強語義模糊性詞語的情感分析
2015-04-21 09:26:36張志飛苗奪謙岳曉冬聶建云
中文信息學報 2015年2期
張志飛,苗奪謙,岳曉冬,聶建云
(1. 同濟大學 計算機科學與技術系,上海 201804;2. 上海大學 計算機工程與科學學院,上海 200444;3. 加拿大蒙特利爾大學 計算機科學系,蒙特利爾)
?
強語義模糊性詞語的情感分析
張志飛1,3,苗奪謙1,岳曉冬2,聶建云3
(1. 同濟大學 計算機科學與技術系,上海 201804;2. 上海大學 計算機工程與科學學院,上海 200444;3. 加拿大蒙特利爾大學 計算機科學系,蒙特利爾)
語義的模糊性給詞語的情感分析帶來了挑戰。有些情感詞語不僅使用頻率高,而且語義模糊性強。如何消除語義模糊性成為詞語情感分析中亟待解決的問題。該文提出了一種規則和統計相結合的框架來分析具有強語義模糊性詞語的情感傾向。該框架根據詞語的相鄰信息獲取有效的特征,利用粗糙集的屬性約簡方法生成決策規則,對于規則無法識別的情況,再利用貝葉斯分類器消除語義模糊性。該文以強語義模糊性詞語“好”為例,對提出的框架在多個語料上進行實驗,結果表明該框架可以有效消除“好”的語義模糊性以改進情感分析的效果。
情感分析;語義模糊性;粗糙集;貝葉斯分類
1 引言
近年來,情感分析一直是自然語言處理領域的研究熱點并取得了廣泛應用[1-2],如商務決策、輿情監控等。隨著社交媒體的普及,文本的表達由規范化向口語化逐漸轉變,而且文本的規模也十分可觀。情感分析借助社交媒體也取得了意想不到的成功,例如,股票走勢預測[3]、政府選舉預測[4]、用戶興趣發現[5]等。
國內外學者在情感分析方面開展了很多研究[6-7],其中也不乏關于特殊句式的研究,如條件句[8-9]和比較句[10-11]等。從這些研究中發現,中英文處理時存在一定的區別。同樣,在單個詞語上也存在區別,例如,英文的“Good”表達積極的情感,而中文對應的“好”雖然在大部分情況下也表達積極的情感,但是在與其他字組合或者在特殊情境下卻表達消極或者中立的情感。目前,單個詞語在情感分析中的研究還鮮有報道。
根據國家語委發布的《現代漢語常用字表》和《現代漢語常用詞表(草案)》,漢語常用字有3 500個,常用詞有56 008個。研究每個字詞在情感分析中的作用既不符合實際,也完全沒有必要。但是,漢語中有些詞語不僅使用頻率高,而且語義模糊性強。以“好”為例,在北京大學CCL現代漢語語料庫*http://ccl.pku.edu.cn:8080/ccl_corpus/index.jsp?dir=xiandai的9 711個字中排名第88位,在《現代漢語詞典(第5版)》中具有15個釋義,足見“好”具有很強的語義模糊性[12]。
如果句子“維修站的服務好差”中的“好”被認為褒義詞,那么句子的情感傾向判斷錯誤。如果通過語義模糊性分析,認為不體現情感(實際為程度副詞),那么句子的情感傾向判斷正確。因此,研究具有強語義模糊性的詞語有助于提高情感分析的效果。文獻[13]利用HowNet*http://www.keenage.com/計算詞語的語義傾向, HowNet中“好”具有13個概念, 會影響正確度
量其他詞與“好”的語義相似度,因此文獻[14]提出利用概念來識別詞語的情感傾向。
本文重點描述了如何消除情感詞語的語義模糊性。第二部分詳細描述了一種規則和統計相結合的框架消除語義模糊性;第三部分以詞語“好”為例具體闡述消除模糊性的方法;第四部分給出了實驗結果;最后總結了全文的工作。
2 語義模糊性處理框架
2.1 基本框架 本文提出的語義模糊性處理框架如圖1所示。以強語義模糊性詞語為研究對象,通過規則和分類器消除在特定句子中該詞語的語義模糊性。從訓練語料中抽取該詞語的特征(A部分),利用粗糙集自動生成決策規則(B部分),同時構造貝葉斯分類器(C部分)。當規則失效時,分類器作為補充。
