中文信息處理研究現(xiàn)狀分析
2016-05-30 10:48:04宗成慶
語言戰(zhàn)略研究 2016年6期

提 要 60多年來中文信息處理研究取得了令人矚目的成就。但是,這一領域也面臨問題和挑戰(zhàn)。本文在對中文信息處理研究成就簡要歸納的基礎上,分析這一領域的技術現(xiàn)狀,直面存在的問題,并對未來發(fā)展的方向提出一些看法。希望本文指出的問題能夠引起中國國內(nèi)同行的關注,為未來的中文信息處理研究提供有益的參考。
關鍵詞 中文信息處理;自然語言處理;自然語言理解;計算語言學
Abstract In the past over 60 years, research on Chinese language processing has made great achievements. With the rapid development and popularization of the Internet and communication technology, Chinese language processing technology has attracted worldwide attention in recent years. This article summarizes the achievements of Chinese language processing and analyzes the present status of the technology in this field, particularly the problems that the field may face in term of development. The author argues that it is still difficult for artificial intelligence to “understand” rather than “process” naturally produced Chinese because of the following three reasons: (1) the current information processing technology is inadequate in processing grammatically complex Chinese sentences; (2) there are unsolved problems in machine learning technologies; and (3) our understanding of how human brain processes language is still very limited. This paper concludes that we need a better understanding of how the Chinese language is decoded in human brain and build a computational model that specifically targets at the Chinese language in order for artificial intelligence to understand naturally produced Chinese.
Key words Chinese language processing; natural language processing; natural language understanding; computational linguistics
一、引 言
自1956年人工智能(artificial intelligence,簡稱AI)概念被提出以來,自然語言理解(natural language understanding,簡稱NLU)就一直是這一領域研究的核心問題之一。盡管20世紀60年代提出的計算語言學(computational linguistics,簡稱CL)和80年代衍生的自然語言處理(natural language processing,簡稱NLP)概念分別從數(shù)學建模和語言工程角度各自詮釋了不同的外延,但NLU、CL和NLP這三個術語的實質(zhì)內(nèi)容和共同面對的科學問題并無本質(zhì)的差異,尤其從實際應用的角度看,幾乎一樣。因此,在不引起混淆的情況下人們常以“人類語言技術”(human language technology,簡稱HLT)泛指這一語言學、計算機科學和人工智能等多學科交叉的研究領域(宗成慶 2013)。
