基于過程挖掘的未來感知預測模型
2015-06-01 12:30:37劉利釗汪建均顧曉光
系統工程與電子技術 2015年4期
劉 健,劉利釗,汪建均,顧曉光
(1.南京理工大學經濟管理學院,江蘇南京210094;2.廈門理工學院計算機與信息工程學院,福建廈門361024)
基于過程挖掘的未來感知預測模型
劉 健1,劉利釗2,汪建均1,顧曉光1
(1.南京理工大學經濟管理學院,江蘇南京210094;2.廈門理工學院計算機與信息工程學院,福建廈門361024)
將事件日志中蘊含的過程模型看成兩緊鄰活動的組合,提出兩種新的過程模型。首先,利用日志信息中的活動緊鄰關系構造鄰接矩陣提取過程模型,該模型中每個活動僅發生一次;其次,為避免過程模型中出現回路或者環路而造成模型預測精度降低的情況發生,在構造的鄰接矩陣中增加活動在事件日志中所處的順序位次,構造含有活動位次信息的鄰接矩陣,以此為基礎上進一步提取過程模型,該模型中每個活動在同一個位次上僅發生一次;再次,通過矩陣中的信息可獲得過程模型中每個上層節點到各個下層節點的路徑與相應概率;接下來,根據事件日志中信息的類型和特征,利用過程模型對決策者所需要的信息(如活動名稱、等待時間、發生概率)進行預測;最后,利用隨機數據與實際數據同基于序列提取規則的過程模型預測結果進行比較,驗證所提模型的實際有效性。
鄰接矩陣;過程挖掘;預測;商業智能
0 引 言
隨著信息技術的發展和信息時代的到來,越來越多的數據信息被記錄在相應的數據信息系統中,這些被記錄下來的數據信息以事件日志的形式進行保存[1],同時這些記錄下來的數據信息蘊含著相關企業的生產制造或商業交易操作過程。企業如何利用這些數據信息,提取有重要價值的操作過程模型,通過模型發現現有過程的不足之處并進行改進,具有非常重要的意義。那么如何從這些以事件日志形式記錄的信息數據中提取出對自己有價值的信息,已經引起越來越多企業經營者和管理者的興趣[2]。伴隨著這種需求的出現,過程挖掘這種新的過程模型挖掘技術應運而生并得到迅速發展[3-5],過程挖掘[612]的目的是利用這些記錄在信息系統中的事件日志信息提取蘊含其中的過程模型。利用過程挖掘技術通過某個企業記錄在信息系統中的數據信息,能夠發現企業的日常采購或銷售的詳細過程模型,從而管理者根據采購和銷售模型建立一套相應的庫存管理預測系統,根據該預測系統實現該企業庫存管理的智能化控制。
隨著大數據時代的到來,第一,越來越多的事件通過信息系統記錄下其詳細的歷史過程;第二,業務流程管理與商業智能軟件已經引起專家學者、軟件開發者和企業管理者的關注。這些都驅動著過程挖掘這種新技術的進一步發展。
過程挖掘[3-9]自20世紀90年代開始萌芽,目前已經成為一個重要的研究領域,它可以彌補現有數據挖掘中存在的一些不足之處[13]。相比數據挖掘其優勢主要表現為:①能讓管理者更好地理解某產品的生產制造過程或某個商業事件的交易過程;②發現并確定實際生產制造或交易過程同理想化生產制造或交易過程之間的不同之處,從而對實際過程進行檢查、調整、修改或重新設計;③對生產過程中某個活動的運行時間進行跟蹤和查詢;④檢查和改善現有的生產制造或商業交易過程,發現機會,增加產品的產量或完善交易過程[1415]。例如:在日常醫療保健方面,基于記錄在某醫院信息體統中的數據信息提取該事件的常規操作流程,從而對患者目前接受的治療過程進行異常識別,避免可能發生的不當治療[1617]。
在日常的商業操作流程和企業生產加工制造中,根據記錄在信息系統中的數據信息提取過程模型,能夠對將來可能發生的活動或該活動發生的時間和概率等進行預測。通過服務推薦模型[18],可以預測接下來最可能發生的活動,利用該模型可進行活動預測但不能對活動發生的時間和概率進行預測。通過循環時間預測方法[19],基于非參數回歸技術可以預測某個事件活動發生后到整個過程結束的時間,根據回歸分析還可以預測某個活動接下來的發生概率。注解轉移系統過程模型[1],基于集合和序列算法能夠預測從過程開始到其中任意活動所需時間和從任意活動到整個過程結束所需時間以及過程模型中任意兩個相鄰活動之間的時間間隔(interval time,IT);該算法能夠解決循環時間預測方法中存在的不足。荷蘭埃因霍芬理工大學開發的過程挖掘(process mining,PROM)工具箱[20]中還包含多種進行提取過程模型的方法,如:啟發式算法[8],區域挖掘算法[9],字母系列[21],Petri網[22]和遺傳算法[23]等。