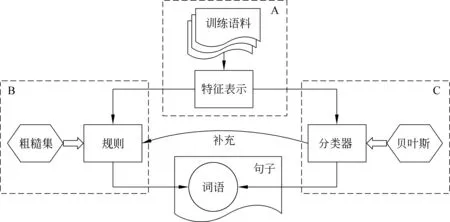
圖1 基本框架圖
2.2 特征表示
特征主要指相鄰信息,如相鄰的詞語、相鄰詞語的詞性、是否位于句子的左端或右端等。
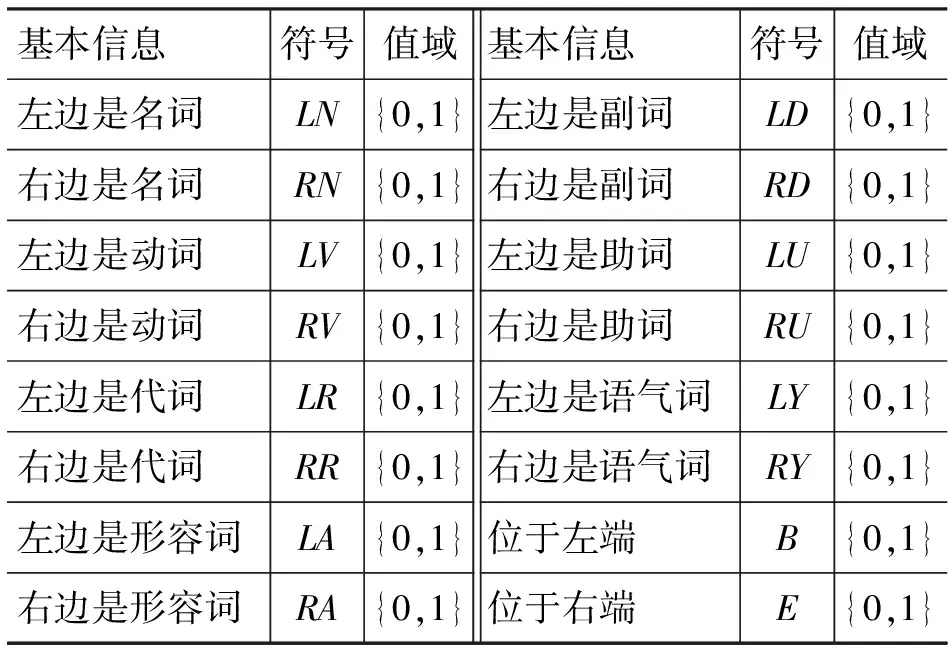
表1 相鄰基本信息
表1從詞性和位置角度列出了16個常見的相鄰基本信息,所有符號的全集記作BI, 每個符號的值域為{0,1},1和0分別表示出現和不出現。
定義1 (基本特征)從基本信息中抽取滿足一定條件的作為基本特征,通常采用閾值設定條件,將基本特征的全集記作BF, 于是有BF?BI, 每個基本特征的值域仍然為{0,1}。
(1)
公式(1)中的“特征名稱=值”表示特征取該值(下同)。
定義2 (附加特征)當限定基本特征取特定詞語時,稱其為基本特征對應的附加特征,將附加特征的全集記作AF。
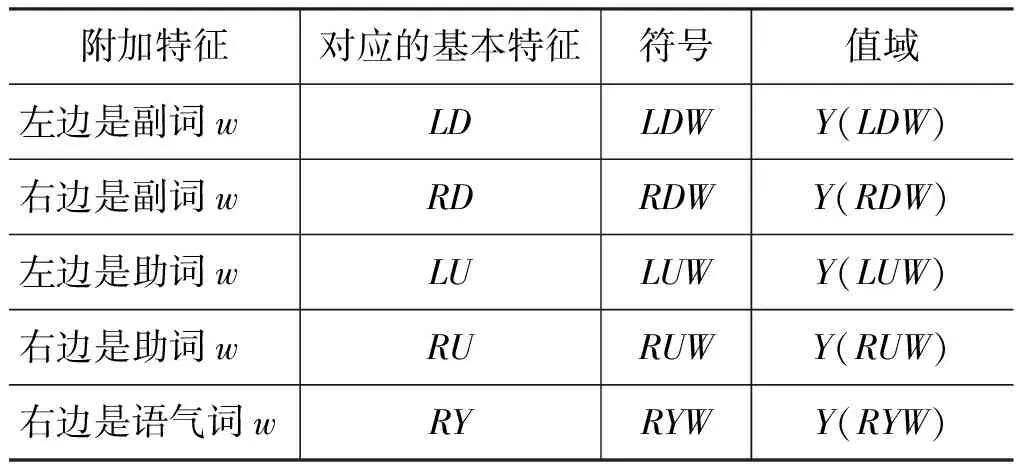
表2 附加特征
表2列舉了5個附加特征,采用閾值法確定附加特征的值域。以LUW為例:

(2)
公式(1)和(2)中 count(*) 表示在訓練語料中的計數,按照經驗分別設置閾值為0.01和0.005。附加特征的閾值比基本特征的閾值小,因為附加特征是基本特征的補充,需要盡量保留。
將上述抽取出的特征表示成一張決策表,即框架圖中的A部分。決策表定義如下。
定義3 (決策表)決策表形式化為一個四元組DT=(U,C∪D,V,f)[15],其中:
U:U為對象的非空有限集合,稱為論域;
C:C=BF∪AF稱為條件屬性集合,包括基本特征和附加特征;
D:D={l} 稱為決策屬性集合,只有一個情感傾向屬性;
V:V=∪Va(?a∈C∪D),Va表示值域,有Va∈BF={0,1},Va∈AF=Y(a),Vl={1,-1,0};
f:f={fa|fa:U→Va},fa表示屬性a的信息函數。
2.3 粗糙集規則生成
粗糙集理論是一種新的處理模糊和不確定性知識的數學工具,主要思想是在保持分類能力不變的前提下,通過屬性約簡或屬性值約簡,導出決策規則,這些規則可以有力解釋一些語言現象,對應框架圖中的B部分。首先給出粗糙集理論中常用的定義[16]。
定義4 (不可分辨關系)給定論域U和屬性子集R?C∪D,則稱IND(R) 為U上的不可分辨關系,簡記為R,見公式(3),顯然R是一個等價關系。
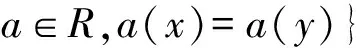
(3)
則 [x]R為包含x的R等價類,U/R表示U上所有的R等價類,有U/R={[x]R|?x∈U}。
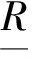
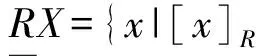
(4)
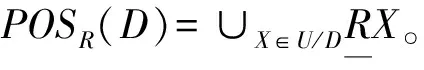
由于細粒度的詞語傾向性標注需要付出更多的時間和人力,因此基于詞語的傾向與句子保持一致的假設,設定決策表的決策屬性l的值,見算法1。

算法1 設定決策屬性l的值輸入:強語義模糊性詞語word和句子sentence輸出:決策屬性l的值(1)(2)(3)(4)(5)對句子sentence進行分詞和詞性標注并利用標點符號劃分為子句集合Subs;找出子句集合Subs中含有word的子句sub;如果sub為否定句,則word的情感傾向和句子sentence的情感傾向相反;如果sub為肯定句或雙重否定句,則word的情感傾向和句子sentence的相同;設定決策屬性l的值為word的情感傾向并返回。