中文信息處理(Chinese language processing,簡稱CLP)是指針對中國的語言文字開展相關研究的一個專屬領域,是自然語言處理的一個具體分支。廣義上講,“中文”是中國各民族使用的語言文字的總稱,在不引起誤解的情況下,“中文”與“漢語”指的是同一概念。隨著中國綜合國力的增強,以互聯(lián)網(wǎng)為紐帶的經(jīng)濟和信息全球化趨勢,尤其是中國“一帶一路”戰(zhàn)略的實施,向包括中文信息處理在內(nèi)的人類語言技術提出了前所未有的挑戰(zhàn),巨大的技術市場吸引著全球科學家和企業(yè)家的目光(宗成慶等 2009)。
與其他語言的處理技術相比,中文信息處理處于怎樣的技術水平?近年來,中文信息處理從資源庫建設、理論建樹,到技術研發(fā)和人才隊伍培養(yǎng),有哪些根本性的變化?在相關學科快速發(fā)展的新形勢下,中文信息處理研究又將何去何從?本文將在簡要歸納中文①信息處理研究所取得成就的基礎上,分析當前的技術狀況,直面存在的問題,并對未來發(fā)展的方向提出看法。希望本文指出的問題能夠引起中國國內(nèi)同行的關注,為未來的中文信息處理研究提供有益的參考。
二、中文信息處理研究的進展與現(xiàn)狀
從1949年新中國成立前后的語言文字改革算起,到20世紀70年代中期開始的漢字編碼和輸入法研究,再到今天網(wǎng)絡時代的全方位、大規(guī)模中文信息處理技術研究、開發(fā)和應用,中文信息處理走過了60多年的曲折歷程。在半個多世紀的發(fā)展過程中幾代人付出了艱苦的努力,一系列國家標準、規(guī)范和理論模型及應用系統(tǒng)應運而生。概括起來,這些成果可以歸納為如下幾個方面(宗成慶、高慶獅 2008;宗成慶等 2009):
(1)漢字簡化與規(guī)范化工作基本完成,漢語拼音方案被國際標準化組織(ISO)接納,漢語拼音正詞法規(guī)則已成為國家標準。
(2)漢字編碼、輸入/輸出、編輯、排版等相關技術已經(jīng)解決,亞偉中文速錄機和漢字激光照排、印刷系統(tǒng)已被大規(guī)模產(chǎn)業(yè)化應用。
(3)面向信息處理的漢語分詞規(guī)范已經(jīng)制定,以“綜合型語言知識庫”和知網(wǎng)(HowNet)②為典型代表的一批漢語資源庫(包括語料庫、詞匯知識庫、語法信息詞典等)相繼建成。
(4)漢語詞語自動切分、命名實體識別、句法分析、詞義消歧、語義角色標注和篇章分析等自然語言處理的基礎問題得到全面研究和推進,一系列不斷改進的模型和方法被相繼提出,一大批高質(zhì)量的研究論文發(fā)表在國際一流的學術會議和權威期刊上。
(5)機器翻譯、信息檢索、輿情監(jiān)測、語音識別和語音合成等應用技術在眾多互聯(lián)網(wǎng)企業(yè)、國家特定領域和機構中得到實際應用,對推動國民經(jīng)濟發(fā)展、提高信息化服務水平和維護國家安全發(fā)揮了重要作用。
另外值得提及的是,由國家語言文字工作委員會發(fā)布的“中國語言生活綠皮書”③正在為國家語言文字工作方針政策提供參考,為語言文字研究者、語言文字產(chǎn)品研發(fā)者和社會其他人士提供語言服務,引領社會語言生活走向和諧(李宇明 2007)。
隨著計算機和互聯(lián)網(wǎng)技術的快速發(fā)展和普及,中文信息處理遇到了前所未有的大好時機。根據(jù)聯(lián)合國對世界主要語種、分布與應用力調(diào)查的結果,世界十大語言依次是:英語、漢語、德語、法語、俄語、西班牙語、日語、阿拉伯語、韓語(朝鮮語)、葡萄牙語。而中國互聯(lián)網(wǎng)絡信息中心(CNNIC)發(fā)布的《第21次中國互聯(lián)網(wǎng)絡發(fā)展狀況統(tǒng)計報告》表明,中國互聯(lián)網(wǎng)上有87.8%的內(nèi)容是文本。2014年7月21日CNNIC發(fā)布的《第34次中國互聯(lián)網(wǎng)絡發(fā)展狀況統(tǒng)計報告》顯示,截止到2014年6月,中國網(wǎng)民規(guī)模達6.32億。這些數(shù)據(jù)清楚地告訴我們這樣一個不爭的事實:無論從政治、經(jīng)濟、文化、軍事和安全等政府關注的角度看,還是從商貿(mào)、旅游和信息服務等商業(yè)市場因素考慮,中文信息處理已經(jīng)成為國際互聯(lián)網(wǎng)和移動通信平臺上獲取和傳遞信息難以繞開的技術結點。不僅IBM、微軟、谷歌等世界巨頭公司投入了大量的人力和財力瞄準中國市場開展相關技術研究,斯坦福大學、賓夕法尼亞大學、加州大學伯克利分校等國際一流大學也為中文信息處理研究做出了卓著貢獻,他們開發(fā)的漢語分詞系統(tǒng)、句法分析器和命名實體識別工具等,以及LDC漢語語料庫④(包括分詞、句法樹和篇章語料庫等)得到廣泛應用。這意味著,中文信息處理不僅是中國學者關注的問題,而且已經(jīng)成為國際學術界和企業(yè)界共同研究的課題。
