一種機器人自主思維方法
2015-12-25 08:30:30鄧豪周一廷謝從霜
機械工程師 2015年3期
鄧豪, 周一廷, 謝從霜
(西南科技大學 信息工程學院,四川 綿陽621010)
0 引言
1950年,圖靈在《心靈》發表論文“計算機器與智力”,給機器思維下了影響深遠的定義:“如果自動機能在某些制定的條件下模仿一個人把問題回答得很好,以致在很長一段時間里能夠迷惑提出該問題的人,那么這種自動機就可以認為是能夠進行思維的”[1]。而現今采用傳統人工智能方法設計的機器人存在無法離線學習、任務確定以及智能擴展性差、無法適應多變的環境等多種局限性問題[2]。隨著各學科技術的發展,受到認知科學、神經生物學和心理學等學科交叉的啟發,研究人員開始著眼于機器人認知這一新的思路解決上述問題與局限[2]。
類人智能一直是人工智能和機器人領域的研究目標。目前,比較成熟的機器人主要是應用在特定環境下,針對于特定任務而特殊設計的機器人。但隨著對智能化水平需求的不斷提高,越來越需要能在高度復雜環境下工作,執行非特定任務和具有高度自治性的智能機器人[3]。但當工作環境動態多變時,周邊環境不完整和不確定的信息會導致機器人在執行任務的過程中遇到困難[4]。而目前對于機器人在完整周邊環境信息、任務完成、學習、記憶與遺忘等情況下獲得與產生的大數據,已經難以用現有的數據工具進行管理利用[9-10]。但這些大數據是機器人通過信息世界認識現實世界的基礎數據和智慧源泉[11],與機器人應用密切相關[12-13]。因此,如何讓完善機器人周邊信息及對于大數據的獲取、處理、存儲、讀取、利用是當前熱點。
本文通過將生物特性與機器人學習機制及遺忘機制聯系,利用多信息綜合對周邊環境進行完善,采用數據降維與稀疏學習的技術完成大數據的處理及信息挖掘,從而提出一種機器人自主思維模型。
1 機器人信息交互
1.1 信息獲取
生物在單位時間內與環境交互的信息量是異常龐大的,且信息相對于時間是形式多樣、維度多種的。傳感器類似人與環境進行信息交互的各種媒介,是機器人與環境進行信息交互的橋梁,但目前各類傳感器處理的是相對時間單維、形式單一的信息,且對環境信息的復用性差。這也是機器人只能在特定環境下、機械地完成特定任務,而無法進行自主性思維的一個重要原因。而對于復雜和動態多變的工作環境,周邊環境不完整和不確定的信息經常導致機器人在執行任務的過程中遇到困難。故機器人如何更全面地與環境進行信息交互及各類信息融合及復用是目前機器人智能化亟待解決的問題。
1.2 傳感器
對于機器人與周邊環境進行信息交互,信息量應是各類單一信息的有機結合,為了盡可能完善周邊信息,而不是針對特定環境、特定任務的單一信息,機器人與周邊環境交互信息量可表示為
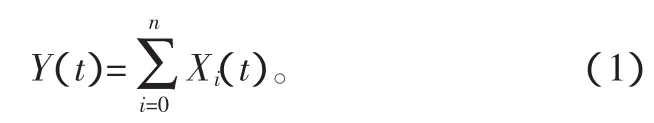
Y(t)表示機器人與環境交互的多維信息量,Xi(t)表示各傳感器傳送至機器人的單一維度信息向量。由式(1)可知,機器人在復雜和動態多變的環境下,所需要的環境信息需要多種傳感器共同提供,并且各單一維度信息量相對于時間具有一致性,即同一時刻各類信息有相應的映射關系。機器人進行決策時,同一時間下的不同環境信息量(次信息量)對主信息量具有輔助作用,使事件決策獲得最優解。因此,多數量、全種類的傳感器為機器人完善周邊信息提供必要條件。
因為機器人與環境交互是多維信息量,需要多傳感器從環境中采集,而目前各傳感器多為單一用途,信息為一維信息量,且機器人體表面積及負荷有限。而生物同一信息交互媒介可以完成多種環境信息交互,故設計一種陣列式傳感器,信息采集單元分為散射式與同心式,采用通道復用及時間復用算法,使一種傳感器完成相應多維環境信息交互。
2 機器人信息處理
2.1 數據降維
