微博輿情話題傳播行為預(yù)測(cè)研究
2015-06-08 11:24:50丁學(xué)君
中國(guó)管理信息化 2015年17期
丁學(xué)君
(東北財(cái)經(jīng)大學(xué) 管理科學(xué)與工程學(xué)院,遼寧 大連 116025)
1 引言
目前,微博已經(jīng)成為輿情話題傳播的重要渠道之一,對(duì)微博網(wǎng)絡(luò)中的輿情話題傳播過(guò)程進(jìn)行監(jiān)控及預(yù)測(cè),將有利于相關(guān)部門對(duì)不良輿情進(jìn)行有效地疏導(dǎo)和澄清。本文以新浪微博為例,在深入分析用戶轉(zhuǎn)發(fā)行為的基礎(chǔ)上,提取出了影響微博個(gè)體轉(zhuǎn)發(fā)行為的4類特征,利用邏輯回歸模型(Logistic Regression,LR)對(duì)微博用戶的輿情話題轉(zhuǎn)發(fā)概率進(jìn)行預(yù)測(cè),并在此基礎(chǔ)上給出了一種基于個(gè)體行為的微博輿情話題轉(zhuǎn)發(fā)規(guī)模預(yù)測(cè)算法。
2 微博輿情話題的個(gè)體轉(zhuǎn)發(fā)行為預(yù)測(cè)
2.1 轉(zhuǎn)發(fā)概率預(yù)測(cè)模型
本文利用有向無(wú)權(quán)圖G(U,E)來(lái)對(duì)微博網(wǎng)絡(luò)進(jìn)行描述。其中U為網(wǎng)絡(luò)中所有節(jié)點(diǎn)構(gòu)成的集合;E為網(wǎng)絡(luò)中所有邊構(gòu)成的集合,且eu,v∈E表示節(jié)點(diǎn)u指向節(jié)點(diǎn)v的有向邊,即節(jié)點(diǎn)u對(duì)節(jié)點(diǎn)v的關(guān)注關(guān)系,信息的傳播方向與關(guān)注方向相反。假設(shè)用戶v發(fā)布了一條話題消息 topic,則 y=f(v,u,topic)表示節(jié)點(diǎn) v 的粉絲節(jié)點(diǎn)u在看到該話題后采取的行為:y=1表示節(jié)點(diǎn)u對(duì)該話題進(jìn)行轉(zhuǎn)發(fā);y=0表示節(jié)點(diǎn)u不對(duì)該話題進(jìn)行轉(zhuǎn)發(fā)。因此,研究微博用戶的個(gè)體轉(zhuǎn)發(fā)行為,即是在給定話題信息topic以及用戶關(guān)系網(wǎng)絡(luò)G(U,E)的情況下,預(yù)測(cè)用戶u轉(zhuǎn)發(fā)話題信息topic的概率。
本文借鑒文獻(xiàn)[2]和文獻(xiàn)[3]的研究結(jié)論,使用LR模型對(duì)微博用戶的輿情話題轉(zhuǎn)發(fā)概率進(jìn)行預(yù)測(cè),其預(yù)測(cè)公式如下:

其中,F(xiàn)u(topic,G)為影響用戶u轉(zhuǎn)發(fā)話題的行為特征集合;yu表示用戶u的轉(zhuǎn)發(fā)行為;ω為權(quán)值向量,其值可以采用極大似然函數(shù)進(jìn)行估計(jì)。
2.2 用戶轉(zhuǎn)發(fā)行為特征提取
2.2.1 話題接收者特征
(1)話題接收者的興趣度。本文利用了Jaccard相似度計(jì)算方法,通過(guò)計(jì)算微博話題內(nèi)容與用戶感興趣內(nèi)容的相似程度,來(lái)對(duì)用戶興趣度進(jìn)行量化。
步驟1:興趣收集。收集某時(shí)間段內(nèi)用戶u發(fā)布的所有Ns條微博,構(gòu)建用戶 u 的語(yǔ)句級(jí)興趣空間 IS={S1,S2,…,SNs}。