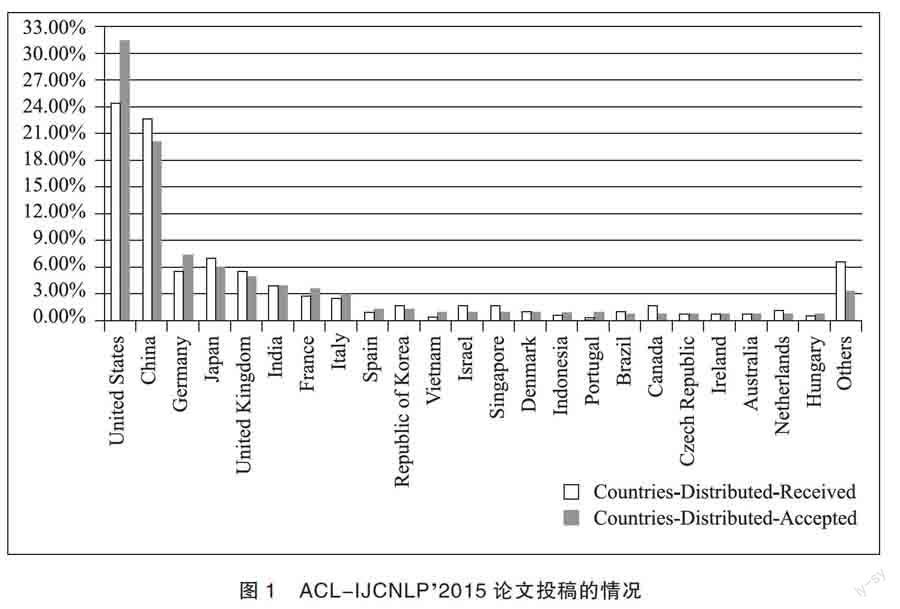
近年來中國的自然語言處理研究水平迅速提升,大陸學者在HLT相關領域的國際一流學術會議和期刊上發(fā)表的論文數(shù)量不斷增長。圖1是2015年第53屆國際計算語言學學會年會與第7屆自然語言處理國際聯(lián)合會議(ACL-IJCNLP)⑤投稿和被接受的論文數(shù)量按國家或地區(qū)分布的直方圖:
ACL-IJCNLP2015分為主會和專題研討會兩種。其中,主會是ACL大會的主體,它以論文質(zhì)量高、錄用率低、影響力大而著稱。每年該會錄用論文的數(shù)量通常被看作是一個國家或地區(qū)在本領域整體水平和實力的象征。ACL-IJCNLP2015主會共收到長文投稿692篇,錄用173篇;收到短文投稿648篇,錄用145篇。也就是說,長文和短文合計投稿量為1340篇,錄用318篇,錄用率約為23.7%。從圖1可以看出,在1340篇投稿中第一作者來自中國大陸的論文數(shù)量占到了22.7%,僅次于美國(24.5%)。值得注意的是,即使是來自美國的投稿,第一作者也有可能是中國學者,包括眾多留美的中國學生。據(jù)統(tǒng)計,在被錄用的318篇論文中第一作者為中國人的論文數(shù)量約占37.1%。換句話說,超過三分之一被錄用的論文出自中國人之手。
除了ACL會議以外,國際計算語言學大會(International Conference on Computational Linguistics, 簡稱COLING)⑥、國際人工智能聯(lián)合會議(International Joint Conference on Artificial Intelligence, 簡稱IJCAI)、ACM 信息檢索大會(Special Interest Group on Information Retrieval,簡稱SIGIR)和ACM信息與知識管理國際會議(International Conference on
Information and Knowledge Management,簡稱CIKM)等其他相關的一流學術會議都已登陸中國。
與此同時,中國的自然語言處理人才隊伍迅速成長,一批優(yōu)秀的學者在國際一流學術會議和權威學術機構中擔任重要職務。2013年王海峰博士出任ACL主席,同年宗成慶當選國際計算語言學委員會⑦委員,2014年和2015年吳華博士和宗成慶分別擔任第52屆和53屆ACL大會程序委員會共同主席,2016年趙世奇博士出任ACL秘書長。還有一大批優(yōu)秀的中國學者在各類一流國際學術會議上擔任組委會主席、領域主席、講座主席和出版主席等。
毋庸置疑,中國學者已經(jīng)成為國際HLT領域一支舉足輕重的生力軍。除了自身的努力以外,很重要的一個原因是國家綜合實力的增強。國家不斷增加的科研經(jīng)費投入使更多的學者有機會走出國門,并把更多優(yōu)秀的國外學者(包括學有所成的海外華人)請到中國來。當然,互聯(lián)網(wǎng)技術起了非常重要的作用。借助于互聯(lián)網(wǎng),任何人都可以隨時隨地地查閱學術資料,實時了解和跟蹤最新的國際研究動態(tài),從而把握正確的研究方向。另外,以IBM、微軟公司、谷歌等為代表的國際大公司在中國大陸開設的研究機構,也對相關領域的技術發(fā)展和人才培養(yǎng)起到了推波助瀾的作用。他們與中國科研機構和高校的密切交流與合作,使更多的青年學生有機會在高水平的技術平臺上利用公司特有的計算資源和數(shù)據(jù)資源快速地學習和實踐先進的技術。當然,這些公司是人才培養(yǎng)和市場開拓的受益者。
三、現(xiàn)狀分析與問題思考
從中文信息處理發(fā)展現(xiàn)狀來看,近20年是該領域迅速崛起和中國學者在國際舞臺發(fā)揮作用的黃金時期。那么,這些豐碩的成果是否意味著中文信息處理的理論方法已經(jīng)具有根本性的建樹呢?
