基于數據變化自適應的應用軟件開發平臺研究
2015-07-18 00:53:36陸維
中國新技術新產品 2015年22期
陸 維
(上海應用技術學院 計算機科學與信息工程學院,上海 201400)
基于數據變化自適應的應用軟件開發平臺研究
陸 維
(上海應用技術學院 計算機科學與信息工程學院,上海 201400)
由于軟件開發的對象面向各種應用領域,用戶需求中的數據需要軟件工程師花費大量精力進行學習,另外,由于需求變更,這些數據經常需要修改,而用戶又無法對數據進行定義和維護,從而形成軟件開發和維護的瓶頸。針對以上問題,本文設計了基于數據變化自適應的應用軟件開發平臺模型,研究了平臺的運行機理與流程,并通過S2SH框架技術對平臺進行了開發,實現了數據可以從應用軟件中分離出來,以簡單的形式定義在平臺中,由平臺進行解析并獲取結果,反饋給應用軟件。實驗表明,通過平臺開發的應用軟件,可以實現數據和規則的用戶自定義,面對需求變化引起的數據變化,平臺可以自動進行調整,應用軟件無需進行任何調整,提高了開發和維護的效率。
軟件開發平臺;軟件自動調整;數據變化;需求變更
1 引言
近年來,軟件產業快速發展,人們對軟件的開發周期和質量要求越來越高,傳統的軟件開發中,由于專業領域的不同,需求分析需要耗費大量的時間和精力,特別是在用戶業務規則和數據定義上,并且需求的變化對軟件質量影響較大,成為了開發的瓶頸。國內外眾多學者與工程師對服務組裝、軟件自動化等方面進行了研究,形成了部分研究成果與產品,但是未解決以下兩個問題:
(1)需要專門的工程師獲取完整的用戶需求,并轉化為系統能夠識別的表示形式。這些表示往往比較復雜,用戶很難進行直接定義與維護。
(2)當需求出現變更時,生成的應用系統需要重新配置、編譯。
針對以上問題,本文研究了基于數據變化自適應的應用軟件開發平臺,從應用軟件中分離出各類數據與規則的定義與維護,軟件工程師可以通過平臺開發應用軟件的框架與界面,用戶可以在平臺上定義、維護數據與業務規則,減輕了需求分析的難度,節省了維護的費用,實現了數據與軟件的分離,從而實現數據變化,應用軟件無需調整的目的,減少了軟件回歸測試與部署的工作量,提高了軟件的可靠性。同時,在平臺中定義的所有數據可以實現共享和復用。
2 平臺體系結構設計與工作原理
2.1平臺體系結構
平臺包括知識庫和執行單元集。體系結構圖如圖1所示。
其中,知識庫包括:
(1)數據字典
它用來存儲用戶數據和數據來源,同時記錄獲取數據的應用描述,以便獲取不同來源的數據,包括數據庫、XML、文本、設備等。
(2)規則庫
應用軟件中的有些數據需要通過用戶規則對多個數據運算得出,規則庫用來存儲這些規則。
執行單元按照一定的流程完成特定功能,包括:
①控制器單元
它是平臺的核心,維護著平臺的運行策略,當應用軟件需要獲取數據結果時,對其他單元的工作進行協調。
②執行器單元
它負責解析知識庫中數據字典中的數據描述,解析規則庫中的數據規則,并獲得數據結果。
