槽填充中抽取模式的優化方法
2015-04-21 09:44:44沈曉衛李培峰朱巧明
中文信息學報 2015年2期
沈曉衛,李培峰,朱巧明
(蘇州大學 計算機科學與技術學院,江蘇省計算機信息處理技術重點實驗室,江蘇 蘇州 215006)
?
槽填充中抽取模式的優化方法
沈曉衛,李培峰,朱巧明
(蘇州大學 計算機科學與技術學院,江蘇省計算機信息處理技術重點實驗室,江蘇 蘇州 215006)
在傳統的信息抽取中,模式匹配已經被證實為簡便而有效的方法,而依存路徑也是最為常用的模式之一。在槽填充任務中就有眾多的參與者引入了以依存路徑為基礎的模式匹配方法;該文就針對該方法中存在的包括模式平衡性,模式抽取方式和模式篩選策略等方面的問題,提出了模式裁剪、模式轉置、模式擴展和模式語義定義等主要的優化方法并實現了相關系統,在TAC-KBP2010的目標語料上進行了測試。該文提出的方法F值為20.8%,比基準系統的14.3%提高了6.5%。
槽填充;模式優化;信息抽取
1 前言
傳統的信息抽取評測如MUC和ACE主要還是關注在個別文檔和領域限定文檔上進行的相關抽取;但在實際中,很多的應用需要從開放的,規模較為龐大的數據源里抽取信息,進而用抽取到的信息實現對現有知識庫(Knowledge Base, KB)的補充和擴展。這就需要系統能夠正確辨別出數據源與知識庫里已知實體間的一一對應關系,并能抽取出這些實體的相關信息。針對這樣的需求,TAC于2009年提出了知識庫填充任務(Knowledge Base Population, KBP),槽填充(Slot Filling, SF)是它的第二個子任務。
到2011年底TAC-KBP已經成功舉辦了三屆,有眾多的小組參與了其中的槽填充任務,提出了一些具有針對性的做法。這些做法主要可以分為兩種,第一種是以傳統的信息抽取方法為主體實現槽填充;另外一種則是以問答系統(Question Answering, QA)為基礎,把每一個槽(SF中把實體的屬性或信息稱為槽,Slot)解析為對應的問題集合來實現任務。在第一種做法中,基于依存路徑的模式匹配方法被較多的參與者所使用。本文即以該方法為基礎,提出了方法中部分具有代表性的問題,并針對每一種問題提出了相應的優化策略,使得系統的綜合表現相對基準系統有了比較可觀的提高。這不僅說明了基準系統中確實存在著此類亟待解決的問題,也說明了本文探討的部分優化方法是切實可行的。
文章的結構安排如下,第2節介紹了TAC-KBP槽填充任務的定義和相關工作;第3節主要描述了基準系統的實現過程;第4節探討了系統中的一些問題和優化策略;第5節給出了加入相應的優化策略后系統的表現和對結果的分析;最后對全文進行了總結。