根據算法1得到的決策表通常是不相容決策表,即條件屬性完全相同的情況下會出現決策屬性值不同。為了獲取確定性規則,將不相容決策表轉變為相容決策表。轉化的思想是: 在同一條件屬性下,保留決策類別數最多的對象,舍棄決策類別少的對象。
對相容決策表運行屬性約簡算法[16](如基于Pawlak屬性重要度、基于差別矩陣和基于互信息等),得到相對約簡,記作Red?C, 相對約簡可能為多個,進而生成決策規則。

算法2 不相容決策表轉化為相容決策表輸入:不相容決策表DT=(U,C∪D,V,f)輸出:相容決策表DT′=(U′,C∪D,V,f)(1)(2)(3)(4)(5)(6)(7)令U′=?;計算條件屬性等價類全集U/C={Uc1,…,Ucn}和決策屬性等價類全集U/D={Ud1,…,Udm};對于U/C的元素集合Ucs(1≤s≤n),計算與U/D的每個元素集合Udt(1≤t≤m)的交集Ucs∩Udt;找出基數最大的交集Ucs∩Udk,其中k=argmax1≤t≤mUcs∩Udt;U′=U′∪(Ucs∩Udk);返回到第(3)步,直到U/C的每個元素集合計算完畢;返回DT′=(U′,C∪D,V,f)。
定義7 (決策規則)給定相容決策表DT′=(U′,C∪D,V,f) 及其相對約簡Red, 令Xi和Yj分別代表U′/Red與U′/D中的各個等價類, des(Xi) 和 des(Yj) 分別表示對Xi和Yj的描述(即屬性的特定取值),則決策規則定義為:rij:des(Xi)→des(Yj)。
通過支持度和覆蓋度對規則進行過濾,支持度Sup和覆蓋度Cov分別反映了決策規則的強度和質量,見公式(5),采用閾值法進行過濾,只保留Sup(rij)≥0.01 且Cov(rij)≥0.01 的決策規則。
(5)
算法3給出了決策規則生成的具體步驟。

算法3 決策規則生成輸入:相容決策表DT′=(U′,C∪D,V,f)輸出:規則集合Rules(1)(2)(3)(4)(5)(6)(7)令Rules=?;計算DT′的相對約簡,由于可能為多個,用集合{Red}表示;對于每個約簡Red,執行(4)至(6)步;計算Red和D的等價類全集({X}和{Y}),得到所有的候選決策規則{r};對于每條規則r,計算支持度Sup(r)和覆蓋度Cov(r);如果Sup(r)≥0.01且Cov(r)≥0.01,則Rules=Rules∪{r};返回規則集合Rules。
2.4 貝葉斯分類
相容決策表提取的規則均為確定性規則,且無法匹配所有語言現象。當規則不能匹配時,進一步使用貝葉斯分類方法將消除語義模糊性問題轉化為分類問題,即框架圖中的C部分。詞語屬于不同情感傾向的概率等于所有特征屬于不同情感傾向的概率的綜合表達式。
定義8 (基本特征先驗概率)基本特征在不同情感傾向中出現的概率,對于 ?b∈BF有式(6)。
(6)
定義9 (附加特征先驗概率)附加特征取某一個詞語時在不同情感傾向中出現的概率,由于附加特征和基本特征之間存在依賴關系,比基本特征先驗概率的計算要復雜。對于 ?a∈AF,a=w有式(7)。
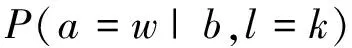
(7)
其中b為a對應的基本特征,參見表2。P(a=w|b,l=k) 的計算公式為式(8)。
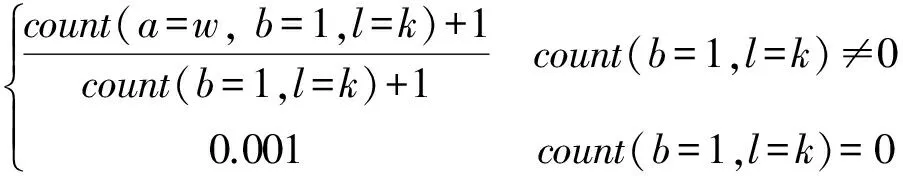
(8)
公式(6)和(8)中的count(*) 為決策表DT中滿足 * 的對象的計數,采用加一平滑避免零概率對其他后驗概率的影響。在公式(8)中,當count(b=1,l=k)=0,count(a=w,b=1,l=k)=0, 于是設定一個很小的值0.001。
