區域公路網結構性能的模糊聚類分析
2015-05-09 03:48:00鄭貴省李月明車亞輝
軍事交通學院學報 2015年10期
王 元,鄭貴省,王 鵬,李月明,車亞輝
(1.軍事交通學院 研究生管理大隊,天津300161;2.軍事交通學院基礎部,天津300161)
目前,我國公路交通建設取得了巨大的成就,基本形成了以高速公路為骨架、國省道干線公路為主體、縣鄉村公路為基礎的公路交通網絡[1]。隨著我國交通的不斷完善,對公路網的規劃、建設和管理需要建立一套科學合理的評價體系。其中,公路網的結構性能評價是公路網評價體系中必不可少的重要組成部分[2]。公路網的結構性能如何,具有模糊性和不確定性,其具有多個評價指標,如密度、連通度、網路覆蓋形態等。不同的區域由于社會經濟發展水平的不同,公路網的結構性能也各不相同。對此,可以采用模糊聚類的理論,針對收集的不同區域的路網性能指標數據進行模糊C-聚類分析,即可得到不同區域的路網結構性能的分類。對公路網的聚類分析可以揭示公路網不同的發展水平,為整個公路網的規劃建設服務。
1 模糊聚類理論與方法
聚類是一種重要的人類行為,通過適當聚類,事物才便于研究,事物的內部規律才可能為人類所掌握。聚類是指按照事物的某些屬性,把事物聚集成類,使類間的相似性盡量小,類內的相似性盡量大,按照相似程度的大小,將事物逐一歸類。經典的聚類算法將每一個辨識對象嚴格劃分為某一類。但是,實際上某些對象并不具有嚴格的屬性,它們可能位于兩類或多類之間,采用模糊聚類可獲得更好效果。模糊聚類分析的思想首先由Zadeh L A[3-4]于 1965 年提出。1973 年,Dunn 提出模糊C-均值聚類算法。1981年,Bezdek J C[5]對其進行改進并推廣到實際應用中。目前,有關模糊聚類的許多成果都是對聚類算法進行的推廣和改進,該算法已被廣泛應用于多種領域。模糊聚類分析是根據事物特性指標的模糊性,應用模糊數學方法確定樣本的親疏程度而實現的分類方法,可分為兩大類:基于模糊等價關系與模糊相似矩陣的動態聚類算法和基于模糊劃分的動態聚類方法。
1.1 基于模糊等價矩陣與模糊相似矩陣的動態聚類算法
(1)建立模糊相似矩陣。設U是需要被分類對象的全體,建立U上的相似系數R,R(i,j)表示i與j之間的相似程度,當U為有限集時,R是一個矩陣,稱為相似系數矩陣。定義相似系數矩陣的工作,可以按系統聚類分析中的相似系數確定方法,也可以用主觀評定或集體打分的辦法。
(2)建立等價矩陣。用上述方法建立的相似關系R,一般只滿足反射性和對稱性,不滿足傳遞性,因而還不是模糊等價關系。為此,可用求傳遞閉包的方法,將R改造成R*,在適當的閾值上進行截取,便可得到所需要的分類。R自乘的思想是按最短距離法原則,尋求xi與xj的親密程度。即先將R自乘改造為R2,再自乘得R4,如此繼續下去,直到某一步出現R2k=Rk=R*。此時R*滿足傳遞性,于是模糊相似矩陣R就被改造成一個模糊等價關系矩陣R*。
(3)模糊聚類。有了等價關系的R*后,給定不同置信水平的λ,求R陣,rij>λ的元素變為1,否則變為0,從而達到分類目的。隨λ值的降低,由細到粗逐漸歸并,最后得到動態聚類譜系圖。