2 任務定義和相關工作
槽填充任務主要涉及到兩個數據集,一個是已知的知識庫(KB),它是由一個個獨立的節點(node)組成的XML文件,每一個節點包含一個從維基百科(Wikipedia*http://www.wikipedia.org/)里獲取到的實體和一段對該實體進行介紹的文本;另一個是數據源(Source Corpora, SC),是由新聞、博客、對話、錄音等網絡文本組成的(TAC-KBP的數據源共包含1 777 888份文檔),用
來作為目標語料的文檔集。
槽填充中目標實體分為PER和ORG兩種類型,分別包含了26和16種預定義的槽。槽有單值和多值之分,單值槽如“per:date_of_birth”只有一個可能的值;多值槽如“per:siblings”有多個可能的值。槽的具體數據表現類型有Name,Value和String三種。Name表示一個實體名稱或是一個專有名詞,如John、IBM等; Value表示一個具體的數值,如時間、年齡等;String表示一個可陳述的事實(通常是一個短語),如死亡原因等。
從2009到2011平均每年都有20個以上的小組參與TAC-KBP相關的評測,其中對槽填充的兩種系統實現方法中,主要以信息抽取方法居多;按照具體做法的不同,又可以分為基于模式匹配的方法和基于分類器的方法。絕大部分的系統都是以其中的某一種方法為主,但也有如CUNY[1]這樣,綜合使用了上述全部三種方法,而在最后對多個方法并行得到的備選答案進行排序和選擇。相關系統的具體實現方法分類如表1[2]。
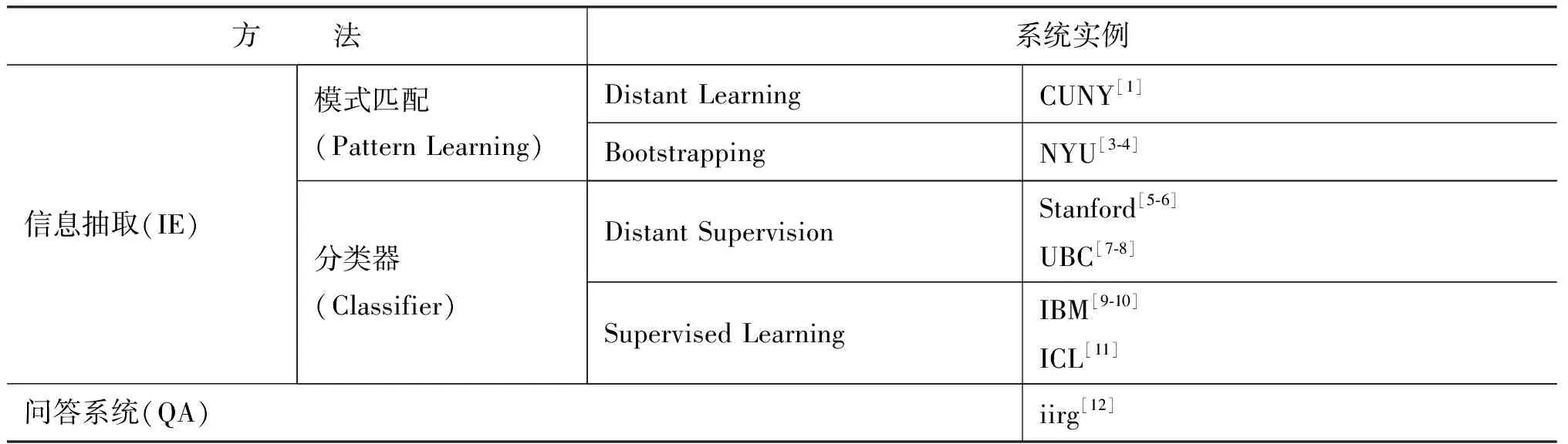
表1 系統實現方法
槽填充任務的評測指標不是很理想;Stanford[5]在以知識庫的2/3為訓練數據,1/3為測試數據時F值達到了56.7%,但其在官方評測上的F值卻只有14.12%。雖然評測中作為TopSystem的IBM[9]系統的F值有28.2%,但多數系統的表現還是集中在10%~20%之間;如果不引入web知識庫(如Wikipedia)或者語料庫(如Freebase*http://www.freebase.com/, DBpedia*http://blog.dbpedia.org/),F值通常在15%。而IBM相對出色的表現則主要歸功于他對于基礎組件性能的提升,例如,IBM就針對槽填充任務擴展了與ACE并不兼容的命名實體類型,重新訓練了實體探測器并且引入了DBpedia以獲得更多的訓練數據,才最終取得了比較優異的性能。這也間接表明傳統的在正規或限定領域的新聞語料里訓練出來的抽取組件在噪音較大的web數據上遭遇了很大的困境。而對TAC-KBP2010的訓練數據的分析顯示只有60.4%[2]的情況實體和槽是在同一個句子里出現的,22.8%[2]的情況下需要句子間的共指消解,其余的還包括句子間的推理,關系的傳遞和世界知識的輔助。