定義10 (特征組合后驗概率)當若干特征組合出現時,詞語屬于不同情感傾向的概率。通常認為特征之間是相互獨立的,但是本文中附加特征和對應的基本特征之間不獨立,當附加特征被賦值時,對應的基本特征必然取值為1。特征組合F的后驗概率為式(9)。
(9)
其中δ(F∩AF) 表示特征組合F中的附加特征集合對應的基本特征集合,F(a) 表示特征組合F中附加特征a的取值,P(l=k) 計算公式為式(10)。
(10)
樸素貝葉斯分類方法根據最大的特征組合后驗概率確定詞語的情感傾向。但是在實際應用時,數據中含有的噪聲或者算法1的假設都可能導致后驗概率之間的差異性不明顯。當差異性不明顯時,拒絕決策(通常賦值為0),否則決策很可能是錯誤的。
利用實際標準差和最大標準差來判斷后驗概率是否具有明顯的差異性。最大標準差和實際標準差計算公式如式(11)和(12)所示。
(11)
(12)
根據公式(13)確定詞語的情感傾向:
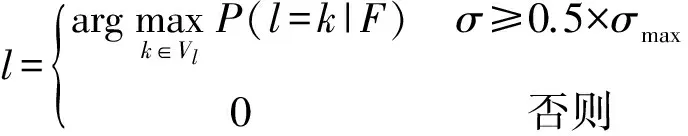
(13)
貝葉斯分類的完整過程見算法4。

算法4 基于貝葉斯分類的情感傾向計算輸入:不相容決策表DT=(U,C∪D,V,f),特征組合F輸出:給定F下的詞語的情感傾向(1)(2)(3)(4)(5)根據DT和公式(6)計算基本特征的先驗概率;根據DT和公式(7)計算附加特征的先驗概率;根據公式(9)計算特征組合F的后驗概率;根據公式(11)和(12)分別計算最大標準差和實際標準差;根據公式(13)確定詞語的情感傾向并返回。
3 強語義模糊性詞語“好”的情感分析
3.1 存在的問題 從分詞及詞性標注和依存句法分析角度體現研究的必要性。分詞及詞性標注工具采用了ICTCLAS*http://ictclas.nlpir.org/、HIT LTP*http://ir.hit.edu.cn/ltp/和FudanNLP*http://code.google.com/p/fudannlp/,HIT LTP和Stanford Parser*http://nlp.stanford.edu/software/lex-parser.shtml用于句法分析。
例1 “還好退了”
ICTCLAS結果(A):還/d 好/a 退/v 了/y
HIT LTP結果(B): 還/d 好/a 退/v 了/u
FudanNLP結果(C):還/副詞 好/副詞 退/動詞 了/時態詞
結果A和B均認為“好”為形容詞,C認為是副詞,最好的結果應該是“還好”整體作為一個副詞。由于形容詞“好”一般作為褒義詞,結果A和B導致情感誤判。
例2 “設置好都不用20分鐘”
ICTCLAS結果(A):設置/v 好/a 都/d 不/d 用/v 20/m 分鐘/q
HIT LTP結果(B): 設置/v 好/a 都/d 不/d 用/v 20/m 分鐘/q
FudanNLP結果(C):設置/動詞 好/趨向動詞 都/副詞 不/副詞 用/動詞 20/數詞 分鐘/量詞
三個結果中只有C給出了更為準確的詞性,趨向動詞“好”不體現感情色彩。結果A和B卻因為形容詞性“好”而體現褒義色彩,導致情感誤判。
例3 “維修站的服務好差”
ICTCLAS結果(A):維修/v 站/v 的/u 服務/v 好/a 差/a
HIT LTP結果(B): 維修站/n 的/u 服務/v 好/a 差/a
FudanNLP結果(C):維修站/名詞 的/結構助詞 服務/名詞 好差/名詞
三個結果均沒有標注最好的結果“好/d 差/a”。如果不考慮情感強度,結果A和B認為是中性;如果考慮情感強度(“好”大于“差”),則為褒義。結果C將“好差”整體作為一個詞,指“服務的好和差”,體現中性色彩。
