基于統計專用字符的維、哈、柯文文種識別研究
2015-04-21 09:44:34買買提依明哈斯木吾守爾斯拉木維尼拉木沙江努爾麥麥提尤魯瓦斯
中文信息學報 2015年2期
買買提依明·哈斯木,吾守爾·斯拉木,維尼拉·木沙江,努爾麥麥提·尤魯瓦斯
(1. 新疆大學 信息科學與工程學院,新疆多語種重點實驗室,新疆 烏魯木齊 830046;2. 和田師范專科學校,計算機科學系,新疆 和田 848000)
?
基于統計專用字符的維、哈、柯文文種識別研究
買買提依明·哈斯木1,2,吾守爾·斯拉木1,維尼拉·木沙江1,努爾麥麥提·尤魯瓦斯1
(1. 新疆大學 信息科學與工程學院,新疆多語種重點實驗室,新疆 烏魯木齊 830046;2. 和田師范專科學校,計算機科學系,新疆 和田 848000)
在Unicode編碼方案中維、哈、柯文字符安排在阿拉伯字符區域,三種語言中共享字符比較多,跟阿拉伯字符區域混在一起,沒有專用的語言ID。在信息檢索和自然語言處理領域對維、哈、柯文的識別、處理帶來不便。該文首先分析并總結了維、哈、柯文三種語言中的專用字符、復合字符、某些字符在某種語言中出現形勢的獨特性等特征,然后在此基礎上設計了維、哈、柯文種識別算法。 實驗結果表明該文提出的文種識別算法的正確率在文本多于70詞時達到96.67%以上。
文種識別;專用字符;復合字符;維文;哈文;柯文;Unicode
1 引言
維吾爾語、哈薩克語、柯爾克孜語(下文簡稱維、哈、柯語)屬于阿爾泰語系突厥語族。雖然有Uyghur、Kazakh、Kyrgyz不同語言之分,但其字模,字符串構成方式,語序以及句法和語法規則大體相通。另外,三種語言對應字符串的Unicode編碼不僅內容上大體相同,而且在表現形式上(斜體字部分)也較接近。在字母表中的大部分字母完全相同并非常相近阿拉伯語[1-2],所以在Unicode編碼方案中維、哈、柯文字符安排在阿拉伯字符區域(0600~06FF),跟阿拉伯字符區域混在一起,該區域中維、哈、柯共用一些字母,而且沒有語言ID。該區域中字母的順序符合阿拉伯字母表,維、哈、柯文字母的順序非常混亂[3],所以在信息交換和自動識別應用中很難區分維、哈、柯文,且存在語言上的二義性。
近年來隨著互聯網技術的發展,維、哈、柯文網站越來越多。如何按文種分類、整理維、哈、柯文互聯網信息資源是在維、哈、柯文信息檢索、輿情分析、在線機器翻譯中,首先需要解決的問題。專用字母識別是一種常用的文種識別技術。本論文研究通過統計維、哈、柯文三種語言各自獨有的專用字符、復合字符和有些字符在某種語言中出現形式的獨特性等特征來對維、哈、柯文進行文種識別。
2 相關技術