3 基準系統
本文參照了目前常用的一些做法, 實現了一個相對簡單的基準系統(這里只選擇了對兩種目標實體中PER類型實體的抽取)。訓練階段的第一步是對知識庫的處理,通過計算不同代詞的個數確定性別并把對應的代詞替換為實體名稱,標示出每一個句子中實體的所有出現(由于做了替換,一個句子里同一個實體的名稱可能會多次出現)和槽的第一次出現;第二步是從同時存在實體標示和槽標示的句子中抽取和選擇出實體到槽合適的依存路徑完成模式庫的生成工作。測試階段就是依據得到的模式庫對測試數據進行抽取并給出相應的實驗結果,基準系統結構如圖1所示。
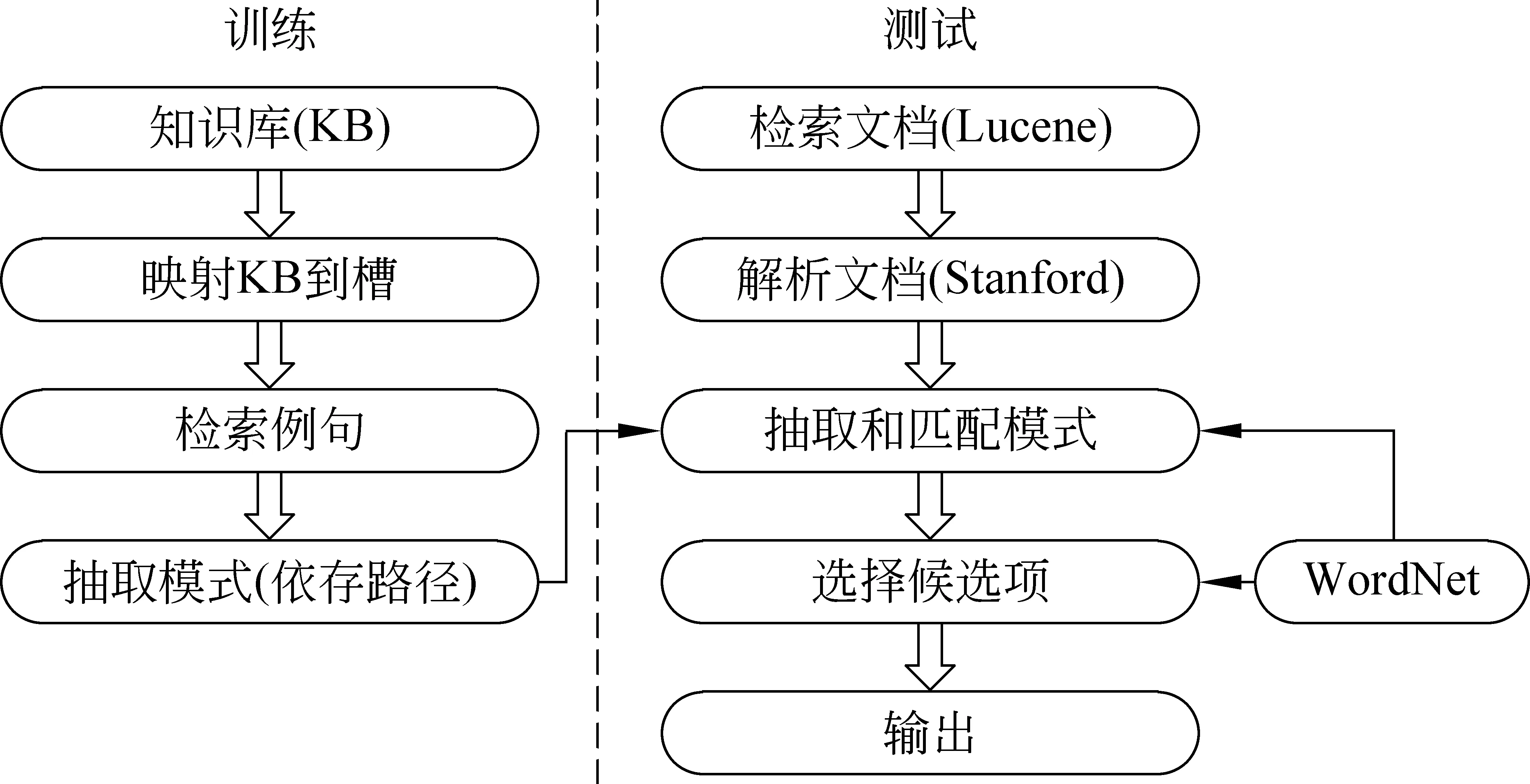
圖1 基準系統結構圖
(1) 模式庫的生成
Stanford*http://nlp.stanford.edu/index.shtml總共定義了53種基本的依存關系,不同的依存關系在模式中的作用也是不一樣的,有些表現為冗余成分, 有些則還會降低模式的有效性
而帶來錯誤,所以抽取之前要對依存關系進行篩選,具體的篩選方法見表2,表中未列出的依存關系表示不做篩選,全部保留。

表2 依存關系篩選方法
模式具體表示為一條從實體到槽的依存路徑,它是一個由詞匯節點和依存關系節點組成的字符串,如從“per:spouse”的例句
中得到模式
nsubj_R
其中每一個節點結尾的“_L”和“_R”表示依存關系的中心詞是在左邊還是右邊,模式最后的“
(2) 目標語料上的測試
對于槽候選項類型的定義采用命名實體和WordNet*http://wordnet.princeton.edu/相結合的方法(具體見表3);由于詞匯存在多義現象,WordNet用編號(如country, SID-08426193-N)表示某一種明確的語義。具體的測試實現過程可以分為如下的幾個步驟:
1) 候選文檔的檢索。以目標實體名稱為檢索關鍵字通過Lucene*http://lucene.apache.org/從目標語料(SC)里獲取候選文檔集;對于Lucene檢索打分相同的文檔優先選擇文本長度更長者,以期待獲取更多的信息。
2) 文檔解析。用Stanford對候選文檔進行句法, 依存和指代的解析并在每一個解析后的文檔里
標示出指向目標實體的指代關系。
