別準確率的對比結果圖Fig.3 Comparative results of per-class accuracy
為了進一步分析該算法的優缺點,針對每個語義類別的準確率,與Ren等[6]提出的參數化RGB-D場景理解算法及Tighe等[12]提出的非參數化RGB場景理解算法進行比較.實驗結果如圖3所示.圖中,pc為語義類別準確率.對比圖3中該算法的RGB結果和RGB-D結果可以發現,在每個語義類別上,該算法在RGB-D上的準確率都比RGB上的準確率高,證明該算法對深度信息進行了有效利用.
對比本文算法的RGB-D結果與Ren等[6]的參數化RGB-D場景理解算法結果可知,本文算法取得了更高的準確率,原因在于該算法的非參數化機制,因為參數化方法需要對每個語義類別訓練模型,但即使屬于同一個語義類別的物體的特征也不盡相同,比如沙發有皮質的和布藝的,桌子有木質的和塑料的,顏色更是多種多樣,所以難以訓練出一個能夠表達所有樣本的模型.最典型的體現是在 “背景”這類,由于該類別表示的是許多語義類別的雜糅,而非單純的某一種語義類別,基于模型訓練的參數化方法無法為“背景”類別訓練生成一個具有語義意義的模型.即使有效結合了深度信息,Ren等[6]的參數化方法在這一類上仍然無法取得好的效果.本文的非參數化方法基于相似超像素之間的標簽傳遞,只要數據量足夠大,總是能夠找到與目標超像素足夠相似的樣本,進行準確的標簽傳遞.
與Ren等[6]提出的算法相比,在“天花板”和“墻畫”這兩個類別上沒有取得更好的效果.經過分析可以發現,在原始的數據集中,這兩個類別的人工標注存在較多的誤標注,即使對超像素進行了正確的匹配,也無法在標簽傳遞的過程中避免因為誤標注帶來的影響.與參數化方法[6]相比,本文算法對誤標注更敏感.
圖4列出了幾組典型的實驗結果圖.觀察圖4的第1組實驗結果圖可以發現,單純基于RGB的場景理解很難區分顏色相似、但分屬不同語義類別的物體,觀察第2和第3組實驗結果圖可以發現,單純的RGB場景理解難以處理光照昏暗的情況,而深度信息不受顏色和光照的影響,結合深度信息的RGB-D場景理解能夠有效地處理這些情況.
本文的場景理解方法在NYU-V1數據集中平均每張圖片的本地測試時間為149.8s,其中,核描述符的計算較慢, 單張圖片的平均用時占到了總用

圖4 NYU-V1數據集中的幾組典型實驗結果圖Fig.4 Typical examples from NYU-V1 dataset
時的一半,為79.5s.在相同的計算機配置下,文獻[6]的方法用作者官網上的原始代碼,在NYU-V1數據集上的總用時為4.92×105s,平均每張圖片需要用時538.5s.因為本文算法不需要訓練的過程,而且數據集的全局特征只需要計算一次存下來即可,基于CRC的馬爾科夫數據項的計算可以先對投影矩陣進行預計算,每計算一個超像素的協同系數,只需要進行一次投影,所以運算速度非常快.
5.2室外場景
本文算法能夠同時適用于室內、外場景,在室外場景的KIITI數據集[20]上進行簡單的實驗.隨機選取96張圖像作為測試集.KITTI數據集[20]中的圖像沒有給出對應的語義標簽,若通過全局特征匹配的方法選取標簽源,因為我們的算法是監督的,則需要事先對標簽源中的圖像進行人工標注,而像素級語義標簽的人工標注非常耗時,因為KITTI數據集是時序的,將測試集中每張圖像前面第3幀的圖像作為該圖像的標簽源,能夠達到減少不同場景干擾的目的.本文沒有另行計算測試集圖像的相似圖像檢索集和稀有類別詞典.
