前后綴與特征詞相結(jié)合的地名地址提取
2016-04-11 01:25:35王克永劉紀(jì)平
測(cè)繪通報(bào) 2016年2期
王克永,劉紀(jì)平,羅 安,王 勇
(1. 山東農(nóng)業(yè)大學(xué),山東 泰安 271018; 2. 中國(guó)測(cè)繪科學(xué)研究院,北京 100830)
?
前后綴與特征詞相結(jié)合的地名地址提取
王克永1,2,劉紀(jì)平2,羅安2,王勇2
(1. 山東農(nóng)業(yè)大學(xué),山東 泰安 271018; 2. 中國(guó)測(cè)繪科學(xué)研究院,北京 100830)
Extracting Toponomy and Location Based on the Combination of Prefix and Suffix with Feature Words
WANG Keyong,LIU Jiping,LUO An,WANG Yong
摘要:隨著地理信息與計(jì)算機(jī)技術(shù)的發(fā)展,網(wǎng)絡(luò)中的非結(jié)構(gòu)化地名地址數(shù)據(jù)越來(lái)越多,逐步成為地理信息更新的重要途徑之一。針對(duì)互聯(lián)網(wǎng)中地名地址的存在方式及結(jié)構(gòu)特點(diǎn),本文提出了一種前后綴與特征詞相結(jié)合的地名地址識(shí)別提取方法。首先利用HMM訓(xùn)練進(jìn)行分詞,接著通過地名地址前后綴詞庫(kù)進(jìn)行候選地名切分與預(yù)提取,最后根據(jù)特征詞進(jìn)行匹配過濾,實(shí)現(xiàn)對(duì)地名地址的準(zhǔn)確提取。試驗(yàn)結(jié)果證明,本文方法提高了地名地址識(shí)別的準(zhǔn)確率和召回率,很大程度上解決了未登錄地址提取問題。
關(guān)鍵詞:前后綴;特征詞;HMM分詞;地名地址
隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展,多源網(wǎng)絡(luò)中廣泛存在數(shù)量龐大、種類繁多的新聞、報(bào)道、軍事、生活信息,它們大多是文本數(shù)據(jù),不容易被自動(dòng)挖掘與提取。然而,蘊(yùn)藏在文本中的地理信息不僅能為政府關(guān)注各類事件的分析、研究和決策提供支撐,而且還可以豐富地理信息的內(nèi)容[1],可以利用GIS軟件進(jìn)行空間分析與應(yīng)用[2]。