本文創新之處:將蘊含在事件日志中的過程模型看成兩個緊鄰活動之間的組合,通過這種緊鄰關系的組合構造鄰接矩陣,進一步提取過程模型。通過鄰接矩陣中包含的信息構建過程模型并計算每個上層節點到下層節點可能存在的路徑、間隔時間和條件概率。本文基于鄰接矩陣提取過程模型(process model based on adjacency matrix abstraction,PMAM)并利用模型進行預測,該方法與現有方法的原理不同,基于PMAM提取的過程模型法不僅可以預測接下來最有可能發生的活動,并預測當某個活動發生后接下來所有可能發生的活動,還可以同時預測達到各個活動的概率及到達時間。本文通過PMAM,針對不同案例可對鄰接矩陣中的信息進行增加,通過提取的過程模型獲得決策者所需要的特征,此時僅需要在過程模型中添加所需要的特征信息即可。本文利用頻率信息預測接下來所有可能發生的活動概率,采用平均值作為時間預測函數[1]預測到達該活動的時間。
本文總體結構如下:首先,對信息系統中的事件日志進行簡要概括,其次,基于隨機數據對本文提出的鄰接矩陣和位次鄰接矩陣的構成過程進行詳細分析并闡述其相應過程模型的提取算法和步驟;再次,利用兩個隨機數據案例對PMAM與現有的過程模型預測結果進行比較并分析預測結果的優劣;然后,利用一個真實數據案例對PMAM與基于序列提取規則過程模型(process model base on sequence abstraction,PMS)預測結果再次進行比較分析;最后,對本文所做工作進行總結及展望。
1 事件日志
目前在人力資源管理系統、企業生產與銷售管理系統、金融證券交易系統等信息系統中都存儲了大量的事件日志信息,這些日志信息都為學術的研究提供了有力的數據支撐。在學術領域,針對商業交易或工業生產中的過程模型都是假設每個事件是相互獨立的,也就是說每個事件對應一個執行活動且活動之間相互獨立。從信息系統角度來看,過程模型包含了業務流程全部針對執行活動的相關記錄。在信息系統中記錄的事件日志包含著活動的開始時間、完成時間、費用和參與人員等相關信息。
表1是一個關于航空航天與國防領域某航空公司對所研發關鍵零部件申請號為“B64654871”的專利申請過程[23]的事件日志信息(部分)。該事件日志中包含4個方面的信息:活動名稱、完成時間、人員和費用。根據其中的活動信息,在該過程中共有5個活動發生,第一個發生的活動是“register request”,該活動完成時間是“20- 10- 2013,10:00”;第二個發生的活動是“examine casually”,該活動完成時間是“21- 10- 2013,11:00”;第五個發生的活動(最后活動)是“accept request”相應的完成時間是“07- 11- 2013,17:30”。

表1 Excel格式事件日志(該圖反映了該航空公司對所研發關鍵零部件的專利申請過程)
數據管理系統中記錄的事件日志一般有XES、XML、Word和Excel等格式。表1的事件日志信息是一個用Excel格式表示的針對專利號為A14658432的申請活動流程。通過觀察可以發現該案例中的過程是由一系列相互聯系活動組合,如:“register request-examine casually”,“examine casually-check ticket”,“check ticket-Decide”和“Decide-accept request”,根據該組合過程可提取出該航空公司對所研究關鍵零部件專利號為A14658432的過程模型。根據過程模型,管理者可以預測接下來將要發生什么活動,從而對活動進行預測。例如:當活動“Decide”發生后,接下來活動“accept request”可能會發生。在此基礎之上,利用事件日志中活動對應的時間,計算任意兩相鄰活動之間的時間間隔。如:在上述日志信息中可知,當活動“Decide”完成后,距離活動“accept request”完成還需要74小時10分鐘的時間。