目前數據降維分為線性降維和非線性降維,降維方法也多種多樣,而對于機器人采集得到的環境信息,應能使數據降維之后在思維決策時快速復原,因此需要盡可能地保留數據信息,所以采取線性降維的PCA降維方法,文獻[15]列出了其主要算法。假設對于環境信息向量,我們有 m 個數據 X1,X2,X3,…,Xm,其中 Xi∈Rn,這些數據已經被中心歸零化,即

定義其協方差矩陣

因為C為半正定矩陣,對其進行去角化,得

其中 Λ=diag(λ1,λ2,…λn)VVT=1。假設 C 的秩為 p,那么C有個非零的特征值,記為
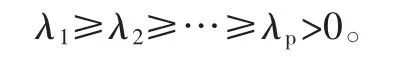
我們取前k個特征值所對應的特征向量V1,V2…Vk作為我們的投影方向,那么對于任何一個樣本Xi,我們計算 Yi=Vi,i=1,2,....,k,那么我們可以用[Y1,Y2,…Yk]T來表示樣本Xi,這樣便將數據從n維降到k維。當k=n=p時,即C滿秩,并且我們去n個基進行投影時,PCA就相當于對坐標系進行了正交變換。
PCA主要思想是將數據向使得投影方差較大的方向投影,這樣可以盡可能地保留數據信息,可以用圖1說明。對于機器人與環境信息交互,在機器人思維決策,需要盡可能完整復原原信息來說,PCA是有很明確的物理意義的。
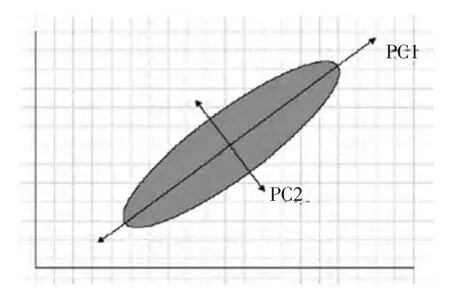
圖1 PCA示意圖
2.2 稀疏學習
稀疏是感知的重要特征之一,稀疏學習只需要少量的觀察值和特征集合就能夠很好的對高維數據進行處理分析,這將克服傳統的信號表示中由于基函數的正交性和完備性帶來的缺陷[16]。機器人在與環境進行信息交互及思維決策時,需要快速讀取記憶庫數據并進行匹配,因此處理的數據量應盡量小,從而保證響應速度,因此需要對少量觀察值及特征值進行處理。根據機器人與周邊環境進行信息交互的特征,對比各種稀疏學習算法,應用文獻[17]中Sparse K_SVD算法進行稀疏學習。
任意長度為N的一維信息Xi∈RN,通過冗余字典D∈RN×K,可稀疏表示為
素心道:“就為二阿哥認床,主子不是囑咐乳母把潛邸時二阿哥睡慣的床挪到了阿哥所么?宮里又足足添了十六個乳母嬤嬤照應,斷不會有差池的。”
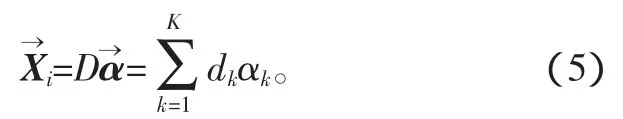
式中:α為信息的稀疏表示系數,為K×1的向量;dk為給定冗余字典D中的一個原子;αk為α向量中與dk相對應的值。信息的稀疏表示是從冗余字典中選擇具有最佳線性組合的若干原子來表示信號,實際上是一種逼近過程,從稀疏逼近角度出發,希望在逼近殘差達到最小的情況下得到α最稀疏的一個解,這等同于解決下述問題:
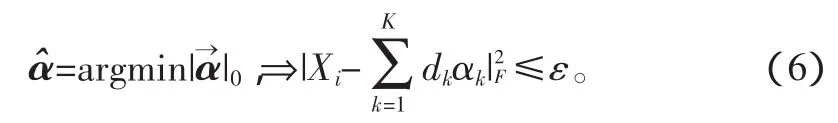
考慮機器人與環境交互信息為加性信息,其單一維度信息模型表示如下:
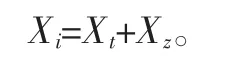
式中:Xi為原始信息;Xt為特征信息;Xz為雜散信息。根據式(6)從冗余字典D中選取最佳線性組合的若干原子來表示原始信息Xi,當逼近殘差足夠小時,利用式(6)求解的稀疏矩陣,通過重構的和特征信息Xt近似,從而把特征信息從信息中提取出來。
3 機器人信息機制
3.1 學習機制
按照人工智能大師H.Simon的觀點,機器學習就是系統在不斷重復的過程中對本身能力的增強或改進,使得系統再執行同樣或類似的任務時,會比原來做得更好或效率更高。機器學習是一個有特定目的的知識獲取過程,其內部表現為從未知到已知這樣一個知識增長過程,其外部表現為系統的某些性能和適應性的改善,使得系統能夠完成原來不能完成或更好地完成原可以完成的任務。機器學習旨在如何使機器通過識別和利用現有知識來獲取新知識的技能,既要注重知識本身的增加,也注重獲取知識的技能的提高[14]。