步驟2:分詞。本文采用中科院計(jì)算技術(shù)研究所開發(fā)的ICTCLAS系統(tǒng)[4]對(duì)IS中的語(yǔ)句進(jìn)行分詞,得到用戶u的詞語(yǔ)級(jí)興趣空間 IW={W1,W2,…,WNw}。
步驟3:從中剔除停用詞。本文利用CSDN(2010)提供的停用詞列表,以去除IW中的停用詞,最終得到用戶u的興趣空間。
步驟4:針對(duì)某一輿情話題topic,按照步驟2~步驟3,對(duì)該話題進(jìn)行處理,得到話題 topic 的特征空間 TP={T1,T2,…,TNt}。
步驟5:計(jì)算INT和TP的Jaccard系數(shù)。Jacccard系數(shù)是樣本集交集與樣本集合集的比值[5],即微博輿情話題特征空間與接收用戶興趣空間的相似度為:

SIMu,topic表示了用戶u對(duì)目標(biāo)話題topic的感興趣程度。
(2)話題接收者的活躍度。本文利用式(3)計(jì)算話題接收者的活躍度Ra:

其中,ri,ci,oi分別為用戶在n天內(nèi)轉(zhuǎn)發(fā)、評(píng)論和原創(chuàng)的微博總數(shù)。
(3)話題接收者的重復(fù)接收次數(shù)。研究表明,用戶會(huì)因?yàn)樾畔⒌闹貜?fù)接收,而對(duì)該信息的轉(zhuǎn)發(fā)傾向發(fā)生改變[6]。因此,本文認(rèn)為話題接收者的關(guān)注對(duì)象中轉(zhuǎn)發(fā)目標(biāo)話題信息的數(shù)量,會(huì)影響該話題接收者的轉(zhuǎn)發(fā)行為。
2.2.2 話題發(fā)布者的特征
(1)話題發(fā)布者的影響力。微博網(wǎng)絡(luò)中,發(fā)布者的影響力大小勢(shì)必會(huì)對(duì)其粉絲的轉(zhuǎn)發(fā)行為產(chǎn)生影響[6]。本文采用文獻(xiàn)[7]給出的UIR算法來(lái)評(píng)價(jià)話題發(fā)布者的影響力,該算法可以描述為:

其中,UIR(v)為節(jié)點(diǎn) v 的影響力,d 為[0,1]區(qū)間上的阻尼系數(shù),通常情況下,取經(jīng)驗(yàn)值d=0.85,本文假設(shè)節(jié)點(diǎn)的初始UIR值為1。f(v)表示節(jié)點(diǎn)v的粉絲集合,Au,v為節(jié)點(diǎn)v分配給節(jié)點(diǎn)u的UIR值的比例:

其中,Nf是節(jié)點(diǎn)v的粉絲節(jié)點(diǎn)總數(shù),Rak為節(jié)點(diǎn)v的第k個(gè)粉絲節(jié)點(diǎn)的活躍度,Rak可由式(3)計(jì)算得到,通過(guò)有限次的反復(fù)迭代,就可以獲得目標(biāo)節(jié)點(diǎn)v的UIR值。
(2)話題發(fā)布者與接收者之間的社會(huì)關(guān)系。研究表明,與具有“單向關(guān)注”關(guān)系的用戶相比,具有“雙向關(guān)注關(guān)系”(“互粉”)的用戶間的親密程度更高[8]。此外,用戶間的互動(dòng)次數(shù)也從另一個(gè)方面反映了用戶間的關(guān)系親密程度,本文定義用戶u和用戶v之間的互動(dòng)次數(shù)為

其中,Cu,v為用戶 u 和用戶 v 轉(zhuǎn)發(fā)對(duì)方微博的數(shù)量,Ru,v為用戶u和用戶v評(píng)論對(duì)方微博的數(shù)量,Mu,v為用戶u和用戶v在微博中提及(“@”)對(duì)方的次數(shù)。
2.2.3 話題的內(nèi)容特征