目前,地理信息中地名地址搜索大多利用關(guān)鍵詞[3-4]及其出現(xiàn)詞頻統(tǒng)計(jì)結(jié)果進(jìn)行分析和應(yīng)用,導(dǎo)致搜索數(shù)據(jù)存在模糊、歧義等問題,使地名地址識(shí)別的準(zhǔn)確率降低。因此,從海量網(wǎng)絡(luò)資源中抽取準(zhǔn)確的地名地址信息顯得格外重要。
地名地址識(shí)別是從文本數(shù)據(jù)中識(shí)別具有空間位置表達(dá)能力的地名地址要素,如帶有行政區(qū)劃的組織機(jī)構(gòu)、門樓地址、餐飲、購(gòu)物商場(chǎng)等。目前,國(guó)內(nèi)外主要相關(guān)研究成果可以分為基于字典與統(tǒng)計(jì)的地名地址識(shí)別、基于規(guī)則的地名地址識(shí)別及基于機(jī)器學(xué)習(xí)的地名地址識(shí)別三方面。翟鳳文等提出了一種字典與統(tǒng)計(jì)相結(jié)合的中文分詞方法,提高了交集型歧義切分的準(zhǔn)確率,并且在一定條件下解決了語(yǔ)境中高頻未登錄詞問題[5];李宏波提出的分詞詞典和統(tǒng)計(jì)分析相結(jié)合的解決方案,合理解決了歧義詞和未登錄詞兩大難題[6];趙偉等結(jié)合規(guī)則和語(yǔ)料庫(kù)統(tǒng)計(jì)兩種分詞方法進(jìn)行分詞[7];張雪英等以大規(guī)模地名詞典和地址數(shù)據(jù)庫(kù)為數(shù)據(jù)源,提出了中文地址的數(shù)字表達(dá)方式,提高了識(shí)別的準(zhǔn)確率[8];馬學(xué)峰分析了地名地址規(guī)律,整合了地名地址數(shù)據(jù)庫(kù)[9];潘正高在構(gòu)造內(nèi)部規(guī)則和外部規(guī)則的同時(shí),采用了概率統(tǒng)計(jì)的中文命名實(shí)體的識(shí)別方法[10];李麗雙等提出了支持向量機(jī)(SVM)與規(guī)則相結(jié)合的中文地名自動(dòng)識(shí)別方法,得到了SVM識(shí)別地名的機(jī)器學(xué)習(xí)模型[11]。
