多文種融合文字書寫教學知識及其自動生成方法
2015-12-06 06:11:40李文濤彭喻杰謝建斌
計算機工程 2015年11期
關鍵詞:教學
李文濤,戴 永,彭喻杰,謝建斌
(湘潭大學智能計算與信息處理教育部重點實驗室,湖南湘潭411105)
多文種融合文字書寫教學知識及其自動生成方法
李文濤,戴 永,彭喻杰,謝建斌
(湘潭大學智能計算與信息處理教育部重點實驗室,湖南湘潭411105)
多文種融合文字書寫教學系統的教學資源具有多語源的特點,但存在知識點數據類型多、計算結構復雜等不足。為此,依據不同文種文字書寫的異性與共性規律,提出基于文字書寫過程計算的知識點自動生成方法。將多文種的筆畫、筆畫關系、部件關系等計算元按共享、分類,給出各類計算元編碼空間的計算方法,定義面向各文種通用的文字書寫過程計算模型,設計并實現計算模型中各計算元編碼的自動生成算法。實驗結果表明,該方法能準確識別各種知識要素,筆畫及各類關系的識別正確率達到98.3%,與人工編碼相比,錄入速率提高15%,冗碼率降低23%。
多文種融合;文字書寫教學;知識點;文字書寫過程計算模型;計算元;自動編碼
1 概述
作為文字書寫自動教學系統[1-2],文字書寫教學知識是實現系統教學功能的必備資源。教學知識研究包括兩方面內容,即知識庫結構與知識點。知識庫結構研究已趨成熟[3-4],單文種知識點的構造方法已進入實用階段,如文獻[5]采用筆畫以及筆畫書寫順序作為知識點結構來指導英文字母書寫;文獻[9]按筆畫與筆畫關系知識點結構設計了基于關系圖的漢字匹配算法指導漢字書寫。知識點構建方法分手動和自動兩大類,知識面窄、量少時可以采用手動,多文種融合使得知識點數據類型多、計算結構復雜及知識量大等,為提高工作效率與知識正確率應采用自動方法。本文依據不同文種書寫過程所具備的公共與獨特形態、公共與獨特規則,提出多文種文字書寫教學的通用教學知識點結構及其自動生成的方法。將各文種的筆畫與關系分為共享及獨特兩大類;設計綜合兩類的編碼結構;給出各類計算元編碼空間的計算方法,定義文字書寫過程計算模型,實現知識點主導筆順、錯交筆順、錯離筆順等的自動編碼,缺省的融合文種含漢字、英文、漢語拼音。
2 文字結構分析
筆畫、筆畫關系、部件關系是文字結構的要素,也是文字書寫教學的基本內容。不同文種有各自的筆畫、筆畫關系、部件關系集合,在形態及書寫過程等方面雖獨具特色但也不可避免會形成相交內容。
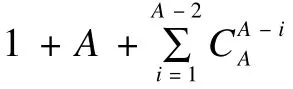

其中,α(·)表示多文種共享的筆畫數目;β(·)表示由“·”個文種的共享筆畫構成的集合,記共享筆畫數量為:

用f(us)表示A個文種的獨特筆畫數目:

A種文種融合后的筆畫全集記為:

各筆畫子集之間無交集。