眾所周知,自然語言處理方法有理性主義方法和經(jīng)驗主義方法兩大流派。理性主義方法通常以喬姆斯基(Noam Chomsky)的語法理論為基礎,建立基于規(guī)則和知識庫的邏輯推理系統(tǒng)。而經(jīng)驗主義方法則以數(shù)理統(tǒng)計和信息論為基礎,實現(xiàn)基于大規(guī)模語料庫的統(tǒng)計機器學習方法。兩種方法的融合正在成為人們探索的第三條路徑。這些方法在目前的自然語言處理系統(tǒng)中都發(fā)揮了重要作用,但是,計算機要從中文信息“處理”走向真正的“理解”還有很長的路要走,在這條遙遠的征途上至少需要跨越三條鴻溝:(1)建立符合中文(這里尤指漢語)語言特點的自然語言處理理論體系;(2)設計更加有效的機器學習算法和模型;(3)揭示和發(fā)現(xiàn)人類大腦理解語言的基本機理。
(一)現(xiàn)有中文信息處理方法的局限性
目前采用的中文信息處理方法和評價標準大都是從英語等西方語言的處理方法中借鑒過來的,無論是基于規(guī)則的方法,還是基于統(tǒng)計的方法,從來都沒有針對漢語本身的特點“量身定做”。例如,傳統(tǒng)的自然語言處理方法通常從詞法分析(漢語詞語自動切分)開始,到句法分析、語義分析,分階段逐步進行,不同層次的任務往往是獨立完成的。句法分析(syntactic parsing)是其中的關鍵環(huán)節(jié),其任務是將給定的句子自動解析成完整的句法分析樹。它的基本假設是每一個句子的句法結構都能夠用一棵完整的句法分析樹表示,如圖2所示。
圖2 句子“我讀書。”的句法分析樹
但是,這一假設對于漢語而言往往不能成立,至少是非常苛刻的。漢語句子中通常不使用標識結構信息的專用詞匯(如英語復句中的which, that, where等引導詞),是一種語義驅(qū)動的松散結構,句法和語義之間存在著千絲萬縷的關系,而且漢語中標點的使用也不像英語那樣有嚴格的限制。例如:
(1)我喜歡在春天去觀賞桃花,在夏天去欣賞荷花,在秋天去觀賞紅葉,但更喜歡在冬天去欣賞雪景。
這是一個典型的流水句。根據(jù)我們對隨機抽取出的4431個長度超過20個詞的句子的統(tǒng)計,有1830個流水復句,占全部長句的41.3%(李幸、宗成慶 2006)。流水句結構看起來比較松散,但語義上卻有緊密的聯(lián)系。如果非要用一棵完整的句法樹表示這種句子的結構,不僅在實現(xiàn)上非常困難,而且對達到語言理解的目標幾乎沒有太多幫助。過去幾十年里,人們提出了大量自動句法分析的算法,目前比較著名的句法分析工具有:Collins Parser、Bikel Parser、Charniak Parser、Berkeley Parser、Stanford Parser、MST Parser、MaltParser和MINIPAR Parser等。但這些系統(tǒng)在規(guī)范的漢語文本上最好的句法分析性能(短語準確率)也只有86%左右,而日語和英語的句法分析性能已經(jīng)超過90%。即使C. Dyer 和M. Ballesteros等人近期實現(xiàn)的基于神經(jīng)網(wǎng)絡的句法分析方法的性能得到了進一步提升(Ballesteros et al. 2015;Dyer et al. 2015),漢語句法分析器的性能仍然比英語的低5個百分點左右。
對于篇章結構分析來說,目前廣泛采用的篇章理論包括修辭結構理論、中心理論、脈絡理論、篇章表示理論和言語行為理論等(宗成慶 2013),而這些理論無一例外地來自西方語言學。漢語的篇章結構與英語有明顯的區(qū)別,這是大家所共知的事實。根據(jù)我們對2016年國際計算自然語言學習會議(Conference on Computational Natural Language Learning,簡稱CoNLL)發(fā)布的漢英篇章論元關系分析評測任務的語料統(tǒng)計,漢語中非顯式的篇章單元之間的關系占到了78.3%,遠遠超過了英語篇章中54.5%的比例。漢語中篇章單元之間可使用的連接詞有385個之多,而英文中只有100個左右(Kang et al. 2016)。而且漢語中的標點逗號可以隱含地表示某種篇章單元關系,例如表示前后兩個單元之間隱含的轉(zhuǎn)折、讓步、因果等關系,而英語的標點不具備這樣的功能。所有這些差異都清楚地提醒我們,漢語需要建立自己的篇章分析理論。