3) 預抽取。對“per:title”、“per: origin”和“per:religion”三種槽進行預抽取;如: 目標實體和“the driver”之間存在指代關系,而“driver”又符合“per:title”候選項類型的定義,那么“driver”就是“per:title”的一個備選答案。
4) 模式抽取和匹配。以目標實體的每一個指代項作為一個出現抽取出模式,進行匹配。對于名詞和動詞匹配同義和子義關系,對于形容詞和副詞,匹配同義,其它諸如冠詞,數詞等只匹配詞性。
5) 備選答案選擇。這里借用IBM[9]的打分方法,單值槽選擇得分最高的一個,多值槽選擇分數排名前三的(少于三個的則全部選擇),具體的評分計算方法如下:
Score(Si) = count(Si) + 1/n * docCount(Si)
其中count(Si)表示備選答案Si的出現次數,docCount(Si)表示包含Si的文檔的出現次數,n則表示所有備選答案的個數。

表3 候選項的實體類型和抽象語義
4 存在的問題和優化方法
上述的基準系統并不是很理想,F值14.3%也只勉強達到了現有系統的平均水平;通過細致的對比觀察發現有些種類槽的模式庫正確率比較低,這種情況的出現主要和模式生成的基礎理論Distant Supervision[13]有關,Distant Supervision只在相對比較苛刻的條件下才能有良好的表現。例如,在一個人和他的出生時間這樣比較單一的關系里Distant
Supervision就會有很優異的表現,但是在另外一種情況下,如一個人和他的出生地之間就可能包含多種的關系,他可能在那里上學、工作、結婚等等。所以在使用Distant Supervision時要對不同的槽附加相應的限制條件,除此之外訓練數據和測試數據之間的平衡性、模式的裁剪和泛化等問題也同樣急需解決。
(1) 模式的裁剪
模式庫部分的模式里包含有一些對抽取沒有貢獻,但是卻嚴重降低了模式覆蓋率的詞匯和依存關系,例如從句子:
得到一條“per:children”的模式:
nsubj_R
在這樣的模式中

表4 裁剪方法
(2) 模式的轉置
訓練數據都來自知識庫,而知識庫和測試語料在表達上還是有很大區別的,這就帶來了平衡性的問題。例如,知識庫里在論述一個人父母的時候,大都會是: “他的父親/母親是誰”,這樣實體在前槽在后的形式,而很少出現槽在實體前面的句子。但測試數據可以認為基本是平衡的,也就是說可能會有一半的情況是槽出現在實體前面,這就是一個顯而易見的平衡性問題之一。模式的轉置操作就是解決這個問題一種快速簡單的方法;例如,抽取父母的模式,把頭尾調轉,就變成了抽取子女的模式,而如配偶這樣的對等關系,轉置后就可以直接作為本身的模式,具體的轉置關系如表5所示。