本文在研究國(guó)內(nèi)外方法的基礎(chǔ)上,根據(jù)前人提出的隱馬爾可夫模型(HMM)進(jìn)行語(yǔ)義訓(xùn)練與分詞,將中文文本分成多個(gè)獨(dú)立詞語(yǔ),并利用語(yǔ)義庫(kù)提取的前后詞綴對(duì)HMM分詞結(jié)果進(jìn)行候選地名地址的預(yù)提取,再結(jié)合構(gòu)建的地名地址特征詞庫(kù)對(duì)候選地名地址進(jìn)行匹配過濾。
一、地名地址識(shí)別提取
網(wǎng)絡(luò)中涉及的地名地址具有種類繁多、樣式復(fù)雜及未登錄詞出現(xiàn)頻率高等特點(diǎn),導(dǎo)致地名地址的提取難度大且識(shí)別精度低。結(jié)合網(wǎng)絡(luò)中中文地名地址的上下文特征,本文提出一種基于前后綴的地名地址識(shí)別與提取方法,具體技術(shù)流程如圖1所示。首先利用訓(xùn)練出的HMM對(duì)中文文本信息進(jìn)行自動(dòng)分詞,將整個(gè)中文文本信息切分成若干個(gè)獨(dú)立的詞語(yǔ);然后根據(jù)建立的地名地址前綴詞庫(kù)和后綴詞庫(kù),對(duì)切分的文本信息進(jìn)行前后綴匹配,從而將前后綴之間的文本提取出來(lái)作為候選地名地址,形成候選的地名地址庫(kù);最后通過構(gòu)建的地名地址特征詞庫(kù),對(duì)候選地名地址庫(kù)進(jìn)行一一比對(duì)和過濾,將其中不包含地名地址要素的文本信息剔除,實(shí)現(xiàn)中文地名地址的自動(dòng)識(shí)別與提取,有效提高地名地址識(shí)別的準(zhǔn)確率。
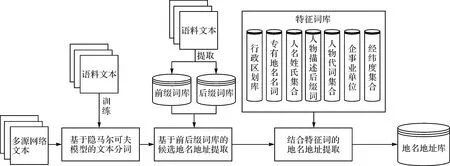
圖1 地名地址識(shí)別流程
1.基于隱馬爾可夫模型(HMM)的文本分詞
前后綴詞庫(kù)中的詞語(yǔ)涉及范圍大,格式不統(tǒng)一,為了避免前后綴詞將完整的地址進(jìn)行切分,需要對(duì)網(wǎng)絡(luò)文本信息進(jìn)行分詞預(yù)處理。本文采用隱馬爾夫模型(HMM)對(duì)網(wǎng)絡(luò)文本進(jìn)行中文分詞,將整個(gè)中文文本信息切分成若干個(gè)獨(dú)立的詞語(yǔ),為下一步基于前后綴的候選地名地址提供基礎(chǔ)。
隱馬爾卡夫過程是一種雙重隨機(jī)過程,結(jié)合傳統(tǒng)HMM的特征,本文利用海量網(wǎng)絡(luò)地名地址文本信息對(duì)HMM參數(shù)進(jìn)行自學(xué)習(xí)訓(xùn)練得到最佳分詞參數(shù),確保分詞后地名地址的完整性。具體HMM描述與訓(xùn)練過程如下。