傳統機器學習算法如圖2所示,其對當前周邊信息進行的思維決策根據主要來自于知識庫以及當前環境信息,但其機器學習知識來自于當前環境信息,而未與知識庫構成反饋。改進后機器學習模型如圖3所示。機器人思維決策根據來自于當前環境信息,機器人知識學習由知識庫與學習行為構成反饋閉環,再與當前環境信息共同影響機器人學習行為。使其得到更好的決策結果,且機器人進行思維決策之后,對知識庫中的知識有重學習及重記憶的反饋過程。

圖2 傳統機器人學習模型

圖3 改進機器學習算法
3.2 遺忘機制
根據生物特性,生物對于信息的記憶性主要由信息的重要性、使用頻率、經過時間來決定。人對環境信息以及新學習知識對于經過時間的遺忘規律有著名的艾賓浩斯遺忘曲線,即遺忘在學習之后立即開始,而且遺忘的進程并不是均勻的。最初遺忘速度很快,以后逐漸緩慢,保持和遺忘是時間的函數。設記憶后經歷了時間t0,則記憶量為
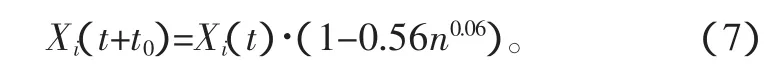
可見,生物的記憶對于時間是指數性反比關系,而指數型數據處理難度較大,對機器人的信息響應速度影響也較大,故對于機器人記憶相對于時間采用線性反比性函數關系,設機器人記憶后經歷了時間t0,記憶量為
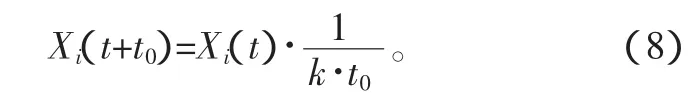
如式(7)及式(8),Xi(t+t0)為經過t0后記憶庫中的信息,Xi(t)為原始信息,k為時間比例系數,其取值由擬合逼近使式(8)與式(7)殘差最小化。
對于信息使用頻率對機器人記憶庫中信息的影響,具有時間一致性的各信息,使用頻率越大,在經過同樣時間后,記憶庫中信息量各異,使用頻率對機器人記憶庫信息的影響為正向性關系。如經過時間對機器人記憶庫影響,建立線性正比關系:
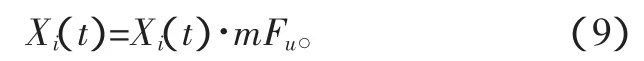
式中:Xi(t)為記憶庫原始信息;Fu為該信息被機器人使用頻率;m為頻率系數,根據信息不增性,應滿足mFu≤1。
由上述,信息的重要性對記憶庫中信息也有影響,信息重要性分為相對重要性及絕對重要性。某一信息量若具有絕對重要性,那么對其他信息量具有信息屏蔽(信息阻塞)作用。某一信息具有相對重要性,那么相對其他信息量在機器人進行多信息綜合決策具有優先權。令X0(t)為標記信息量,對各信息量重要性進行線性加權,則

式中:PXi(t)為信息量Xi(t)的相對重要性;qi為其相對比例系數,若其具有絕對重要性,則qi>>1。
4 機器人思維模型
生物的思維可建立成如下模型,環境信息刺激,生物對信息分析,思維決策,信息學習、記憶或重記憶,其具體模型如圖4所示。根據生物思維模型,機器人思維模型如圖5所示,機器人獲得的環境信息,是具有時間一致性的各單一維度信息集合,經過分解成單一維度信息向量,再經過單一維度信息向量的信息降維,減少數據計算量,然后經過適合機器學習的K_SVD稀疏算法,并結合機器人記憶庫中的的已有知識,進行當前信息的思維決策、機器人學習以及記憶庫的完善等。對于機器人存在的遺忘機制,對于信息缺失,信息遺忘等問題,由記憶庫完善及機器人再學習及重記憶完成。
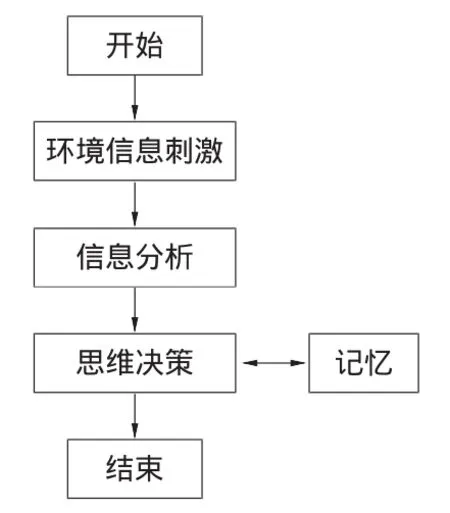
圖4 生物思維模型
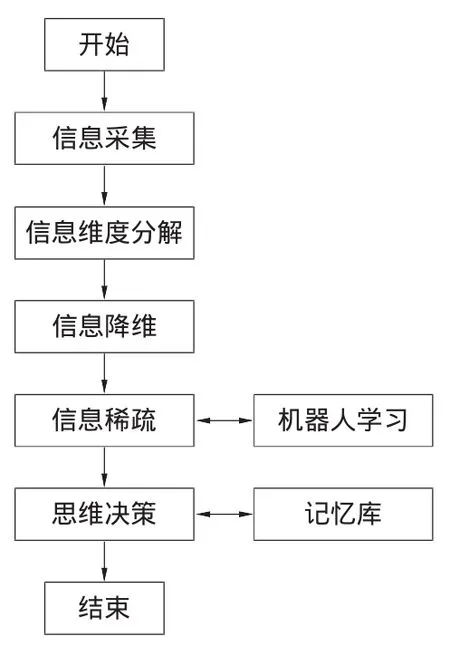
圖5 機器人思維模型
5 結語
提出了一種機器人自主思維方法,根據生物特性,結合PCA降維方法及Sparse K_SVD算法,建立機器人學習機制及遺忘機制,解決傳統機器人無法離線學習、任務確定以及智能擴展性差、無法適應多變的環境等多種局限性問題,有效提升了機器人的實用性及智能性。
[1] 陳巍.聚焦“機器思維”的跨學科思維盛宴[J].科技導報,2011,29(14):80.