2 事件日志中鄰接矩陣生成
事件日志中,不同路徑中兩相同緊鄰活動之間的時間間隔可能會不同,本文采用文獻[1]中的平均值作為時間預測函數。本文利用蘊含在事件日志的活動,通過兩緊鄰活動之間組合構造鄰接矩陣,基于該鄰接矩陣提取所對應的過程模型,然后利用過程模型進行相應事件的預測(活動、概率和時間)。
2.1 鄰接矩陣構造算法
本部分采用文獻[1,24]中的隨機數據I為例(見表2),詳細描述事件日志數據信息所對應鄰接矩陣構造過程的算法細節,在此基礎之上,闡述基于矩陣的過程模型提取方法。

表2 隨機數據I
顯然,表2中含有7個不同的案例,每個案例中記錄著相應該過程發生的活動名稱和時間,本文假設對應時間為活動完成時間。
2.1.1 算法細節
假設事件日志中所含活動信息對應的鄰接矩陣是一個(N+2)×(N+2)的方陣,其中,N是指事件日志中所有不同類型活動的數量,2表示人為增加的兩個虛擬活動開始(START)和結束(END)。表2中含有A,B,C,D,E 5個不同類型的活動,再加上START和END,表2中的事件日志信息對應的是一個7×7的鄰接矩陣。
本文通過鄰接矩陣中的數據來反映這種緊鄰活動的鄰接關系,即:當兩個活動i與j在事件日志中所有案例中的緊鄰頻率(frequency,FRE)之和為n時,那么矩陣中在這兩個活動(i,j)的對應位置的信息是[n],若兩個活動i與j在事件日志中所有案例中沒有作為緊鄰活動出現過,則鄰接矩陣的相應位置為空(在本文中在該位置不添加任何的信息,因此在本文中用空白進行表示,當然也可以在該位置采用空集合來替代,達到相同的效果)。利用表2中隨機數據I構造的鄰接矩陣如表3所示。
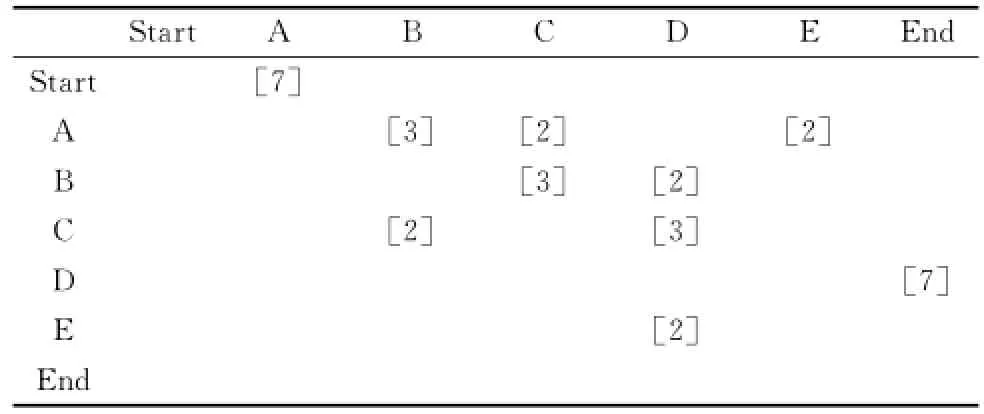
表3 鄰接矩陣I_______________________
根據表3(鄰接矩陣I)可知,針對表2中的7個案例,活動A與B緊鄰的次數之和是3,活動A與C緊鄰的次數之和是2,活動A與E緊鄰的次數之和也是2。從而當活動A發生后,接下來活動B、C和E將會發生,這3個不同活動發生的相應概率分別是3/7,2/7和2/7。活動START與活動A緊鄰的次數之和是7,活動D與活動END緊鄰的次數之和也是7。由于START和END都是虛擬的活動,因此在表2中,第一個活動都是A,最后一個活動都是D。
由于表2中的時間對應活動的完成時間,案例1中活動A完成后,距離活動B完成所需時間間隔為4;案例3中活動A完成后,距離活動B完成所需時間間隔為4;在案例5中當活動A完成后,距離活動B完成所需時間間隔為6。通過文獻[1,24]中提到的平均值作為時間預測函數,根據表2中時間信息,可知活動A完成后,針對上述3個案例的平均間隔時間值,還需要4.67(14/3)的間隔時間活動B才能完成,同樣可以得到,距離活動B、C和E完成所需要的時間分別是4.67,4.50和9.50。
根據前面的分析,利用對應事件日志中的活動完成時間,計算兩個相鄰活動(i,j)之間的時間間隔,得到新的含有時間信息的鄰接矩陣,如表4所示。由于活動START與END是構造鄰接矩陣時,人為增加的兩個虛擬活動,所以事件日志信息中的任何真實活動與這兩個虛擬活動緊鄰之間的時間間隔都是0。
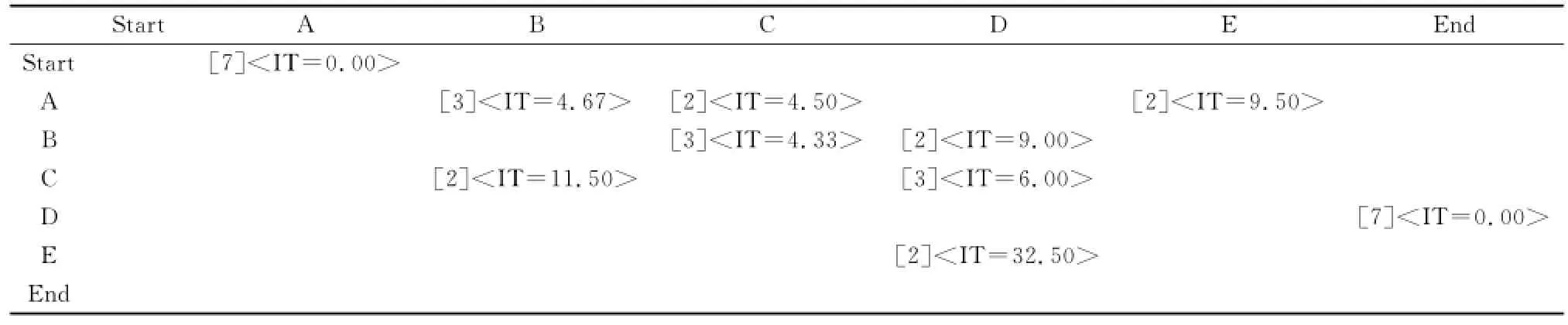
表4 鄰接矩陣Ⅱ
2.1.2 過程模型提取
根據鄰接矩陣的構造過程算法細節可知,當鄰接矩陣中所對應(i,j)位置數據不為空時,說明在事件日志中,活動i與j在某個或某幾個案例中作為緊鄰活動,那么在過程模型提取時,這兩個活動之間有直接的聯系,從而應用線連接起來,當在兩個活動相連的線上增加矩陣中的相應信息(頻率與時間間隔數值),可得到包含時間信息與頻率信息的過程模型。針對表2中的隨機數據(7個案例,26個活動)對應的鄰接矩陣Ⅱ,提取的過程模型如圖1所示。

圖1 預測過程模型(基于鄰接矩陣Ⅱ提取)
表2中含有的5個不同類型的活動在圖1的模型中僅出現一次,此時在圖1中活動B與C之間存在一個回路,根據圖1中現有頻率信息,無法計算出活動B與C之間回路發生的次數(無法確定活動B與C在事件日志案例中緊鄰成對出現的次數)。
