圖像并行集群復原校正方法研究
2015-04-30 06:58:12華夏等
軟件導刊 2015年4期
關鍵詞:圖像復原
華夏等
摘要摘要:論述了圖像校正算法的并行集群實現方法。針對圖像復原問題,對復原算法結構與流程的并行處理進行研究,提出了整體數據傳輸、按行分片計算復原的并行處理方法。該方法在基于MPI的計算機并行集群系統中的8個計算節點上通過了測試,給出了集群校正實驗結果和MPI并行計算時空圖。實驗結果表明,基于集群計算的并行復原方法十分有效,可縮短計算時間,提高計算效率。
關鍵詞關鍵詞:圖像復原;并行處理;MPI;集群計算
DOIDOI:10.11907/rjdk.151061
中圖分類號:TP317.4
文獻標識碼:A文章編號
文章編號:16727800(2015)004014203
0引言
退化圖像的快速復原是成像探測研究的重要課題。傳統的復原方法是在目標圖像點擴展函數確定的情況下,用去卷積的方法來實現圖像復原。然而,在復雜條件下,點擴展函數很難測定與預先獲得[1]。基于極大似然估計準則的正則化圖像復原算法利用序列多幀退化圖像數據,采用極大似然估計方法來尋找最相似于退化圖像的點擴展函數和目標圖像,從概率意義上達到極大程度恢復圖像的目的[2,3]。由于該復原算法采用迭代的方式,因此計算量大,計算速度較慢。為了縮短計算時間,加快計算速度,人們對算法的結構優化和計算方法進行了研究[4],但要將計算負擔降低一半以上仍存在困難。因此,對該算法采用高性能并行化處理值得深入研究。
高性能計算技術在國內外受到高度重視,其在科學研究、工程技術以及軍事技術方面的應用已取得了巨大成果。目前,利用相對廉價的微機和高速網絡構建高性能的并行與分布式集群計算系統來完成高性能計算任務已越來越普遍[5]。集群計算在圖像校正方面有著廣闊的應用前景。建立算法并行模型的問題即是解決算法如何并行的問題,如何把單機運行的圖像處理算法改造成在并行集群上運行的算法。并行計算的目的是充分利用計算集群系統資源,縮短計算時間,提高計算效率。并行計算的實現方法是將一個大計算量的計算任務分解成多個子任務,分配給各個節點進行并行計算。由于計算上的內在關聯性,計算節點之間必須進行數據交換,然而圖像復原校正處理中圖像的數據量通常較大,所以并行計算不可避免地會引入額外的節點間的通信時間。額外的通信時間過大,將降低并行計算的運行效率。如果通信時間大于算法并行計算節省的計算時間,并行集群計算系統運行速度將低于一臺計算機的運行速度,并行計算則失去了意義。因此,建立算法的并行模型,需要確定算法哪一部分運算需要進行并行計算,哪一部分不并行,如何并行處理直接決定著并行計算的運行效率。
建立算法并行模型過程分為3步:①對算法模型與流程進行分析,找出算法中運算量最大的幾個計算量或步驟,也即需要并行計算的部分;②對需要并行計算的計算量進行分析,找出并行實現的方法;③分析并行計算的可行性,如果計算耗時遠大于并行計算需要的額外通信耗時,并行計算則是高效和可行的;如果計算耗時小于額外通信耗時,或者與通信耗時相當,并行計算則是低效的。
MPI(Message Passing Interface)是目前比較流行的并行計算開發環境之一。MPI是一個并行計算消息傳遞接口標準,其現已成為被產業界廣泛支持的并行計算標準,具有可移植性,因此選擇MPI來構建并行校正計算系統。
1基于空間域按行分片的并行計算處理方法