[2] 翟心昱.基于仿人腦認知計算模型的機器人視覺學習方法[D].杭州:浙江工業大學,2012.
[3] 張麗.基于HTN方法的記憶機器人任務規劃研究[D].哈爾濱:哈爾濱工業大學,2010.
[4] United Nations Global Pulse.2012,Big Data for Development:Challenges&Opportunities[R].2012.
[5] Office of Science and Technology Policy.Executive Office of the President.2012,Fact Sheet:Big Dataacrossthe Federal Government[R/OL].[2012-12-21].Http://www.whiteHouse.gov/Ostp.
[6] Office of Science and Technology Policy.Executive Office of the President.2012,Obama Administration Unveils “Big Data”Initiative:Announces$200 Million in New R&D Investments[R/OL].[2012-03-19].http://WWW.WhiteHouse.gov/OSTP.
[7] Mckinsey Global Institute.2011 Big Data the Next Frontier for Innovation,Competition,and Productivity[R].2011.
[8] Rajaraman A,Ullman J D.Mining of Massive Data-sets[M].Cambridge:Cambridge University Press,2011.
[9] Lapkin A.Hype Cycle for Big Data[R].Gartner,Inc.2012.
[10] Miller H J,Han J.Geographic Data Mining and Knowledge Discovery[M].London:Taylor and Francis,2009.
[11] Barabasi A L.Bursts:The Hid den Patterns Behind Everything We Do[M].Plume Books,2011.
[12] 舍恩伯格,庫克耶.大數據時代:生活、工作與思維的大變革[M].盛楊燕,周濤,譯.杭州:浙江人民出版社,2012.
[13] 李健宏.人工智能中的機器學習研究及其應用[J].江西科技師范學院學報,2004(5):84-86.
[14] 馬小龍.數據降維方法綜述[D].北京:清華大學,2005.
[15] 宋彩風,劉偉鋒,王延江.基于稀疏學習的人臉表情識別[J].山東科技大學學報(自然科學版),2013,32(3):28-34.
[16] 黃玲,李琳,王薇,等.基于Sparse K-SVD學習字典的語音增強方法[J].廈門大學學報(自然科學版),2014,53(1):36-40.
猜你喜歡
小哥白尼(野生動物)(2022年6期)2022-08-17 08:05:28
小哥白尼(野生動物)(2022年4期)2022-07-16 03:37:32
小哥白尼(野生動物)(2022年2期)2022-06-01 06:21:20
小哥白尼(野生動物)(2022年1期)2022-04-26 14:01:18
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