從這三個例子看出,三個軟件的詞性標注結果不太一致,僅僅通過表面的詞性來確定“好”的感情色彩也會有失偏頗。如果僅僅依賴詞性不能滿足要求,是否可以借助依存句法來解決這個問題呢?仍然對這三個例子進行分析,抽取其中與“好”有關的依存關系。
對于例1,HIT LTP的結果: ADV(退, 好),Stanford Parser的結果: advmod(退, 還好)。兩者均認為“好”出現在狀中結構中的副詞,不體現感情色彩,符合實際情況。
對于例2,HIT LTP的結果: CMP(設置, 好),Stanford Parser的結果: dep(設置, 好)。前者為述補結構,后者識別為非定義的依賴關系,均不體現感情色彩,符合實際情況。
對于例3,HIT LTP的結果: ADV(差, 好),Stanford Parser的結果: nsubj(好, 服務)、root(ROOT, 好)、comod(好, 差)。前者正確判斷,而后者句法分析錯誤,導致情感誤判。
依存句法分析在一定程度上解決了問題,但是還存在局限性,如句法分析不正確會導致情感誤判,而且需要付出一定的時間代價。因此,可以僅僅使用ICTCLAS,然后通過消除語義模糊性來確定“好”是否表達情感。
以強語義模糊性詞語“好”為例,將本文所提出的框架用于消除“好”的語義模糊性,將其轉化為二值分類問題,即表達褒義感情色彩和不表達感情色彩。根據框架,詳細介紹“好”的特征表示、決策規則生成和特征組合后驗概率計算三個過程。
3.2 “好”的特征表示
將實驗數據集整合為一個訓練語料。根據表1獲取“好”的基本信息:
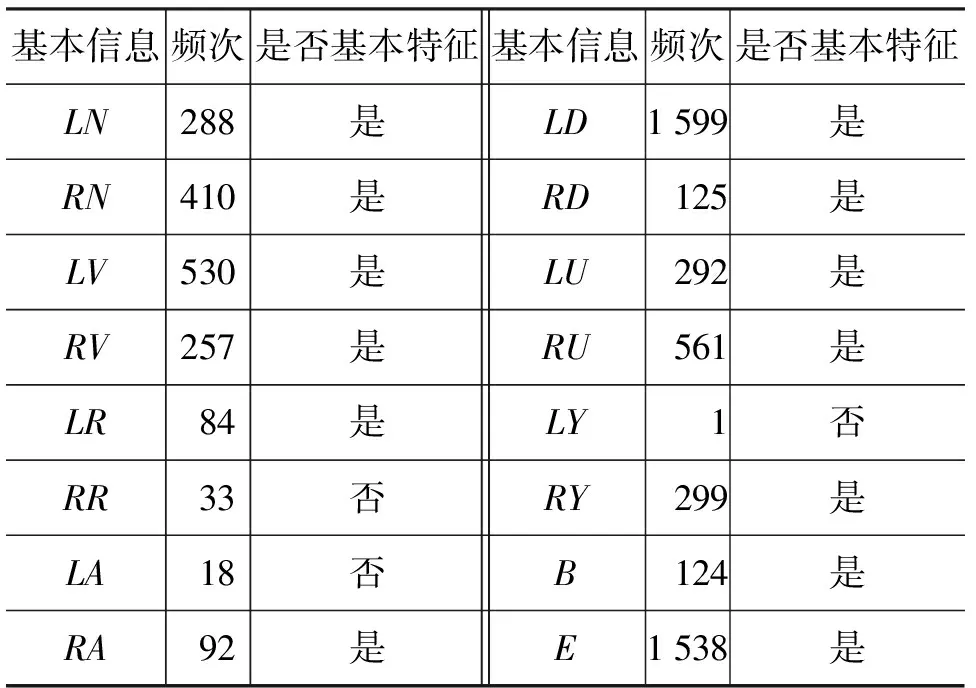
表3 “好”的基本信息
根據公式(1),選擇13個基本特征,并從中選擇LU、RU和RY為其設置附加特征LUW、RUW和RYW, 最終得到“好”的16個特征。參照公式(2),計算三個附加特征的值域如表4所示(其中“出現次數”指附加特征取對應詞語的次數)。
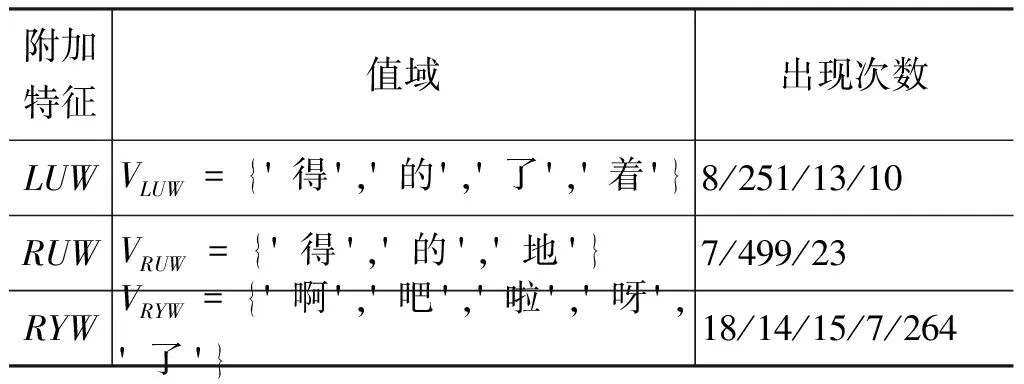
表4 “好”的附加特征

3.3 “好”的決策規則
從表5所列的6條規則來看,十分符合實際情況,說明利用粗糙集抽取的規則能夠消除一定的語義模糊性。
3.4 “好”的特征組合概率
27條規則很難覆蓋詞語“好”發生的所有語言現
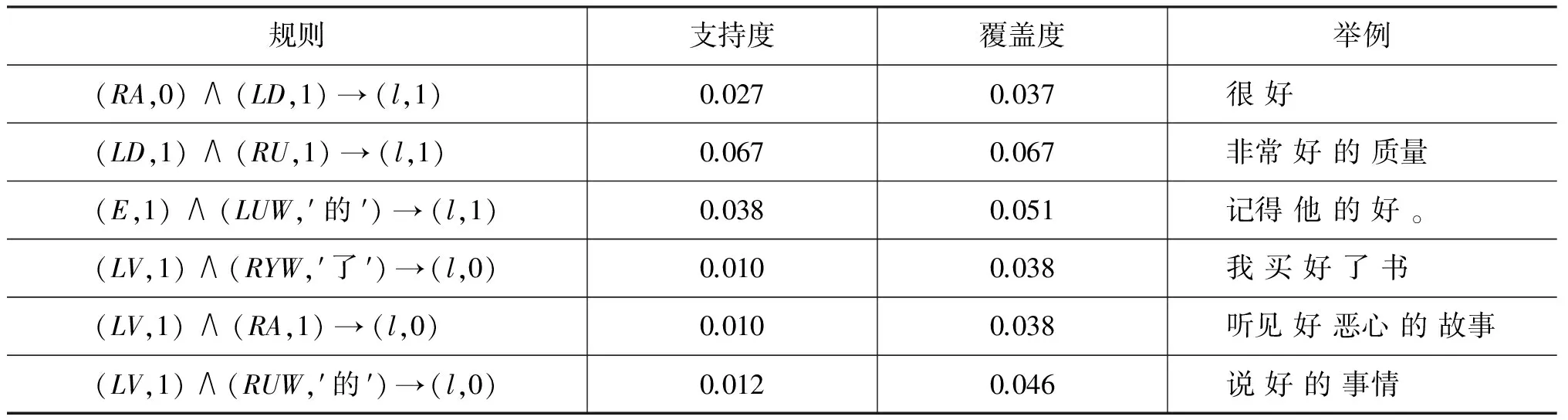
表5 “好”的決策規則
象。當無法匹配到任何規則時,使用貝葉斯分類方法消除“好”的語義模糊性。
將表5中的規則前件轉化為特征組合F, 根據算法4計算這些特征組合下的詞語情感傾向,并補充其他兩條規則不能覆蓋的特征組合情況,如表6所示。σmax=0.5, 第5個和第6個如果不考慮標準差則導致誤判,前6個特征組合的識別結果與表5完全一致。貝葉斯分類器對最后兩個特征組合也能夠正確判斷。對于F={RV,LUW(′了′)}, 例如,“休息 完 了 好 學習”中的“好”僅僅表達“可以”的意思;對于F={LD,RYW(′啊′)}, 例如,“很 好 啊”中的“好”表達褒義情感。

表6 “好”的特征組合概率
3.5 “好”字句的情感分析
將句子中含有“好”字的句子稱為“好”字句。分詞和詞性標注后如果含有獨立的詞語“好”,則需要消除“好”的語義模糊性。通過更新“好”的詞性標記來實現,見算法5,如果詞性標記為NULL,則說明“好”不體現褒義情感,否則為褒義詞。
句子中其他情感詞語采用一般方法處理。圖2給出了“好”字句的情感分析流程。