隱馬爾夫模型是個(gè)五元組模型N、M、A、B、π,它們表現(xiàn)的意義分別是:
N={q1,q2,…,qN},表示狀態(tài)的集合,地名地址識(shí)別中,有單字成詞、詞首、詞中、詞尾4種狀態(tài)。
M={v1,v2,…,vM},表示觀察值的有限集合。
π={πi},表示狀態(tài)的初始概率。
A={aij},aij=P(qt=Sj|qt-1=Si),轉(zhuǎn)移概率矩陣,本文中為S的4種狀態(tài)之間的轉(zhuǎn)換,理論上有42種轉(zhuǎn)換,考慮到地名識(shí)別的實(shí)際情況,只有單字成詞→單字成詞、單字成詞→詞首、詞首→詞中、詞首→詞尾、詞中→詞中、詞中→詞尾、詞尾→詞首、詞首→單字成詞8種轉(zhuǎn)移。
B={bjk},bjk=P(Ot=vk|qt=Sj),為觀察值概率分布矩陣。
一般而言,A、B確定后,M與N也能夠確定,因此給定一系列觀察樣本,從而可以將HMM描述為λ(π,A,B)模型,滿足某種優(yōu)化條件,使P(O|π)最大,具體重估迭代公式如下
2. 基于前后綴詞庫(kù)的候選地名地址預(yù)提取
在基于HMM分詞的基礎(chǔ)上,利用前后綴詞庫(kù)進(jìn)行地名地址前后綴詞語(yǔ)的隊(duì)列匹配,即首先通過地名前綴詞語(yǔ)進(jìn)行詞語(yǔ)的逐一匹配,然后根據(jù)與該前綴詞語(yǔ)對(duì)應(yīng)后綴詞的權(quán)重進(jìn)行地名地址后綴詞的匹配,只有當(dāng)前后綴詞語(yǔ)完全匹配成功后,才將中間的文本信息串連起來(lái),作為候選地名地址,最終形成候選地名地址庫(kù)。
由于候選地名地址提取的準(zhǔn)確性在很大程度上依賴于前后綴詞庫(kù)的豐富程度,因此本文采用大量網(wǎng)絡(luò)文本信息作為語(yǔ)料庫(kù),利用常伴隨地名地址同時(shí)出現(xiàn)的前綴詞與后綴詞的頻率與詞性,通過機(jī)器自學(xué)習(xí)的方式來(lái)自動(dòng)豐富與完善地名地址前后綴詞庫(kù)(部分前后綴詞庫(kù)如圖2、圖3所示),并通過前后綴詞詞性與搭配情況,構(gòu)建前后綴詞庫(kù)對(duì)應(yīng)連接關(guān)系,即為前綴詞所對(duì)應(yīng)的后綴詞賦予權(quán)重,提高后綴詞匹配分詞的速度與準(zhǔn)確性,具體賦予權(quán)重公式如下
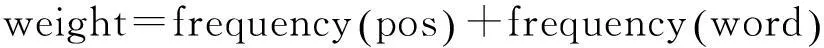