文種識別技術是在信息檢索和在線機器翻譯領域使用的基礎技術之一,用來判斷某一個文本是由哪種語言來描述的[4-5]。文種識別技術中用各種各樣的特征來對文本進行分析。它們包括專用字符、獨有詞集合和獨有N元字符序列等,分別有各自的優缺點[6]。基于統計專用字符的文種識別技術是最簡單的文種識別方法,對于大規模的文本文種識別性能非常好,但是對于處理小規模的文本(包含一個句子)性能較差[7]。基于統計獨有詞集合的文種識別技術中選用獨有詞集合進行識別時,首先為每一個語種建立獨有詞庫,并統計每一個語言中獨有詞的出現頻率,這項工作較難實現[5,7]。這種方法不適合用于像英、維、哈、柯等粘性語言,因為這種語言中單詞的前后加上前綴或后綴來表示不同的語法現象,形態變化活躍。統計單詞的出現頻率必須要進行分詞、詞法分析和詞干提取等預處理操作[6,8]。沒有指定文種之前無法對文本進行以上預處理操作。而且大多數語言的詞法分析和詞干提取技術不公開,不容易實現。所以這種文種識別方案難度高,不可取。另一種文種識別方法是由Canver和Trencke提出的基于N元模型的文種識別方法,該方法的思想是根據每種語言中出現頻率組多的N元字符(連續字符序列)進行文種識別[8]。
在維、哈、柯文文種識別技術方面維尼拉·木沙江、吐爾地·托合提等人提出了基于靜態重定位的維、哈、柯文Unicode編碼方案,在該方案中,維、哈、柯文字母根據各自的字母表排序在三個不同的區域(仍然在0600~06FF),自動獲取各自的語言表示信息,消除了語言上的二義性[3]。買爾旦·吾守爾用“維吾爾語-漢語”、“哈薩克語-漢語”和“柯爾克孜文-漢語”詞庫,分別統計以上詞庫中的維、哈、柯文專用字母和復合字母的出現頻率,采用統計學知識、理論和方法,使得三種語言之間的文種識別率達到58.18%[9]。薛亞平也提出了采用維、哈、柯文特有字母的字母和特殊的字母組合進行文種識別的算法。在該算法中,如果該文件中只出現了維文特有的字母或字母組合,則可以判定該文為維文文件。同樣方法也可以判斷哈文文件。如果兩種語言的特殊字母或字母組合均有出現,則可以判斷為維、哈文的混排文件[10]。但該工作沒有給出詳細的統計實驗數據。倪耀群、曹鵬等人使用N元語法模型實現了維吾爾文的快速語種判別,準確率超過98%[11]。
3 基于統計字符的維、哈、柯文文種識別系統的設計
3.1 維、哈、柯文Unicode字符介紹 Unicode字符編碼是一種使用16bits(兩個字節)唯一表示一個字符、一共能夠表示65 536個字符的國際標準[11]。其中阿拉伯字母所有文字字符(包括維、哈、柯文)都集中在阿拉伯字母區域(0600~06FF),但是該區域中維、哈、柯文字符分布是不連續的,沒有分配語言ID,共用一些代碼位。0600~06FF范圍包括,在“中華人民共和國國家標準(GB 21669-2008)信息技術維吾爾文,哈薩克文,柯爾克孜文編碼字符集”中有制定的維、哈、柯文字母的42個名義字符形式和160個位于Arabic Presentation Forms的變形顯現形式[12]。而以上42個名義字符代碼位的大部分被三種語言共用。如表1~7中列出了三種語言中共用和獨用字符[6]。

