基于計算方法的語言規范效力檢測初探
2016-05-30 10:48:04饒高琦
語言戰略研究 2016年6期

提 要 語言規范實施效力的檢測和反饋是語言規劃工作中的重要問題。本文對基于計算方法的語言規范效力檢測進行了可行性論證,并以異形詞整理工作為對象進行了實踐。計算結果表明,1949年新中國成立以來的異形詞整理工作基礎較好,效果顯著。本文也探討了計算方法的適用性以及計算方法視角下人工規范應注意的事項。
關鍵詞 計算方法;效力檢測;異形詞;語言規范
Abstract The monitoring and measurement of the implementation of language standards have long been a challenging task for language planning. Based on a large-scale Chinese newspaper corpus, this paper attempts to explore the feasibility of a computation-based method in the measurement of language standards in practice. Chinese words with variant forms are taken as a case study, and the tendency of their change from the year 1949 to 2012 has been examined. The statistic results show that for the words with variant forms, the frequency of officially-recognized standard forms is remarkably higher than that of nonstandard forms. Therefore, the computation-based method of monitoring language practice is a promising endeavor. However, the application scope of computational methods and the time window of artificial regulations have to be carefully controlled in the computational analysis.
Key words computational method; effectiveness monitoring; words with variant forms; language standard
一、引 言
語言規范實施效力的檢測與反饋是語言政策與規劃領域的一大難題。
自然語言在使用時面臨內在和外在擾動。內外擾動的結果常表現為一段時間內的無序狀態,如一種內容對應多種形式。語言生活中的不少規范問題是由此造成的。異形詞不同詞形間的混用便是典型例子。自然語言面對內在和外在擾動時,具有規范和調節的能力。這樣的規范和調節有的來自其自身,有的來自人工干預。后者主要指各類語言文字規范。而語言規范的過程體現為自然語言遭遇擾動后經過規范而恢復和諧、豐富狀態的過程。