流場點擴展函數具有衰減性質,有意義的支撐區域(其值大于零)集中在峰值附近[6]。點擴展函數的支撐區域一般比圖像的支撐區域小得多。因此,對點擴展函數而言,只需要估計點擴展函數空間支撐域范圍內的有效值。
由復原校正算法可知,若圖像大小為N×N,點擴展函數支撐域為M×M,則在每次迭代中,計算點擴展函數和目標圖像的加法和乘法運算量正比于N2M2,在圖像空間域進行計算時,計算工作量較大,圖像恢復較慢。為了縮短計算時間,加快計算速度,有必要對基于EM計算的最大似然估計復原校正算法(簡稱EM算法)進行并行化處理。
從算法流程可知,EM算法是一個多次迭代過程,每一次迭代過程都包含多個計算步驟。因此沒有必要把每一個計算步驟都并行化,因為并不是每個計算步驟都需要并行化,對計算量過小的計算步驟并行化,引入的通信時間會大于并行計算節省的計算時間,反而會降低算法運行速度。所以,只需選取計算量較大的計算步驟進行并行化,計算量小的部分在根節點上單機計算,在實現并行計算的同時達到減少節點間通信量的目的。
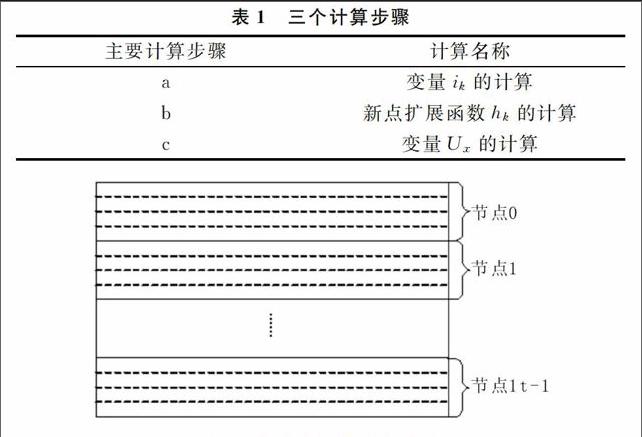
對單機上運行的串行EM算法每一次迭代過程中的各個步驟計算時間進行了記錄。從單機運行的時間結果來看,一次迭代過程中a、b、c三個計算步驟(見表1)用時占一次迭代計算總時間的99%以上,只要把這三個計算步驟進行并行化,則可以大大降低計算耗時。其它幾個步驟計算量較低,沒必要分配到各節點進行并行計算,否則節點間的數據通信和計算同步需要的時間可能會大于3ms,反而降低計算速度。所以,現將a、b、c三個計算步驟分配到各個節點上進行并行計算,其它步驟在根節點(進程號為0的節點)上用單機計算。
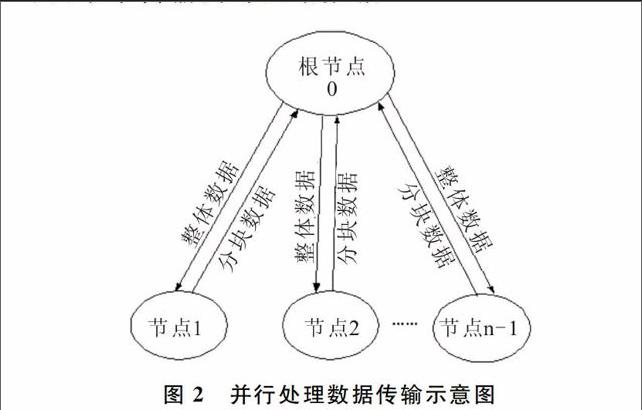
并行計算即把計算任務分配到各個計算節點上,a、b、c三個計算步驟需并行處理的計算值ik、hk及Ux,均可看成具有M行和N列的二維圖像(見圖1)。由于每一塊的計算涉及到整體圖像數據,所以提出整體數據傳輸、分塊計算復原的并行處理方法:即將整個圖像數據傳輸到每一個計算節點上,在每一個節點上計算每一塊的數據值,然后傳回到根節點上,再整體傳輸到各節點上進行分塊計算,直至計算結束為止。采用的分配方法是細粒度任務劃分方法,把圖像分成若干個子塊圖像并按行存放,為便于分片并行計算處理,按行對圖像進行分配計算。把整個圖像根據并行計算節點數量按行平均分為n個子塊圖像,計算任務分配如圖1所示。按行分片,每個子塊圖像的計算在同一個計算節點上進行,不同子塊圖像計算在不同計算節點上進行。具體方法如圖2所示。
2基于MPI環境的并行計算與實現
利用內部局域網把各臺獨立的計算機連接起來組成一個并行計算集群。集群系統采用并行計算方法,把圖像處理中計算量大的計算任務分解成各個子任務,然后分配給各個節點進行并行計算。由于計算上的內在關聯性,節點之間必然存在數據交換,而由于圖像的數據量相當大,內部網絡傳輸數據的速率是整個系統計算速度的瓶頸。盡量高的傳輸帶寬和盡量低的傳輸延時 (Latency)是圖像處理集群系統高并行效率的基本要求[7]。因此,采用千兆光纖網絡來傳輸內部網絡數據。
