基于分區的關聯規則Apriori算法研究
2015-10-14 10:49:52李婷張繼周
科技視界 2015年28期
李婷 張繼周
【摘 要】Apriori算法是挖掘頻繁項集的一種重要方法,但是如果事務數據庫大到難以一次裝入內存就會遇到瓶頸。本文給出一種基于分區技術的改進算法,通過將大的事務數據庫劃分為小的分區來實現頻繁項集的挖掘。
【關鍵詞】關聯規則;Apriori算法;頻繁項集;分區技術
【Abstract】Apriori algorithm is an important ways on mining frequent itemsets, but the situation is difficult to handle if the transaction database is very huge. An improving algorithm based on partitioning is given, and the frequent itemsets are obtained by dividing the huge database into small ones.
【Key words】Association rules; Apriori algorithm; Frequent item sets; Partition technique
0 引言
挖掘頻繁模式是數據挖掘中的一個重要內容,它是研究如何可以找到頻繁出現在數據集中的模式。它對于挖掘數據之間的相關和關聯性以及發現頻繁模式起著非常重要的作用。因此,頻繁模式的挖掘成為了數據挖掘任務和數據挖掘研究關注的重要主題之一[1]。
1 基本概念
(1)項集:由若干個項組成的集合,設I={I1,I2,…,Im},I是一個項集。
(2)k項集:項集中的元素如果有k個,就稱這個項集為k項集。
(3)關聯規則:設A和B為兩個項集,A?奐I,B?奐I且A∩B=Φ,則有關聯規則R:A=>B。
(4)支持度(相對支持度):D中事務包含A∪B的百分比,也就是概率P(A∪B)。
(5)置信度:D中事務即包含A同時也包含B的百分比,也就是條件概率P(B|A)。
(6)支持度計數(絕對支持度):包含項集的事務數。
(7)強關聯規則:滿足最小支持度和最小置信度的關聯規則[2]。
(8)關聯規則的產生步驟:首先找出所有的頻繁項集,然后由頻集產生強關聯規則。
2 頻繁項集挖掘的Apriori算法
關聯規則產生的一個步驟就是要找出所有的頻繁項集,而這一步是挖掘過程中最重要的,它的開銷遠遠大于第二個步驟,因此它的性能的好壞就決定了整體挖掘性能的好壞。Apriori算法是為挖掘布爾類型關聯規則頻集的原創性算法。它是一種逐層搜索的迭代方法,其中k項集用于探索(k+1)項集。首先,通過掃描數據庫,找出事務中包含的所有項,同時對每一項進行計數,得到候選1項集(C1),用每個計數和最小支持度計數進行比較,得到頻繁1項集(L1)。然后,使用L1通過自身的連接產生C2,通過對C2計數找出集合L2。再使用相同的方法找出L3,依次如此做下去,直到不能再找到頻繁k項集。
為了提高頻集逐層產生的效率,可以使用先驗性質來壓縮搜索空間。
先驗性質:頻繁項集的所有非空子集也一定是頻繁的。