語言規范的行為和語言政策本身都是對各種語言變項的選擇(戴昭銘 1999;李宇明 2015;伯納德·斯波斯基 2016)。相比于“雅正觀”,這一觀念被稱為語言規劃的“選擇觀”(李宇明 2015)。基于“選擇觀”,語言規范的過程可以視作一定時間段和一定領域內不同語言變項間的競爭過程。競爭將通過語言社團集體性的“用口投票”或“用筆(鍵盤)投票”完成。語言社團的選擇在數據上就體現為諸語言變項使用的多寡,從而可以用頻率、分布和生命度等計算方法對其進行刻畫與分析。由于變項的競爭發生在一定時間段內,因而規范實施的效力也是具有時間屬性的分析對象。同時,大規模語料庫可以視作對語言生活的采樣。綜上所述,在語料庫中對可形式化的語言變項進行歷時計算分析可以考察語言規范的實施效力。
要開展這一工作,在數據上要求具備一定時間跨度的歷時語料庫,在技術上需要具備對規范對象(即相應語言變項)進行計算的手段,在方法上需要對語言變項進行形式化處理并控制其規模,以適應計算和分析的需求。
本文擬就使用計算手段檢測語言規范實施效力的方法進行初步探索,并對異形詞規范工作進行研究,借此實踐基于詞語定量計算的效力檢測方法。
二、研究現狀
(一)使用語言信息處理技術的詞語定量研究
面向現代漢語并基于語言信息處理技術的詞語定量研究20世紀80年代就已開始。其代表性成果就是《現代漢語頻率詞典》(北京語言學院語言教學研究所 1986)。張普及其團隊的一系列研究(張普1999,2003,2008a,2008b;郭慧志等 2004)推動了詞語定量研究中資源和計算方法的持續進步,并為大規模的語言監測奠定了基礎,進而支持了穩態詞(趙小兵 2007;謝曉燕 2010)、新詞語(劉長征2008,2011)、政府話語(張沖 2011)、成語(劉長征、秦鵬 2007;李彥燕 2015)、流行語(謝學敏 2006)、中醫術語(王文媛 2013)、 傳統經典著作中的詞語(陳曉丹 2014;王佳 2014;郭景旋 2016)使用及變遷的監測。
當前對現代漢語開展的最大規模的詞語定量研究是國家語言資源監測與研究中心從2005年開始并延續至今的語言生活狀況調查(教育部語言信息管理司 2005—2015)。詞語的使用調查以《中國語言生活狀況報告·數據篇》和“漢語盤點”活動的形式逐年向社會發布。
(二)中文歷時語料庫資源
中文方面,鄒嘉彥等(2011)的泛華語地區漢語共時語料庫(LIVAC)主要收集兩岸三地的報刊數據,尤其是同題報刊數據,目前規模5.5億字。雖名為共時,但其數據特點決定了其穩定的更新速率,因此自1993年啟動以來,該工程就具有監測歷時語言演變的功能。
北京語言大學建立的動態流通語料庫(DCC)是國家主導語言監測工作的直接產物,輯錄近30年的報紙語料,并根據動態流通理論逐年更新。現已成為中國語言生活監測的最重要語料庫之一。與其具有類似功能和目標的還有中國傳媒大學的有聲媒體語料庫與華中師范大學的網絡媒體語料庫。但是它們的時間跨度都遠遠小于DCC語料庫。