值得慶幸的是,國內(nèi)已有專家在漢語篇章分析理論研究方面進行卓有成效的探索,如宋柔(2012)提出的“廣義話題結構理論”、王德亮(2004)研究的“篇章向心理論”等,但離建立相對成熟和完善的漢語篇章理論體系還有較遠的距離。
另外,漢語中的指代消歧也是中文信息處理面臨的棘手問題。請看如下兩個例句:
(2)夫人穿著很得體,舉止優(yōu)雅,左臂上掛著一個暗黃色的皮包,右手領著一只白色的小狗,據(jù)說是京巴。
(3)夫人穿著很得體,舉止優(yōu)雅,左臂上掛著一個暗黃色的皮包,右手領著一只白色的小狗,據(jù)說是局長的太太。
在這兩個句子中除下劃線標識的部分以外,其余部分完全一樣,但“據(jù)說”的所指完全不同,一個是指“小狗是京巴”,而另一個則是指“夫人是局長的太太”。這種表達方式在英文中是不可能出現(xiàn)的。
綜上所述,不同語言具有不同的特點,無論在詞法、句法、語義等不同的層面上,還是在詞匯、短語、句子和篇章等不同的語言單位上,有共性,也有差異,尤其語義與語言的文化背景密切相關。我們認為,不存在與語言無關的自然語言處理方法和全世界語種通用的自然語言處理理論體系。最終要解決中文信息處理的問題,使其真正實用化,必需建立適合中文語言特點的理論體系。
(二)現(xiàn)有機器學習方法的缺陷
20世紀80年代末期、90年代初期以來,統(tǒng)計機器學習方法逐漸興起,并成為當前自然語言處理領域的主流方法。其基本思路是,基于大規(guī)模人工標注的語料樣本建立數(shù)學模型,通過調(diào)試模型的參數(shù)使其達到最優(yōu)(這一過程稱作模型的訓練過程)。所建的數(shù)學模型就像一個小學生,標注的語料則是老師為學生提供的樣例,而訓練過程則類似于老師教小學生如何按照樣例學習句子分析方法或完成其他任務的過程。最終小學生的成績?nèi)绾稳Q于學生本身的能力、樣例規(guī)模的大小和學生學習的技巧,對應地,統(tǒng)計模型的性能好壞取決于數(shù)學模型本身、訓練樣本規(guī)模的大小和模型參數(shù)的調(diào)試情況。
序列標注方法是自然語言處理中常用的一種典型的機器學習方法。以漢語自動分詞為例,序列標注方法的基本思路是:每個“字”(包括字符、數(shù)字、標點等文本中出現(xiàn)的任何符號)只有4種可能的身份出現(xiàn)在文本中,即詞首字(B)、詞尾字(E)、詞中間字(M)和單字詞(S)。對于給定的文本,如果能夠?qū)γ總€“字”打上一個標簽(B、E、M或S中的任意一個),那么分詞任務就完成了。被標記為B和E的“字”及其之間標以M的“字”(如果有的話)構成一個分詞單位,被標記為S的“字”獨立成詞。例如,句子“我喜歡讀書。”的序列標注結果為:我/S 喜/B 歡/E 讀/S 書/S 。最終的分詞結果就是:我/ 喜歡/ 讀/ 書/ 。
在為每個“字”打標簽的過程中,依據(jù)當前“字”的上下文計算對當前“字”貼上某種標簽的條件概率,選擇概率最大的候選標簽。實際上這是一種通過上下文分類進行標簽選擇的方法,稱為區(qū)分式方法。確定上下文多大范圍內(nèi)、哪些因素可作為計算概率的條件的過程,則稱作特征選擇。
類似地,命名實體識別、語塊識別和篇章單元識別等,都可采用這種方法實現(xiàn)。
統(tǒng)計方法的優(yōu)點不言而喻,它避免了基于規(guī)則的方法中由于人工編寫規(guī)則的主觀性因素可能導致的語言現(xiàn)象覆蓋面小甚至錯誤的情況。有些自然語言處理任務(如機器翻譯)并不需要人工標注語料,這就大大地減少了系統(tǒng)對人的依賴性,極大地提高了系統(tǒng)開發(fā)的效率。這也是統(tǒng)計方法備受青睞的重要原因之一。但是,目前的統(tǒng)計方法仍然存在若干問題和不足。歸納起來,這些缺陷包括:
1. 模型性能過于依賴訓練樣本