據文獻[2,25]可知,過程模型的預測精度與模型中回路或者環路的數量呈負相關性,隨著回路或者環路數量的增多,該過程模型的精度相應降低。為避免過程模型中產生回路或者環路,在鄰接矩陣Ⅱ中的(i,j)處,增加活動i在事件日志案例中所發生位置對應順序數據信息,進一步構造含有活動順序位次的鄰接矩陣。
2.2 鄰接矩陣進一步構造
表2中,活動A作為第1位次的活動出現了7次,即A都是第一個發生的活動。由于每個案例中發生活動的數量與過程不同,每個活動順序發生的位次不同,D在案例4和案例7中是第3個發生的活動,在其余5個案例中是第4個發生的活動,但所有案例中D都是最后一個發生的活動,因此無論D在哪個位次出現,距離結束(END)的時間間隔都是0(IT=0)。
本文假設虛擬活動START在案例中對應的位次是0。在鄰接矩陣Ⅱ中的(i,j)處,增加活動i在事件日志中相對應的位次,得到含有活動位次信息的鄰接矩陣Ⅲ,如表5所示。
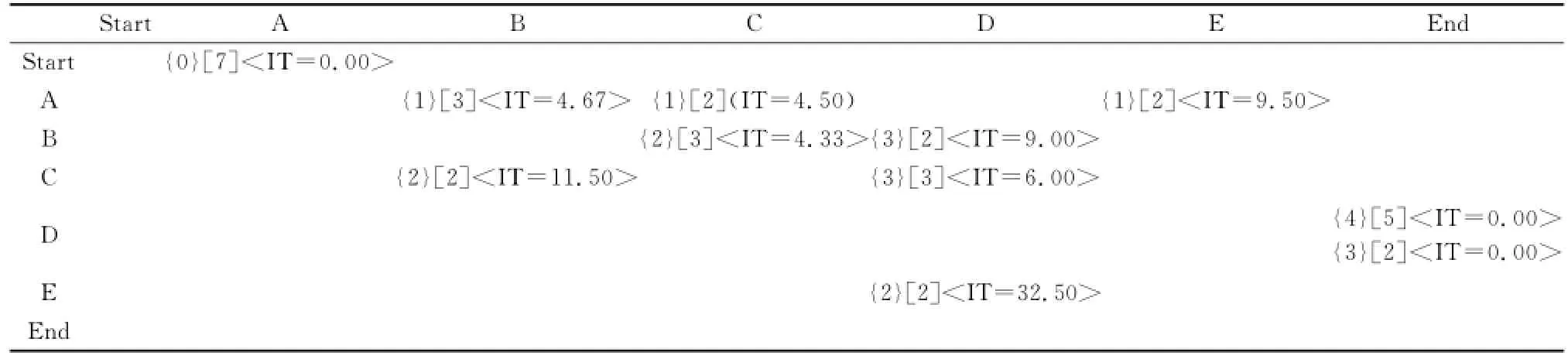
表5 鄰接矩陣Ⅲ
2.2.1 過程模型提取
對比鄰接矩陣Ⅲ與鄰接矩陣Ⅱ中的信息,可以發現,活動D與END相對應位置的信息由([7]<IT=0.00>)變為({4}[5]<IT=0>;{3}[2]<IT=0>),表示在表2中,活動D作為第3位次的活動與END相鄰的是2次,作為第4位次的活動與END相鄰的是5次。表2基于位次鄰接矩陣提取的過程模型如圖2所示。
針對表2中的隨機數據,都是基于鄰接矩陣提取過程模型,但是由于鄰接矩陣Ⅱ與鄰接矩陣Ⅲ所含有信息的不同,得到圖1與圖2中兩個不同的過程模型。圖2中同一個活動可能多次出現(如:活動C出現2次,活動D也出現2次),但是不同類型活動在同一個順序位次上僅出現了一次,同時圖2中的模型與圖1中的模型相比不存在回路或環路。

圖2 預測過程模型(基于鄰接矩陣Ⅲ提取)
根據圖2中的過程模型可知,當活動B發生在第2個位次時,接下來在第3位次上將會發生活動C,根據圖2過程模型中的頻率信息可知,第2位次發生活動B的頻率是3,第3位次發生活動C的頻率是3。第3位次中的活動與第2位次活動B相鄰的只有活動C,利用活動C在第3位次發生的頻率3與活動B在第2位次發生的頻率3可以求得此時的條件概率,那么活動C發生的概率是1(P{{3}←C/{2}←B}=3/3=1,與此同時,活動B完成后距離活動C完成的時間是4.33。
針對表2中的隨機數據事件日志信息,利用圖2中的過程模型相比利用圖1中的過程模型能得到更好地預測結果,原因在于鄰接矩陣Ⅲ比鄰接矩陣Ⅱ含有更多的信息(案例中每個活動的順序位次信息),因此圖2中過程模型更精確。因此,在實際應用中,可根據決策者對模型預測精度要求,在鄰接矩陣中增加不同的信息。
3 隨機數據預測結果比較
利用隨機數據,將本文提出的PMAM的預測結果與文獻[1]中提出的PMS的預測結果進行比較,來驗證PMAM算法的可行性。
3.1 隨機數據I
針對表2中的事件日志,利用過程挖掘工具PROM[20]提取PMS與PMAM(具體數據信息如圖2中所示),這兩種模型的預測結果比較如表6所示。

表6 PMAM與PMS預測結果
在表6中的第2個狀態表示活動A是過程模型或事件日志的案例中第1個發生的活動,或者活動A是第一個位次的活動,在本文中用(“A{1}”)來表示這種狀態。由表6可知,PMAM與PMS共在9個狀態下進行預測。針對時間預測:在2個狀態下得到的結果不同(“A{1}”和“D{4}”),在7個狀態下得到的結果相同。在表6中:當“A{1}”時,PMAM有3個可能的預測值,而現有的PMS只有1個預測值。當“D{4}”時,PMAM只有1個預測值,而PMS有2個可能的預測值。通過表6還可以發現,現有PMS不能預測接下來發生某個活動的概率。
通過表6可知,PMS算法關注已經發生了什么活動;而PMAM算法關注當前活動所處的順序位次及接下來可能發生的活動。利用PMS和PMAM進行預測,相同之處在于:當發生在同一個順序位次的活動不同時,模型中的路徑將會在此處產生分支;不同之處在于:利用PMS算法,模型中的路徑只要有分支產生,直到最后一個活動完成路徑都不可能再次合并;利用PMAM算法,若在接下來在同一個順序位次上有相同的活動發生時,模型中產生分支的路徑將會再次進行合并。