證明:令S是一個頻集,min_sup是最小支持度,D為事務數據庫的集合,|D|為D中的事務數,則support_count(S)=min_supX|D|。令S為S的任意一個非空子集,則任何包含項集S的事務必然會包含項集S。因此,support_count(S)support_count(S)=min_supX|D|,故S也是一個頻集。
因此在生成候選k-項集之前,可以使用上述性質來進行剪枝,這樣可以減去大量的k-項集,從而大大壓縮了候選k-項集。
3 基于分區的算法改進
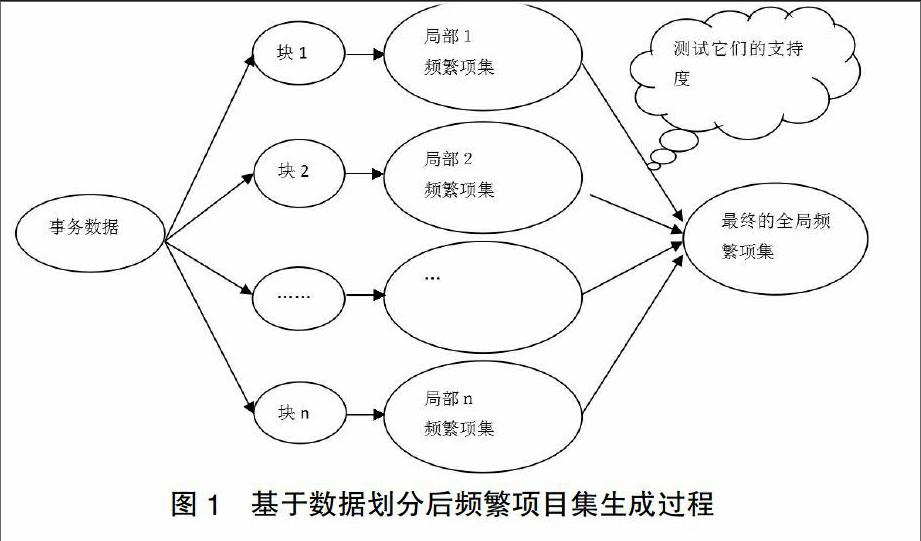
事務數據庫有時候會很大而無法一次全部裝入內存,此時可以進行事務數據庫的劃分。分區的大小和分區的數目要使得每個分區都能夠放入內存。過程如圖所示:
首先,把D中的事務劃分成n個非重疊的分區,如果D中事務的最小相對支持度閾值為min_sup,則每個分區的最小支持度計數為min_supX該分區的事務數。對于每個分區,掃描數據庫,找出所有的局部頻繁項集[3]。局部頻集可能是也可能不是整個數據庫D的頻集。然而,D的任何頻集必須作為局部頻集至少出現在一個分區中,證明如下:
證明:反證法。假設頻集在D的任何一個分區都不頻繁。令F為任意一個頻集,D為事務數據庫集合,C為D中的事務總數,A為D中包含F的事務總數,min_sup為最小支持度。因為F是一個頻集,所以A=CXmin_sup。將D分成n個不重疊的分區:d1,d2,d3,…,dn,令C1,C2,C3,…,Cn為分區d1,d2,d3,…,dn各自對應的事務數,則C=C1+C2+C3+…+Cn。令a1,a2,a3,…,an為分區d1,d2,d3,…,dn中包含F的事務數,則A=a1+a2+a3+…+an。因此A=a1+a2+a3+…+an=(C1+C2+C3+…+Cn)Xmin_sup。因為前面已經假設F在D中任意一個分區d1,d2,d3,…,dn中都不頻繁,則a1 因此,所有局部頻集都是D的候選項集,來自所有分區的局部頻集作為D的全局候選項集。然后,第二次掃描數據庫D,評估每個候選的實際支持度,以確定全局頻繁項集。它的優化算法步驟為:(1)把數據庫劃分成一些模塊大小相當的塊,記為N塊;(2)在每一塊內產生一組自己的頻繁項集;記為Li;(3)最后合并這些項集生成一個全局候選的頻繁項集;(4)在數據庫內,計算全局候選的頻繁項集的支持度,得到確定的最終的頻繁項集。 4 結語 通過上述對基于劃分數據庫的Apriori算法的描述,可以清楚的知道改進算法與原始的算法思想的異同,也完整體現了改進算法的解題思路和所在優勢,它把一個大而復雜的數據庫劃分成許多小的結構簡單的數據庫,大大減小了因為候選集呈指數增長的問題,減少了候選集的構造,縮短了時間;減少了不必要候選集生成的個數,節省了內存空間,提高了算法的效率。 【參考文獻】 [1]Jiawei Han,Micheline Kamber.數據挖掘概念與技術[M].2版.范明,孟小鋒,譯.北京:機械工業出版社,2010. [2]王麗珍,周麗華,陳紅梅,等.數據倉庫與數據挖掘原理及應用[M].北京:科學出版社,2005. [3]王榮福,余麗娜,等.基于劃分技術對Apriori算法的改進[J].科技創新導報,2008(12). [責任編輯:湯靜]