研究表明,微博話題中是否包含圖片、視頻、URL、Hashtag以及“@”等內(nèi)容,均會(huì)對(duì)用戶的轉(zhuǎn)發(fā)行為產(chǎn)生影響[3]。
2.2.4 外部媒體關(guān)注度
本文利用目標(biāo)輿情話題傳播過(guò)程中,網(wǎng)絡(luò)媒體對(duì)此輿情事件的新聞報(bào)道數(shù)量,來(lái)描述外部媒體的關(guān)注度。針對(duì)某一目標(biāo)輿情話題 topic,首先得到該話題的特征空間 TP=(T1,T2,…,TNt),并提取出相應(yīng)輿情事件的關(guān)鍵詞,然后利用百度搜索引擎得到該輿情事件的相關(guān)新聞報(bào)道數(shù)量NMtopic。
通過(guò)以上分析,本文共提取了影響微博用戶輿情話題轉(zhuǎn)發(fā)行為的11個(gè)數(shù)值化特征,見表1。 特征6、7、8、9、10均采用二元表示方法。

表1 微博用戶轉(zhuǎn)發(fā)行為的特征分析
3 微博網(wǎng)絡(luò)輿情話題轉(zhuǎn)發(fā)規(guī)模預(yù)測(cè)算法
3.1 微博網(wǎng)絡(luò)中的話題轉(zhuǎn)發(fā)規(guī)則
微博網(wǎng)絡(luò)中,用戶節(jié)點(diǎn)對(duì)某一目標(biāo)話題topic的轉(zhuǎn)發(fā)規(guī)則如下:(1)定義微博輿情話題的傳播底圖為有向網(wǎng)絡(luò)G(U,E),其中U為該網(wǎng)絡(luò)中所有節(jié)點(diǎn)的集合,E為網(wǎng)絡(luò)中所有邊的集合,節(jié)點(diǎn)總數(shù)為N。
(2)定義U中的節(jié)點(diǎn)僅具有兩種狀態(tài),即易感狀態(tài)S和傳播狀態(tài)I,其中S態(tài)表示節(jié)點(diǎn)沒有對(duì)目標(biāo)話題進(jìn)行轉(zhuǎn)發(fā),I態(tài)表示節(jié)點(diǎn)對(duì)目標(biāo)話題進(jìn)行了轉(zhuǎn)發(fā);USt、UIt分別表示t時(shí)刻,網(wǎng)絡(luò)中的S態(tài)節(jié)點(diǎn)集合和I態(tài)節(jié)點(diǎn)集合。
(3)定義節(jié)點(diǎn) u 所關(guān)注的節(jié)點(diǎn)集合為 FL(u)={v|eu,v∈E}。
(4)定義 t時(shí)刻節(jié)點(diǎn) u 所關(guān)注的 S 態(tài)節(jié)點(diǎn)集合為 FLSt(u)={v|v∈FL(u),且 v為 S 態(tài)};t時(shí)刻節(jié)點(diǎn) u 所關(guān)注的 I態(tài)節(jié)點(diǎn)集合為 FLIt(u)={v|v∈FL(u),且 v 為 I態(tài)}。 此處假設(shè) FLIt(u)中的每個(gè)節(jié)點(diǎn)均會(huì)影響節(jié)點(diǎn)u的轉(zhuǎn)發(fā)行為,且其中所有節(jié)點(diǎn)對(duì)節(jié)點(diǎn)u轉(zhuǎn)發(fā)行為的影響相互獨(dú)立。
(5)根據(jù)式(1)確定節(jié)點(diǎn) u 對(duì)話題 topic的轉(zhuǎn)發(fā)概率 Pu,topic

(6)假設(shè)節(jié)點(diǎn)u對(duì)話題topic產(chǎn)生轉(zhuǎn)發(fā)行為的閾值為λu,且λu=[0,1],則當(dāng) Pu,topic≥λu時(shí),節(jié)點(diǎn) u 將產(chǎn)生轉(zhuǎn)發(fā)行為,并由 S 態(tài)轉(zhuǎn)變成為I態(tài)。