同理可計算融合后總的筆畫關系子集數量F(sr)、部件關系子集數量F(pr)。分別用λ(·),χ(·)依次表示共享筆畫關系、部件關系的數目,用φ(·),φ(·)分別依次表示共享筆畫關系、部件關系元素構成的集合,共享筆畫關系數量f(ssr)和共享部件關系數量f(spr)計算結構與式(2)相同。獨特筆畫關系數量f(usr)和獨特部件關系數量f(upr)計算結構與式(3)相同。A種文種融合后的筆畫關系、部件關系全集分別依次記為φ,φ,各子集關系描述類同β。用L表示文種,表1給出A種文種筆畫的共享與獨特情況分析,筆畫關系、部件關系分析結構類同,即將筆畫子集的β,w分別依次用φ,r*和φ,rρ替代便可。

表1 A種文種融合筆畫共享與獨特情況
為適用多文種通用的部件描述,部件分割采用定制法,即當緊鄰前后2條筆畫的空間位置關系超出所在系統設置的分析能力,稱其為具有不可計算性,并認為此2條筆畫處于2個相鄰的部件中,在2條筆畫間插入部件關系符。
3 知識結構設計
教學知識點通用的基本內容與結構如圖1所示。

圖1 通用的文字書寫教學知識點結構
第2字段為被教學文字的標準編碼,如漢字采用國標GB2312-80編碼(區位碼),英文字母采用ASCII碼等;第3字段、第4字段用于文字書寫質量分析[7];第5字段用于產生文字語音碼[8]。第1字段是被練習文字書寫過程的計算結構,計算元為筆畫、筆畫關系、部件關系等要素,為本文的重點研究對象。
3.1 元編碼計算
對計算元編碼應滿足的基本要求為:(1)不同計算元有明顯的數值段;(2)能體現不同文種共享與獨特計算元的區別;(3)具有能自動適用于文種增加和計算元補充的編碼變換機制等。

采用10進制數字編碼。以筆畫編碼為基準編碼,單粒度占用編碼范圍為1~(f(ss)+f(us)),當粒度為m時,編碼范圍為1~m×(f(ss)+f(us)),考慮筆畫的擴充,設置編碼裕量。記ε(ss),ε(us)分別依次為共享、獨特筆畫編碼裕量,則確認的筆畫編碼范圍為1~m×(f(ss)+ε(ss)+f(us)+ε(us)),最大值需j位表示,個位為1高位為j-1個0是首條共享筆畫的編碼。編碼數目為m×(f(ss)+ε(ss)+f(us)+ε(us))。w的最高位位值用bitmax表示,令B1為對應于筆畫關系r*類編碼,當w(bitmax)+b≤9,b∈{1,2,…,8},B1取j位,且w(bitmax)<B1(bitmax)≤w(bitmax)+b,低j-1位編碼全取0;否則B1取j+1位,B1(bitmax)=1,低j位編碼全取0。確認的r*類編碼范圍為B1(bitmax)×10(j-1 orj)~[B1(bitmax)× 10(j-1∩or∩j)+(f(ssr)+ε(ssr)+f(usr)+ε(usr))],ε(ssr),ε(usr)分別依次為共享、獨特筆畫關系編碼裕量。B1(bitmax)×10(j-1 or j)為首個共享筆畫關系的編碼。從文字書寫教學的角度出發,筆畫關系編碼需進行多層次空間關系描述。