表1 維、哈、柯文共用字符名義形式及編碼

表2 維吾爾文復合字符名義形式及編碼

表3 哈、柯文共用名義字符及編碼

表4 維吾爾文專用名義字符及編碼

表5 維、哈文共用名義字符及編碼

表6 哈薩克文專用名義字符及編碼

表7 柯爾克孜文專用名義字符及編碼
3.2 維文字符獨特特征分析
維吾爾語中一共有32個字母,其中有8個元音字母和24個輔音字母。維文與哈文和柯文相比有以下三個特點。
a) 維文元音字符的特點。有些元音字符的獨立形式、尾字符和首字形式由相應的元音字符前加“”(編碼為0626,HAMZA ABOVE)來實現,如表8中的帶下劃線的字符,在哈、柯文中不會出現這種形式的字符組合。
c) 表4中的三個輔音字母是維文專用字符。
根據維文的以上三個特征,通過統計維吾爾文專用字符和復合字符,能夠識別維吾爾文。

表8 維文復合字符名義形式和變形顯現形式及編碼
3.3 哈文字符獨特特征分析
哈薩克語中一共有33個字母,其中有9個元音和24個輔音字母。目前哈薩克文網頁上的字符有如下特點。
a) 理論上,根據表6中的哈薩克文專用字符可以識別出哈薩克文,但統計500篇哈薩克文網頁正文中出現的哈文字符,只出現了28個哈文字符,幾乎沒出現表9中的帶下劃線的四個元音字母,也沒出現哈文元音前置符“”(HIGH HAMZA, 編碼為
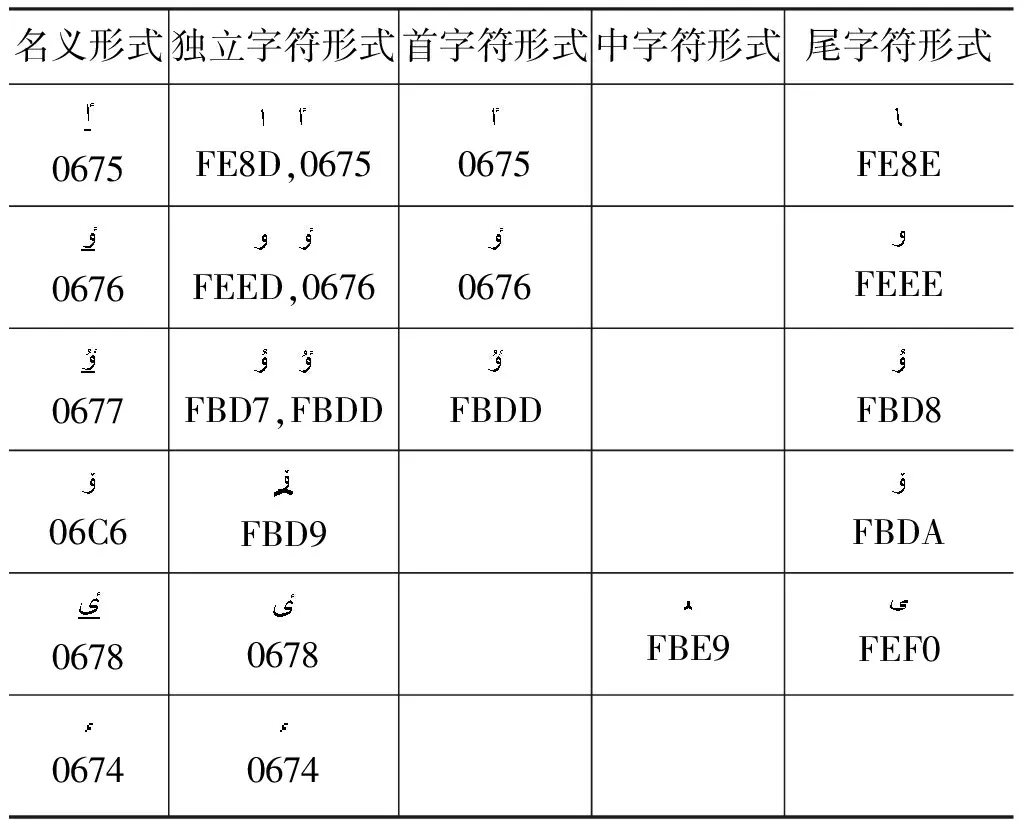
表9 哈文專用名義字符形式和變形顯現形式及編碼