(7)FLI(u)中每增加一個(gè) I態(tài)節(jié)點(diǎn)時(shí),需要對(duì)特征集合 Fu,topic中的話題發(fā)布者特征進(jìn)行更新,即更新表1中的特征4、5、6。由此得到目標(biāo)輿情話題在網(wǎng)絡(luò)G(U,E)中的傳播過(guò)程。
3.2 PRALR 算法
本文根據(jù)上述話題轉(zhuǎn)發(fā)規(guī)則,給出了一種微博輿情話題轉(zhuǎn)發(fā)規(guī)模的預(yù)測(cè)算法——PRALR算法,其實(shí)現(xiàn)過(guò)程如下。
步驟1:網(wǎng)絡(luò)初始化。獲取微博網(wǎng)絡(luò)上輿情話題傳播的歷史數(shù)據(jù)集,得到傳播底圖 G(U,E),并為網(wǎng)絡(luò)中的每一個(gè)節(jié)點(diǎn)用 1,2,…,N進(jìn)行編號(hào),其中N為節(jié)點(diǎn)集合U中的節(jié)點(diǎn)總數(shù);利用式(1)給出的邏輯回歸模型,通過(guò)訓(xùn)練得到權(quán)值向量ω,進(jìn)而建立每個(gè)節(jié)點(diǎn)的轉(zhuǎn)發(fā)概率預(yù)測(cè)公式;為U中的每個(gè)節(jié)點(diǎn)設(shè)置隨機(jī)的轉(zhuǎn)發(fā)閾值λ∈[0,1];初始狀態(tài)下,網(wǎng)絡(luò)中所有節(jié)點(diǎn)均設(shè)置為易感狀態(tài)S,即US0中的節(jié)點(diǎn)數(shù)為N,UI0中的節(jié)點(diǎn)數(shù)為0;根據(jù)網(wǎng)絡(luò)中邊的集合E,為U中的每個(gè)節(jié)點(diǎn) i建立集合 FLS0(i)、FLI0(i)(i=1,2,…,N)。
步驟2:t=1時(shí)刻,設(shè)置網(wǎng)絡(luò)中某一節(jié)點(diǎn)v為I態(tài),即v為話題topic在該網(wǎng)絡(luò)中的入口節(jié)點(diǎn),將其從對(duì)應(yīng)的FLS0(i)中移除,放入相應(yīng)的 FLI0(i)中,并更新 US1、UI1。
步驟 3:t時(shí)刻,對(duì)于網(wǎng)絡(luò)中任意節(jié)點(diǎn) u,根據(jù)集合 FLIt-1(u)中各節(jié)點(diǎn)狀態(tài)的改變,對(duì)節(jié)點(diǎn)u的特征4、5、6進(jìn)行更新,得到更新后的Fu(topic,G),并重新計(jì)算節(jié)點(diǎn) u 此時(shí)的轉(zhuǎn)發(fā)概率函數(shù) Pu,topic,如果 Pu,topic≥λu,則節(jié)點(diǎn)u產(chǎn)生轉(zhuǎn)發(fā)行為。
步驟4:將在步驟3中產(chǎn)生轉(zhuǎn)發(fā)行為的節(jié)點(diǎn)u從對(duì)應(yīng)的FLSt-1(i)中移除,加入到相應(yīng)的集合 FLIt-1(i)中,即將 FLSt-1、FLIt-1分別更新成為 FLSt、FLIt,同時(shí)更新 USt、UIt。
步驟5:t=t+1,重復(fù)步驟3~步驟4,直到網(wǎng)絡(luò)中再也沒有新的節(jié)點(diǎn)產(chǎn)生轉(zhuǎn)發(fā)行為為止。此時(shí),集合UI中的節(jié)點(diǎn)數(shù),即為話題topic在該網(wǎng)絡(luò)中的最終轉(zhuǎn)發(fā)次數(shù)。