算法5 更新“好”的詞性標記輸入:不相容決策表DT=(U,C∪D,V,f),特征組合F輸出:“好”的詞性標記POS(′好′)(1)(2)(3)(4)(5)根據DT使用粗糙集屬性約簡生成決策規則;根據DT生成貝葉斯分類器;如果F和某條決策規則匹配,當規則后件l=1時,POS(′好′)=′a′,否則POS(′好′)=′NULL′;轉至第(5)步;根據F和貝葉斯分類器,如果l=1時,POS(′好′)=′a′,否則POS(′好′)=′NULL′;返回POS(′好′)。
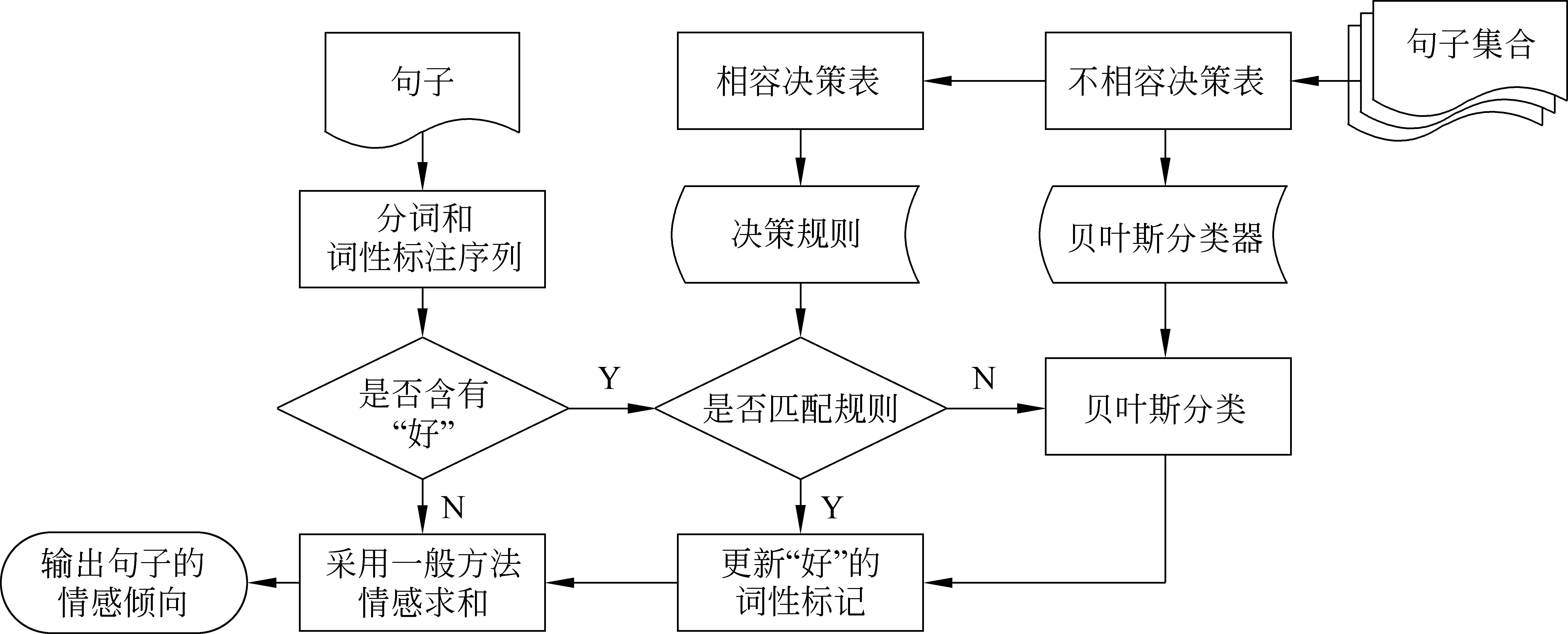
圖2 “好”字句的情感分析
4 實驗結果與分析
4.1 實驗數據 實驗數據有COAE2012[17]任務1的數據集,記作COAE,分別標注了來源于電子和汽車兩個領域的1 200條句子;SEMEVAL2010[18]任務18的數據集,記作SEMEVAL,主要是含有情感歧義形容詞的句子,共計2 917條;中科院譚松波提供的情感語料*http://www.searchforum.org.cn/tansongbo/senti_corpus.jsp,本文使用了其中正負類各2 000篇的書籍和電腦評論語料,記作TAN。詳細信息如表7所示。
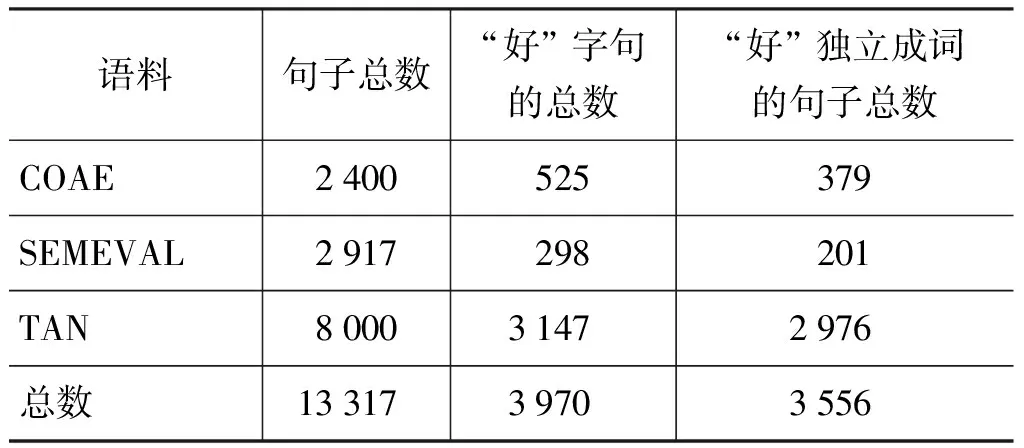
表7 語料統計情況
從表7可以看出,“好”字句在三個語料中的出現比例分別約為0.2、0.1和0.4。COAE和TAN涉及的都是產品評論,“好”出現的情況要明顯多于SEMEVAL。此外,這些“好”字句中的“好”絕大部分都是獨立成詞,比例達到90%。
以COAE的525條“好”字句為例,用ICTCLAS分詞得到詞序列,對這些詞序列中“好”的相鄰信息進行統計,采用IBM Word Cloud*http://www-958.ibm.com/software/data/cognos/manyeyes/page/Word_Cloud_Generator.html展示如圖3所示。

圖3 COAE語料上“好”的詞云圖
圖3表明程度副詞修飾“好”的情況出現最多,而容易產生歧義的“最好”、“還好”、“要好”也十分明顯。此外,“好”和動詞搭配的情況也不少,由于各個動詞不一樣,詞云圖上不夠突出。該圖也進一步說明了研究強語義模糊性情感詞語的必要性。
4.2 實驗設置
預處理: 采用ICTCLAS分詞和詞性標注,并利用標點(不含頓號和引號)切分子句。
情感詞典: 在情感詞匯本體[19]基礎上,加入自己根據《學生褒貶義詞典》整理的中文褒貶詞*http://tjzhifei.github.io/resources/bbycd.zip,并補充一些日常用語,最終得到含有28 567個條目的褒貶詞典。
否定副詞: 否定副詞的出現會改變情感傾向,僅考慮情感詞語周圍3個詞之內的否定副詞,共計65個。
程度副詞: 程度副詞會加強或者減弱情感,僅考慮情感詞語周圍3個詞之內的程度副詞,但不改變情感傾向,共計140個。
特殊句式: 對于讓步和轉折句,不考慮讓步部分的情感,僅考慮轉折部分的情感;對于假設、目的和條件句,不考慮體現的情感。本文中表轉折的詞12個,表讓步的詞6個,表假設的詞20個,表目的和條件的詞分別是4個和6個。
評價指標: 對“好”字句進行情感分類,采用精確率 Pre 、召回率 Rec 和 F1值三個評價指標(此處均為微平均)。
情感分析方法: 實驗使用了四種情感分析方法。兩種基準方法是簡單的情感值求和(記作Baseline1)、融合特殊句式的情感值求和(記作Baseline2)[20]。這兩種方法均考慮了否定副詞和程度副詞,但是后者還考慮了特殊句式。在這兩種基準方法的基礎上,加入消除“好”的語義模糊性過程得到對應的兩種方法,記作Defuzz1和Defuzz2。
4.3 實驗結果
4.3.1 Baseline1和Defuzz1的性能比較
將三個語料整合為一個全語料,記作ALL。Baseline1和Defuzz1在全部4個語料上的分類結果如圖4所示。