在RGB和RGB-D上分別進行實驗,在RGB上取得了89.8%的像素級準確率,在RGB-D上取得了93.9%的像素級準確率.圖5列出了幾組典型的室外場景的實驗結果圖.可以看出,本文算法在室外場景中取得了理想的效果.分析圖5可以發現,只利用RGB信息的場景理解,很難對室外場景的陰影部分進行準確的標記,而陰影在室外場景中是非常普遍的,加入深度信息后,陰影的問題得到了很好的解決.

圖5 KITTI數據集中的幾組典型實驗結果圖Fig.5 Typical examples from KITTI dataset
6結語
本文提出基于標簽傳遞機制的非參數化RGB-D場景理解方法.與傳統的參數化RGB-D場景理解方法相比,本文算法不需要繁瑣的訓練,不僅降低了運算成本,提升了運算速度,而且在準確率上得到了顯著的提高.與傳統的非參數化RGB場景理解方法相比,本文算法一方面有效結合了深度信息;另一方面,本文算法比傳統非參數化方法優越的地方在于:1)設計了雙向特征匹配機制,有效減少了傳統非參數化方法單向特征匹配產生的誤匹配;2)設計了基于CRC的匹配殘差的標簽傳遞機制,比基于kNN歐氏距離的標簽傳遞機制更好地描述了標簽源中不同超像素對目標超像素的貢獻差異,有效提升了算法的性能.
室內、外場景的實驗結果證明,提出的方法簡單高效,效果可靠.
參考文獻(References):
[1]Velodyne.Velodynehdl-64e[EB/OL]. [2014-06-10].http:∥velodynelidar.com/lidar/.
[2]Kinect.Microsoftkinect[EB/OL]. [2014-06-10].http:∥www.microsoft.com/enus/kinectforwindows/develop/learn.aspx.
[3] 閆飛, 莊嚴, 王偉. 移動機器人基于多傳感器信息融合的室外場景理解[J]. 控制理論與應用, 2011, 28(8):1093-1098.
YANFei,ZHUANGYan,WANGWei.Outdoorscenecomprehensionofmobilerobotbasedonmulti-sensorinformationfusion[J].ControlTheoryandApplications, 2011, 28(8):1093-1098.
[4] 譚倫正, 夏利民, 夏勝平. 基于多級Sigmoid神經網絡的城市交通場景理解[J]. 國防科技大學學報, 2012, 34(4): 1001-2486.
TANLun-zheng,XIALi-min,XIASheng-ping.Urbantrafficsceneunderstandingbasedonmulti-levelsigmoidalneuralnetwork[J].JournalofNationalUniversityofDefenseTechnology, 2012, 34(4): 1001-2486.
[5]SILBERMANN,FERGUSR.Indoorscenesegmentationusingastructuredlightsensor[C]∥ProceedingsofICCV.Barcelona:IEEE, 2011: 601-608.
[6]RENXiao-feng,BOLie-feng,FOXD.RGB-(D)scenelabeling:featuresandalgorithms[C]∥ProceedingsofCVPR.Providence:IEEE, 2012: 2759-2766.
[7]TORRALBAA,FERGUSR,FREEMANWT. 80milliontinyimages:alargedatasetfornon-parametricobjectandscenerecognition[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2008, 30(11): 1958-1970.
[8]SHOTTONJ,WINNJ,ROTHERC,etal.Textonboostforimageunderstanding:multi-classobjectrecognitionandsegmentationbyjointlymodelingtexture,layout,andcontext[J].InternationalJournalofComputerVision, 2009, 81(1): 2-23.
[9]FARABETC,COUPRIEC,NAJMANL,etal.Learninghierarchicalfeaturesforscenelabeling[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2013, 35(8): 1915-1929.
[10]STURGESSP,ALAHARIK,LADICKYL,etal.Combiningappearanceandstructurefrommotionfeaturesforroadsceneunderstanding[C] ∥ProceedingsofBMVC.London:BMVA, 2009.