4 實(shí)驗(yàn)仿真
4.1 實(shí)驗(yàn)數(shù)據(jù)集
本文利用自行開發(fā)的爬蟲工具從新浪微博中抓取了1000條用戶特征數(shù)據(jù),及這些用戶在采樣時(shí)間段內(nèi)發(fā)布的95783條微博數(shù)據(jù),并最終從原始數(shù)據(jù)集中提取出15276條輿情話題數(shù)據(jù),構(gòu)成實(shí)驗(yàn)數(shù)據(jù)集,其中包括6814條轉(zhuǎn)發(fā)數(shù)據(jù),8762條非轉(zhuǎn)發(fā)微博數(shù)據(jù)。
4.2 輿情話題轉(zhuǎn)發(fā)行為預(yù)測(cè)結(jié)果及分析
本文利用Matlab工具對(duì)微博用戶輿情話題轉(zhuǎn)發(fā)行為進(jìn)行預(yù)測(cè)。首先,從實(shí)驗(yàn)數(shù)據(jù)集中提取出表1所描述的11個(gè)話題轉(zhuǎn)發(fā)行為特征,構(gòu)建每個(gè)用戶的話題轉(zhuǎn)發(fā)行為特征集合Fu,topic;然后,將實(shí)驗(yàn)數(shù)據(jù)集分成訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集兩部分,其中訓(xùn)練集中的微博數(shù)量占70%,測(cè)試集中的微博數(shù)量占30%;最后,利用訓(xùn)練集估計(jì)出式(1)中的權(quán)值向量ω,進(jìn)而建立每個(gè)用戶的微博輿情話題轉(zhuǎn)發(fā)概率模型,并利用測(cè)試集對(duì)用戶的轉(zhuǎn)發(fā)行為進(jìn)行預(yù)測(cè),預(yù)測(cè)結(jié)果見表2。結(jié)果表明,本文給出的微博輿情話題轉(zhuǎn)發(fā)行為預(yù)測(cè)模型具有較高的預(yù)測(cè)準(zhǔn)確度。
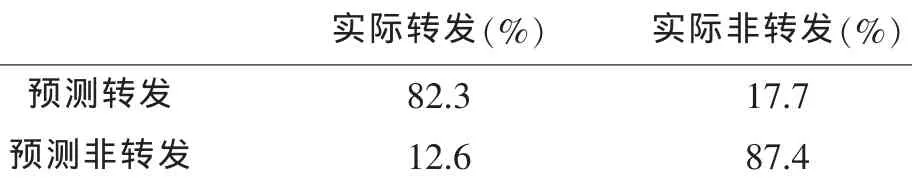
表2 微博用戶轉(zhuǎn)發(fā)行為預(yù)測(cè)結(jié)果
4.3 輿情話題轉(zhuǎn)發(fā)規(guī)模預(yù)測(cè)結(jié)果及分析
本文從數(shù)據(jù)集中選取了2個(gè)輿情話題,其中話題1為“奧巴馬2013年就職典禮”,其在本文選取的微博子網(wǎng)中被轉(zhuǎn)發(fā)了595次(采樣時(shí)間為2013年1月 21日-2013年 3月 31日);話題2為“長(zhǎng)春盜車殺嬰案”,其在傳播子網(wǎng)中被轉(zhuǎn)發(fā)了1057次(采樣時(shí)間為2013年3月4日-2013年3月31日)。利用PRALR算法對(duì)以上兩個(gè)話題的轉(zhuǎn)發(fā)規(guī)模進(jìn)行預(yù)測(cè),分別得到了其轉(zhuǎn)發(fā)次數(shù)隨時(shí)間的變化趨勢(shì),如圖1所示。結(jié)果表明,PRALR算法可以有效地預(yù)測(cè)微博輿情話題轉(zhuǎn)發(fā)規(guī)模的演化趨勢(shì)。

圖1 話題轉(zhuǎn)發(fā)規(guī)模隨時(shí)間的變化趨勢(shì)
5 結(jié)論