針對目前歷時語言資源建設的短板,北京語言大學荀恩東團隊于2012年建設了“現代漢語詞匯歷時檢索系統”,即現在BCC語料庫歷時頻道的前身(荀恩東等 2015,2016)。該語料庫涵蓋1946年到2015年的《人民日報》語料①,時間跨度70年,規模12億字,經過分詞和詞性標注后獲得分詞單元種數約220萬。并收集了近似跨度的《貴州日報》語料。本文所使用的數據即來自該語料庫1949年到2012年的部分。
由于報刊語言是語言規范的先行者和執行標桿,可以忽略規范標準的社會宣傳與推廣這一變量,因而適合作為語言規范尤其是人工規范相關研究的語料。
三、對異形詞整理規范效力的考察
異形詞是書面語中存在的一種特殊詞匯現象,如“筆畫—筆劃”“身份—身分”。異形詞是漢語漫長發展過程中的累積現象,使用非常廣泛,給語言學習與傳播帶來了不必要的負擔和障礙,也增加了語言使用的復雜程度。2002年教育部和國家語委聯合發布了《第一批異形詞整理表》。2003年中國出版協會校對研究委員會和中國語文報刊協會等四家單位又編制了《第二批異形詞整理表(試行)》。
異形詞整理首先遵從的是“約定俗成”,其他還包括“義明”“音準”“形簡”“分化”和“兼顧”幾個原則(楊劍橋 2006)。本文基于語料庫的考察主要著眼于“從俗從眾”。在長時間跨度的歷時語料庫中可以觀測到異形詞不同詞形間使用的頻率關系,從而判斷語言規范在報紙上的實施效力。
(一)對具體詞形使用趨勢變化的考察
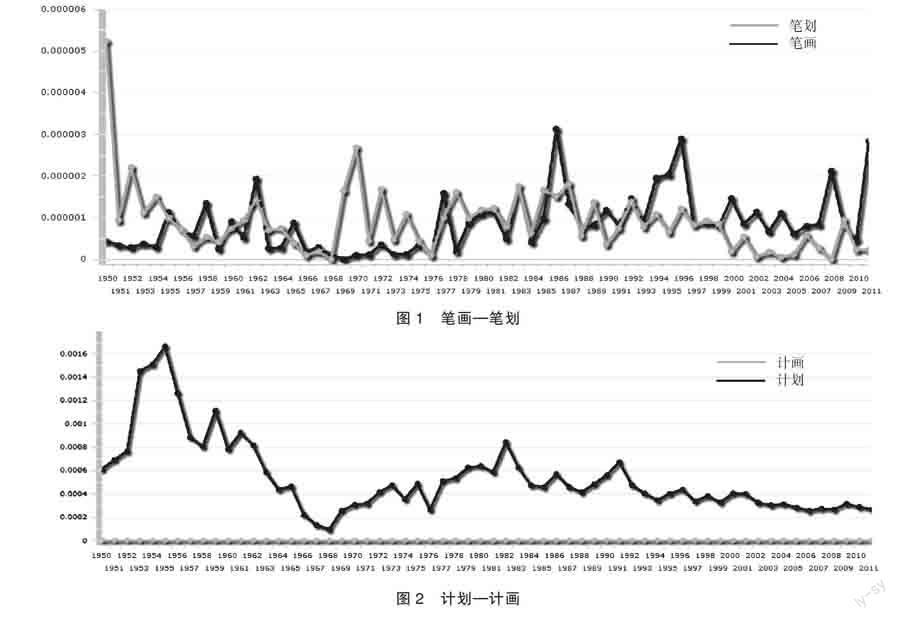
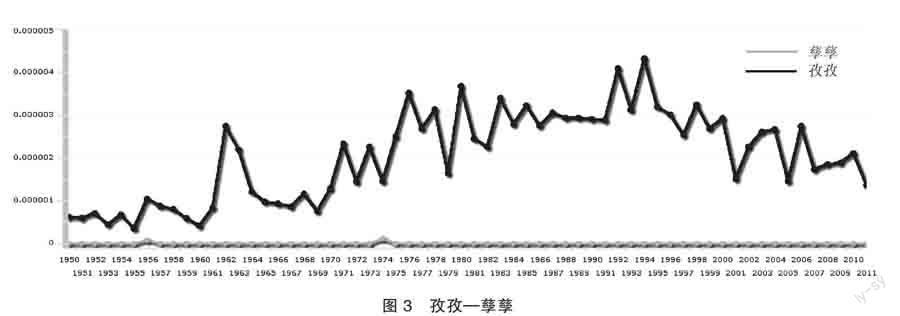
在微觀上,歷時語料庫中不同詞形的頻次對比可以直觀反映一組異形詞不同詞形在報紙中的使用變化情況,圖1、圖2和圖3分別展示了“筆畫—筆劃”(第一個為規范文件中的推薦詞形,后同)、“計劃—計畫”和“孜孜—孳孳”在1949年到2012年間使用情況的變化。其中橫坐標為年份、縱坐標為頻率,如無特殊說明皆為此意。這三組異形詞分別代表了詞形間頻率差異不明顯、一種詞形完全不使用和一種詞形極少使用三種分布情況。
過去幾十年中頻率上占據明顯優勢的詞形為優勢詞形,如圖2和圖3中的“計劃”和“孜孜”;頻率上處劣勢的為劣勢詞形,如圖2和圖3中的“計畫”和“孳孳”。圖1中的兩個詞形則無法確定哪一個占有整體性的優勢。在本文歷時語料庫中,規范文件中的絕大多數推薦詞形是優勢詞形。《第一批異形詞整理表》和《第二批異形詞整理表》分別整理異形詞338組和264組,其中推薦詞形為非優勢詞形的分別僅有7組和5組③。可見異形詞的規范工作基本上遵循了“從俗”“從眾”的原則。
如果一個詞的各詞形在多數年份的語料中均出現10次以下,其在語料庫中的使用可認為具有較大偶然性,統計可信度較差,本文不予考察。兩份規范文件中這樣的異形詞分別有50組和75組。
對異形詞使用情況的考察側重于不同詞形間使用情況的對比,有些劣勢詞形在語料庫中基本不出現,即異形詞的多種詞形在語料庫中已不再混用,如圖2和圖3中所示,因而在統計推薦詞形的頻率優勢時也將其排除。這一部分異形詞兩份規范文件中分別有198個和111個。除去上述兩種情況后,剩余的168組異形詞為本文的有效數據。
我們將兩批整理表的發布時間2002年和2003年視作分界時間點,在歷時語料中統計該時間點到2011年間具有混用情況的異形詞的推薦詞形(它們大多為優勢詞形或優劣不明顯詞形)使用頻率的變化情況。結果如表1所示。