根據(jù)上面的介紹,訓練樣本的質(zhì)量和規(guī)模對模型最終的性能起著至關重要的作用。一般而言,如果樣本的規(guī)模太小,或者樣本的質(zhì)量太差,模型的性能肯定不好。人工標注大規(guī)模訓練樣本同樣是一件艱苦的工作,而且標注樣本往往難以隨著語言使用情況的變化而自動調(diào)整。即使機器翻譯等任務不需要人工標注的訓練樣本,但仍然需要樣本的數(shù)量達到足夠的規(guī)模,這對于有些領域或語言對來說是無法做到的。例如,波斯語與漢語之間的自動翻譯系統(tǒng)就很難收集到大規(guī)模波斯語與漢語句子級雙語平行語料,即使在新聞等公共領域,收集幾十萬句對都是困難的,更不必說在某些特定領域。
2. 固化的模型參數(shù)導致模型無法處理“陌生”的語言現(xiàn)象
在統(tǒng)計方法中模型一旦被訓練完成,參數(shù)是被固化的,對于超出特征預設范圍的語言現(xiàn)象完全無能為力。例如,在詞義消歧任務中我們通常根據(jù)歧義詞出現(xiàn)的上下文建立分類模型,由上下文決定詞語的語義。以“打”字的詞義消歧為例,“打”字做實詞用時有多個含義,“打毛衣”“打電話”和“打籃球”等不同表達中“打”字的含義各不相同,因此可以設定“打”字前后一定范圍內(nèi)的上下文詞作為分類特征構建分類模型。假如設定上下文窗口范圍為±1(即在當前詞前后一個詞的窗口范圍內(nèi)),大多數(shù)情況下“打”字的含義都可以區(qū)分出來。但是,對于超出窗口范圍的情況模型便無能為力了。例如,在句子“張三打了一壺紹興老酒。”中,“打”字與“老酒”之間間隔4個詞,這就很可能導致模型誤判“打”的詞義。
3. 缺乏領域自適應能力
模型對訓練語料所在領域的語言現(xiàn)象處理可能表現(xiàn)出較好的性能,但一旦超出領域范圍或測試集與訓練樣本有較大差異,模型性能將大幅度下降。例如,在標注的大規(guī)模《人民日報》分詞語料上訓練出來的漢語詞語自動切分模型的準確率可達96%左右,甚至更高,但在微博等非規(guī)范文本基礎上訓練出的分詞性能至少要低5個百分點左右。在LDC漢語樹庫上訓練出來的句法分析系統(tǒng)準確率可達86%左右,但在非規(guī)范網(wǎng)絡文本上的分析準確率只有60%左右(宗成慶 2013)。統(tǒng)計模型對領域自適應能力的缺乏嚴重制約了該方法的應用。
4. 難以通過人機交互自動完成參數(shù)更新
人類在語言學習中可以通過人際之間和人與自然界之間的不斷交互主動學習新的知識(包括語言知識和生活常識等),從而不斷提高語言學習和理解的能力,但對于目前的統(tǒng)計自然語言處理系統(tǒng)而言卻無法做到這一點。如何使系統(tǒng)通過人機交互過程,自動根據(jù)語用信息判別和提取有用的知識,完成模型參數(shù)的自動更新,以達到模型性能不斷提高的效果,到目前為止還需探索。
5. 常識學習與歸納推理能力亟待提高
現(xiàn)有的統(tǒng)計學習方法在局部問題求解上可以達到較好的技術水平,但是在整體歸納和全局抽象方面卻顯得力不從心。例如,有如下一則新聞報道:
張小五從警20多年來,歷盡千辛萬苦,立下無數(shù)戰(zhàn)功,曾被譽為孤膽英雄。然而,誰也未曾想到,就是這樣一位曾讓毒販聞風喪膽的鐵骨英雄竟然為了區(qū)區(qū)小利而精神崩潰,悔恨之下昨晚在家開槍自斃。
對這則新聞目前的詞語自動切分準確率可達96%以上,命名實體(人名“張小五”)識別和句間關系分析(關鍵詞“然而”引起的轉(zhuǎn)折),甚至語義角色標注等,都沒有太大問題,準確率至少可達85%以上。但是,對于一個自動問答系統(tǒng)來說,要正確地回答“張小五是什么警察?死了沒有?”等,恐怕非常困難,因為它無法建立起“毒販”與“緝毒警察”之間的對應關系,也不會知道“自斃”與“死亡”的必然聯(lián)系。當前中文信息處理系統(tǒng)的常識學習和歸納推理能力亟待提高。
宏觀上講,統(tǒng)計是一種“賭博”方法,決策的依據(jù)是概率值大小,一定程度上有點“撞大運”的味道。其基本假設是:樣本中蘊含著全部與特定自然語言處理任務相關的知識,而且處理任務(測試集)與訓練樣本符合同樣的規(guī)律,只要有足夠多的訓練樣本,模型就能夠?qū)W習到相應的知識,并對待處理集進行正確的分析。且不說如何擁有“足夠多”、多到多大規(guī)模的訓練樣本,只就模型本身的學習能力、區(qū)分能力和自適應能力等方面而言,還遠無法與人腦的自然語言理解能力相比較。
(三)自然語言研究需要與腦神經(jīng)科學和認知科學相結合