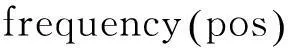
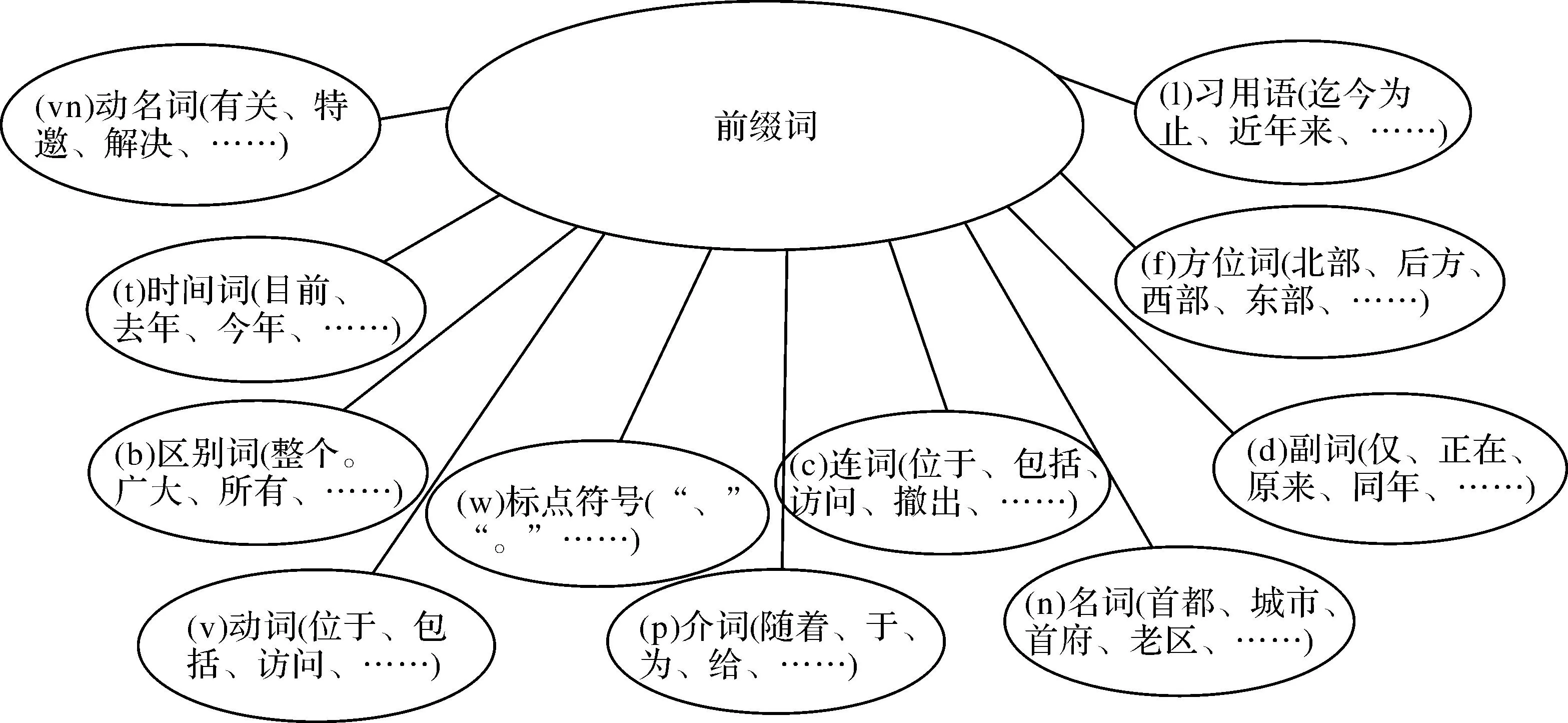
圖2 前綴詞庫(kù)部分前綴詞
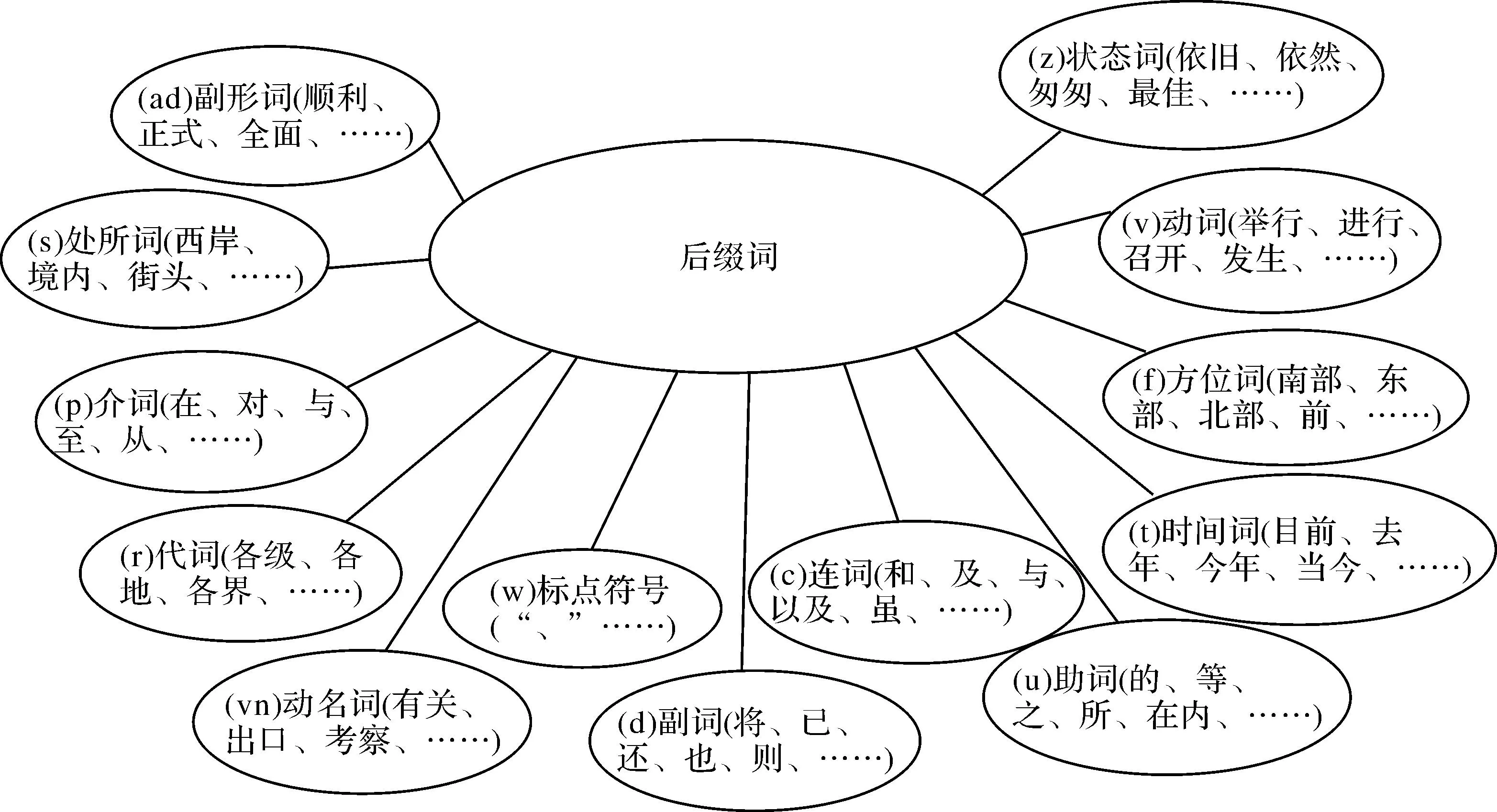
圖3 后綴詞庫(kù)部分后綴詞
具體過程如下:本文以1998年1月一條新聞為例,首先去除語(yǔ)料庫(kù)中每條新聞開始的時(shí)間(如19980101-02-003-003/m),以避免時(shí)間造成的誤差;然后對(duì)專屬名詞與地名地址進(jìn)行合并,有效統(tǒng)計(jì)地名地址的前后綴詞詞性及對(duì)應(yīng)出現(xiàn)的頻率;最后統(tǒng)計(jì)后綴詞中相同詞出現(xiàn)的頻率,詞性頻率與詞的頻率相加作為前綴詞確定下后綴詞出現(xiàn)的權(quán)重。如“[那曲/ns 地區(qū)/n]ns”合并為“那曲地區(qū)/ns”,“[西藏/ns 自治區(qū)/n 政府/n]nt”合并為“西藏自治區(qū)政府/nt”,根據(jù)地址(ns)出現(xiàn)的位置提取前后綴,在“今晚/t 的/u 長(zhǎng)安街/ns 流光溢彩/l”中,提取出地址“長(zhǎng)安街/ns”的前綴是助詞(u)“的”,后綴是習(xí)用語(yǔ)(l)“流光溢彩”。在提取的過程中,根據(jù)前綴助詞(u)確定權(quán)重由大到小的后綴詞,并依次匹配,直至匹配到出現(xiàn)的后綴詞“流光溢彩”。
3. 結(jié)合特征詞的地名地址提取
利用地名地址元素特征對(duì)上文形成的候選地名地址庫(kù)中地名地址逐一進(jìn)行匹配,剔除未包含地名地址要素及不符合地名地址構(gòu)詞規(guī)則的噪音信息,提取包含地址元素特征詞的地名地址,確保地名地址識(shí)別與提取的正確性與效率,主要包括特征詞提取與特征詞過濾。
(1) 特征詞提取
1) 候選地名地址中包含行政區(qū)劃要素的則作為地名地址信息,具體公式為:AdminLib[i]∈Loc(wait)?Loc(y),其中AdminLib為行政區(qū)劃庫(kù)(精確到村級(jí)),如北京、濟(jì)南、海淀等,i為集合中的一個(gè)元素;Loc(y)為地名地址集合。
2) 提取包含專有地名名詞的候選地名地址作為地名地址:Loclist[i]∈Loc(wait)?Loc(y),其中Loclist為專有地名名詞集合,如河流、湖泊、道路等。