由表1可知,兩批整理表對有混用情況的異形詞的使用起到了明顯的規范作用。整理表發布后,有60%到70%的推薦詞形的優勢得以擴大,減少了語言使用中的混淆情況。推薦詞形不占明顯優勢的情況也存在,這一類被歸入表中“優勢不明”一欄。推薦詞形優勢擴大的異形詞如圖4所示的“啟程—起程”,優勢縮小的例子如圖5的“襤褸—藍褸”,優勢不變的例子如圖6的“神采—神彩”,優勢不明的例子如圖7的“戰栗—顫栗”。
(二)對推薦詞形整體使用情況的考察
如果要考察整個異形詞群體的規范使用情況,可以使用所有推薦詞形的頻次之和與非推薦詞形頻次之和的對比來進行衡量。本文稱之為“倍比”(r),其計算方法如公式(1)所示。
公式(1)
其中f(w)為詞w在當年的詞頻,wu為非推薦詞形,wt為推薦詞形。在歷時語料庫中對兩批異形詞整理表中的異形詞進行計算,諸年度倍比的數據如圖8所示,橫軸為年份,縱軸為倍比數值。
兩批異形詞整理表中異形詞推薦詞形與非推薦詞形的倍比的變化區間為8.9倍到236.2倍,即非推薦詞形的總頻率最高時約為推薦詞形頻率的九分之一,最低時推薦詞形每出現200余次非推薦詞形出現一次。可見,規范狀況較好。從1946年到21世紀初,規范詞形的使用頻率持續緩慢增長,這也體現出語言社團自發的語言規范行為在發揮作用。
2002年、2003年兩批《異形詞整理表》的發布帶來了規范詞形使用頻率的明顯增長。2003年后,許多異形詞在語料中都過渡到了非推薦詞形頻率為零的狀態。倍比的增長主要由處于該種狀態的推薦詞形的頻率增加而造成。如2009年到2010年的高峰,主要由“參與”“人才”“計劃”“標志”等詞本身頻率的大幅增加造成,它們所對應的非推薦詞形在當年語料中已經消失,語言規范的成果在該語域內得到了鞏固。可以推測,這些詞在語言生活中已基本不存在可選的變項,穩定的語言規范已經形成。因而此時出現的倍比高峰和之后倍比的下跌不再代表推薦詞形和非推薦詞形的實力對比。
如果僅對存在混用情況的異形詞進行考察,以評價語言規范在有混用情況下的作用,則不需要考慮非推薦詞形頻率為零的詞對觀察的影響。我們將單純基于頻率的倍比r發展為公式(2)所示的修正倍比kr。
公式(2)
其中f(w)為詞w的詞頻,wu為非推薦詞形,wt為推薦詞形。但修正倍比中w的選擇范圍比計算倍比時有所縮小。修正倍比僅計算非推薦詞形頻率大于零的異形詞的頻率,即存在混用的異形詞。同時,考慮到存在混用的異形詞越多,規范狀況越差,而混用詞語的數量對公式(1)并無影響,因此我們在公式(2)中使用存在混用情況的異形詞的數量n在分母上對混用詞數較多的情況進行調節。
我們對兩批異形詞整理表中存在混用的異形詞使用公式(2)進行計算,修正倍比的變化情況如圖9所示,橫軸為年份,縱軸為修正倍比數值。
2002年頒布《異形詞整理表》引起了2003年推薦詞形頻率的增長和2004年非推薦詞形數的迅速下降。兩種效應合力之下2008年到2010年出現了修正倍比的高峰,非推薦詞形的數量則下降并停留在10到20個之間。在這種情況下,個別非推薦詞形偶然的頻率起伏就會對修正倍比產生較大影響。但總體上推薦詞形的使用頻率在震蕩中保持著遠高于2003年以前的水平(150—200倍)。
(三)對具體推薦詞形在歷史時期中使用情況的考察