本文分析了影響微博用戶輿情話題轉(zhuǎn)發(fā)行為的相關(guān)因素,利用邏輯回歸模型,對(duì)微博用戶的輿情話題轉(zhuǎn)發(fā)行為進(jìn)行了預(yù)測(cè)。此外,本文還將微觀層面上的個(gè)體用戶行為與宏觀層面上的微博網(wǎng)絡(luò)話題傳播過(guò)程相結(jié)合,給出了一個(gè)基于個(gè)體行為的微博輿情話題轉(zhuǎn)發(fā)規(guī)模預(yù)測(cè)算法——PRALR算法。實(shí)驗(yàn)結(jié)果表明,本文給出的微博用戶輿情話題轉(zhuǎn)發(fā)概率預(yù)測(cè)模型,及預(yù)測(cè)微博輿情話題轉(zhuǎn)發(fā)規(guī)模的PRALR算法,均具有較高的預(yù)測(cè)精度。本文的研究工作將為相關(guān)部門制訂有效的微博輿情話題控制策略提供一定的理論依據(jù)。
[1]D J Zhao,M B Rosson.How and Why People Twitter:The Role that Micro -blogging Plays in Informal Communication at Work [C]//In Proceedings of ACM 2009 International Conference on Supporting GroupWork, Florida, 2009:243-252.
[2]吳凱,季新生,劉彩霞.基于行為預(yù)測(cè)的微博網(wǎng)絡(luò)信息傳播建模[J].計(jì)算機(jī)應(yīng)用研究,2013,30(6):1809-1812.
[3]張旸,路榮,楊青.微博客中轉(zhuǎn)發(fā)行為的預(yù)測(cè)研究[J].中文信息學(xué)報(bào),2012,26(4):109-114.
[4]張華平, 劉群.中文自然語(yǔ)言處理開發(fā)平臺(tái)[EB/OL].[2013-03-01].http://www.nlp.org.cn.
[5]林學(xué)民,王煒.集合和字符串的相似度查詢[J].計(jì)算機(jī)學(xué)報(bào),2011,34(10):1853-1862.
[6]R Narayanam,Y Narahari.A Shapley Value-based Approach to Discover Influential Nodes in Social Networks [J].IEEE Transactions on Automation Science and Engineering, 2011,8(2):130-147.
[7]何靜,郭進(jìn)利.基于改進(jìn)PageRank算法的微博用戶影響力研究[J].中國(guó)報(bào)業(yè),2013 (2):21-23.
[8]苑衛(wèi)國(guó),劉云,程軍軍,等.微博雙向“關(guān)注”網(wǎng)絡(luò)節(jié)點(diǎn)中心性及傳播影響力的分析[J].物理學(xué)報(bào),2013,62(3).
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39

- 中國(guó)管理信息化的其它文章
- 基于CPV模型的宏觀壓力測(cè)試實(shí)證研究
——以中國(guó)農(nóng)業(yè)發(fā)展銀行為例 - JSZ期限結(jié)構(gòu)模型對(duì)我國(guó)債券收益率曲線的擬合實(shí)證
- R&D費(fèi)用同IPO抑價(jià)之間的關(guān)系研究
——以深圳創(chuàng)業(yè)板為例 - 互聯(lián)網(wǎng)金融沖擊下小額貸款公司的挑戰(zhàn)與應(yīng)對(duì)策略研究
——基于SWOT分析 - 基于“雙主體”角度的教學(xué)技能評(píng)價(jià)體系設(shè)計(jì)
- 高等學(xué)校自然科學(xué)研究投入產(chǎn)出總量及其變動(dòng)趨勢(shì)分析