基于科技文獻的研究設計指紋描述框架研究
2015-07-15 08:36:28錢力張曉林王茜
大學圖書館學報 2015年1期
錢力+張曉林+王茜
摘要 提出用于描述科技文獻核心知識的“研究設計指紋”概念,綜合研究分析了相關的科技文獻規范描述框架,創建“基于科技文獻的研究設計指紋描述框架”,以增強科技文獻的機器計算可執行性、知識粒度性、知識關聯性、結構的擴展性以及研究設計思路的可視性,為科研人員快速發現研究設計方法、研究設計工具等指紋提供了新的思路與方法。
關鍵詞 科技文獻 研究設計指紋 知識組織 語義出版 知識骨干
l 引言
科技文獻是科學技術發展的重要戰略資源,但隨著信息技術的快速發展,數字出版速度加快,海量科技文獻也帶來一些現實問題:對某一具體研究領域或研究方向,無法快速追蹤與了解相關的研究方法、研究設備等核心知識對象,也無法快速客觀評估相關知識對象對研究問題的有效性。特別對一個剛剛踏人科研領域的工作者來說,會出現無從下手的局面。
針對上述問題,筆者在調研了科技文獻描述規范以及相關寫作指南之后,提出利用研究設計指紋對科技文獻進行結構化描述,提升科技文獻的計算機可識別性、可執行性,幫助科研人員快速了解科技文獻的研究方法、算法、工具及結論等,并為未來的科學出版(即語義化出版)提供相應的出版規范參照。論文結構如下:第二部分提出“研究設計指紋”的概念,第三部分就此展開相關研究分析,第四部分提出科技文獻的“研究設計指紋描述框架”,第五部分探析其潛在應用。
2 研究設計指紋概念的提出
科技文獻從本質上看是科研人員開展科學研究思路的文本化,也是科研成果發布與傳播的重要載體,還是掌握某一研究主題的研究概貌的核心資料。在面對海量科技文獻的情況下,如何快速了解文獻的研究框架、采用的研究方法以及講述的研究內容成為圖書情報領域關注與研究的主題。論文提出“研究設計指紋”概念,嘗試從科學研究設計的視角去解決上述問題,通過對一篇科技文獻的知識骨干網絡進行結構化描述,揭示出相關研究方法、算法等研究設計指紋,幫助科研人員快速了解研究設計過程以及各個過程中的重要研究設計指紋對象。
目前,“研究設計指紋”沒有一個明確的界定,但是“基于本體標引文獻的工具”(An Ontology BasedTool for Preparation of Articles)項目組在2007年開展全文挖掘與標引工作中,抽象出“科技文獻核心信息(Core Information Scientific Papers, CISP)”概念,一定程度上也是對科技文獻所包含的重要知識對象的揭示,其定義如下:CISP是來自于知識本體類的一個已定義好的集合,包含的關鍵類有:調研目標、調研對象、研究方法、結果以及結論等。另外,其他研究項目也提出“核心知識對象”、“科學知識組織體系”、“科技核心”等類似概念。