倍比和修正倍比描述了異形詞在一個時間點上的使用情況,但若量化考察一組異形詞在整個歷史時期中的使用情況則需要不同的計算方法。一組異形詞的不同詞形在一段時間內平均使用頻次的比值可以刻畫它們的使用情況的差異,其計算方法如公式(3)所示:
公式(3)
S為該異形詞在一個時間段中的兩種詞形的平均頻率比。其中e為時間段的終了年份,s為時間段的開始年份,fai和fbi分別代表詞形a和b在i年語料里出現的頻次。假設計算1950年到2005年間“筆畫—筆劃”的平均使用頻次之比,則e為2005,s為1950。由于有的詞形在許多年份中不出現,為避免分母為0,在分式中使用了加一平滑策略。
顯然公式(3)所示的計算方法中各年份數據的地位是一致的。但對現實的語言規劃工作而言,更晚近的語言數據重要性更高。因而我們對公式(3)進行了改進,形成公式(4):
公式(4)
公式(4)中各符號的意義不變。其中,越早年份的語料,其詞形頻次比在最終結果S中所占的權重越低。假設以公式(4)對“筆畫—筆劃”這組異形詞在1950年至2005年時間段中進行計算。則1950年兩詞形頻次之比所占的權重為1/(2005-1950+1)≈0.018,而1990年頻次之比所占的權重為1/(2005-1990+1)≈0.063。年份越近的數據對S的影響越大,即參考價值越高。假設存在一組異形詞,其詞形在每年語料中的頻次fai和fbi都相等,s和e分別取本文所使用語料的開頭年份(1949)和結尾年份(2012),則此時的S值為4.74,可稱之為臨界值。大于臨界值的異形詞可以認為其詞形a相對詞形b在70年的考察范圍內具有整體性的優勢,反之亦然。
如果在使用公式(4)進行計算時將推薦詞形設為a,那么在《第一批異形詞整理表》和《第二批異形詞整理表(試行)》的有效數據中有94.6%的S值高于臨界值,79%的S值超過臨界值兩倍,57%的S值超過臨界值五倍。可見異形詞規范工作中所選擇的推薦詞形在較長的時間跨度內具有整體性的使用優勢。我們認為,這樣的優勢在人工規范制定前來自語言社團的自我規范,在人工規范制定后部分來自人工規范的強制力量。
總體而言,《異形詞整理表》在報紙語言中得到了良好的執行,規范實施效果顯著。因所選語料在語言規范問題上比較嚴格,是執行語言規范標準的模范,因此統計數據只能在一定程度上反映語言規范的效力。如果更換其他語料,具體數值可能會有變化,但總的趨向不會改變,即《異形詞整理表》起到了提高語言文字使用效率、減少學習負擔的作用。
四、語言規范計算分析的反思
(一)計算方法的適用范圍
我們對異形詞整理的實施效力進行了研究。顯然不是每一類語言規范的實施效力都適合通過計算方法進行分析和檢測。計算方法檢測的適用范圍是由語料庫和分析方法的形式化能力決定的。因此我們可以歸納適用于計算方法分析的語言規范所應具備的幾類特征。
首先,計算方法基于對語言現象的符號化和形式化,因而規范對象可以形式化為符號或符號序列的適合使用計算方法進行檢測,如字、詞。以當前技術手段難以形式化的規范對象,如文風、語體等,就難以使用計算方法進行檢測和分析。
其次,計算方法所涉及的語料數量極大,需要自然語言處理諸多技術支持,規范對象的處理不應超出相應語言信息處理技術的適應范圍。例如,目前通用文本上的自動分詞與詞性標注已具有較高精度,面向詞語,尤其是字詞形式的規范可以進行計算調查。但句法分析性能尚無法令人滿意,在大規模語料上語法規范效力的檢測就面臨巨大困難。