表10 哈文錯誤字符編碼統計結果


3.4 柯文字符獨特特征分析
柯爾克孜語中一共有30個字母,其中有8個元音字母,22個輔音字母。柯文專用字符有如下特點。
a) 編碼為06C5和06C9及它們的變形顯現形式是柯文專用的,如表11所示。
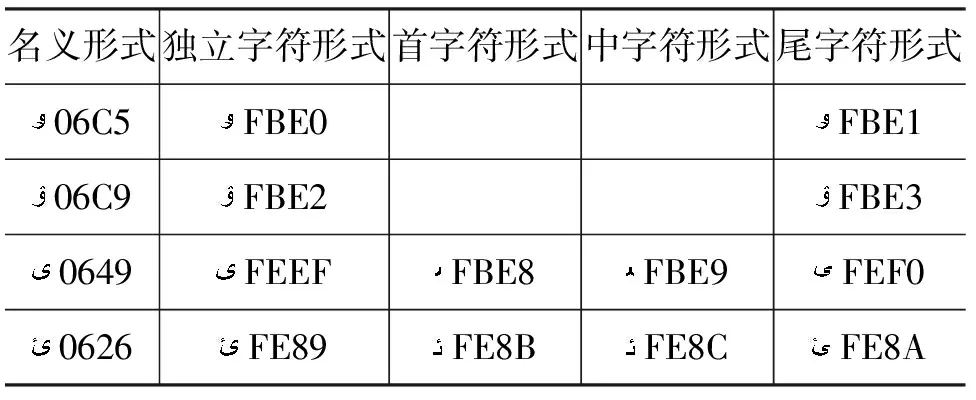
表11 柯文專用名義字符形式和變形顯現形式及編碼
b) 編碼為0649的字母和它的變形顯現形式在維文和哈文中都出現,所以從字符編碼角度上不能作為專用字符,如表8和10所示。
c) 編碼為0626(HAMZA ABOVE)的字母在維文中也出現,但出現時后面連接的字符必須是元音字符,如表8所示。在柯文中出現該字符的首字符形式和中字符形式時后面連接的是輔音字符,它的尾字符形式、獨立字符形式是柯文專用的。在維文中詞的最后不出現編碼為0626的字符,也不以獨立字符形式出現,后面必須要連接維吾爾元音字符。
d) 柯文中有同一個元音字符形式前后出現的現象,而在維文和哈文中的外來語中也會出現,主要出現在外來語中,但出現頻率很低。柯文中的特殊元音字母組合如表12所示。
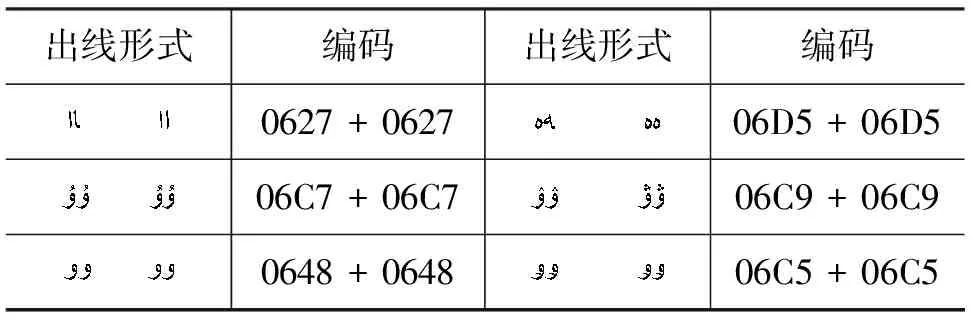
表12 柯文中的特殊元音字母組合
根據以上柯文的四個特征,通過統計柯文字符的獨特特征,能夠識別柯文。
3.5 基于統計字符獨特特征的維、哈、柯文文種識別算法的設計 按照上述分析的維、哈、柯文專用字符、復合字符以及有些字符在某種語言中出現形式的獨特性,本文設計了維、哈、柯文文種識別算法。該算法的思路是首先分別統計文本中出現的屬于維、哈、柯三種語言的專用字符、復合字符、某種語言中出現的獨特的字符形式,然后判斷屬于哪種語言統計值最高,統計值最高的語種被判斷為該文本文種。因為維、哈、柯文是粘性語言,用戶的拼寫錯誤導致文本中出現屬于其他語種的字符形式,有時候文本中也會引入其它語種描述的文本信息。所以為了避免文本中出現的其它文種的獨特特性對文種識別的干擾,要分別統計文本中出現的屬于三種語言的獨特特征。具體分析思路是: 首先要讀取文本,然后分析文本中的所有字符,判斷某個字符是否滿足如下條件:
a) 該字符是否屬于某種語言的專用字符。
b) 能不能跟它后面的字符組合,形成屬于某種語言的復合字符或特殊的元音字母的組合形式。
c) 該字符的出現形式是否屬于該字符在某種語言的出現形式的獨特字符。
按照上述的三個條件分別統計文本中出現的屬于三種語言字符的獨特特征。統計公式如下:
Chracter(x)=