[11]LIUCe,YUENJ,TORRALBAA.Nonparametricsceneparsing:labeltransferviadensescenealignment[C]∥ProceedingsofCVPR.Miami:IEEE, 2009: 1972-1979.
[12]TIGHEJ,LAZEBNIKS.Superparsing:scalablenonparametricimageparsingwithsuperpixels[C] ∥ProceedingsofECCV.Heraklion:Springer, 2010: 352-365.
[13]YANGJ,PRICEB,COHENS,etal.Contextdrivensceneparsingwithattentiontorareclasses[C] ∥ProceedingsofCVPR.Columbus:IEEE, 2014.
[14]EIGEND,FERGUSR.Nonparametricimageparsingusingadaptiveneighborsets[C] ∥ProceedingsofCVPR.Providence:IEEE, 2012: 2799-2806.
[15]ZHANGLie,YANGMeng,FENGXiang-chu.Sparserepresentationorcollaborativerepresentation:whichhelpsfacerecognition? [C] ∥ProceedingsofICCV.Barcelona:IEEE, 2011: 471-478.
[16]BOYKOVY,VEKSLERO,ZABIHR.Fastapproximateenergyminimizationviagraphcuts[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2001, 23(11): 1222-1239.
[17]OLIVAA,TORRALBAA.Buildingthegistofascene:theroleofglobalimagefeaturesinrecognition[J].ProgressInBrainResearch, 2006, 155: 23-36.
[18]LEVINSHTEINA,STEREA,KUTULAKOSNK,etal.Turbopixels:fastsuperpixelsusinggeometricflows[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2009, 31(12): 2290-2297.
[19]BOLie-feng,RENXiao-feng,FOXD.Kerneldescriptorsforvisualrecognition[C] ∥NIPS.Vancouver:NeuralInformationProcessingSystemsFoundation, 2010: 244-252.
[20]GEIGERA,LENZP,URTASUMR.Arewereadyforautonomousdriving?theKITTIvisionbenchmarksuite[C] ∥ProceedingsofCVPR.Providence:IEEE, 2012: 3354-3361.
收稿日期:2015-05-13.浙江大學學報(工學版)網址: www.journals.zju.edu.cn/eng
作者簡介:費婷婷(1990-),女,碩士生,從事機器視覺研究.ORCID: 0000-0003-1924-426X.E-mail:21231083@zju.edu.cn 通信聯系人:龔小謹,女,副教授.ORCID:0000-0001-9955-3569.E-mail:gongxj@zju.edu.cn
DOI:10.3785/j.issn.1008-973X.2016.07.014
中圖分類號:TP 391
文獻標志碼:A
文章編號:1008-973X(2016)07-1322-08
NonparametricRGB-DsceneparsingbasedonMarkovrandomfieldmodel
FEITing-ting,GONGXiao-jin
(Department of Information Science and Electronic Engineering, Zhejiang University, Hangzhou 310027, China)
Abstract:An effective nonparametric method was proposed for RGB-D scene parsing. The method is based upon the label transferring scheme, which includes label pool construction, bi-directional superpixel matching and label transferring stages. Compared to traditional parametric RGB-D scene parsing methods, the approach requires no tedious training stage, which makes it simple and efficient. In contrast to previous nonparametric techniques, our method not only incorporate geometric contexts at all the stages, but also propose a bi-directional scheme for superpixel matching in order to reduce mismatching. Then a collaborative representation based classification (CRC) mechanism was built for Markov random field (MRF), and parsing result was achieved through minimizing the energy function via Graph Cuts. The effectiveness of the approach was validated both on the indoor NYU Depth V1 dataset and the outdoor KITTI dataset. The approach outperformed both state-of-the-art RGB-D parsing techniques and a classical nonparametric superparsing method. The algorithm can be applied to different scenarios, having a strong practical value.
Key words:scene parsing; nonparametric; RGB-D; Markov random field (MRF)