從以上的方法中可以看出:在建立相似系數矩陣時,指標權重是人為給定的,顯然,計算結果不可避免地受到主觀因素的影響;同時,在建立等價關系矩陣時,采用布爾矩陣相乘過程中,需要不斷地檢驗它是否已經是等價關系矩陣;再則,對于不同置信水平λ的選擇上也存在著多大為合適的問題。
1.2 基于模糊劃分的動態聚類方法
模糊C-均值聚類(fuzzy c-means algorithm,FCMA)用隸屬度表示每個樣本屬于某個聚類的程度。FCMA把n個 xi(i=1,2,…,n)分為 c個模糊組,并求每組的聚類中心,使得目標函數達到最小。
xi(i=1,2,…,n)是 n個樣本組成的樣本集合,c為預定的類別數目,mj(j=1,2,…,c)為每個聚類的中心,uj(xi)為第i個樣本對于第j類隸屬度函數。
設目標函數為
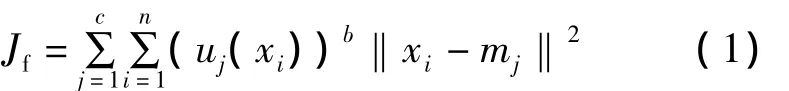
式中:Jf為目標函數;b為一個可以控制聚類結果的模糊程度的常數,b越大,分類越模糊,實踐證明,b應大于1,但一般不超過2,否則將引起分類失真。其中
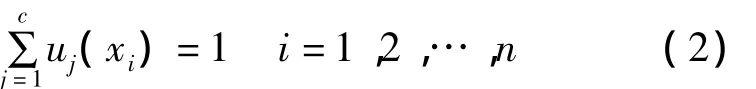
在式(2)下求式(1)的極小值,令Jf對mj和uj(xi)的偏導數為0,可得必要條件:
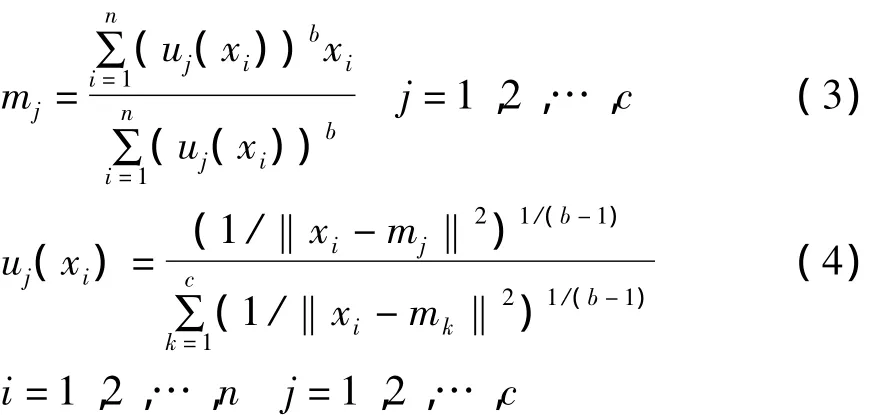
FCMA迭代過程為:①設定初始聚類數目c及參數b,目標函數迭代精度ε;②初始化各個聚類中心mj(j=1,2,…,c);③根據式(4)計算隸屬函數矩陣;④根據式(1)計算目標函數,Jf<ε,則算法停止,否則,返回步驟③。
模糊C-均值聚類是較成熟的技術,這是一種尋找最佳劃分矩陣的方法,這種方法可以根據樣本的特性進行合理分類。
2 實例分析
2.1 公路網結構性能評價指標及實例數據
公路網的結構性能評價就是對相關的各項指標進行定量、定性分析,揭示現狀公路網存在的問題,為規劃近、遠期公路網服務。評價的首要工作是選擇評價指標,評價結果的準確與否不僅取決于指標選擇的科學性,也取決于指標量化的科學性。經過分析比較,本文選取的指標主要有以下6個。
(1)公路網理想接近規模。公路網理想規模接近度是實際公路網里程接近于理論所需公路里程的程度,反映的是公路網與國民經濟發展、人口規模的適應程度。
(2)當量綜合密度。當量綜合密度定義為將區域中各等級公路的里程依據通行能力折算成標準等級(二級)公路的總里程與區域國土面積、人口、經濟指標乘積的立方根的比值,能夠較客觀地反映公路網的真實規模[6]。
(3)公路網等級水平。公路網等級水平定義為路網中各等級公路里程的加權平均值,反映公路網的等級水平。
(4)連通度。連通度反映的是網絡交通節點(公路交叉口或城鎮交通樞紐)的連通狀況,從路網布局方面反映公路網的結構特點,其定義為規劃區域內各節點間依靠公路交通相互連通的強度。
(5)公路網平均車速。公路網平均車速是由公路交通中的公路系統、車輛系統和管理系統綜合作用的結果,它綜合反映了路網的系統性能。
(6)公路網擁擠度。公路網擁擠度是用來表示公路擁擠或利用程度的指標,公路網擁擠度就是反映整個路網適應負荷的能力,即與交通需求的適應情況。
本文以2005年北京市各區縣公路網的結構性能指標數據為實例數據(見表1)進行分析。