MPI并行計算進程必須由mpirun命令啟動[7],mpirun命令只支持以命令提示符的方式啟動并行計算進程。因此,無法在軟件的主界面中調用MPI函數,只能通過命令行調用mpirun命令啟動并行計算進程。主程序和MPI并行計算程序是兩個獨立的進程,各個進程的存儲區獨立,進程與進程之間不能直接傳遞數據。并行計算輸入參數和輸入圖像的傳遞利用共享內存映射方法實現。建立共享內存映射即建立一段共享內存,該內存不屬于某個進程獨有,每個進程都可以通過這段內存的名字來訪問它。在MFC中CreateFileMapping函數可用來建立一段內存映射。主進程創建了共享內存以后,MPI進程和主進程都可以使用這段內存空間,主進程首先把并行計算需要的參數和輸入圖像都拷貝到共享內存空間,然后啟動MPI進程進行并行計算,MPI進程計算完畢后仍然把計算結果圖像拷貝到這段共享內存,主程序讀取共享內存后將其釋放。通過這個過程完成了算法的MPI并行計算。
Windows提供了程序調用命令,可以在一個進程中創建另一個進程。程序調用命令為:int system( const char *command ),其中command即為要調用的程序及參數。在軟件系統中編制程序代碼啟動MPI命令,調用并行計算命令,啟動并行程序。EM算法的MPI并行程序名稱設為EMRec_MPI.exe,該文件和應用程序存放在一個目錄下,用GetModuleFileName命令獲得當前應用程序所在路徑,即可得到并行程序所在路徑。在mpirun命令中,使用了-np與-localroot參數。變量nodeNum指定參與并行計算節點的數目,該變量由用戶通過校正軟件人機交互界面設置。現使用默認節點設置,參與計算的節點在圖像校正軟件系統啟動之前配置完成。
圖像復原軟件系統主程序進程和圖像恢復并行計算程序進程是兩個獨立的進程,各個進程的存儲區獨立,進程和進程之間不能直接通過變量或內存地址的方式傳遞數據。用共享內存文件映射的方法實現主進程和并行計算進程間的數據傳遞。共享內存文件由某一個進程創建,該文件映射對象的內容能夠為多個其它進程所映射,這些進程共享的是物理存儲器的同一個頁面。因此,當一個進程將數據寫入此共享文件映射對象的內容時,其它進程可以立即獲取數據變更情況。
首先,主進程通過CreateFileMapping()函數創建一個內存映射文件對象,并把該文件對象命名為EM_rec_mem,在并行計算進程中,即可通過這個名字找到該內存文件。如果創建成功,則通過MapViewOfFile()函數將此文件映射對象的視圖映射到地址空間,同時得到此映射視圖的首地址。首先,計算需要創建的內存文件大小。其中40個為頭信息,并保存算法的輸入參數等信息。內存文件創建成功以后,把輸入數據,包括圖像恢復參數、輸入圖像幀數,擴展函數行、列數,迭代次數、多幀輸入圖像數據等,寫入共享文件內存。完成了初始化工作,即可調用并行計算程序。并行計算進程由mpirun命令啟動以后,首先用CreateFileMapping()函數創建一個名稱為EM_rec_mem的內存文件,然后獲得輸入數據,并把輸入數據用MPI_Bcast的方法廣播到各個計算節點上的進程,開始并行計算。并行計算完成后把處理結果寫入共享內存文件,完成算法的MPI并行計算。
3實驗結果與分析
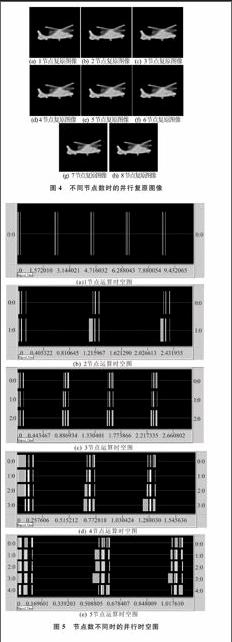