設建立e層空間關系,r*編碼的完整結構定義為B1(B2B3…Be+1),B2B3…Be+1為空間關系細分描述碼,Bi是對Bi-1的進一步細分(i∈{2,3,…,e+1},Bi∈{0,1,…,9}),e+1越大,空間關系描述越精細。設b2b3…be+1依次分別對應B2B3…Be+1的取碼數量,筆畫關系編碼數目為(f(ssr)+ε(ssr)+f(usr)+ε(usr))×b2× b3…×be+1。部件關系與筆畫關系的接碼及其編碼原理基本類似筆畫關系與筆畫,不同之處在于部件關系編碼的結尾碼字標注的該部件與后續多少部件構成該關系編碼所標注的關系,用x表示結尾碼,其缺省值為1,x無當前空間標識作用,因此不影響編碼數量。
算法1 編碼空間生成
輸入 m,f(ss),f(us),ε(ss),ε(us),f(ssr),f(usr),ε(ssr),ε(usr),e(sr),f(spr),f(upr),ε(spr),ε(upr),e(pr)

3.2 結構計算
文字書寫過程的計算內容及其關系定義為:主導筆順||錯交筆順||錯離筆順。


圖2 文字示例
以Q表示文字的書寫過程計算結構,書寫過程中的定制部件記為M,Q定義為:


為便于式(5)各計算元的分類輸入與庫存管理、筆順跟蹤及逆跨分析等,按后綴波蘭式結構重排計算元。去掉“+”號,用Q(B)表示Q的后綴波蘭式,于是:
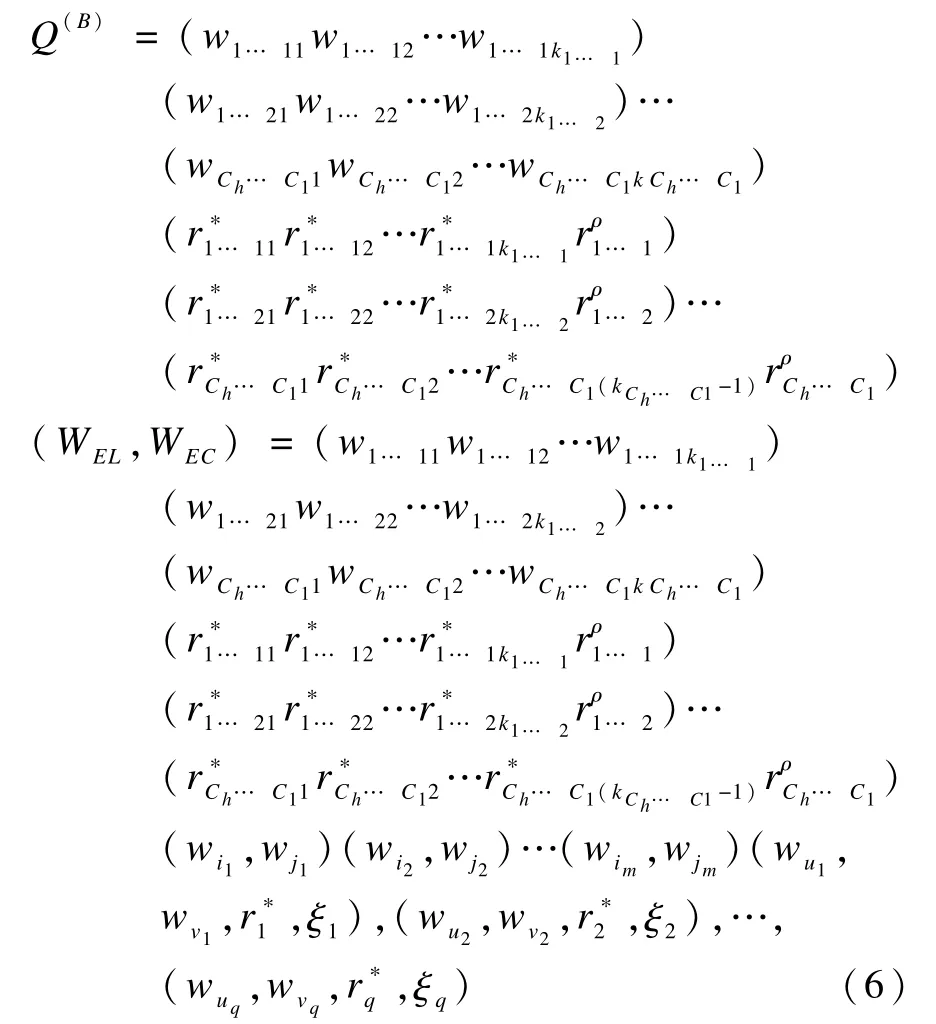
4 知識碼的自動生成
將式(6)表示為向量,即有:
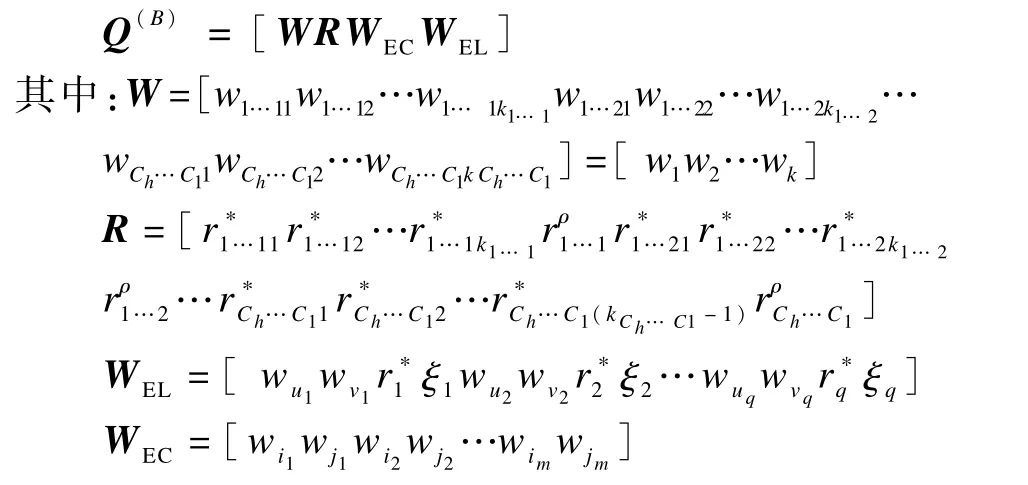
通過對文字標準書寫結構的跟蹤生成W,R,WEC,WEL。
4.1 主導筆順碼鏈的生成
主導筆順碼鏈生成是基礎。跟蹤主導筆順不但要給出W,R,還要為生成WEC,WEL準備筆畫數據。R中既有r*,也有rρ,兩者的生成方法有較大區別。4.1.1 筆畫與筆畫關系編碼
借鑒已有成果[9-10]對當前書寫筆畫wi(i=2,3,…,k)進行識別,將識別結果的筆畫編碼有序存入W。在wi,wi-1之間進行e+1次計算分析,將r*i-1的屬性編碼有序存入R。當wi,wi-1之間無法在系統中找到相應的計算模型分析時,在wi,wi-1之間預置部件分割的通用標志。寫完文字最后一條筆畫,即i=k,W生成結束;R中r*有確定的代碼,但其中需進一步分析;提供k行筆跡數據陣列S[k, lmax],lmax為該字最長的筆畫筆跡點數量。
4.1.2 部件關系編碼
部件關系依托R,S[k,lmax]分析。設R中存在m個。在R中搜素到(j=1,2,…,m),在S[k,lmax]中獲取Mj,Mj+1所含w,利用φ元素所適用的計算模型分析關系,將分析結果對應的編碼有序存于位置。第1輪均按x=1建立部件關系,第2輪進行跨部件關系分析,即如果關系與關系相同,則x+1。依次類推,直至j=m-2。
4.2 錯交筆順向量的生成