(1)
4 實驗與分析
4.1 實驗數據的采集 維、哈、柯文到目前為止沒有公開的文種識別語料庫,本文設計了一個定向網頁數據采集系統,在人民網、天山網、新華網和一些熱門的維、哈、柯文綜合網站中采集了相應的文本數據。本文采集的三種語言的文本集規模如表13所示。目前柯爾克孜文網站的數量比維文和哈文網站少,所以測試語料庫中柯爾克孜文的數據比較少。

表13 測試語料庫的規模
4.2 統計三種語言的專用和復合字符的出現頻率
為了驗證基于統計專用字符和復合字符的維、哈、柯文文種識別技術的有效性,需要統計維、哈、柯三種語言中的專用字符和復合字符出現的頻率。在測試文本集中統計了第三節中總結出的三種語言的專用字符和復合字符的出現頻率。
在表14~16中所示的數據分別為測試語料庫中的維、哈、柯文文本中出現的維、哈、柯文字符的獨
表14 10 606篇維文文本中維文字符的獨特特性出現的文本數量

字符網頁數字符網頁數063A102190626+,06C710073062E10460626+,06C684810698193206C898560626+,06271045006D010425626+,06D5101740626+,0649101000626+,06488623
特特性。通過觀察可以判斷通過統計維、哈、柯文字符的獨特特性的方法來識別維、哈、柯文文種的有效性。

表15 測試語料中哈文字符的獨特特性出現的文本數量
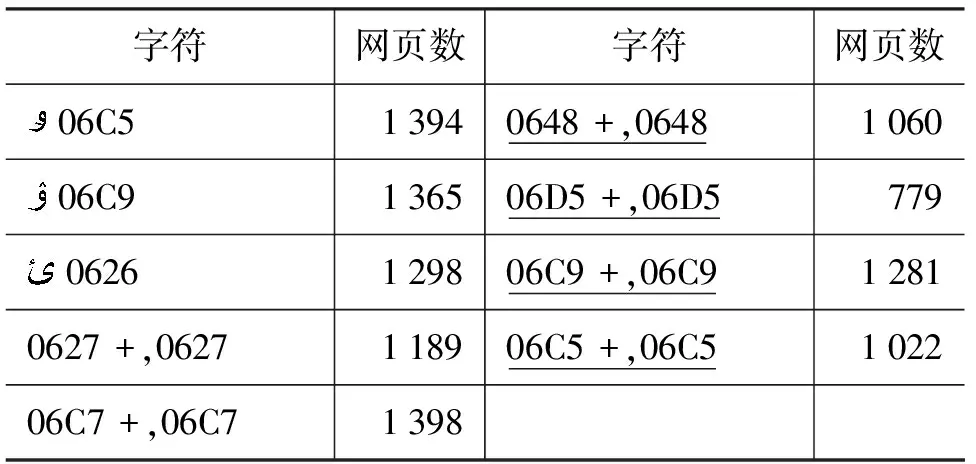
表16 測試語料中柯文字符的獨特特性出現的文本數量
在表15中幾乎沒有出現在表9中的帶下劃線的哈文專用字符,而代替出現了表10中的字符和字符的組合。出現以上錯誤的原因是當前使用的哈文輸入法沒有根據“中華人民共和國國家標準(GB 21669-2008)信息技術維吾爾文,哈薩克文,柯爾克孜文編碼字符集”設計的原因。所以不能在統計理論上的哈文專用字符的基礎上識別哈文,必須要借用實際出現編碼的特點來識別哈文。
在表16中帶下劃線的數據是柯文文本中的特殊元音字母組合出現的文本數量。在表17中帶下劃線的數據是不考慮柯文雙元音字母組合時不同規模的柯文文本段的識別正確率,比較兩組數據可以得到結論,考慮特殊雙元音字母組合很大程度上提高了對柯文文種的識別準確率。從表中的數據可以看出柯文中的特殊的元音字母組合可以作為特征來識別柯文。