近年來,類人智能和類腦計算備受矚目,尤其AlphaGo圍棋系統(tǒng)戰(zhàn)勝人類選手以來,人工智能被再度推向媒體輿論和學術研究的風口浪尖。但是,對于人腦是如何完成自然語言理解過程的,比如為什么一個三歲的兒童在學習一個新的詞項時,父母只需做簡單的解釋,給出一兩個例子,孩子就可以理解并使用所學的詞項,而且基本不會用錯,根本不需要大量的訓練樣本,目前尚無法給出非常清楚、合理的解釋。
近年來基于神經(jīng)網(wǎng)絡的深度學習方法備受推崇,它在某種意義上的確模擬了人腦的認知功能,但是,這種方法只是對神經(jīng)元結構和信號傳遞方式給出的形式化數(shù)學描述,并非是基于人腦的工作機理建立起來的數(shù)學模型,同樣難以擺脫對大規(guī)模訓練樣本的依賴。
目前人們只是在宏觀上大致了解腦區(qū)的劃分和在語言理解過程中所起的不同作用,但在介觀和微觀層面,語言理解的生物過程與神經(jīng)元信號傳遞的關系,以及信號與語義、概念和物理世界之間的對應與聯(lián)系等,都是未知的。如何打通宏觀、介觀和微觀層面的聯(lián)系并給出清晰的解釋,將是未來需解決的問題。從微觀層面進一步研究人腦的結構,發(fā)現(xiàn)和揭示人腦理解語言的機理,借鑒或模擬人腦的工作機理并建立形式化的數(shù)學模型才是最終解決自然語言理解問題的根本出路。這需要與語言學家、腦神經(jīng)科學家和認知科學家的共同努力和協(xié)作。
30多年來自然語言處理研究成績斐然,但中文信息處理的理論研究和技術創(chuàng)新卻有弱化之勢。近年來中文信息處理技術性能的提高在很大程度上源自數(shù)據(jù)規(guī)模的擴大和計算機硬件性能的提高,在理論方法和數(shù)學模型上并沒有太多的建樹,真正面向漢語的計算理論和實現(xiàn)技術似乎并不多見。
在ACL-IJCNLP2015錄用的318篇論文中,115篇是關于深度學習方法的,約占36.2%。而深度學習方法的熱度仍在持續(xù)升高,2016年會議錄用的論文中與深度學習方法相關的論文比例再創(chuàng)新高。但是,如此大量的論文中,有多少還在關注漢語呢?據(jù)對ACL-IJCNLP2015投稿論文的統(tǒng)計,在形態(tài)分析專題領域的28篇投稿(包括長文和短文)中,關于中文詞語切分(中文信息處理的經(jīng)典問題)的論文僅有6篇,其中包括一篇關于藏語分詞的論文,而句法分析專題領域的全部108篇投稿中,只有22篇是研究漢語句法分析方法的。所有這些稿件都無一例外地采用了統(tǒng)計方法,它們的貢獻基本是在別人提出的模型的基礎上,做些特征選擇和參數(shù)調(diào)整等方面的改進工作,在中文信息處理的理論創(chuàng)新方面鮮有建樹。
近幾年來隨著國內(nèi)指標(SCI/SSCI論文數(shù)量、引用次數(shù)、高被引論文數(shù)等)導向的各種學術評估愈演愈烈,很多研究開始一味地跟蹤熱點、追逐新潮,只是為了早出成果、快發(fā)論文,而最終忘記了解決中文語言理解這一問題的根本目標。這正是我們擔憂的關鍵所在。
四、結束語
過去60多年中,中文信息處理取得了令人振奮的成果,尤其在統(tǒng)計方法成為主流方法之前,老一代學者創(chuàng)建了一系列面向漢語特點的理論方法和實用技術,并為中文語言資源庫建設做出了卓越貢獻,人才培養(yǎng)和隊伍建設成就顯著。而當統(tǒng)計方法一統(tǒng)天下之后,對語言學特性和認知規(guī)律的研究在自然語言處理領域并沒有得到應有的重視。其實,早在10多年前有關專家就已經(jīng)通過腦功能成像技術研究證明,漢英兩種語言的名詞和動詞在人腦中的表征并不完全一樣(Li et al. 2004)。如何針對漢語自身的特點和規(guī)律建立專用的模型和算法,恐怕才是最終解決漢語理解問題的正確出路。
總體而言,目前計算機處理自然語言的能力僅僅停留在“處理”層面,還遠不能達到“理解”的水平,未來的任務艱巨而充滿挑戰(zhàn)。跟蹤國際前沿是每一位科研工作者應有的素質(zhì)和理念,但是,在學習和跟蹤國際先進技術的同時,無論如何都不應該喪失以解決我們母語問題為目標的創(chuàng)新意識。
注 釋
① 本文接下來討論的中文信息處理研究現(xiàn)狀和趨勢,主要指漢語信息處理的技術狀況。