基于上述描述與概念,本文給出“研究設計指紋”的定義為:描述一個科學研究設計實現過程中擁有多個核心設計元素特征的知識對象。它具有三個主要特征:(l)精煉地“揭示科學研究的設計思路”;(2)結構化地“揭示科學研究方法、過程和結構”;(3)可視化地“揭示科學研究中的骨干知識及其關系”。設計指紋的類型方面,本文主要參考科技文獻寫作指南(如侯賽因教授設計的“研究文獻寫作指南與要求”、巴達沙利設計的“寫作與出版科技文獻的指南”以及有機生物學實驗室的“科技文獻寫作指南”等),定義了II種設計指紋,即研究假說、研究場景、研究目的、研究背景、研究方法、研究數據、研究算法、研究設備、研究結果、研究結論和未來研究。
3 相關研究綜述
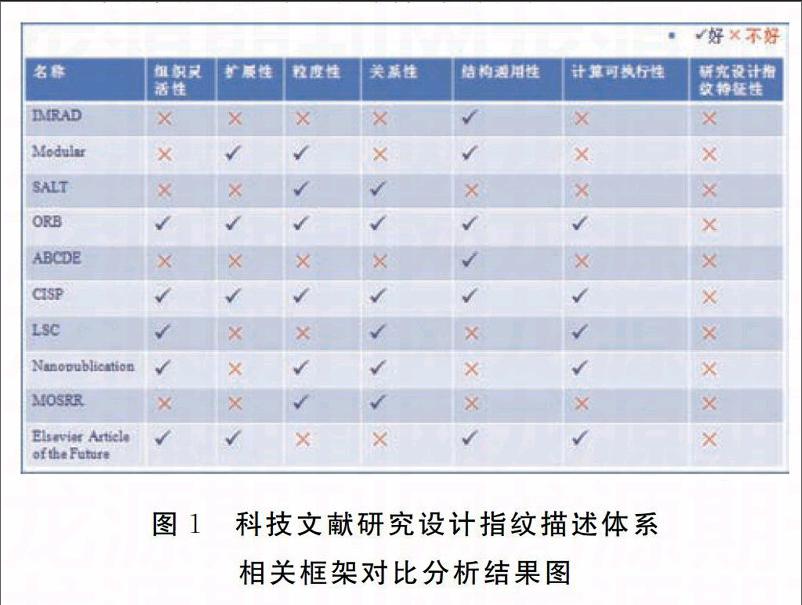
作為一種科研成果的傳播載體,科技文獻本身具有相應的描述規范,如最初的經典通用模型IM-RAD (Introduction-Methods-Result-And-Discus-sion,介紹一方法一結果一結論)、模塊化(Modular)模型、語義注解LaTeX(Semantically AnnotatedLaTeX,SALT)、W3C提出的科學篇章修辭塊本體(Ontology of Rhetorical Blocks,ORB)標準結構模型、ABCDE模型(Annotation-Background-Contri-bution-Discussion-Entity,注解一背景一貢獻一討論一實體)、科技文獻核心信息(Core Information Sci-entific Papers,CISP)、關聯科學核心詞匯(LinkedScience Core Vocabulary,LSC)、納米出版物模式( Nanopublication)、面向模型的科學研究報告規范( Model-Oriented Scientific Research Report,MOSRR)以及Elsevier的未來論文模式(ElsevierArticle of the Future)等,以實現科技文獻或者資源信息的結構化描述,使文獻或者資源具備自動識別執行性、自動理解性等語義特征。本文從組織靈活性、擴展性、粒度性(粗/細)、關系性、結構通用性、計算可執行性以及研究設計指紋特征等七個角度對上述描述規范或者模型進行比對分析,結果如下圖l所示,具體描述規范的內容與特征如下。
3.1 IMRAD經典模型
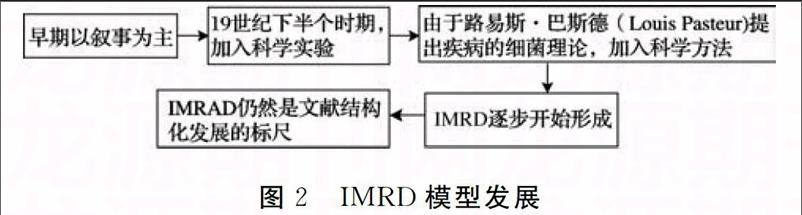
IMRAD經典模式是在自然科學中基于科學實驗報告的原型表示,即:要研究什么問題(lntro-duction),如何研究上述問題(Methods),通過研究發現了什么( Results),上述發現意味著什么(Dis-cussion)。IMRAD結構被許多科學雜志認可,并且是國際醫學期刊編輯委員會( International Commit-tee of Medical Journal Editors)發布的生物醫學類期刊的投稿統一要求,即生物醫學出版物的寫作與編輯中推薦的標準。IMRAD模型發展歷程如下圖2所示。