表5 轉置關系
轉置的具體做法是這樣的,例如對于模式
nsubj_R
首先把
dobj_R
(3) 模式的語義定義
基準系統只在測試階段使用了有關語義的比較,實際上在系統的每個階段都可以引入語義的輔助,特別是在模式庫的生成階段。例如槽“per:place_of_birth”對應的模式庫,如果能在其中的一個模式中檢測到表示“生育(bear/birth)”語義的詞匯,那么這個模式確實能夠正確表達槽關系的可能性就非常大了;但對于模式庫中的所有模式而言,能夠表達這種關系的并不一定都包含表示“生育”語義的詞,例如,“John’s birthplace is China”,除卻“birthplace”的歧義不談,這個句子的模式中就沒有顯式的表示“生育”語義的詞匯。另一個比較棘手的問題是并不是每一個槽都可以抽象出一個明確的語義或語義詞匯,或者說半數以上的槽都很難用某一個語義囊括全部。例如,槽“per:children”,除了表達“子女(children)”的語義外,“父母(parents)”語義同樣可以表達“子女”關系,甚至諸如“領養(adopt)”,“生育(give birth to)”,“懷孕(pregnant)”等也可以表達“子女”關系,但這都是建立在一定的世界知識基礎之上的,而對于沒有任何世界知識的模式而言,簡單而有效的做法就是人為的為他定義一個語義集合。對于“place_of_residence”這樣確實很難建立一個語義集合的,可以使用槽之間的語義差集關系來間接完成對語義的限定,即認為不包含“生育(bear/birth)”和“死亡(death)”語義的模式就是表達了“place_of_residence”關系的模式。
由于詞匯的多義性,如何判斷一個詞到底表示哪一個語義又是一個難題,在模式庫的生成階段可以根據WordNet的編號確定一個唯一的語義,即如果模式庫里的一個模式包含“bear”這個詞,那么就可以把這個詞的語義定義為“生育”,它在WordNet里對應一個唯一的編號“SID-00056206-V”,當然這個詞也并不一定就表示“出生”,但由于它是出現在實體和槽之間的路徑上,這是可能性最大的一個語義。測試階段的二義性問題就比較難解決,折中的方法就是定義一個“停用詞”表,如“have/deliver”也有表示“生育”的意思,但在系統中就可以認為它們是不表示這個語義的,而被標記為“停用詞”。于是對于每一個語義都建立這樣的一張詞匯表最終組成一個“停用詞”表。模式的語義定義具體如表6。
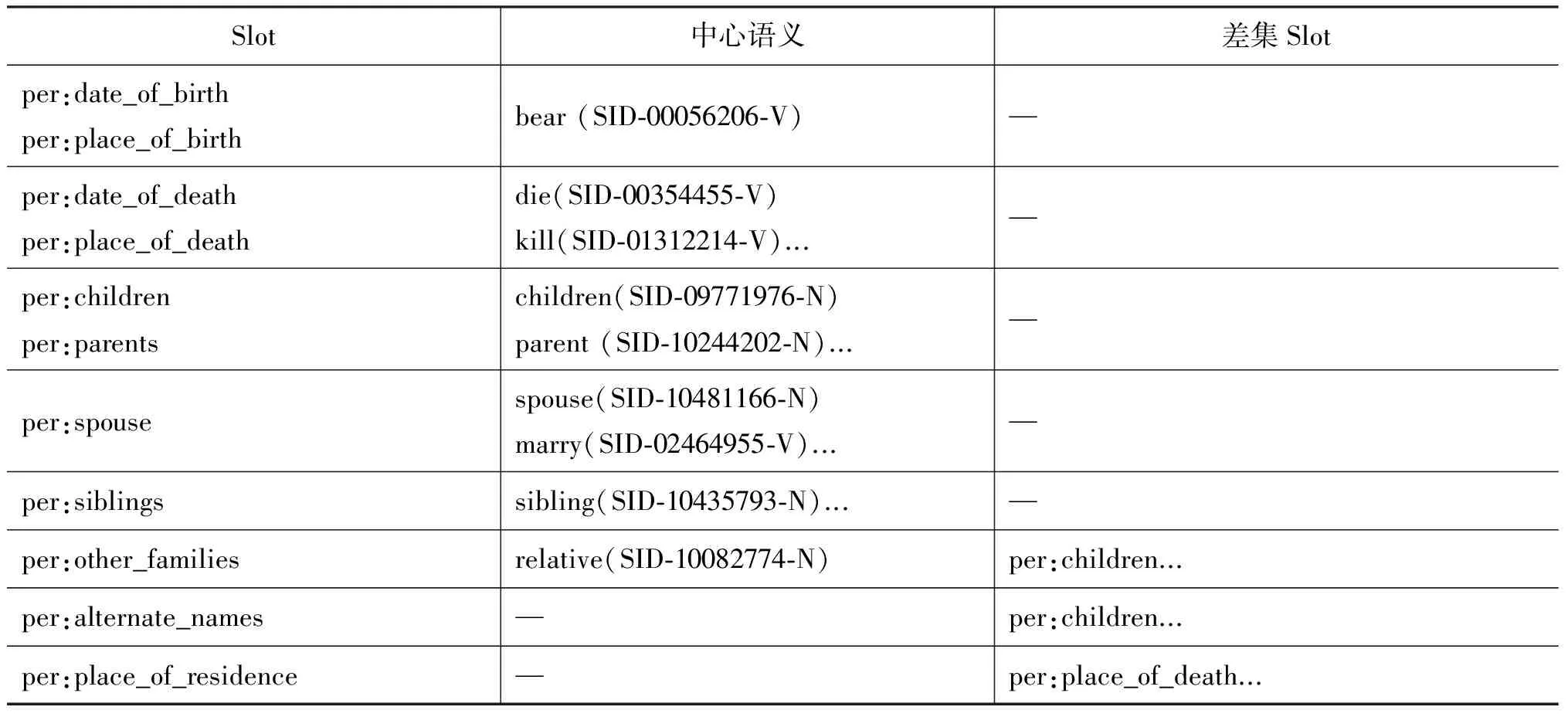
表6 模式語義定義
(4) 模式的擴展