表17 測試雙元音字母特征對柯文文種識別印象
在表18~20中所示的數據分別為測試語料庫中的維、哈、柯文文本中出現的其他文種的獨特特性。所以為了避免文本中出現的其他文種的獨特特性對文種識別的干擾,首先要分別統計文本中出現的各個文種字符的獨特特性,然后出現獨特特性最高的文種被指定為該文本的文種。

表18 10 606篇維文本中出現其他文種獨特特性的文本數量
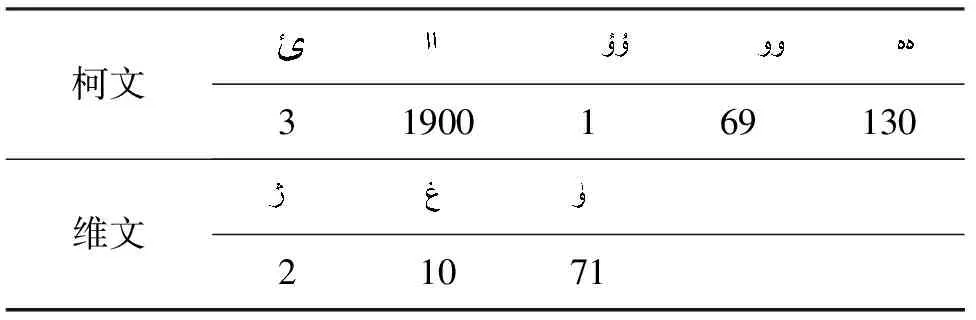
表19 8 039篇哈文本中出現其他文種獨特特性的文本數量

表20 1 503篇柯文本中出現其他文種獨特特性的文本數量
4.3 性能測試
為了驗證本文研究的文種識別算法的準確率,分別測試了語料中的識別率和包含不同字數文本中的準確率,實驗結果如表21和表22所示。
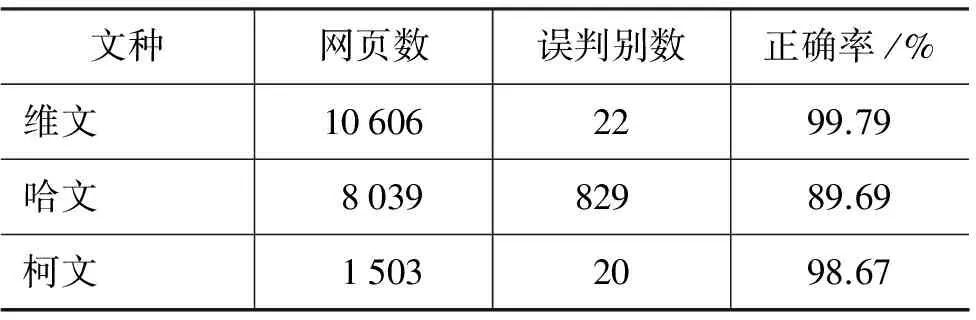
表21 在測試語料中的識別率
通過分析表21中的數據可以總結出本文研究的維、哈、柯文文種識別算法對維文和柯文的識別性能是很理想的,哈文識別效果不如維、柯文,因為哈文字符的獨特字符特征比維、柯文少得多。
為了測試本文研究的文種識別算法在不同規模的文本中的性能,把測試語料庫中的文本分組成不同規模的文本段,在不同規模的文本段中測試文種識別算法的精確度。通過分析表22中的數據可以總結出文本中包含的詞總數70以上時,它的識別效率是很理想的,準確率高于96.67%。維、柯短文本的識別效率是很理想的,對包含詞數小于30的哈文段文本的識別效率不太理想。