文字書寫主導筆順正確,進行錯交碼對偶預測。在S[k,lmax]中,對于wi,wj(i>j+1,i,j∈{1,2,…,k}),將wi兩端點的筆段按其形態進行延伸,對所有的wj(j∈{i-2,i-3,…,1})進行十字交關系分析,形成初選筆畫書寫序號構成的十字交序號對偶序列,借助共享工作容器進行對偶元素去留分析,分析模型為S[k,lmax]。
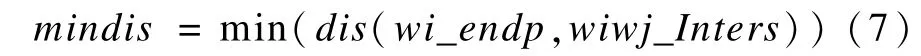
即將wi端點到wi,wj交點距離最短的那一對(i,j)有序填入WEC。dis(wi-endp,w iw j-Inters)為wi端點到wi,wj十字交點的距離計算函數。
4.3 錯離筆順向量生成
對于書寫結構確認正確的W,設其存在q對有可能產生錯離的筆畫,在S[k,lmax]中取第τ對可能產生錯離的wi,wj(i>j+1,i,j∈{1,2,…k}),記為wiτ,wjτ,τ=1,2,…,q,識別wiτ,wjτ之間的關系,并根據類別選擇ξ,將對應的編碼、當前(i,j)和ξ一起構成結構,將此結構先存儲在共享工作容器內。如此,完成q對筆畫的錯離碼鏈在WEL中的生成。
4.4 算法設計
知識碼鏈的生成過程分為2個階段,第1階段是跟蹤文字書寫過程實時生成W、R中的r*及S[k,lmax];第2階段是基于S[k,lmax]生成R中的rρ與WEC,WEL。主要步驟如下:
算法2 Q(B)生成
Step1 讀入當前書寫筆畫數據;
Step2 對筆畫數據進行前置處理[11],并有序存入S[k,lmax];
Step3 識別當前筆畫,將對應的筆畫編碼有序存入W;
Step4 對于非第1條筆畫,分析其與前條筆畫的關系,存在關系,將關系碼有序存入R;不存在則存入部件分割標注;
Step5 是否有文字寫完信息,無則轉Step1;
Step6 基于S[k,lmax]查詢部件分割標志,識別部件關系,將關系碼替代分割標志符;
Step7 基于預測錯交筆畫,將預測的錯交筆畫的序號對偶有序存入WEC;
Step8 基于S[k,lmax]預測錯離筆畫,將預測的錯離筆畫的4元結構有序存入WEL;
Step9 結束。
5 實驗測試及結果分析
實驗平臺主要硬件模塊包括7英寸觸摸屏及S3C2440A,32 bit ARM 920T內核及其控制器,標準配置64 MB NAND-FLASH,標準配置64 MB SDRAM等。軟件開發環境為VS2005,操作系統為W ince 5.0,開發語言為C++。以漢字(L1)、英文(L2)、漢拼(L3)融合為例,即A=3。3文種融合的相關信息結構如表2所示。

表2 3文種計算元共享與獨特內容及其對應的編碼空間