3) 候選地名地址中含有經(jīng)緯度信息的作為地名地址:Lonlat[i]∈Loc(wait)?Loc(y),其中Lonlat[i]為經(jīng)緯度詞,如東經(jīng)、北緯、西經(jīng)、南緯。
4) 含有企事業(yè)單位特征詞的候選地名地址作為地名地址:Unit[i]∈Loc(wait)?Loc(y),其中Unit[i]為企事業(yè)單位詞,如公司、學(xué)校、客運(yùn)站、展覽館、銀行等。
(2) 特征詞過濾
1) 含有姓氏且含有人物描述詞的候選地名地址判斷為非地名地址:Familyname[i]∈Loc(wait)&&Figurelist[i]∈Loc(wait)?Loc(n)[11],其中Familyname為人名姓氏集合,如趙、錢、孫等;Figurelist為人物描述后綴詞,如女士、先生、叔叔、阿姨等;Loc(n)為非地名地址集合。
2) 候選地名地址中既含有人物代詞也含有人物描述后綴詞的被判斷為非地名地址:Pronlist[i]∈Loc(wait)&&Figurelist[i]∈Loc(wait)?Loc(n),Pronlist為人物代詞集合,如你們、我們、他等。
二、試驗(yàn)與結(jié)果分析
由于新華社網(wǎng)站的新聞具有權(quán)威、報(bào)道精準(zhǔn)、傳播范圍廣、涉及范圍大等優(yōu)勢(shì),本文選取新華社網(wǎng)站上的新聞文本作為試驗(yàn)數(shù)據(jù),利用Web爬蟲技術(shù),采集新華社網(wǎng)站的1200條數(shù)據(jù)記錄。同時(shí)為了驗(yàn)證本文提出方法的有效性和優(yōu)越性,試驗(yàn)將基于本文提出的方法與HMM分詞方法進(jìn)行對(duì)比,并將試驗(yàn)數(shù)據(jù)進(jìn)行人工判讀,最終采用召回率R、準(zhǔn)確率P、F值(F-Measure)來(lái)反映本文方法和HMM分詞方法的區(qū)別,具體計(jì)算公式如下
本試驗(yàn)將1200條數(shù)據(jù)分為300條、600條、900條、1200條4種樣本進(jìn)行對(duì)比試驗(yàn),采用前綴詞1483個(gè),后綴詞2312個(gè),企事業(yè)單位特征詞204個(gè),專有地名名詞138個(gè),姓氏名詞4100個(gè),人物描述后綴詞86個(gè),人物代詞52個(gè),行政區(qū)劃庫(kù)數(shù)據(jù)精確到村級(jí),試驗(yàn)結(jié)果見表1。試驗(yàn)結(jié)果顯示,1200條新聞信息時(shí),本文提出的方法準(zhǔn)確性為92.11%,召回率達(dá)到89.13%,F(xiàn)值達(dá)到90.60%,其中F值對(duì)比如圖4所示。