在表6中,當“D{4}”時,利用PMAM進行時間預測時只有1個數值。根據上面的分析可知,在案例2和案例4中:[A,B,C,D]與[A,C,B,D]因為在第2順序位次的活動不同(B和C),路徑產生了分支,但是在第4順序位次的活動都是D,因此兩條不同的路徑在活動D處在第4位次時又重新進行了合并。當“A{1}”時,接下來第2位次上有3個不同的活動出現,利用PMAM進行預測,得到指向這3個不同活動相應的時間值,而利用PMS進行預測僅有1個時間預測值。
當事件日志中包含活動較多時,鄰接矩陣階數增加極快,此時得到的預測過程模型將極為復雜,但是利用本文的算法提取過程模型,在同一個層次每個活動僅出現一次,而基于前面分析,利用基于序列規則提取過程模型,在同一個層次上相同的活動可能出現多次,因為利用序列提取的過程模型,路徑一旦出現分支將不會再合并。當事件日志中存在大量活動時,利用PMAM進行過程挖掘將會比利用PMS進行過程挖掘能節省大量的運算時間,從而可以提高運算速度。
根據過程模型中的頻率信息,利用在2個狀態“A{1}”和“D{4}”時的預測值,可得:
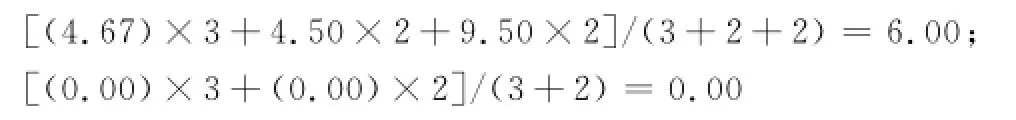
顯然,在上述兩種狀態時,利用PMS得到的時間預測值,是利用PMAM進行時間預測的加權綜合值(權重與頻率有關)。
本文認為,在同一種狀態下提供多種可能性的預期比僅能提供一種預期要好。針對表2中的事件日志在兩種模型的預測結果進行分析后得到表7。

表7 利用隨機數據I兩種模型預測結果的比較
根據表7可得如下結論:
(1)概率預測:PMS不能進行概率預測,因為在PMS中不存在頻率信息。
(2)時間預測:在77.78%的情形下PMAM與PMS得到相同的時間預測結果;在11.11%的情形下利用PMAM比PMS得到更好的時間預測結果;在11.11%的情形下,利用PMS比PMAM得到更好的時間預測結果;因此,利用PMAM進行時間預測與PMS進行時間預測得到相同的結果。
(3)活動預測:兩個模型對活動的預測起到相同的效果,可以通過這兩個模型的路徑預測接下來可能發生的活動。
3.2 隨機數據Ⅱ
本節利用表8中的隨機數據Ⅱ,再次對PMAM與PMS的預測結果進行比較,進一步驗證本文提出的算法。

表8 隨機數據Ⅱ
針對表8中的隨機數據Ⅱ事件日志,構造含有活動順序位次的鄰接矩陣,基于鄰接矩陣提取過程模型如圖3所示。利用過程挖掘工具PROM 5[20]對表8中事件日志提取PMS,將圖3與PMS預測結果進行比較,從圖3可知,當在4個狀態即:“A{1}”,“B{2}”,“C{3}”和“C{6}”時,過程模型中的路徑出現了分支;當且僅當“C{5}”時,過程模型中的分支路徑進行合并。通過分析發現,在上述出現分支的3種狀態下(“A{1}”,“B{2}”和“C{3}”),通過時間預測結果對比可以發現,PMS預測值是PMAM預測值的加權綜合值,此時PMAM比PMS能起到更好的時間預測效果。當“C{6}”時,PMAM的概率預測結果為:接下來發生活動E(“adjacency E”)的概率P=1/2,當活動C完成后,距離活動E完成所需時間為11.00(IT=11.00);同時可以得到接下來發生D(“adjacency D”)的概率P=1/2,當活動C完成后,距離活動D完成所需時間為4.00,但此時利用PMS得到的時間預測值,并不是本文提出的PMAM加權綜合預測值,而是其中兩個預測值之一(說明某個活動不會發生)。根據PMS可知,當[A,B,C,C,C,C]這6個活動已經發生后,接下來發生“adjacency D”的概率P=0,相應的當[A,B,C,B,C,C]這6個活動已經發生后,接下來發生E(“adjacency E”)的概率P=0。
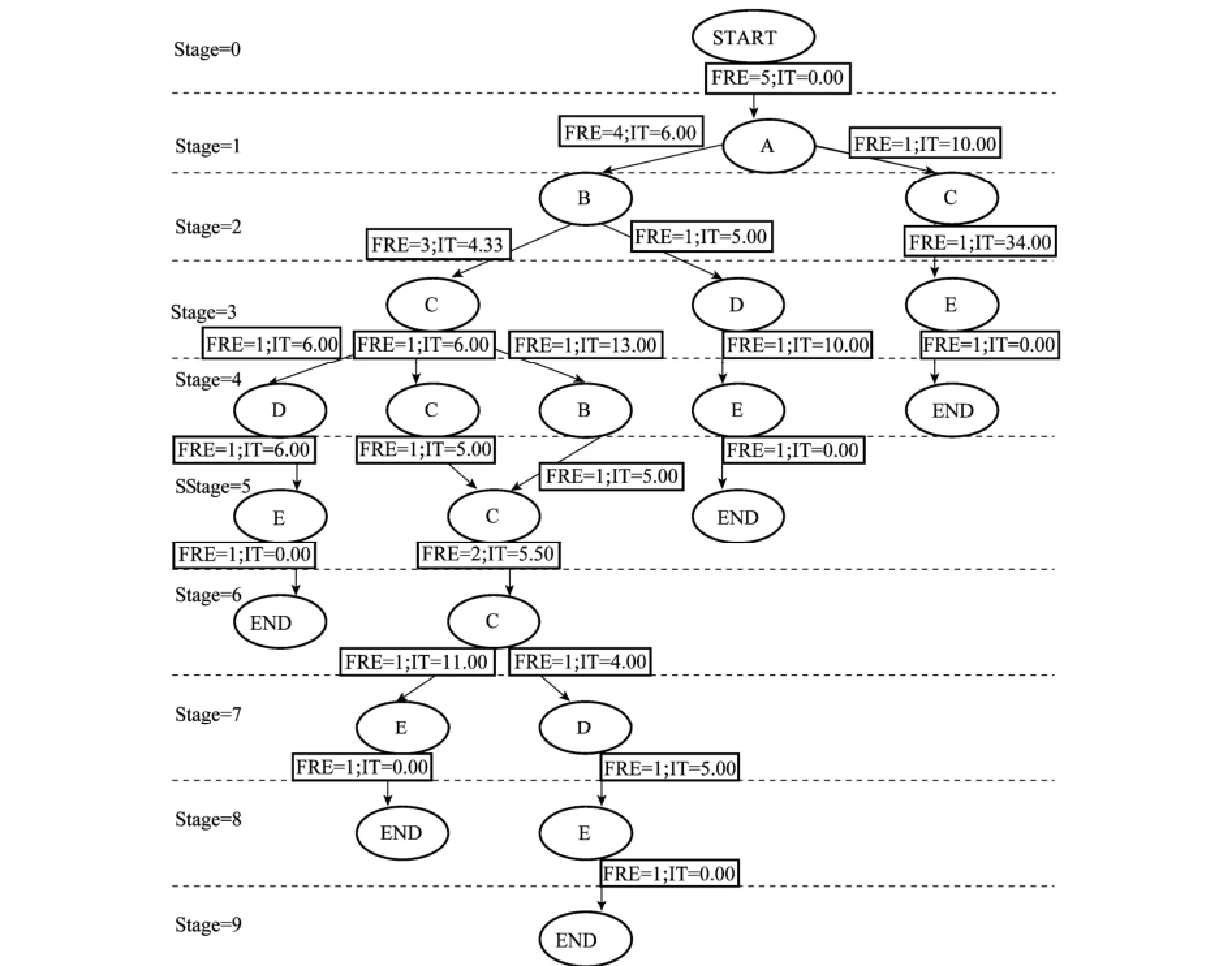
圖3 預測過程模型(基于鄰接矩陣提取規則)