③數據獲取單元
它負責執行不同數據來源的應用,實時獲取數據,并滿足對數據來源定義的“開-閉”原則。
2.2 平臺工作原理
在平臺運行模型中,各單元按照既定運行策略完成系統的特定功能,圖2給出了應用軟件中需要某一用戶數據結果時,平臺單元執行的流程。
圖中,當平臺收到應用軟件獲取數據結果的請求信息后,控制器單元調度執行器單元,并把相關信息傳輸給執行器單元。執行器單元根據接收到的信息在知識庫的數據字典與規則庫中進行查找,解析,并把解析后的結果反饋給控制器單元。控制器單元調度數據獲取單元,同時向其傳輸執行器單元的解析信息。數據獲取單元根據信息執行獲取數據的應用,并把獲取的實時數據結果傳輸給控制器單元。
當應用軟件獲取的數據在數據字典中有直接定義時,經過上述一次流程即可得出結果,當在數據字典中沒有直接定義,而是在規則庫中有定義時,需要對上述流程進行遞歸執行。獲取數據的流程如圖3所示。
圖中,當應用軟件所需數據在數據字典中有定義時,可以通過平臺單元的工作流程直接得出結果,否則從規則庫中獲得規則的定義,該規則可能包括常數、規則和數據,對于規則和數據,遞歸執行上述過程,直至獲取所需的各數據結果,最終通過運算得出總結果。
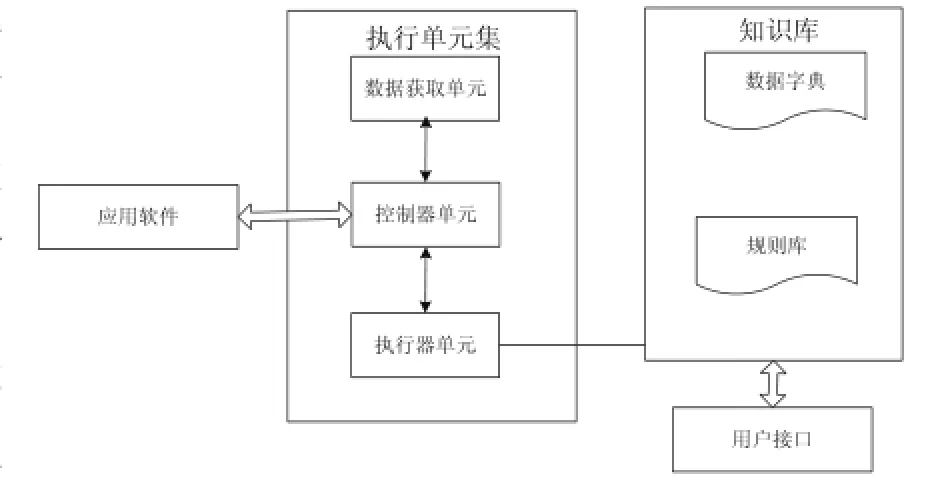
圖1 平臺體系結構

圖2 平臺單元工作流程
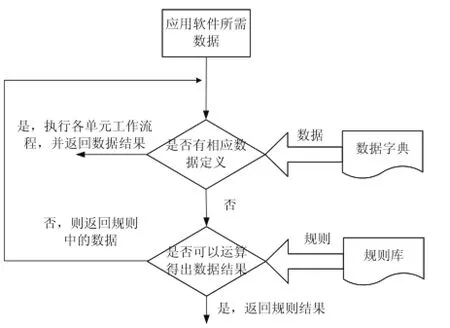
圖3 數據獲取流程
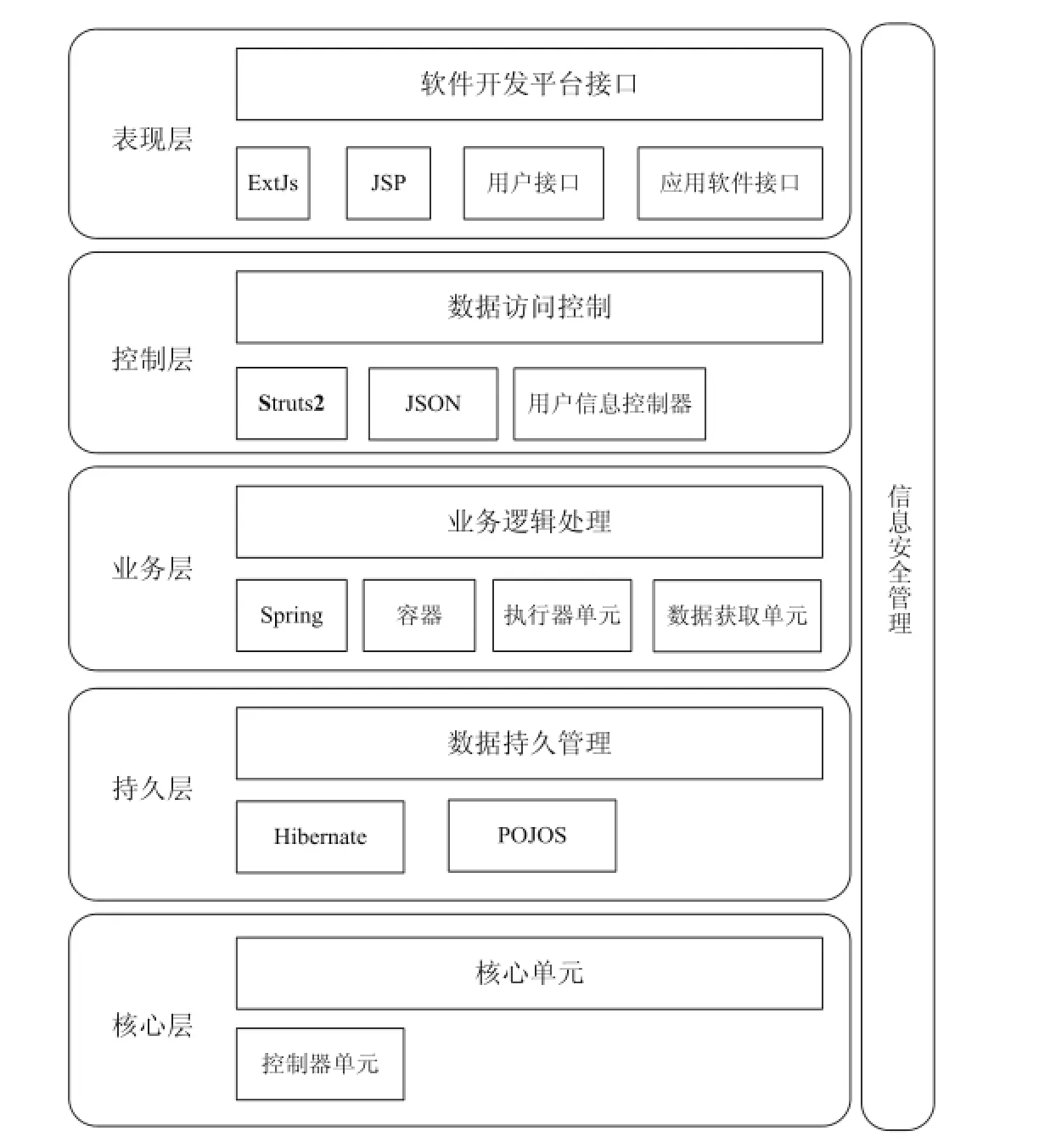
圖4 平臺架構圖
3 實驗
3.1 平臺應用開發
平臺由S2SH框架整合開發完成,數據庫服務器使用MySQL,應用開發框架包括五個層次,并配置信息安全管理體系,以保證信息的安全和完整性,平臺的應用開發架構設計如圖4所示。
(1)表現層主要負責平臺的對外接口,完成平臺與用戶及應用軟件的交互,采用ExtJs技術完成RIA的應用,通過與Struts2整合后,以Jsp作為輸出頁面。
(2)控制層主要負責數據的訪問控制,對發送來的請求進行篩選和處理,將可執行的請求轉交給業務層進行處理,將錯誤請求轉交給錯誤處理程序處理。本層采用了Struts2框架的技術,當該層得知業務層完成處理請求后,發送相應的頁面給表現層,本層的數據交換使用了JSON格式。本層包括用戶信息控制器,它負責平臺與用戶信息的控制轉發。
(3)業務層負責接收控制層轉發的請求并進行處理,該層使用Spring容器管理業務Bean,增強了業務間的交互性,也減少了業務間的耦合程度。同時啟用了Spring基于注解的模式,有效地減少了配置的代碼量,增強了系統的可控性。該層包括執行器單元和數據獲取單元。
(4)持久層負責對數據進行持久化管理,運用Hibernate框架技術,對數據庫進行管理,整合Spring后,將相關的配置工作轉交給Spring容器負責管理,減少了配置數據庫的代碼量。