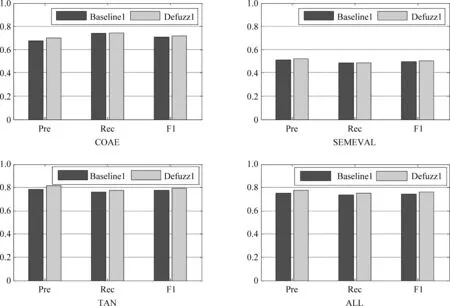
圖4 Baseline1和Defuzz1的比較
在4個語料上,Defuzz1的各項指標都不低于Baseline1。從全語料ALL上看,Defuzz1的 F1值高出Baseline1約兩個百分點。主要原因在于Defuzz1消除了“好”的語義模糊性,例如,Defuzz1能夠正確識別如下例子,但是Baseline1卻因為“好/a”的出現而誤判。
那/r 就/d 考慮/v 好/a 了/y
傳閱/v 了/u 好/a 一陣子/m
配/v 好/a 多/a 小/a 配件/n
已經/d 寫/v 好/a 的/u 代碼/n
注: 均來自實驗數據集中真實句子的ICTCLAS分詞結果。
4.3.2 Baseline2和Defuzz2的性能比較
Baseline2和Defuzz2在全部4個語料上的分類結果如圖5所示,顯然Defuzz2的各項指標均要高于Baseline2。從全語料ALL來看,Defuzz2的 F1值高出Baseline2約1.5個百分點。對于上一節的例子,Defuzz2能夠正確識別,但是Baseline2不能。
對于實驗效果,補充兩點: 在SEMEVAL語料上的分類效果不是很令人滿意,主要是因為該語料主要用于情感歧義形容詞(如“高”、“低”、“大”、“小”等)的分析,而這四種方法均未處理; 融入特殊句式的情感求和要優于一般的情感求和,即Baseline2優于Baseline1,Defuzz2優于Defuzz1。

圖5 Baseline2和Defuzz2的比較
4.3.3 決策表決策屬性值標注的一致性
算法1基于詞語的傾向與句子保持一致的假設來設定決策屬性值。為了說明這一假設的合理性,借助標注者間可信度來評估,本文采用Cohen的kappa指標[21]:
(14)
其中,Pr(a) 是觀測一致性,Pr(e) 是期望一致性。
實驗中認為有兩個標注者: 基于假設的標注(記作H)和基于消除語義模糊性的標注(記作D)。
兩個標注者間的列聯表,如表8所示(由于“好”的左右會出現未定義的特征,所以該表中的總數2 505低于表7中的“好”字句總數)。

表8 列聯表
公式(14)中的 Pr(a) 和 Pr(e) 分別計算如式(15)和(16)所示。
(15)
(16)
于是Pr(a)=0.7,κ=0.345, 即兩個標注的一致程度為70%,可信程度為0.345。
5 結論
消除情感詞語的語義模糊性能夠幫助確定其體現的感情色彩。本文提出了一種基于規則和統計的消除語義模糊性的框架,主要過程如下:
(1) 特征表示: 對相鄰信息進行閾值過濾,抽取基本特征和附加特征并構造決策表。
(2) 粗糙集規則生成: 將不相容決策表轉化為相容決策表;對相容決策表進行屬性約簡,生成決策規則;使用支持度和覆蓋度對規則過濾生成最終的規則。
(3) 貝葉斯分類: 根據不相容決策表計算基本特征和附加特征的先驗概率;脫離特征獨立性假設,計算特征組合出現的后驗概率;通過標準差度量后驗概率的差異程度,并結合最大后驗概率進行分類。
情感詞語“好”在漢語中頻繁使用,且具有很強的語義模糊性。本文以“好”為例具體闡述消除語義模糊性的方法,實驗表明所提的方法可以提高情感分析效果。
由于強語義模糊性詞語決策屬性值標注的可信度不高,因此如何更為準確地標注情感傾向(非人工細粒度標注)值得進一步研究。此外,使用拓展的粗糙集模型(如概率粗糙集)直接對不相容決策表進行處理,在生成確定性規則的同時生成不確定性規則,不確定性規則也將有助于消除語義模糊性。
[1] 姚天昉, 程希文,徐飛玉. 文本意見挖掘綜述[J]. 中文信息學報, 2008, 22(3): 71-80.