利用本文PMAM中含有的頻率進行概率預測,是基于已發生的前一個活動,預測發生下一個活動的條件概率,PMS是基于已發生的所有活動,預測到下一個活動的條件概率。由于在同一個狀態下能提供更多預測信息,該模型能起到更好地預測效果,因此本文提出的PMAM預測效果比文獻[11]中的PMS預測效果好。
針對表8中的事件日志(隨機數據Ⅱ)在兩種模型下的預測結果進行分析,得到如表9所示的比較數據。

表9 利用隨機數據Ⅱ兩個模型預測結果的比較
根據表9中的數據可得如下結論:
(1)概率預測:PMS不能進行概率預測,因為在PMS中不存在頻率信息,所以PMAM進行預測比PMS得到更好的概率預測結果。
(2)時間預測:在72.22%的狀態下,本文提出的PMAM與PMS得到完全相同的時間預測結果,在22.22%的狀態下,PMAM比PMS得到更好的時間預測結果,僅在5.56%的狀態下,PMS比PMAM得到更好的時間預測結果。因此,利用PMAM進行時間預測比利用PMS進行時間預測得到更好的時間預測結果。
(3)活動預測:通過過程模型中的路徑判定接下來可能發生的活動,兩個模型得到相同活動預測效果。
4 真實數據預測結果比較
為進一步說明本文所提出的PMAM在實際商業流程或企業生產過程進行預測的有效性,在該部分,利用真實數據與現有PMS的預測結果進行比較。
本文采用2003~2010年美國專利申請的相關數據[26](種類編號B64:航空航天與國防領域,該專利申請數據總共含有24576個案例和456個不同類型的活動)。由于對456個不同類型活動進行挖掘是非常龐大的過程而且有些活動出現的頻率非常低,本文對案例中出現頻率最高的10個活動,選擇數據中的50個案例(661個活動),利用本文的算法構造鄰接矩陣。首先得到僅包含頻率信息的鄰接矩陣,然后在鄰接矩陣中增加兩個活動之間的間隔時間信息與活動在案例中的順序位次,得到含有活動位次信息、頻率信息、時間信息的鄰接矩陣,依據本文的算法進行過程挖掘提取過程模型。
在利用過程模型進行預測時,在同一個狀態下能提供更多預測信息,比僅僅得到一個預測信息時,能起到更好的預測效果,針對上述的專利數據,得到如表10所示的數據。

表10 利用實際數據兩個模型預測結果的比較
根據表10的數據可得如下結論:
(1)概率預測:PMS不能進行概率預測,因為在PMS中不存在頻率信息,所以PMAM進行預測比PMS得到更好的概率預測結果。
(2)時間預測:在49.18%的狀態下PMAM與PMS得到相同的時間預測結果,在40.16%的狀態下PMAM比PMS得到更好的時間預測結果,在10.66%的狀態下,現有PMS比PMAM得到更的好時間預測結果。因此,PMAM比PMS進行時間預測得到更好的時間預測結果。
(3)活動預測:利用過程模型中的路徑判定接下來可能發生的活動,兩個模型得到相同的活動預測效果。
5 結 論
本文將事件日志中蘊含的過程模型進行研究,以期利用過程模型進行預測,通過預測對生產制造和商業流程進行優化。通過事件日志信息中不同類型活動的個數N和2個的虛擬活動(START和END)構建一個(N+2)×(N+2)階的鄰接矩陣(方陣)。然后根據決策者與管理者的需求和模型預測精度,在所構造的鄰接矩陣中增加相應的信息(如:時間間隔、活動位次、緊鄰頻率等)。依據鄰接矩陣中對應位置處有數據信息的兩個活動依據位次的先后順序進行連接,提取相應的過程模型并在相應位置標注對應時間信息,利用該過程模型預測接下來會發生么活動、概率多大、何時發生。
本文通過2個隨機數據案例與1個真實數據案例,將PMAM預測結果同PMS的預測結果進行比較分析。發現當在某個狀態出現分支時,利用PMAM進行時間預測比PMS提供更好的預測值,當在某個狀態幾個分支進行合并時,利用PMS進行時間預測比PMAM提供更好的預測值。利用PMAM比利用PMS能得到更好的概率預測。伴隨著大數據時代數據量的急劇增加,事件日志所包含活動較多時,所構造的鄰接矩陣階數也增加極快,此時得到的預測過程模型將極為復雜,但是利用PMAM進行預測將比利用PMS進行預測減少運算量,縮短運算時間。