再次,語言變項間具有較好的可對比性。基于“選擇觀”的語言規范本身就是語言變項的選擇過程。因而規范實施效力的核心刻畫手段就是語言變項間的對比。在時間、語域、種類等不同側面對語言變項進行對比,從而從不同側面獲得語言規范對變項使用情況的影響,進而評價其實施效力。
最后,歷時語料庫的時間或領域對規范內容有較好覆蓋。時間方面,語料庫需覆蓋規范實施前后較長的時間段,以提供規范實施效力參考。領域方面,語料需覆蓋規范對象的常用領域。
由此容易發現,除異形詞外,規范漢字、異體字、阿拉伯數字、字母詞、計量單位符號等也適合使用計算方法對其規范的實施效力進行分析和反饋。
(二)人工規范的時機選擇
如果視語言使用者對語言變項的選擇行為為隨機過程,當一個變項的使用衰減成為小概率事件③時,變項間的實力對比就失去了意義。這在異形詞的倍比統計中得到體現。如果此時占據使用頻率優勢地位的是規范標準所支持的變項,則可以認為社會規范在該語域內已經得以實現。此時人工規范應該關注具體的失范實例,并進行微調。
對語言單位的規范過程進行人為干預,需要把握時機。由圖8和圖9可知,《異形詞整理表》發布的時候,推薦詞形的總體頻率已經達到了非推薦詞形的79倍(圖8),修正倍比為11倍(圖9)。如果以最大似然估計進行概率估計,非推薦詞形的使用概率已經很小。變項間實力對比出現這種情況的時期可以視作人工干預期。這個階段的人工規范容易取得較好效果。
在中國語言規劃的歷史上,出版物數字使用的規范則展現出不同的情況。1956年、1980年、1981年三次發布的相關規范④均是在漢字數字書寫占據絕對優勢情況下,逆勢拉升阿拉伯數字的使用頻率。當時效果雖然較為明顯,但沒能改變變項間的實力對比,且緊隨其后出現了60年代到80年代初較強的反彈。變項間實力對比類似以上情況的時期可以視作觀察期。這個階段的人工規范應當十分慎重,強行推廣規范可能遭遇較強烈的反彈。
介于觀察期和干預期之間的是引導期。此時應廣泛收集語言變項,甄別選擇適合的變項,為制定人工語言規范進行準備。2011年最新頒布的“出版物數字使用國家標準”不再強調阿拉伯數字的使用,而要求使用者更加重視“得體原則”和“局部體例一致原則”。這恰好體現了引導期語言規范工作的特點。
五、結論與展望
本文對使用計算方法尤其是詞語計算方法進行語言規范實施效力的調查和分析的數據資源、適用范圍和具體方法進行了初步探索,并對異形詞在歷時語料庫中的使用情況進行了統計和分析。對異形詞規范工作的效力給出了定量計算,并基于數據得出了異形詞規范工作基礎較好、效果顯著的結論。
作為使用計算手段檢測語言規范實施效力的初步探索,本文的工作還有許多尚待完善之處,尤其是對異形詞整理工作的研究還較為粗糙。為適應長時間、多領域的語言規范效力檢測,還應該在報紙語料之外擴充多語域、多語體的歷時語料庫,在計算手段上廣泛使用更加多樣化的方法。此外,充分融合語言本體研究的成果,對語言規范對象進行更科學的形式化建模也是重要的研究內容。
注 釋
① 由于種種原因,本文實驗過程中沒有獲得2003年到2008年《人民日報》的語料,該部分由相應年份的《貴州日報》語料替補。