表2中沒有參數的子集欄目表明該子集為空。取筆畫粒度m=2,即筆畫規模按長、短2種狀態設置,f(ss)+f(us)=72,取ε(ss)=10,ε(us)=17,編碼空間為001~198;筆畫關系空間采用3-3細分編碼,即e(sr)= 2,b2=3,b3=3,B2,B3∈{0,1,2}f(ssr)=4,f(usr)=5,取ε(ssr)=2,ε(usr)=9,編碼空間為20 000~21 922;部件關系空間采用3區位細分編碼,即e(pr)=1,b2=3,B2∈{0,1,2},f(spr)=2,f(upr)=1,取ε(spr)=2,ε(upr)= 5,編碼空間為3 000x~3 192x。3類計算元編碼空間欄給出由算法1生成的相應類計算元編碼空間。圖3所示為“體”、“E”字的書寫教學知識形態或模板結構及其Q(B)的生成內容。
對于模板“體”,寫完第1條筆畫,筆跡點坐標數據被記錄于S[1],筆畫識別模塊將該識別結果“008”存于Cstroke(筆畫碼)容器,并在圖3(a)界面的W子窗口顯示;第2條寫完,筆跡數據放入S[2],識別結果“006”放入前條筆畫編碼之后。依據S[1]、S[2]進行第2條筆畫、第1條筆畫關系識別,該關系為T字交關系,生存的編碼為“20311”,存于Crelation(關系碼)容器,并顯示于圖3(a)的R子窗口。第3畫“短橫”與第2畫“長豎”本系統無法確定兩者空間關系,在第2畫之后插入部件分割標志代碼p,將兩者定制在兩個緊鄰部件中,并記錄該標志在Crelation中序號。如此直至第7條筆畫即該字的最后一條筆畫寫完,主導筆順的Cstroke生成結束,Crelation筆畫關系編碼生成完畢,但部件關系待進一步分析確定。“體”的書寫數據S[k,lmax]如表3所示,其中,k=7,lmax=42,xmax=63,xmin=19,ymax= 62,ymin=24。

圖3 文字書寫教學知識生成實例
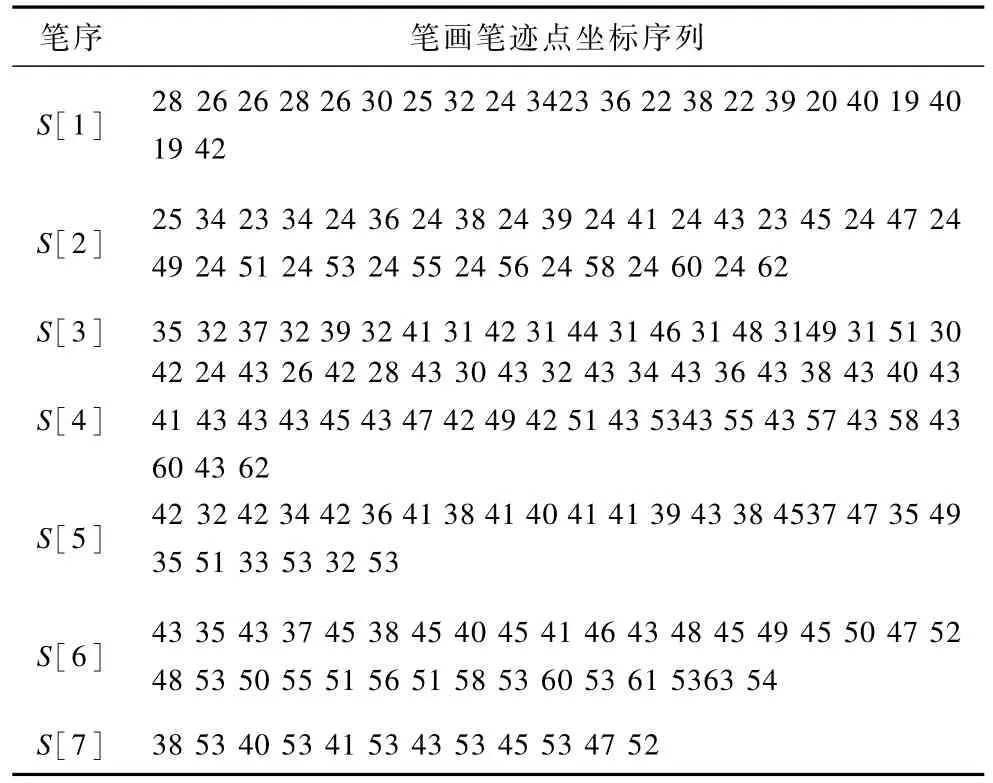
表3 “體”字S[k,lmax]
根據記錄的標注符在Crelation中的序號,第1輪按序進行由標注符分割的筆畫子集(部件)之間的關系識別。該文字只記錄了1個標注符,且序號為2,即圖3(a)“體”在書寫過程中被定制為M 1和M 22個部件,M 1?{S[1],S[2]},M 2?{S[3],S[4],S[5],S[6],S[7]}。利用均質比較法識別M 1,M 2關系為居中左右關系,賦予30011碼,該碼存于Crelation容器,并顯示在圖3(a)的R子窗口。
從S[3]開始進行錯交預測。端點筆段長度取5,延伸步長取2,延伸長度至文字最值邊線,預測結果存入Cerrorc(錯交碼)容器,并顯示在圖3(a)的WEC子窗口。從S[3]開始進行錯離預測,十字交取ξ=0,點與筆畫T字交取ξ=2,端點T字取ξ=5,預測結果存入Cerrorl(錯離碼)容器,并顯示在圖3(a)的WEL子窗口。
圖3(b)為英文大寫字母“E”的書寫模板及其Q(B),該字存在一對預測錯交筆畫,無錯離結構。