表1 兩種方法對(duì)比 (%)
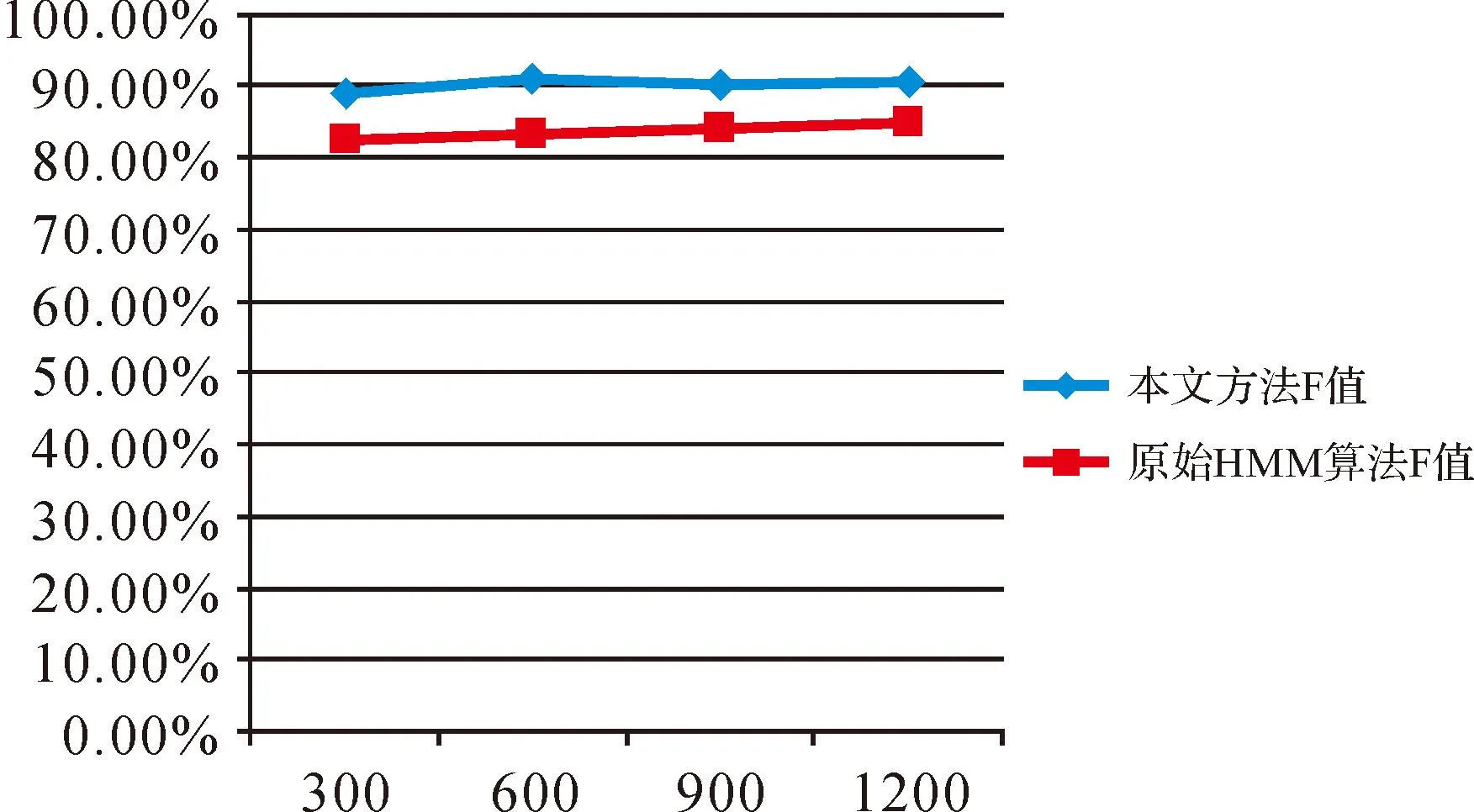
圖4 4種樣本識(shí)別F值對(duì)比圖
本文方法對(duì)地名地址識(shí)別的準(zhǔn)確率和召回率都高于HMM分詞方法。通過分析發(fā)現(xiàn),其原因是在地名地址識(shí)別時(shí),對(duì)于出現(xiàn)頻率不高的詞語(yǔ),HMM分詞方法學(xué)習(xí)度不夠,從而引起錯(cuò)分,而本文方法經(jīng)過前后綴預(yù)提取與特征詞匹配過濾后,可以有效地將錯(cuò)分地址組合到一起,并提取出來(lái)。同時(shí),為了測(cè)試方法的應(yīng)用效果,本方法已經(jīng)在基礎(chǔ)地理信息更新中得到了相應(yīng)的應(yīng)用,通過識(shí)別并提取網(wǎng)絡(luò)上地理信息網(wǎng)站發(fā)布新聞中的地名地址數(shù)據(jù),實(shí)現(xiàn)對(duì)地理信息數(shù)據(jù)庫(kù)中的原始數(shù)據(jù)更新,系統(tǒng)如圖5所示。
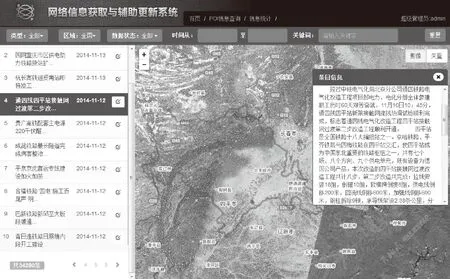
圖5 地名地址提取與定位效果
三、結(jié)束語(yǔ)
本文提出了前后綴與構(gòu)詞規(guī)則相結(jié)合的地名地址識(shí)別方法,充分考慮了網(wǎng)絡(luò)地名地址前后綴詞庫(kù)及未登錄詞的結(jié)構(gòu)特征,利用訓(xùn)練的HMM分詞技術(shù),實(shí)現(xiàn)了地名地址的自動(dòng)識(shí)別與提取,提高了地名地址的識(shí)別準(zhǔn)確率、召回率,最后通過與傳統(tǒng)地名地址識(shí)別方法的對(duì)比試驗(yàn),驗(yàn)證了本文方法的有效性,并將本方法應(yīng)用在基礎(chǔ)地理信息更新領(lǐng)域。
參考文獻(xiàn):
[1]劉紀(jì)平,張福浩,王亮,等.電子政務(wù)地理信息服務(wù)[M].北京:測(cè)繪出版社,2014:136.