在做如“per:children”和“per:parents”等槽的抽取時,從很多能夠明顯表征關系的句子中卻無法得到有效的模式。原因主要是因為一些非主干性的成分不能被有效的捕捉到。基準系統中的模式只表示了實體和槽之間的主干關系,這樣雖然可以大大減少無用的附加開銷,但是在做如上述的槽抽取時,非主干性的成分也是非常重要的,有時候甚至是決定性的。例如從句子
得到的“per:parents”的模式只是一個簡單的并列關系:
conj_and_L
顯然這樣的一個模式是沒有任何的關系表征作用的,這里如果能夠進一步地抽取出father和槽之間的“nn”修飾關系,這個模式才可以有更好的表現。具體做法是如果能在實體和槽之間找到表達模式定義的語義詞匯,并且這個詞匯和實體或是槽之間存在某種依存關系,就做一次模式擴展,那么上面的模式擴展后就變成了下面的:
conj_and_L<@@>nn_L < father[NN]><##>R
其中“<@@>”之后的部分表示是擴展的部分,“<##>”之后的“R”表示是對槽的擴展,相應的對實體的擴展就是“L”。
5 實驗結果及分析
運用上述的四種策略對基準系統進行了優化,在模式生成階段,用人為定義的語義對模式進行了篩選,并對部分種類的依存關系進行了裁剪,對有些種類槽的模式做了擴展和轉置。
在測試階段,對于定義有語義的模式,對語義詞要求同基準系統相同的匹配規則,模式其他部分的依存關系和詞匯節點,只做詞性的匹配。對于沒有定義語義的槽則采用和基準系統相同的匹配規則。為了檢驗方法的效果,在TAC-KBP 2010的數據上進行了測試,得到的結果如表7所示。

表7 實驗結果
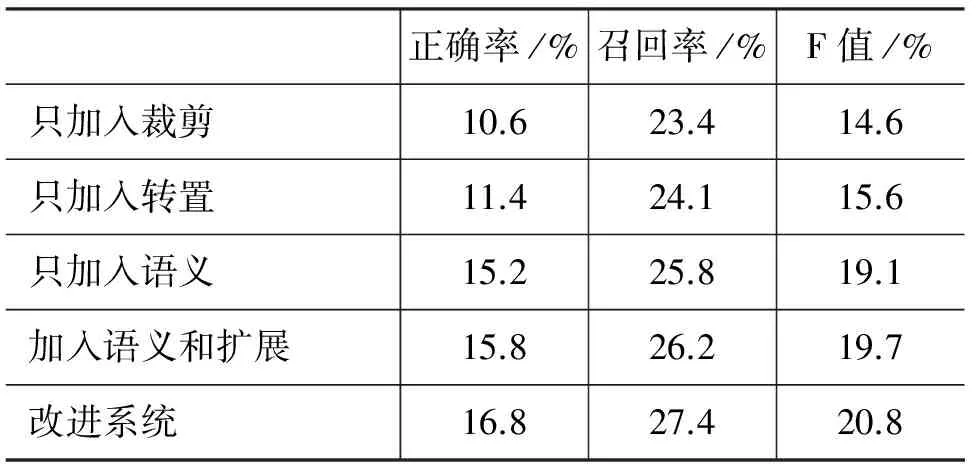
續表
從表中可以看出,每一種方法的加入,都提高了系統的表現。但是除了語義以外,其他三種方法對表現的影響比較小,都在2%以內;轉置和擴展都只針對部分種類的槽,而這些槽在TAC-KBP 2010中的總體比重并不是非常大。而且現階段轉置和擴展的程度都比較低,轉置僅僅局限于對部分槽人為的定義了對應的倒轉關系,而擴展的條件也限制的太過嚴苛,如句子
中抽取的模式是
conj_and
由于在實體和槽之間沒有可供擴展的語義詞匯(只有一個“and”),模式無法擴展而被作為噪音丟棄,這就直接導致系統無法從目標語料里類似表達的句子中抽取出有效的信息。但是如果對擴展不加限制,那么對其引入的大量噪音如何消除就是一個嚴峻的問題,不然最后的結果可能是得不償失的。
模式語義的加入對系統性能有了相對其他方法都大的提高,首先是它能很有效地對模式進行篩選,并且使模式里的不同節點有了地位高低的區分,而不再是所有的節點都同等對待,例如,“per:children”的一個模式