3.2 電子文獻的模塊化模型
基于標準通用標記語言的理論,提出電子文獻的模塊化結構,用標簽來識別。一個模塊即是能夠表達概念的信息單元,劃分的依據是其包含信息的連續性與完整性。科技文獻的結構本身可以劃分模塊,如:簡介、方法、結果、討論與結論,這種順序代表著一篇科技敘述的規范流程。但是,這種敘述流程具有一個先決條件,即要對文獻從頭到尾進行順序閱讀。但是知識豐富的讀者很少進行順序閱讀,而是通過瀏覽來發現有用的信息點或者信息片。所以作為能夠獨立用于閱讀的模塊,其獨立性并不是指它能夠充分敘述整個工作,而是能夠讓讀者瞬間縮小關注點,快速獲取知識。
3.3 ABCDE模型
從敘述式閱讀到計算機理解的一種好方式是讓作者在科研寫作過程中,就按照一定的格式創造出具有豐富語義結構的研究文獻,基于這一目標,沃德(Anita de Waard)提出了ABCDE模型,以便研究人員集成、挖掘與分析研究成果:A( Annotation),基于DC元數據標準的文獻元數據描述,如標題、作者等;B( Background),描述研究的定位,當前持續性的問題以及相關的研究問題;C( Contributlon),描述作者已經做過的工作,包括調研、實現等;D( Dis-cussion),描述已經開展過的研究的討論結果,同時列出各個結果之間的對比分析;E( Entity),描述一個實體對象,例如人名、工程名稱、研究方法等。
3.4 SALT模型
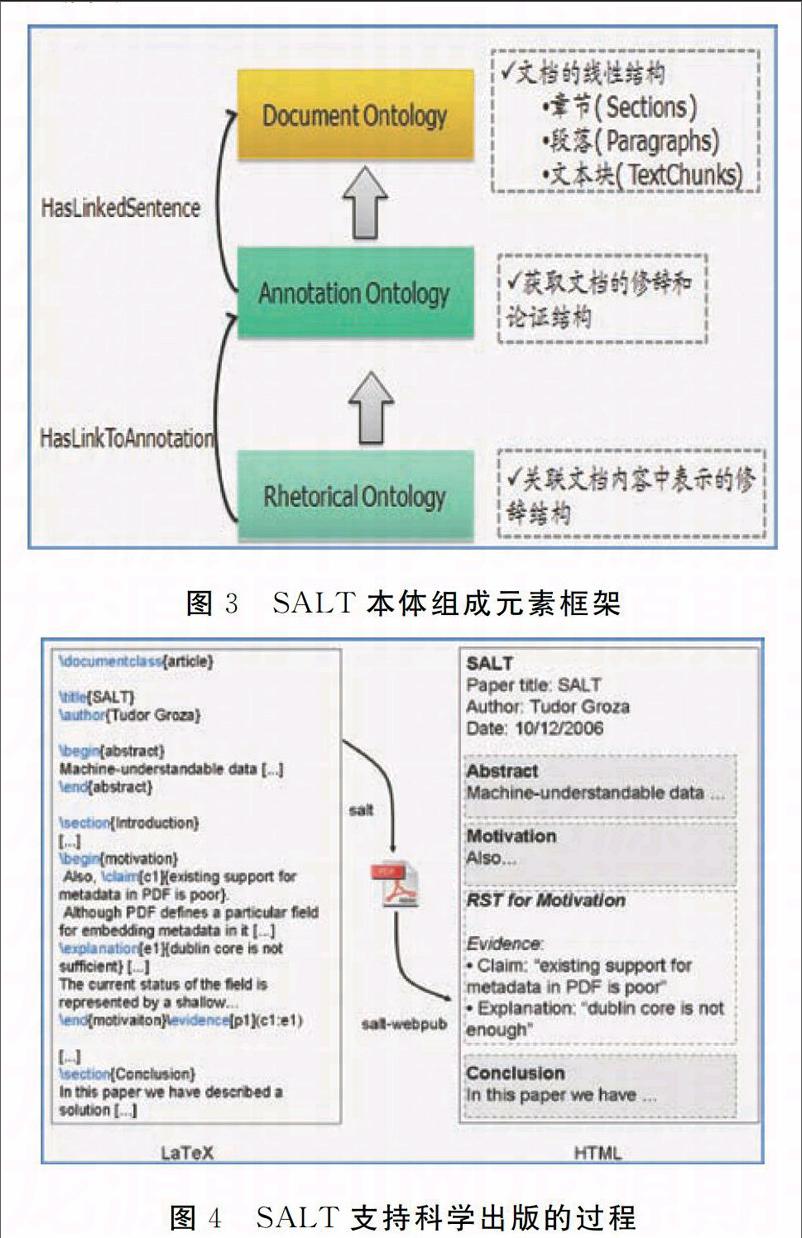
SALT-是利用語義標注原理豐富科學出版的一個語義創作框架。SALT提供了用來識別出版物的修辭結構與論證內容的方法,實現核心是創建三種本體即文檔本體、修辭本體與標注本體,它們之間的關系結構如圖3所示。利用SALT支持科學出版的過程大致分為兩個階段:第一階段是SALT過程,主要負責分析標引和將本體實例嵌入到最終的PDF文檔中,分為綜合分析與標引抽取、標引與本體創建和PDF文檔編譯三個步驟;第二階段是出版過程,將第一階段生成的語義PDF文檔集作為輸入集合,生成一系列對應且具有索引的HTML文件。目前SAILT不僅支持LaTeX的創作環境,其模型還可被用于其他環境來豐富科學出版,出版過程如下圖4所示。
3.5 ORB修辭模型
ORB是W3C于2011年發布的文獻修辭塊結構描述標準,目標是提供一個規范化結構來表示科技文獻中的所有描述知識項,從而推動科技文獻結構表示的標準化、語義化及實用化。ORB不僅可以在新創作的科學文獻結構中增加語義,也可以標引已經出版的科學文獻。它類似于利用插件式操作方式實現對科技文獻內容結構的靈活控制,主要有以下特征:融入修辭模塊粗粒度集合,如表示摘要、研究背景等段落;文檔內容提供了細粒度語義人口,如具體的某一句話或者某一句話的某一部分、某一個詞等。ORB在內容結構的組織上分為頭部、主體和尾部。