本文利用事件日志信息中的活動緊鄰關系構造鄰接矩陣,基于矩陣中所含數據信息提取過程模型進行預測,通過預測對實際操作過程進行優化。將來將利用事件日志中的人員信息,構建在商業交易流程與生產制造過程中所涉及員工之間的社會關系網絡,同時將從時間序列與數理統計的角度出發對時間預測函數及相應算法進行研究。
[1]Van Der A W M P,Schonenberg M H,Song M.Time prediction based on process mining[J].Information Systems,2011,36(2):450- 475.
[2]Huang Z,Kumar A.A study of quality and accuracy trade-offs in process mining[J].INFORMSJournal on Computing,2011,10(3):1- 18.
[3]Van Der A W M P,Van Dongen B F,Herbst J,et al.Workflow mining:a survey of issues and approaches[J].Data and Knowledge Engineering,2003,16(9):1128- 1142.
[4]Dustdar S,Hoffmann T,Van Der A W M P.Mining of Ad-Hoc business process with teamlog[J].Data and Knowledge Engineering,2005,55(2):129- 158.
[5]Van Der A W M P,Van D B F,Gunther C W,et al.Pro M 4.0:comprehensive support for real process analysis[C]∥Proc.of the 28th International Conference on Applications and Theory of Petri Nets,2007:484- 494.
[6]Van Der A W M P,Weijters A J M M,Maruster L.Workflow mining:discovering process models from event logs[J].IEEE Trans. on Knowledge and Data Engineering,2004,16(9):1128- 1142.
[7]Van Der A W M P.Exploring the CSCW spectrum using process mining[J].Advanced Engineering Informatics,2007,21(4):191- 199.
[8]Agrawal R,Gunopulos D,Leymann F.Mining process models from workflow logs[C]∥Proc.of the 6th International Conference on Extending Database Technology,1998:467- 483.
[9]Cook J E,Wolf A L.Discovering models of software processes from event-based data[J].ACM Trans.on Software Engineering and Methodology,1998,7(3):215- 249.
[10]Liu J,Liu P,Liu S F,et al.Handover optimization in business processes via prediction[J].Kybernetes,2013,42(7):1101- 1127.
[11]Weijters A J M M,Van Der A W M P.Rediscovering workflow models from event-based data using little thumb[J].Integrated Computer-Aided Engineering,2003,10(2):151- 162.