對30個英文字母、30個漢語拼音字母、340個漢字進行編碼實驗,正確率達到98.3%,錄入速率與人工編碼比較,效率提高15%,冗碼率如圖4所示,字數越多,人工冗碼率越大,而自動編碼較平穩。
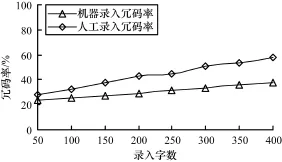
圖4 手動與自動生成知識點冗碼率對比
6 結束語
教學知識點的自動生成是多文種融合的文字書寫教學系統核心技術之一。教學知識點的內容結構具有雙重性,過于簡單生成容易,但影響教學效果和質量,乃至系統的實用性;過于復雜又會導致系統的存儲、速度、算法復雜度等開銷增大。本文方法在文獻[1]系統中得到應用,編碼與建模方法按文獻[12-13]等予以改進,結構分析方法借鑒文獻[14-15]等進行優化,相應的教室系統見文獻[16]。
本文從人們書寫文字的共性出發,提煉不同文種文字的共享結構與獨特結構進行探索,給出多文種融合的計算元數量及其編碼空間計算規則;提出多文種通用的基于筆畫、筆畫關系及部件關系等計算元的文字書寫過程計算模型;設計并實現了知識點各字段的生成算法。實驗結果表明,該方法筆畫及各類關系識別的正確率達到98.3%,錄入效率提高15%。
[1] 戴 永,劉任任,王求真,等.可聯網交互的多功能規定格式習字系統及方法:中國,ZL201010149767.2[P]. 2010-09-01.
[2] Hammadi M,Bezine H,Njah S,et al.Towards an Educational Tool for Arabic Handwriting Learning[C]// Proceedings of IEEE ICEELI'12.Wacington D.C.,USA:IEEE Press,2012:1-6.
[3] Kherallah M,Bouri F,Alimi A M.On-line Arabic Handwriting Recognition System Based on Visual Encoding and Genetic Algorithm[J].Engineering Applications of Artificial Intelligence,2009,22(1):153-170.
[4] 鄢 琦,駱仁波,皮佑國.無字庫智能造字中漢字基元的統計分析與預測[J].計算機研究與發展,2012,22(4):33-36.
[5] 戴 永,王心覺,張維靜,等.面向指導的自由式英文字母書寫跟蹤[J].湘潭大學自然科學學報,2012,34(2):85-89.
[6] Hu Z,Leung H,Xu Y.Automated Chinese Handwriting Error Detection Using Attributed Relational Graph Matching[C]//Proceedings of ICWL'08.Berlin,Germ any:Springer,2008:344-355.