[2]馬照亭,李志剛,孫偉,等.一種基于地址分詞的自動(dòng)地理編碼算法[J].測(cè)繪通報(bào),2011(2):59-62.
[3]曾文,鄢軍霞.城市GIS地名定位工具的設(shè)計(jì)及應(yīng)用[J].地球科學(xué):中國(guó)地質(zhì)大學(xué)學(xué)報(bào),2006,31(5):725-728.
[4]王平,薄正權(quán).地名地址數(shù)據(jù)采集方法與實(shí)踐[J].城市勘測(cè),2013(2):54-57.
[5]翟鳳文,赫楓齡,左萬(wàn)利,等.字典與統(tǒng)計(jì)相結(jié)合的中文分詞方法[J].小型微型計(jì)算機(jī)系統(tǒng),2006,27(9):1766-1771.
[6]李宏波.詞典與統(tǒng)計(jì)相結(jié)合的中文分詞算法研究[J].武漢理工大學(xué)學(xué)報(bào)(信息與管理工程版),2010,32(6):907-913.
[7]趙偉,戴新宇,尹存燕,等.一種規(guī)則與統(tǒng)計(jì)相結(jié)合的漢語(yǔ)分詞方法[J].計(jì)算機(jī)應(yīng)用研究,2004,21(3):23-25.
[8]張雪英,閭國(guó)年,李伯秋,等.基于規(guī)則的中文地址要素解析方法[J].地球信息科學(xué)學(xué)報(bào),2010,12(1):9-16.
[9]馬學(xué)峰.湛江市地名地址數(shù)據(jù)庫(kù)設(shè)計(jì)與實(shí)現(xiàn)[J].測(cè)繪通報(bào),2014(S1):288-291.
[10]潘正高.基于規(guī)則和統(tǒng)計(jì)相結(jié)合的中文命名實(shí)體識(shí)別研究[J].情報(bào)科學(xué),2012,30(5):708-712.
[11]李麗雙,黃德根,陳春榮,等.SVM與規(guī)則相結(jié)合的中文地名自動(dòng)識(shí)別[J].中文信息學(xué)報(bào),2006,20(5):51-57.
[12]陳玉萍,張秀. 地名地址普查與建庫(kù)研究[J]. 測(cè)繪通報(bào),2015(6):103-107.
[13]數(shù)字城市地理信息公共平臺(tái)地名/地址編碼規(guī)則.中華人民共和國(guó)行業(yè)標(biāo)準(zhǔn):GB/T 23705—2009[S].北京:中國(guó)標(biāo)準(zhǔn)出版社,2009.
[14]鄒崇堯,朱貴方,趙雙明. 基于搜索引擎技術(shù)的地名地址定制查詢研究[J]. 測(cè)繪通報(bào),2014(8):92-94.
[15]李榮,胡志軍,鄭家恒.基于遺傳算法和隱馬爾可夫模型的web信息抽取的改進(jìn)[J].計(jì)算機(jī)科學(xué),2012,39(3):196-199.
中圖分類號(hào):P208
文獻(xiàn)標(biāo)識(shí)碼:B
文章編號(hào):0494-0911(2016)02-0064-05
作者簡(jiǎn)介:王克永(1990—),男,碩士生,主要從事3S技術(shù)集成與應(yīng)用。E-mail: yongkewang@126.com
基金項(xiàng)目:國(guó)家863計(jì)劃(2012AA12A402;2013AA12A403);中國(guó)測(cè)繪科學(xué)研究院基本科研業(yè)務(wù)費(fèi)(7771403)
收稿日期:2015-01-27; 修回日期: 2015-11-06
引文格式: 王克永,劉紀(jì)平,羅安,等. 前后綴與特征詞相結(jié)合的地名地址提取[J].測(cè)繪通報(bào),2016(2):64-68.DOI:10.13474/j.cnki.11-2246.2016.0050.
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