[12]Van Der W J M E M,Van D B F,Hurkens C A J,et al.Process discovery using integer linear programming[C]∥Proc. of the 29th International Conference on Applications and Theory of Petri Nets,2008:368- 387.
[13]Tan P N,Steinbach M,Kumar V.Introduction to data mining[M].Boston:Addison Wesley,2006.
[14]Klein M,Bernstein A.Towards high-precision service retrieval[J].IEEE Internet Computing,2004,8(1):30- 36.
[15]Song M,Van Der A W M P.Supporting process mining by showing events at a glance[C]∥Proc.of the 7th Annual Workshop Information and Technology Systems,2007:139- 145.
[16]Mans R S,Schonenberg M H,Song M,et al.Application of process mining in healthcare-a case study in a dutch hospital[J].Communications in Computer and Information Science,2009,25:425- 438.
[17]Yang W S,Hwang S Y.A process-mining framework for the detection of healthcare fraud and abuse[J].Ex pert system with Application,2006,31(1):56- 68.
[18]Schonenberg H,Weber B,Van D B F,et al.Supporting flexible processes from recommendations based on history[C]∥Proc.of the International Conference on Business Process Management,2008:51- 66.
[19]Van D B F,Crooy R A,Van Der A W M P.Cycle time prediction:when will this case finally be finished?[C]∥Proc.of the 16th International Conference on Cooperative Information Systems,2008:319- 336.
[20]Process mining research tools application[EB/OL].[2014- 02-20].http:∥www.processmining.org/prom/downloads.
[21]Wen L,Wang J,Sun J.Detecting implicit dependencies between tasks from event logs[C]∥Proc.of the Aisa-Pacific Web Conference on Frontiers of WWW Research and Development,2006:591- 603.
[22]Van Der W J M E M,Van D B F,Hurkens C A J,et al.Process discovery using integer linear programming[C]∥Proc. of the 29th International Conference on Applications and Theory of Petri Nets,2008:368- 387.
[23]Alves De M A K,Weijters A J M M,Van Der A W M P.Genetic process mining:an experimental evaluation[J].Data Mining and Knowledge Discovery,2007,14(2):245- 304.
[24]Liu J.HCS:study on algorithms and models of decision making problem based on“human-centered service”[D].Nanjing:Nanjing University of Aeronautics and Astronutics,2012.(劉健.基于“人本服務”的決策問題算法與模型研究[D].南京:南京航空航天大學,2012.)
[25]Huang Z,Kumar A.New quality metrics for evaluating process models[C]∥Proc.of the 4th Workshops Business Process Management,2009:52- 57.
[26]The Unite States patent and trademark office an agency of the department of commerce[EB/OL].[2014- 02- 20].http:∥portal.uspto.gov/external/portal/pair.
Future aware prediction model based on process mining
LIU Jian1,LIU Li-zhao2,WANG Jian-jun1,GU Xiao-guang1
(1.School of Economics and Management,Nanjing University of Science and Technology,Nanjing 210094,China;2.School of Computer Science and Technology,Xiamen University of Technology,Xiamen 361024,China)
Viewing the process model in event logs as the combination of the two adjacent activities,two novel process models are proposed.First,the process model is extracted by constructing adjacency matrix,taking advantage of the adjacency relationships of activities in the event logs.To improve the prediction accuracy of the model,loops are avoided in the process model.So,each activity in this model will only happen once.Second,the serial number of activities in the event logs to the adjacency matrix is added,constructing a new adjacency matrix with sequence information.Based on the new adjacency matrix,the process model is extracted.Each activity in this model will only happen once at the same sequence position.Third,with the adjacency matrix,the path from each prior node to next nodes in the process model and their corresponding probabilities are gotten.Then,according to the type and characteristic information of the event logs,predictions of the information are made which are needed by decision-makers,e.g.activity name,waiting time,and probability based on process model.Finally,the effectiveness of the proposed models by comparing the prediction results of random data and real data based on process models is verified.
adjacency matrix;process mining(PROM);prediction;business intelligence
C 931
A
10.3969/j.issn.1001-506X.2015.04.35
劉 健(1982 ),男,講師,博士,主要研究方向為過程挖掘、決策分析。E-mail:jianlau@njust.edu.cn
劉利釗(1983-),男,副教授,博士,主要研究方向為云計算、數據挖掘。E-mail:kollzok@yahoo.com.cn
汪建均(1977-),男,副教授,博士,主要研究方向為供應鏈質量管理、數據挖掘。E-mail:wangjj0818@163.com
顧曉光(1986-),男,博士研究生,主要研究方向為質量控制技術、質量管理。E-mail:guxiaoguang@hotmail.com
1001-506X(2015)04-0949-09
2014- 02- 21;
2014- 10- 31;網絡優先出版日期:2014- 11- 19。
網絡優先出版地址:http://w ww.cnki.net/kcms/detail/11.2422.TN.20141119.2156.003.html
國家自然科學基金(71301075,71371099);中央高校基本科研業務費資助項目(30920130132014);中國博士后科學基金(2013M530261,2013M531366,2014T70527);江蘇省自然科學基金(青年)(BK20130770);江蘇省博士后科研資助計劃(1301108C);南京理工大學經濟管理學院青年教師科研項目(JGQN1401);南京理工大學紫金之星科研項目資助課題
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
中等數學(2022年2期)2022-06-05 07:10:50
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
海峽姐妹(2018年3期)2018-05-09 08:20:40
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