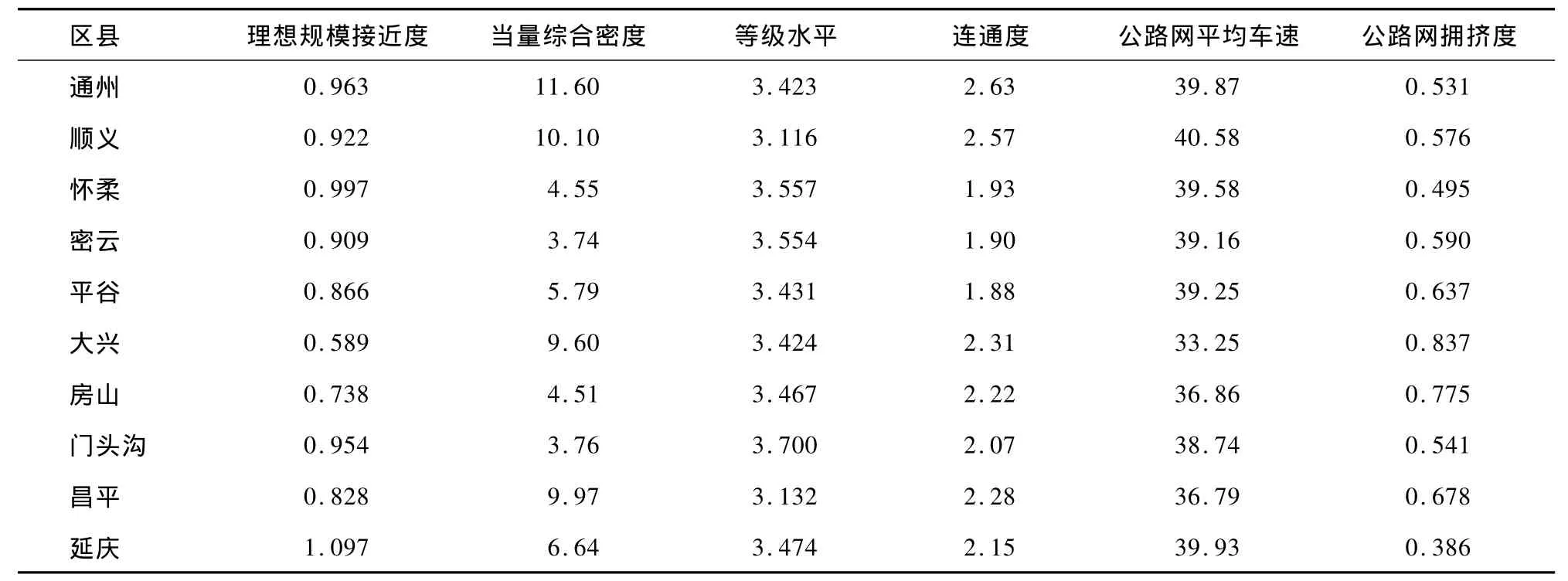
表1 北京市路網結構性能評價指標
2.2 數據預處理
根據模糊聚類的要求,為了消除不同量綱對數據的影響,必須對樣本進行數據預處理[7]。本文采用平移―標準差處理樣本數據:
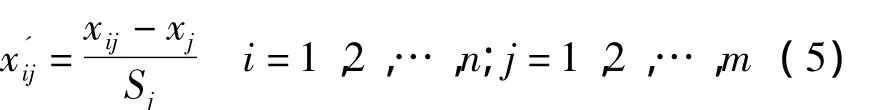
對數據進行歸一化處理:
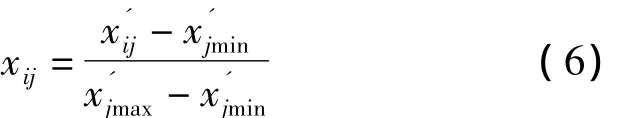
使用Matlab編程歸一化處理后的數據如下:
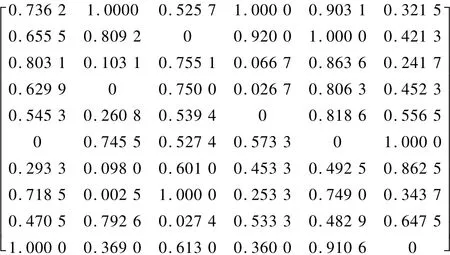
2.3 聚類結果
設定初始聚類中心數目為3,隸屬度矩陣的指數為2,隸屬度最小變化量為10-5,按模糊C-均值聚類的運算結果如下。
聚類中心:

分類矩陣:

由分類矩陣可知,樣本分 3類:{x1,x2,x9}、{x3,x4,x5,x8,x10}、{x6,x7}。即根據 2005 年北京市各區公路網結構性能指標數據,將北京市各區路網性能分為3類,分別是:{通州,順義,昌平}、{懷柔,密云,平谷,門頭溝,延慶}、{大興,房山}。
3 結語
采用模糊C-均值聚類的方法,對區域公路網的結構性能做了評價和分類,最后以北京市為例進行了實例分析。結果說明,通過聚類分析可以科學、有效地區分和橫向比較各區域公路網結構性能的發展水平,為下一步公路網的規劃建設、管理和促進公路交通網絡的平衡發展提供科學合理的參考依據。
[1] 沈鴻飛.面向風險評估與應急管理的公路網結構性質評價與分析方法[D].北京:北京交通大學,2012:1.
[2] 朱強.基于GIS的公路網綜合評價技術研究[D].鄭州:鄭州大學,2005:7.
[3] Zadeh L A.Fuzzy sets[J].Information and Control,1965,8(3):338-353.
[4] Zadeh L A.Fuzzy algorithms[J].Information and Control,1968,12(2):94-102.
[5] Bezdek J C.Pattern Recognition with Fuzzy Objective Function Algorithms[M].New York:Plenum Press,1981:11.
[6] 張志清,金光浩,范懷玉.公路網現狀適應性評價[J].公路,2007(7):167-168.
[7] 賈繼德,孔凡讓.發動機連桿軸承故障噪聲診斷研究[J].農業機械學報,2005(6):89-90.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
哲學評論(2021年2期)2021-08-22 01:53:34
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華詩詞(2019年7期)2019-11-25 01:43:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
現代企業(2015年9期)2015-02-28 18:56:50
