一種基于AutoEncoder的RBF神經網絡訓練算法
2015-11-01 09:19:00馬艷東
中國科技信息 2015年9期
關鍵詞:方法
馬艷東
一種基于AutoEncoder的RBF神經網絡訓練算法
馬艷東
RBF神經網絡中心寬度等參數確定的是否合理將直接影響到RBF網絡的學習性能。通過有監督學習的方法來確定RBF神經網絡的參數是最一般化的方法。研究表明,參數的初始化問題是該類方法的關鍵所在。為此,提出了一種利用AutoEncoder初始化RBF神經網絡各個參數的新型訓練算法。實驗仿真表明,與傳統RBF神經網絡訓練算法相比,該新型算法具有更高的訓練精度與更強的泛化能力。
徑向基函數(Radial Basis Function,RBF)神經網絡是一種高效的前饋神經網絡,相對于傳統BP(Back Propagation)神經網絡,不僅具有結構簡單、收斂速度快、泛化能力強等特點,而且還具有優異的函數逼近,全局尋優和最佳逼近能力。因此,RBF神經網絡廣泛應用于模式識別、語言識別、圖像處理和工業控制等領域。研究表明,RBF神經網絡節點的寬度、中心、權重等參數確定的是否合理將直接影響到RBF神經網絡的學習性能。通過有監督學習的方法來確定RBF神經網絡的中心等參數是最一般化的方法。而在這類方法中,參數的初始化問題是關鍵點。而目前采用最普遍的方法是隨機初始化各個參數。但是,由于隨機選擇的各個參數不能夠保證距離最優點的距離足夠近。因此,該方法也導致RBF神經網絡訓練不穩定,容易陷入局部最優。為此,不管從學術研究角度,還是從實際應用角度來說,都需要一種方法能夠很好地確定RBF神經網絡的各個參數,至少是給個合理的初始化參數。
深度學習(Deep Learning)是人工智能領域最前沿技術,通過建立、模擬人腦視覺系統來進行分析學習的神經網絡,在圖像識別、語音識別、語義識別等領域表現出了強大的從少數樣本中學習數據集本質特征的能力。本文提出采用深度學習中的自動編碼器(AutoEncoder)改進RBF神經網絡訓練算法,用無監督數據訓練的權重作為RBF網絡各參數的初始化值,然后利用有標簽數據,采用有導師訓練算法調整各個參數的數值。最后利用訓練好的網絡來分類或擬合。
RBF神經網絡
RBF神經網絡是一種特殊的三層前饋神經網絡,它能夠以任意精度逼近任意連續函數。RBF神經網絡結構(如圖2)包括一個輸入層、一個隱含層和一個輸出層,隱含層神經元的個數由具體問題的實際情況決定。輸入層節點只傳輸信號到隱含層,負責將網絡與外界實際連接起來。隱含層結點由徑向基函數構成,其主要作用是輸入空間到隱含層空間之間進行非線性變換,在大多數情況下,隱含層空間有較高的維數。而輸出層節點通常是由簡單的線性函數構成,其作用主要是為輸入層信號作出最終響應。