3.6 CISP結構模型
JISC于2007發布的大學研究報告介紹了科學文獻核心信息描述的一種新模式CISP,主要利用本體方法體系來開發與組織以科學實驗為基礎的科技文獻的元數據,挖掘與揭示其內在的邏輯關系、語義關聯關系以及各個組成元素的清晰定義,如定義了調研目的、調查動機、調查對象、研究方法、開展的實驗、觀察發現、結果與結論等本體類別。
3.7 納米出版物計劃項目
為了解決發現、關聯與設計學術研究中特殊核心科學描述的困難,概念網絡聯盟啟動了納米出版物計劃。它利用計算機作為輔助工具,從文獻和數據中抽取研究結論、研究事實或研究結果,以三元組的模式建立起語義關系,從而使文獻結構的動態性、機器計算可執行性得到加強,更好地支持后期的大數據處理與挖掘。雖然目前此計劃對于學科領域的依賴性、數據處理的針對性相對較強,但是對相關研究來說具有很好的借鑒意義。
3.8 MOSRR規范模型
雖然科學研究報告已經結構化了(比如上述的IMRD模型),但是知識單元的粒度相對還較大,仍然以自由文本表示為主。而MOSRR規范模型在一定程度上改進了上述問題,能通過結構化使信息具有更小粒度角色,可以更靈活嵌入到科研工作流中,幫助改善與提升科學研究報告的結構化程度。同時此模型也可以支持數據密集型的科學研究以及靈活的研究工作流設計等活動。
3.9 Elsevier發起的“未來論文”項目
Elsevier的未來論文項目是2009年開始發起,目前超過150位研究人員進行研發,其目標是使Elsevier期刊成為發現與探索科學研究最可能的地方,讓重新設計描述的文獻更具有可讀性、無縫導航性。此項目的深度研發遵循三個指導原則:一是可讀性,即讓新出版的文獻知識更容易在屏幕中得到有效揭示;二是可發現性,即實現引導式、工作流式的內容與功能發現;三是可擴展性,即在不犧牲可讀性的基礎上,具有一個通用的功能層來揭示豐富的特殊主題內容。這一項目的發展模式目前已經初具雛形,在未來的語義化出版中值得借鑒與期待。
3. 10 LSC描述框架
LSC作為一種輕量級詞匯,由德國明斯特大學地理信息學院構建,其底層框架技術主要依賴W3C的資源描述框架規范,同時借鑒了牛津大學趙軍編輯的開放源模型詞匯表(Open ProvenanceModel Vocabulary)描述規范。LSC詞匯為出版商和科研人員提供與時間、空間、主題相關的科學事件的術語詞匯,能夠結構化描述科學資源,最終達到以機器可以理解的方式來關聯發現科學資源。此種以科學知識關聯為目的的描述框架,也為科技文獻中研究設計指紋之間的關聯關系提供了很好的借鑒。
4 研究設計指紋描述框架的設計
綜上發現,各個規范描述框架都具有自身的研究環境與特殊目標,比如對理化領域知識的描述、對科學實驗本體的創建、對開放科學資源的關聯以及對未來語義出版的支持等。但是,面向海量科技文獻的深度知識分析,使科技文獻可自動計算執行、自動閱讀理解以及自動創建知識之間的關聯等語義特征,仍然是需要深入研究的問題。本研究提出的研究設計指紋描述框架,即是一種描述科技文獻知識單元的標準規范,利用研究設計指紋將科技文獻知識單元以一種結構化、語義化與關聯化的標準進行組織,使科技文獻轉換成機器可計算與理解的智能文獻。