nsubj_R
在這個模式中只有兩個詞匯節點,分別是“live”和“child”,但是可以看出這兩個詞匯的作用差別是很大的,其中“live”幾乎可以換成其他任何符合語法的詞匯,而“child”則只能限制在它所表征的特定語義范圍內。但本文模式語義的定義仍然是最初級的人工定義,而模式中的詞匯節點也只是一刀切的分為了語義詞和非語義詞兩類,如何能更好地解決這些問題也是今后工作的內容之一。除去上述的原因之外,基礎組件的性能,如句法分析、實體識別等的性能也對系統有著比較大的影響,由于依存路徑在很大程度上還是依賴句法分析的結果,如果句法分析有誤,那么后面所有的工作都是錯誤的。實體識別更是如此[14],如果把一個地名識別為一個機構名,結果也是可想而知的。在很多情況下,槽并不能通過直接的模式獲得,而是需要不同槽之間的關系傳遞,例如可能直接抽取一個人的“per:siblings”并不能得到答案,但是通過抽取這個人的“per:parents”的不同于本人的“per:children”槽也可以同樣達到這個目的。
6 總結
傳統的信息抽取如關系抽取在限定領域中已經有了70%以上的優秀表現,但是在面對開放的如網絡文本類型的數據時就有了很大的問題。原因是多方面的,首先是基礎抽取組件性能的下降,如在傳統新聞語料上訓練出來的實體識別組件在網頁、博客之類的文本里表現就很大程度的下降了,同時下降的還有句法分析、指代消解等組件的表現。除了基礎組件的問題,還有就是抽取方法的問題,在開放的數據源中,除了句法、指代等信息外,語義等信息也應該給予更多的關注。
實驗的結果雖然說明我們提出的方法有一定的效果,但是仍然有很多的缺陷,而且這些方法有的只針對部分類型的槽,對其余類型的槽我們仍然沒有找到很好的改進方法。
[1] Zheng Chen, Suzanne Tamang, Adam Lee, et al. CUNY-BLENDER TAC-KBP2010 Entity Linking and Slot Filling System Description[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[2] Ralph Grishman, Heng Ji. Knowledge Base Population: Successful Approaches and Challenges[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), 2011: 1148-1158.