② 參見http://www.keenage.com/html/c_index.html。
③ 第一部“中國語言生活綠皮書”——《中國語言生活狀況報告(2005)》于2006年9月18日正式出版。此后每年發(fā)布一次,持續(xù)至今。
④ https://www.ldc.upenn.edu/。
⑤ ACL是國際計算語言學學會(Association for Computational Linguistics)的縮寫。該學會成立于1962年,第一屆ACL年會于1963年8月在美國召開,目前是本領域最具影響力和權威性最高的頂級學術會議,被中國計算機學會(CCF)認定為A類會議。第53屆ACL年會與亞洲自然語言處理聯(lián)合會(The Asian Federation of Natural Language Processing,簡稱AFNLP)第7屆自然語言處理國際聯(lián)合會議(The 7th International Joint Conference on Natural Language Processing,簡稱IJCNLP)于2015年7月26日至31日在北京舉辦,會議名稱通常簡寫為:ACL-IJCNLP2015。
⑥COLING創(chuàng)辦于1965年,每兩年召開一次,是本領域最具權威性和影響力的一流學術會議之一。
⑦International Committee on Computational Linguistics, 簡稱ICCL。網(wǎng)址:http://nlp.shef.ac.uk/iccl/。
參考文獻
李 幸、宗成慶 2006 《引入標點處理的層次化漢語長句句法分析方法》,《中文信息學報》第4期。
李宇明 2007 《關于〈中國語言生活綠皮書〉》,《語言文字應用》第1期。
宋 柔 2012 《漢語篇章廣義話題結構研究》,北京語言大學語言信息處理研究所研究報告。
王德亮 2004 《漢語零形回指解析——基于向心理論的研究》,《現(xiàn)代外語》第4期。
宗成慶 2013 《統(tǒng)計自然語言處理》,北京:清華大學出版社。
宗成慶、曹右琦、俞士汶 2009 《中文信息處理60年》,《語言文字應用》第4期。
宗成慶、高慶獅 2008 《中國語言技術進展》,《中國計算機學會通訊》第8期。
Ballesteros, Miguel, Chris Dyer, and Noah A. Smith. 2015. Improved Transition-Based Parsing by Modeling Characters instead of Words with LSTMs. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Dyer, Chris, Miguel Ballesteros, Wang Ling, Austin Matthews, and Noah A. Smith. 2015. Transition-Based Dependency Parsing with Stack Long Short-Term Memory. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP).
Kang, Xiaomian, Haoran Li, Long Zhou, Jiajun Zhang, and Chengqing Zong. 2016. An End-to-End Chinese Discourse Parser with Adaptation to Explicit and Non-Explicit Relation Recognition. Proceedings of the SIGNLL Conference on Computational Natural Language Learning (CoNLL).
Li, Ping, Zhen Jin, and Li Hai Tan. 2014. Neural Representations of Nouns and Verbs in Chinese: An fMRI Study. Neuroimage 21, 1533-1541.
責任編輯:戴 燃