(5)核心層包括控制器單元,協調平臺各單元的工作,完成平臺功能。
3.2 實驗內容
在實驗中,設計并實現了如下場景:應用軟件中需要用到數據“score”,第一次需求要求“score”來自于一個Web應用程序,然后需求變更,要求“score”來自數據庫。
在基于本文平臺開發的應用軟件中定義、使用數據“score”,但不描述如何獲得數據的值。對于第一次需求,“score”可以直接從Web應用程序中獲取,因此用戶可在數據字典中定義表1所示內容。
數據“score”獲取了IP地址為“192.168.1.111”,端口號為“80”,名稱為“StudentSta”傳來的數據。
對于第二次需求,數據庫中有名為“StuScore”的表,表中有三個屬性“MathScore”、“ChineseScore”和“EnglishScore”,要求score=0.3* mathScore +0.5* chineseScore + 0.2*englishScore。因為“mathScore”、“chineseScore”和“englishScore”可能再用于應用軟件的其他數據,因此把他們定義在數據字典中。數據“score”的獲取需要用到數據字典中三個數據,因此定義在規則庫中,見表2。
數據來自于連接字符串為“jdbc:mysql://localhost:8088/appdemo”,用戶名為“root”,密碼為“123456”的數據庫。
數據“score”獲取了數據字典表中三個數據經過計算的結果。
通過實驗可以看出,通過本文平臺開發的應用軟件的數據可以定義在平臺中,無需在應用軟件中進行描述。數據的定義與維護非常簡單方便,用戶可直接進行操作。當需求變化后,平臺可以進行動態調整,應用軟件無需進行任何調整。

表1 數據字典主要屬性實例

表2 數據規則主要屬性實例
結語
針對軟件工程中數據與規則靈活化的目的,本文設計了基于數據變化自適應的應用軟件開發平臺,對平臺體系結構進行了設計,確定了平臺各單元的工作原理和流程,并以S2SH框架技術對平臺進行了實現。實驗表明,通過平臺開發的應用軟件,數據的定義和維護方便,提高了開發和維護的效率。對復雜數據的自適應研究是將來的研究工作。
[1]趙亮,黃志球,劉林源.Web服務組裝中的隱私暴露分析方法[J].計算機科學與探索,2012,6(04):319-326.
[2] Shalloway A,Trott J R.設計模式精解.熊節,譯.北京:清華大學出版社,2005.
TP391
A
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
山東青年(2016年1期)2016-02-28 14:25:25
創業家(2015年5期)2015-02-27 07:53:25
當代修辭學(2014年3期)2014-01-21 02:30:44