表22 包含不同詞數文本中的識別率
5 結論
本文研究的基于統計字符的維、哈、柯文文種識別技術對長文本性能非常好,文本包含的詞數多于70詞的時候準確率達到96.67%以上。對維、柯文的識別率比哈文的識別率高,因為哈文的獨特字符特征比維、柯文少得多。在文本規模比較大時可以達到各領域實際應用的目標。
[1] 吐爾根·依布拉音,袁保社.新疆少數民族語言文字信息處理研究與應用[J].中文信息學報,2011,25(6):150-156.
[2] 王玲,達瓦·伊德木草,吾守爾·斯拉木.維哈柯及蒙語多文種語言相似性考查研究[J].中文信息學報,2013,27(6):180-186.
[3] 維尼拉·木沙江,吐爾地·托合提,吐爾洪·吾司曼。基于重定位的維、哈、柯文Unicode編碼及多文種索引技術研究[J].鄭州大學學報(理學版),2009,41(1):48-51.
[4] R D Lins and P. Gon?alves. Automatic language identi_cation of written texts[C]//Proceedings of SAC-2004, the 2004 ACM symposium on Applied computing, ACM Press, 2004:1128-1133.
[5] Chew Y Choong, Yoshiki Mikami, C A Marasinghe et al. Optimizing ngram Order of an ngram Based Language Identification Algorithm for 68 Written Languages[J]. The International Journal on Advances in ICT for Emerging Regions 2009,02 (02):21-28.
[6] Bruno Martins, M rio J.Silva. Language Identification in Web Pages[C]//Proceedings of SAC’05 March, Santa Fe, New Mexico, USA:ACM, 2005: 13-17.
[8] W B Cavnar and J.M.Trenkle. N-gram-based text categorization[C]//Proceedings of SDAIR-94, the 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, Nevada, U.S.A, 1994: 161-175.
[9] 買日旦·吾守爾,維尼拉·木沙江.多文種多向電子詞典軟件系統關鍵技術研究[J].計算機應用與軟件,2011,28(4):170-173.
[10] 薛亞平,袁保社. 全文檢索系統中語種識別與索引技術研究[J].技術應用,2009,12: 49-51.
[11] 倪耀群,曹鵬,許洪波,唐慧豐,程學旗.網絡維吾爾文判別及其文本長度下界的探討[J].中文信息學報,2012,26(6):109-115.
[12] 中華人民共和國國家標準(GB 21669-2008)信息技術維吾爾文,哈薩克文,柯爾克孜文編碼字符集[C],2008-04-11發布,2008-09-01實施.
Unique Character Based Statistical Language Identification for Uyghur, Kazak and Kyrgyz
Maimaitiyiming Hasimu1,2, Wushouer Silamu1, Weinila Mushajiang1, Nuermaimaiti Youliwasi1
(1. School of Information Science and Engineering, Xinjiang University, Multilingual Information Technology Laboratory of Xinjiang, Urumqi, Xinjiang 830046, China; 2. Department of Computer Science Hotan Teachers College, Hotan, Xinjiang 848000, China)
In Unicode encoding consortium, Uyghur, Kazak and Kyrgyz characters are arranged in the Arabic characters area and mixed with Arabic characters. Some characters in these languages shares same code without language ID,which brings difficulty in information retrieval and natural language processing. After analyzing the unique characters, compound characters and the special features of some characters in certain language context, this paper designs a language identification algorithm of Uyghur, Kazak and Kyrgyz. The experimental results show that the accuracy achieves 96.67% for texts with 70 words or more.
language identification, unique characters, compound characters, Uyghur text, Kazak text, Kyrgyz text, Unicode

買買提依明·哈斯木(1980—),博士研究生,講師,主要研究領域為信息檢索。E?mail:mamtimin116@163.com吾守爾·斯拉木(1942—),中國工程院院士,本科,教授,博士生導師,主要研究領域為自然語言處理。E?mail:wushour@xju.edu.cn維尼拉·木沙江(1960—),本科,教授,碩士生導師,主要研究領域為信息檢索。E?mail:winira@xju.edu.cn
1003-0077(2015)02-0111-07
2014-03-17 定稿日期: 2014-04-25
國家“973”重點基礎研究計劃(2014CB340506);國家自然科學基金(61262063,61363063)
TP391
A
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