實驗以空間域按行分片復原算法為基礎,引入并行計算,用VC6.0編程進行實現。將并行系統校正方法在計算機并行集群系統(微機主要配置均為CPU Intel Pentium IV,2.66 GHz,1024 MB內存)上運行。以紅外直升機目標圖像的并行集群校正為例,下面給出在該并行集群系統運行通過的兩個并行校正實驗結果。3幀退化圖像如圖3所示,為便于對比,分別采用1~8個節點進行并行復原校正,其中迭代次數均為80次。不同節點復原圖像如圖4所示,當節點數設置不同時,由從輸入相同的模糊圖像中復原出來的結果圖像相同,說明各個節點并不改變算法參數和圖像數據,只參與并行計算,以提高計算效率。不同節點數耗費時間對比見表2。由表2可知,隨著節點數增加,計算耗時幾乎成比例地減少,這是由于各個節點平均分擔了計算任務。不同節點數并行運算的時空圖如圖5所示,其中橫向細實線寬度表示計算所用時間,橫向塊寬度表示數據傳輸及廣播所用時間。分析時空圖可知,節點之間數據通信所耗費的時間相對于整個計算時間較短。但隨著節點數目增加,通信量增多,數據通信耗費時間增加。因此,節點數并不是越多越好,當節點數目達到一定數量(8節點)時,復原算法耗費時間將達到穩定。
4結語
針對圖像校正算法迭代次數多、耗時長等問題,為提高計算效率,本文引入了并行集群計算。對復原校正算法的結構與流程進行了研究,提出了整體數據傳輸、按行分片計算復原的并行處理方法,有效解決了校正算法的并行集群處理問題。并行集群實驗計算結果表明,本文提出的并行方法十分有效,可縮短計算時間,提高計算效率。通過研究了解圖像處理算法MPI并行化方法,實現了基于MPI的并行計算集群,解決了MPI并行程序與Windows窗口的集成連接問題,建立了一個并行計算圖像校正軟件平臺。由此證實MPI并行計算在氣動光學效應圖像校正處理中具有實用價值。
參考文獻參考文獻:
[1]張天序,洪漢玉,張新宇.氣動光學效應校正[M].合肥:中國科學技術大學出版社,2013.
[2]洪漢玉,張天序,余國亮.航天湍流退化圖像的極大似然估計規整化復原算法[J].紅外與毫米波學報,2005,24(2):130134.
[3]洪漢玉,張天序,余國亮.基于Poisson模型的湍流退化圖像多幀迭代復原算法[J].宇航學報,2004,25(6):649654.
[4]洪漢玉,王進,張天序,等.紅外目標圖像循環迭代復原算法的加速技術研究[J].紅外與毫米波學報,2008,27(1):433436.
[5]都志輝.高性能計算之并行編程技術—MPI并行程序設計[M].北京:清華大學出版社,2001.
[6]J G NAGY,R J PLEMMONS,T C TORGERSEN.Iterative image RESToration using approximate inverse preconditioning[J].IEEE Trans.on Image Processing,1996,5(7):11511162
[7]呂捷.并行與分布式圖像處理系統的實現與應用[D].武漢:華中科技大學,2004.
責任編輯(責任編輯:黃健)
猜你喜歡
農業工程學報(2022年14期)2022-10-19 02:34:26
石家莊鐵路職業技術學院學報(2019年3期)2019-10-30 03:26:32
大科技·C版(2019年1期)2019-09-10 14:45:17
數碼世界(2017年12期)2017-12-28 15:45:13
蘇州科技大學學報(自然科學版)(2017年1期)2017-03-20 15:25:20
科技資訊(2016年27期)2017-03-01 18:23:16
光學精密工程(2016年2期)2016-11-07 09:02:28
航天返回與遙感(2014年4期)2014-07-31 17:47:47
長江大學學報(自科版)(2014年7期)2014-03-20 13:21:02
電子設計工程(2014年18期)2014-02-27 12:00:32