[3] Ralph Grishman, Bonan Min. New York University KBP 2010 Slot Filling System[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[4] Ang Sun, Ralph Grishman, Wei Xu, et al. New York University 2011 System for KBP Slot Filling[C]//Proceedings of Text Analysis Conference (TAC2011), 2011.
[5] Mihai Surdeanu, David McClosky, Julie Tibshirani, et al. A Simple Distant Supervision Approach for the TAC-KBP Slot Filling Task[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[6] Mihai Surdeanu, Sonal Gupta, John Bauer, et al. Stanford’s Distantly-Supervised Slot-Filling System[C]//Proceedings of Text Analysis Conference (TAC2011), 2011.
[7] Ander Intxaurrondo, Oier Lopez de Lacalle, Eneko Agirre. UBC at Slot Filling TAC-KBP 2010[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[8] Ander Intxaurrondo, Oier Lopez de Lacalle, Eneko Agirre. UBC at Slot Filling TAC-KBP 2011[C]//Proceedings of Text Analysis Conference (TAC2011), 2011.
[9] Dan Bikel, Vittorio Castelli, Radu Florian, et al. Entity Linking and Slot Filling through Statistical Processing and Inference Rules[C]//Proceedings of Text Analysis Conference (TAC2009), 2009.
[10] Vittorio Castelli, Radu Florian, Ding-jung Han. Slot Filling through Statistical Processing and Inference Rules[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[11] Yang Song, Zhengyan He, Houfeng Wang. ICL_KBP Approaches to Knowledge Base Population at TAC2010[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[12] Lorna Byrne, John Dunnion. UCD IIRG at TAC 2010 KBP Slot Filling Task[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[13] Mike Mintz, Steven Bills, Rion Snow, et al. Distant supervision for relation extraction without labeled data[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009: 1003-1011.
[14] 奚斌, 錢龍華, 周國棟, 等. 語言學組合特征在語義關系抽取中的應用. 中文信息學報, 2008, 22(3): 44-49.
Pattern Optimization for Slot Filling Task
SHEN Xiaowei,LI Peifeng,ZHU Qiaoming
(School of Computer Science and Technology,Soochow University,Suzhou, Jiangsu 215006,China; Key Lab of Computer Information Processing Technology of Jiangsu Province,Suzhou,Jiangsu 215006,China)
Pattern matching has been confirmed to be a simple and effective way in traditional information extraction, and dependency path is one of the most common patterns. There are a large number of researchers apply the pattern matching method based on dependency path in Slot Filling task. Focused on the issues of pattern balance, pattern extraction mode and pattern selection strategy in this task, this paper proposes some optimization strategies of pattern cutting, pattern reversing, pattern expansion and pattern semantic definition, and realizes a complete system. Tested in the TAC-KBP2010 target corpus, the F value of the proposed method achieves 20.8%, leading a 6.5% improvement against the 14.3% of the baseline system.
Slot Filling; pattern optimization; information extraction

沈曉衛(1989—),碩士,助理工程師,主要研究領域為信息抽取。E?mail:shenxiaowei@suda.edu.cn李培峰(1971—),博士,副教授,主要研究領域為信息抽取、情感分析和機器學習。E?mail:pfli@suda.edu.cn朱巧明(1963—),博士生導師,教授,主要研究領域為中文信息處理和機器學習。E?mail:qmzhu@suda.edu.cn
1003-0077(2015)02-0199-08
2012-11-01 定稿日期: 2013-01-09
國家自然科學基金(61070123);江蘇省自然科學基金(BK2011282);江蘇省高校自然科學重大基礎研究項目(11KIJ520003)
TP391
A
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
現代語文(2016年21期)2016-05-25 13:13:44
山東青年(2016年1期)2016-02-28 14:25:25
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