研究設計指紋描述框架的設計思路本質依賴于科學研究方法,對于科技文獻撰寫者來說,它是規范與體現科研過程的一個流程框架,如下圖5所示;而對于閱讀科技文獻的用戶來說,它是幫助用戶了解科研成果的導航工具。下面從分類體系、構建規則與框架結構三個方面對此框架進行介紹,并將在后續研究中對其應用效果進行驗證與分析。
4.1 分類體系
科技文獻蘊藏著豐富的知識單元類型,為了更清晰合理地識別與組織各種研究設計指紋,參照文獻修辭篇章結構,將研究設計指紋分為四種類型,如下圖6所示:一是基礎指紋,主要描述科學研究的知識基礎,包括研究假設、研究背景和研究目標;二是技術指紋,主要描述實施解決研究問題的技術方案,包括研究方法、研究數據、研究算法、研究模型與研究設備;三是結論指紋,主要描述研究的成果或者效果,包括研究結果與研究結論;四是未來指紋,主要描述研究未來的研究方向或者重點。
4.2 構建準則
(l)將科技文獻表示為計算機可以自動計算執行與閱讀理解的智能載體;
(2)勾畫出一篇科技文獻或者一個研究主題的研究設計指紋的知識骨干網絡圖,幫助科研人員快速了解文獻的中心主題或者核心研究思路與內容;
(3)關聯發現科技文獻的研究設計指紋之間的證據鏈,通過關鍵主題或者知識對象來支持相關的研究設計指紋,表明它的唯一性或者效率性能等;
(4)支持實現技術創新,通過發現較好的研究方法、研究設備、研究模型等研究設計指紋以及組合、擴展等模式,實現科學研究設計的再創造,更好地解決研究問題。
4.3 框架結構
研究設計指紋框架結構是將研究設計指紋按照一種標準規范進行結構化組織,支持科技文獻的機器計算執行性、語義計算與知識標引等知識組織相關的研究活動。下面從指紋類型與整體框架、指紋類設計和指紋的劃分粒度三個視角進行研究與實現,具體如下:
4.3.1 指紋類型與整體框架
研究設計指紋框架體系結構以研究設計指紋來表示科技文獻研究成果,總體結構分為兩個層次,第一個層次分為研究主題、研究方法、研究算法、研究結果、研究結論與未來研究六大部分,而第二個層次詳細描述科技文獻,主要分為研究假說、研究場景、研究目的、研究背景、研究方法、研究數據、研究算法、研究結果、研究結論、未來研究以及研究設備共11種設計指紋,兩個層次之間相互關聯、層次內部相互關聯,很好地支持科技資源之間的關聯計算與發行,具體框架描述如下圖7。
4.3.2 指紋類設計
從科技文獻的知識結構性、可計算執行性設計,利用實體類與類屬性兩個角度來描述,如下表1所示,同時參考W3C發布的ORB即語義化組織的方式,將上述內容進行有機關聯,一方面提升科技文獻所包含研究設計元素的可分析評估性與可計算性,另一方面增強它們之間的知識關聯性,同時也提高計算機處理效率。
4.3.3 指紋的劃分粒度