[2] 趙妍妍, 秦兵, 劉挺. 文本情感分析[J]. 軟件學報, 2010, 21(8): 1834-1848.
[3] Bollen J, Mao HN, Zeng XJ. Twitter Mood Predicts the Stock Market [J]. Journal of Computational Science, 2011, 2(1): 1-8.
[4] Tumasjan A, Sprenger TO, Sandner PG, et al. Predicting Elections with Twitter: What 140 Characters Reveal about Political Sentiment[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media, 2010: 178-185.
[5] Liu ZY, Chen XX, Sun MS. Mining the Interests of Chinese Microbloggers via Keyword Extraction [J]. Frontiers of Computer Science, 2012, 6(1): 76-87.
[6] Pang B, Lee L. Opinion Mining and Sentiment Analysis [M]. Foundations and Trends in Information Retrieval, 2008, 2(1-2): 1-135.
[7] Liu B. Sentiment Analysis and Opinion Mining [M]. Synthesis Lectures on Human Language Technologies, 2012, 16: 1-167.
[8] Narayanan R, Liu B, Choudhary A. Sentiment Analysis of Conditional Sentences[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, 2009: 180-189.
[9] 楊源, 林鴻飛. 基于產品屬性的條件句傾向性分析[J]. 中文信息學報, 2011, 25(3): 86-92.
[10] Ganapathibhotla M, Liu B. Mining Opinions in Comparative Sentences[C]//Proceedings of the 22nd International Conference on Computational Linguistics, 2008: 241-248.
[11] 黃小江,萬小軍,楊建武,等. 漢語比較句識別研究[J]. 中文信息學報, 2008, 22(5): 30-38.
[12] 孫秋秋. “好”在語義上的模糊性與確定性[J]. 遼寧大學學報(哲學社會科學版), 1982, 1: 70-76.
[13] 朱嫣嵐,閔錦, 周雅倩,等. 基于HowNet的詞匯語義傾向計算[J]. 中文信息學報, 2006, 20(1): 14-20.
[14] 陳岳峰,苗奪謙,李文,等. 基于概念的詞語情感傾向識別方法[J]. 智能系統學報, 2011, 6(6): 489-494.
[15] 張志飛, 苗奪謙. 基于粗糙集的文本分類特征選擇算法[J]. 智能系統學報, 2009, 4(5): 453-457.
[16] 苗奪謙, 李道國. 粗糙集理論、算法與應用[M]. 北京: 清華大學出版社, 2008.
[17] 劉康, 王素格, 廖祥文, 等. 第四屆中文傾向性分析評測總體報告[R]. 第四屆中文傾向性分析評測論文集, 2012: 1-32.
[18] Wu YF, Jin P. SemEval 2010 Task 18: Disambiguating Sentiment Ambiguous Adjectives[C]//Proceedings of the 2010 Evaluation Exercises on Semantic Evaluation, 2010: 81-85.
[19] 徐琳宏, 林鴻飛, 潘宇, 等. 情感詞匯本體的構造[J]. 情報學報, 2008, 27(2): 180-185.
[20] 張志飛,李飏,衛志華,等.中文否定句的情感傾向性分析[R].第五屆中文傾向性評測論文集,2013:111-120.
[21] Cohen J. A Coefficient of Agreement for Nominal Scales [J]. Educational and Psychological Measurement, 1960, 20(1): 37-46.
Sentiment Analysis with Words of Strong Semantic Fuzziness
ZHANG Zhifei1,3, MIAO Duoqian1, YUE Xiaodong2, NIE Jian-Yun3
(1. Department of Computer Science and Technology, Tongji University, Shanghai 201804, China; 2. School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China; 3. Department of Computer Science and Operations Research, University of Montreal, Montreal, Canada)
Some frequent sentiment words have strong semantic fuzziness, i.e., have ambiguous sentiment polarities. These words are particularly problematic in word-based sentiment analysis. In this paper, we design an approach to deal with this problem by combining rough set theory and Bayesian classification. To determine the sentiment polarity of a fuzzy word, we use a set of features extracted from its context of utilization. Decision rules based on the features are derived using rough sets. In case the rules fail to classify a case, a Bayes classifier is used as complement. We investigate the case of “HAO” in Chinese—a very frequent sentiment word, but with many different meanings. The experimental results on several datasets show that our combined method can effectively cope with the semantic fuzziness of the word and improve the quality of sentiment analysis.
sentiment analysis; semantic fuzziness; rough set theory; Bayesian classification

張志飛(1986—),博士,博士后,主要研究領域為自然語言處理和情感分析。E?mail:tjzhifei@163.com苗奪謙(1964—),博士,教授,主要研究領域為粒計算和機器學習。E?mail:dqmiao@tongji.edu.cn岳曉冬(1980-),博士,講師,主要研究領域為軟計算和數據挖掘。E?mail:yswantfly@gmail.com
1003-0077(2015)02-0068-11
2013-06-27 定稿日期: 2013-10-22
國家自然科學基金(61273304,61103067);高等學校博士學科點專項科研基金(20130072130004)
TP391
A
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