RBF神經網絡的函數表達式為:
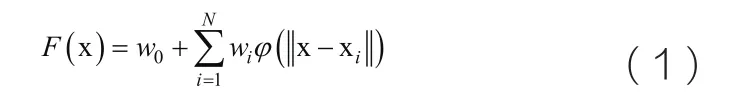
由于RBF神經網絡隱含層結點常用的徑向基函數是高斯(Gauss)函數,則RBF神經網絡的表達式可以寫為:
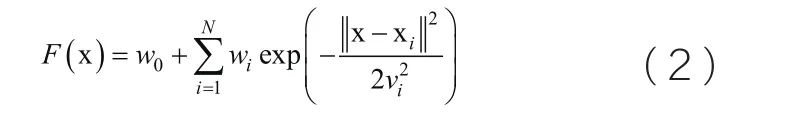
RBF神經網絡的訓練算法如下。
Step 1:隨機初始化徑向基函數的中心、半徑與隱含層到輸出層的連接權重。
Step 2:通過梯度下降方法來對神經網絡中三種參數進行監督訓練優化。其代價函數是網絡實際輸出F( x)與其期望輸出d 的均方誤差:

然后,每次迭代,在誤差梯度的負方向上,以一定的學習速率調整參數。下面是各個參數的更新函數。
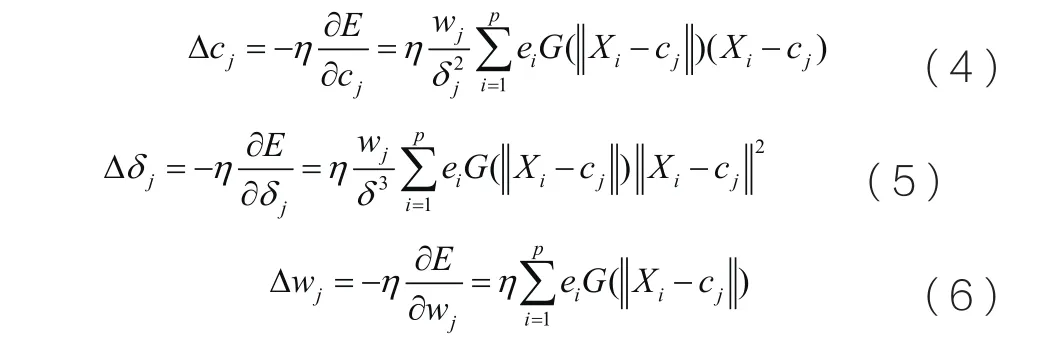
其中,cj為第j個隱含層神經元節點的中心,?cj為第j個隱含層神經元節點中心的的更新步長。δj為第j個隱含層神經元節點的寬度,?δj為第j個隱含層神經元節點寬度的的更新步長。wj為第j個隱含層神經元節點與輸出層節點的連接權重,?δj為第j個隱含層神經元節點與輸出層節點的連接權重的更新步長。
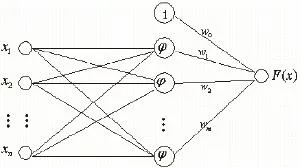
圖1 徑向基函數神經網絡結構圖

圖2 AutoEncoder原理圖
AutoEncoder自動編碼器
AutoEncoder自動編碼器是深度學習領域重要算法之一,是利用人工神經網絡具有層次結構的特點,假定其輸出數據與輸入數據相同,即輸入數據的類標是其本身。然后,訓練調整網絡各個參數,得到每一層結點的參數及權重。通常隱含層結點的數目要小于輸入層結點的數目。那么,在給定的假定條件下,隱含層結點的直接輸出值可以看做從輸入數據抽取出來的特征。也就是說可以利用隱含層直接輸出的數據恢復輸入層的數據。這樣AutoEncoder就是一種盡可能復現輸入信號的神經網絡,其原理圖如圖2所示,其中輸入數據維數為M,隱含節點數目為N,且N〈M。
基于AutoEncoder的RBF神經網絡訓練算法
針對AutoEncoder自編碼器提取的輸入特征能夠更好地發現樣本間的相關性的優點,本算法擬利用AutoEncoder訓練結果,來替代隨機初始化RBF神經網絡各個參數,其后再接著利用梯度下降法進行進一步的調整更新網絡的各個參數。
其算法步驟如下:
Step 1 :設置算法終止條件
(1)條件1:RBF神經網絡的訓練精度。
(2)條件2:梯度下降更新網絡參數的最大迭代次數。
只要滿足上述2個條件的任何一條即可結束迭代。
Step 2: 歸一化訓練樣本,這里采用min-max標準化方法,其轉換函數如下:

其中,x*為樣本數據轉換后的標準數據,且有x*∈[0,1]。xmax為樣本數據中的最大值。xmin為樣本數據中的最小值。x為樣本數據的原始值。
Step 3:隨機抽取樣本數據的70%作為訓練集,其余30%為測試集。
Step 4:在訓練集上,利用AutoEncoder自編碼器進行學習訓練。訓練結束后得到RBF神經網絡NN*。
Step 5:在網絡NN*各個參數的基礎上,利用梯度下降方法繼續調整更新各個參數,直至滿足終止條件。
仿真實驗
下面對本文提出的算法進行仿真實驗,試驗數據特選取UCI機器學習數據庫中的Iris、Glass、Wine等3個數據集,作為樣本集。各個數據集的基本情況參見表1。
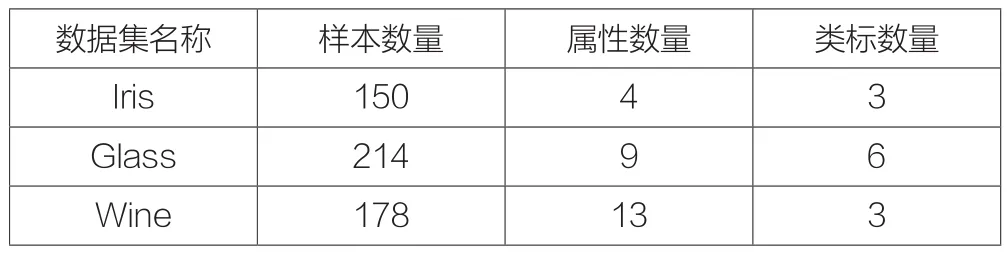
表1 Iris、Glass、Wine等數據集基本情況
為驗證本算法的可行性與先進性,特采取在第2節描述的采樣隨機輸出宏網絡各個參數的傳統訓練方法作為對比,采用相同的隱含層節點數,分別對上述3個數據集重復進行10仿真實驗,取其識別精度的平均值作為其訓練與測試能力的評價標準。
仿真實驗結果如表2所示。
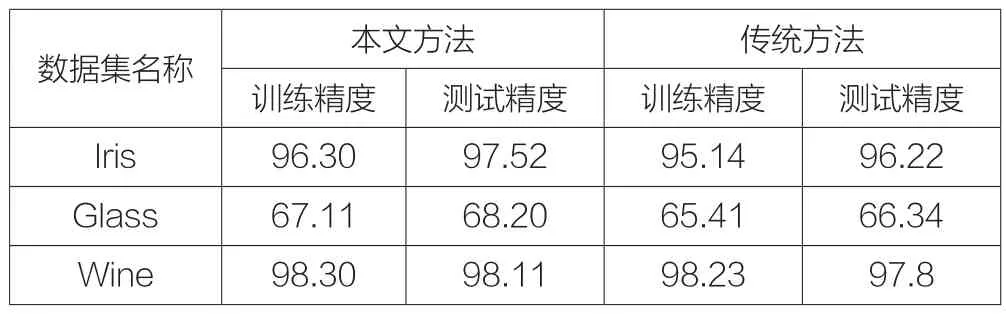
表2 仿真實驗結果
從實驗結果可知,在選取相同數目的隱含層結點的前提下,本文提出的算法,無論在訓練集的訓練精度,還是在測試集上的測試精度上,都比采用傳統隨機初始化網絡各個參數的方法都有較好的表現。
結語
AutoEncoder自動編碼器能夠采用無監督特征學習算法,模擬人類視覺系統,來對原始樣本數據進行分析學習,表現出了強大的從少數樣本中學習數據集本質特征的能力,在圖像識別、語音識別、語義識別等領域有著廣闊的應用前景。本文利用AutoEncoder算法初始化RBF神經網絡參數,接著利用梯度下降方法來調整更新網絡的參數。經過試驗仿真,說明了本文所提的算法具有可行性與先進性,相對于傳統方法,具有更好的學習能力與泛化能力。對RBF神經網絡的進一步推廣應用有著積極的作用。
10.3969/j.issn.1001-8972.2015.09.018
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