研究設計指紋的粒度方面,粗細結合,從科技文獻的物理修辭結構角度出發,分為四個層次,具體設計如下表2與下圖8所示:
5 應用研究探析
以上介紹了基于科技文獻的研究設計指紋描述框架,但在科研成果數字化文本數量激增的信息環境下,如何應用此框架幫助科研人員快速發現科技文獻中的重要知識以及相互之間的脈絡關系?此框架能否對未來科技文獻的出版提供標準規范的幫助?能否為科研人員提供一個寫作思路上的標準語義框架以最終實現與語義出版的無縫集成?下面主要從挖掘科技文獻中心主題、繪制科技文獻知識骨干網絡圖和支持語義出版三個視角對“研究設計指紋描述框架”的應用優勢進行分析與論證。
5.1 挖掘科技文獻中心主題
如何快速準確地識別出科技文獻的中心主題、一般主題以及分析出主題間的結構關系,歷來是文本挖掘中的重要研究課題。隨著語言分析、信息抽取和社會網絡分析等方法的發展,一些新的解決思路和方法正在涌現。而通過科技文獻研究設計指紋描述規范框架,不僅可以將文獻主題從指紋特征的粒度進行結構化組織,而且也揭示了相互之間的關系,進而快速創建科技文獻的主題結構網絡圖,輔助科研人員快速了解所關注文獻論述的中心主題。
5.2 繪制科技文獻知識骨干網絡圖
研究設計指紋描述框架從“研究設計”的視角組織與揭示一篇科技文獻,即識別它的具體研究內容以及研究背景、方法、算法、工具、數據集、結果以及結論等研究設計指紋(如圖5所示),形成科技文獻的知識骨干網絡圖,從而幫助科研人員迅速掌握該領域最新或者最有效的研究方法、工具等。
5.3 支持語義出版
語義出版2009年被首次提出,肖頓等將其概念界定為:提升期刊文章的語義,以促進其自動獲取為目的,通過構建語義相關的文章之間的鏈接,提供多種獲取文章內數據的可行途徑,也使文章之間的數據整合更容易實現。而肖頓又提出語義出版能夠極大地提高科學交流效率,其提供的增值服務能獲得合理的商業回報,在學術出版領域將得以推廣實施。徐昊提到隨著語義出版研究的推進,目前科學出版領域關注的重點在于改善知識對象在產生、傳播、演進、發布和重用這一生命周期中的語義。在上述語義出版發生與發展的背景下,研究設計指紋描述框架將科技文獻進行語義化、結構化組織,將以一種新的模式支持科技文獻內核心知識內容的識別、提取與計算,科技文獻之間知識關聯、整合以及研究成果的傳播,使科技文獻成為計算機可以自動計算、自動閱讀的智能產品。
6 小結
隨著現代信息技術的快速發展,科技文獻的數字化規模勢必繼續擴大,從海量科技文獻中了解某一研究問題的最新研究方法、最有效的研究設備與模型等,成為科研人員面臨的巨大挑戰。因此,設計一套規范化的科技文獻描述框架指南,不但能夠對已出版的科技文獻進行知識的再創造,而且能對科技文獻寫作進行知識的研究設計組織與關聯化組織,輔助科研人員快速了解研究進展,掌握研究方法,洞察研究動向。本課題將在下一階段研究中,對研究設計指紋描述框架進行實驗設計,進一步驗證該框架對于科技文獻知識挖掘與分析的作用。