[7] 王 耀,戴 永.規定格式文字書寫練習質量普適評價[J].計算機工程與應用,2010,46(29):69-72.
[8] 孫廣武,戴 永,喻世東,等.音素關聯的多文種語音融合編碼方法[J].計算機工程與應用,2013,49(19):217-221.
[9] Liu C L,Jaeger S,Nakagawa M.Online Recognition of Chinese Characters:The State-of-the-art[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(2):198-213.
[10] Tan C K.An Algorithm for Online Strokes Verification of Chinese Characters Using Discrete Features[C]// Proceedings of the 8th International Workshop on Frontiers in Handwriting Recognition.Wacington D.C.,USA:IEEE Press,2002:339-344.
[11] 覃冰梅,戴 永,樊 亮.面向聯機書寫指導的觸摸筆跡信息前置處理[J].計算機應用研究,2012,29(9):3365-3368.
[12] Chen Tieling,Dylon E,M a Jun.Binary Search Tree with Vine[J].Natural Science Journal of Xiangtan University,2013,35(3):1-8.
[13] 余 英,羅永超,程明寶.帶分批的一類具有惡化加工時間的排序問題的算法研究[J].湘潭大學自然科學學報,2013,35(2):14-16.
[14] 任 昆,戴 永,王求真,等.上下文感知手寫數學公式結構分析[J].湘潭大學自然科學學報,2014,36(2):85-91.
[15] 游應德,李成大.一種邊界梯度組合的圖像識別技術與分割方法[J].湘潭大學自然科學學報,2014,36(2):99-103.
[16] 喻世東,戴 永,王求真,等.適用于文字書寫教學教室系統的嵌入式局域網協議[J].計算機工程,2014,40(9):284-290.
編輯 索書志
Multilingual Integration Text Writing Teaching Know ledge and Its Automatic Generation Method
LI Wentao,DAIYong,PENG Yujie,XIE Jianbin
(Key Laboratory of Intelligent Computing and Information Processing,Ministry of Education,Xiangtan University,Xiangtan 411105,China)
The teaching resources features of multilingual integration writing teaching system expresses asmultilingual sources leading to data types of know ledgemore,comp lex calculation structures,greater know ledge and so on.According to heterosexual and common rule of writing in different languages,the method is proposed based on the know ledge automatic generation of the calculating of writing on the process.The Computing elements including stroke,stroke relations,component relations are classified by sharing,unique,and the calculation method of all kinds of computing elements coding space is given,the general writing on the process of calculating model which is know ledge structure for the various text types is defined,the automatic generation algorithm of each computing element coding in calculation model is designed and realized.Experimental results show that the generation method can accurately identify various know ledge elements,correct identification rate of strokes and various relations reaches 98.3%,the rate of entry improves 15%efficiency compared with manual coding,redundancy rate decreases by 23%.
multilingual integration;text writing teaching;know ledge point;calculation model of text writing process;computing element;automatic coding
李文濤,戴 永,彭喻杰,等.多文種融合文字書寫教學知識及其自動生成方法[J].計算機工程,2015,41(11):218-223,231.
英文引用格式:Li Wentao,Dai Yong,Peng Yujie,et al.Multilingual Integration Text Writing Teaching Know ledge and Its Automatic Generation Method[J].Computer Engineering,2015,41(11):218-223,231.
1000-3428(2015)11-0218-06
A
TP18
10.3969/j.issn.1000-3428.2015.11.038
湖南省教育廳基金資助項目(13C914);湖南省“十二五”重點學科建設基金資助項目。
李文濤(1986-),男,碩士研究生,主研方向:知識處理,智能系統;戴 永,教授;彭喻杰,講師;謝建斌,碩士研究生。
2014-10-10
2014-11-29 E-m ail:liw entaoss@sohu.com
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:50
作文成功之路·小學版(2020年7期)2020-08-24 08:20:14
作文成功之路·小學版(2020年6期)2020-07-27 01:48:22
甘肅教育(2020年12期)2020-04-13 06:25:34
頌雅風·藝術月刊(2019年11期)2019-03-15 09:23:46
東方教育(2017年19期)2017-12-05 15:14:48
唐山文學(2016年2期)2017-01-15 14:03:59
中國音樂教育(2016年2期)2016-05-20 10:11:10
中學語文(2015年6期)2015-03-01 03:51:42
中國教育技術裝備(2015年6期)2015-03-01 02:36:31