② 第一批:“渾水摸魚—混水摸魚”“摩拳擦掌—磨拳擦掌”“叫花子—叫化子”“綿連—綿聯”“五勞七傷—五癆七傷”“小題大做—小題大作”“凝練—凝煉”;第二批:“黏液—粘液”“黏性—粘性”“黏土—粘土”“黏稠—粘稠”“俯首帖耳—俯首貼耳”。
③ 統計學上常用的兩個小概率事件閾值為1%和5%。
④ 三項規范分別為:關于國家機關的公文、電報和機關刊物橫排橫寫以后采用阿拉伯數碼的通知,關于數目字改排阿拉伯數字的規定,國家行政機關公文處理暫行辦法。
參考文獻
北京語言學院語言教學研究所編 1986 《現代漢語頻率詞典》,北京:北京語言學院出版社。
伯納德·斯波斯基 2016 《語言管理》,張治國譯,北京:商務印書館。
陳曉丹 2014 基于動態流通語料庫的《道德經》語言使用狀況調查研究,北京語言大學碩士學位論文。
戴昭銘 1999 《語言功能和可能規范》,《語言文字應用》第2期。
郭慧志、王強軍、劉 華、張 普 2004 《大規模動態流通語料庫的構建》,全國學生計算語言學研討會論文。
郭景旋 2016 《組合類成語的詞匯化考察:以出自〈孟子〉的組合類成語為例》,北京語言大學碩士學位論文。
教育部語言文字信息管理司 2005―2015 《中國語言生活狀況報告》,北京:商務印書館。
李彥燕 2015 《報紙媒體四字成語使用狀況調查》,北京語言大學碩士學位論文。
李宇明 2015 《語言規范試說》,《當代修辭學》第4期。
劉長征 2008 《基于動態流通語料庫(DCC)的新詞語監測》,《長江學術》第1期。
劉長征 2011 《基于動態流通語料庫的新詞語監測研究》,北京:世界圖書出版社。
劉長征、秦 鵬 2007 《基于中國主流報紙動態流通語料庫(DCC)的成語使用情況調查》,《語言文字應用》第3期。
王 佳 2014 《當代語言生活中的〈論語〉使用情況考察》,北京語言大學碩士學位論文。
王文媛 2013 《基于動態流通語料庫的中國傳統醫學術語使用情況考察》,北京語言大學碩士學位論文。
謝曉燕 2010 《基于26年〈深圳特區報〉的穩態詞語提取與考察研究》,北京語言大學博士學位論文。
謝學敏 2006 《基于動態流通語料庫(DCC)的流行語釋義信息自動提取研究》,北京語言大學博士學位論文。
荀恩東、饒高琦、肖曉悅、臧嬌嬌 2016 《大數據背景下BCC語料庫的研制》,《語料庫語言學》第3期。
荀恩東、饒高琦、謝佳莉、黃志娥 2015 《現代漢語詞匯歷時檢索系統與應用研究》,《中文信息學報》第3期。
楊劍橋 2006 《關于漢語多音節異形詞的幾個問題》,《復旦大學學報》第6期。
張 沖 2011 《歷年〈政府工作報告〉的詞語變化及其反映的內容分析》,北京語言大學碩士學位論文。
張 普 1999 《關于網絡時代語言規劃的思考》,中國科協首屆學術年會論文。
張 普 2003 《基于DCC的流行語動態跟蹤與輔助發現研究》,全國計算語言學聯合學術會議論文。
張 普 2008a 《論語言的穩態》,《鄭州大學學報》(哲學社會科學版)第2期。
張 普 2008b 《論語言的動態》,《長江學術》第1期。
趙小兵 2007 《基于動態流通語料庫的現代漢語基本詞匯自動識別與提取方法研究》,北京語言大學博士學位論文。
鄒嘉彥、鄺藹兒、陸 斌、蔡永富 2011 《漢語共時語料庫與追蹤語料庫》,《中文信息學報》第6期。
責任編輯:戴 燃
