四種坐標函數(shù)對流式細胞術(shù)數(shù)據(jù)可視化的影響
2015-04-18 02:38:26杜慶華李慶山許艷麗
海南醫(yī)學 2015年15期
杜慶華,李慶山,許艷麗
(廣州醫(yī)科大學附屬廣州市第一人民醫(yī)院血液內(nèi)科,廣東 廣州 510180)
四種坐標函數(shù)對流式細胞術(shù)數(shù)據(jù)可視化的影響
杜慶華,李慶山,許艷麗
(廣州醫(yī)科大學附屬廣州市第一人民醫(yī)院血液內(nèi)科,廣東 廣州 510180)
目的 研究流式細胞術(shù)數(shù)據(jù)可視化中四種常見坐標函數(shù)的特點,探討這四種坐標函數(shù)在數(shù)據(jù)可視化中的應用。方法對比分析線性、對數(shù)、HyperLog以及Logical四個坐標函數(shù)曲線的特點,使用不同坐標函數(shù)對同一個數(shù)據(jù)使用散點圖進行顯示,對比圖形顯示的差異。結(jié)果線性函數(shù)對數(shù)據(jù)呈等比例顯示,但動態(tài)范圍不足。對數(shù)函數(shù)能拉伸1附近的數(shù)值,壓縮顯示數(shù)值大的數(shù)值,但不能顯示小于1的值。HyperLog與Logical函數(shù)數(shù)值小的時候近似線性顯示,數(shù)值大時近似對數(shù)顯示。結(jié)論不同的坐標函數(shù)有不同的特點,在進行流式細胞術(shù)數(shù)據(jù)分析時,要根據(jù)需要選擇相應的坐標函數(shù)進行顯示。
流式細胞術(shù);坐標函數(shù);數(shù)據(jù)可視化
數(shù)據(jù)可視化是流式細胞術(shù)數(shù)據(jù)分析中的一個重要環(huán)節(jié),數(shù)據(jù)通過圖形顯示,然后才能通過設(shè)門操作進行進一步分析。流式數(shù)據(jù)的顯示樣式有直方圖、散點圖、等高圖或者密度圖等。每個細胞的熒光強度數(shù)據(jù)要在圖中顯示均需要通過坐標函數(shù)計算其位置,因此坐標函數(shù)的選擇會直接影響圖形的形狀。流式細胞術(shù)中常用的坐標有線性坐標、對數(shù)坐標以及其他對數(shù)衍生的坐標。由于細胞表面及內(nèi)部分子表達的差異很大,這些數(shù)據(jù)很難通過線性坐標顯示[1-2],因此一直以來使用流式細胞術(shù)進行免疫表型分析基本都使用對數(shù)坐標以顯示數(shù)據(jù)。但因為對數(shù)無法恰當?shù)仫@示小于1的數(shù)據(jù),故Bagwell及Parks建議使用對數(shù)衍生函數(shù)進行坐標轉(zhuǎn)換[3-4]。而這些坐標函數(shù)間特性的比較暫時未見詳細報道。本文將深入探討不同坐標函數(shù)的特點,為坐標函數(shù)的選擇提供指引。
1 材料與方法
1.1 儀器及軟件 流式細胞儀為FACS Canto (美國BD公司),數(shù)據(jù)為常規(guī)淋巴細胞亞群臨床檢測的流式數(shù)據(jù),軟件使用本實驗室自行研發(fā)的流式數(shù)據(jù)分析軟件CFCS(軟件著作權(quán)登記號:2010SR064983)。
1.2 方法
1.2.1 函數(shù)曲線的繪制 對數(shù)函數(shù)及其反函數(shù)為:
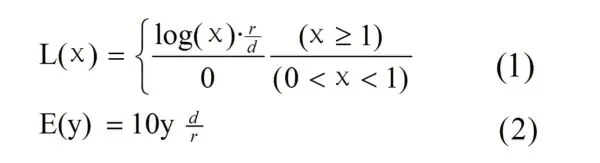
其中r為數(shù)據(jù)的分辨率,d為動態(tài)范圍的數(shù)量級。HypherLog為隱函數(shù)[3],故僅能寫出其反函數(shù):

因此在進行HypherLog函數(shù)運算時,必須通過其反函數(shù)進行求根運算。函數(shù)中b為相關(guān)系數(shù),是影響線性范圍與對數(shù)范圍的參數(shù)。當b=0時曲線最接近對數(shù)[3]。
Logical與HypherLog同樣是隱函數(shù)[4-5],其反函數(shù)為:

其中M為圖形顯示寬寬的數(shù)量級,而W=2p log (p)/(p+1),為線性范圍的寬度,其值可以根據(jù)以下公式求出:
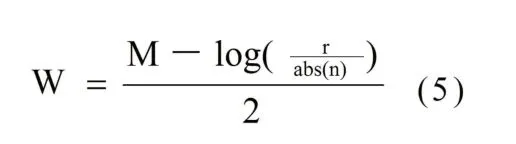
其中n為負值范圍參考點的值。
1.2.2 坐標函數(shù)曲線的繪制 使用MATLAB7.0繪制線性、對數(shù)函數(shù)、HyperLog函數(shù)以及Logical函數(shù)的函數(shù)曲線。
1.2.3 不同坐標函數(shù)對圖形的影響 同一個數(shù)據(jù)在CFCS上分別使用線性坐標、對數(shù)坐標、HyperLog以及Logical顯示,并對比四者圖形的區(qū)別。
2 結(jié)果
2.1 不同的坐標函數(shù)曲線的特點 從函數(shù)曲線發(fā)現(xiàn)線性坐標能顯示整個實數(shù)域的數(shù)據(jù),且具有對稱性。因其等比例的特性,當數(shù)據(jù)動態(tài)范圍較大時會使數(shù)值小的數(shù)據(jù)被壓縮,造成顯示效果不佳。對數(shù)坐標能保證數(shù)值小數(shù)據(jù)的顯示空間,但其缺點是僅僅能顯示≥1的數(shù)據(jù),對于<1的數(shù)值全按0來處理。HyperLog與Logical能顯示實數(shù)域的數(shù)據(jù),且二者在數(shù)值較小的時候函數(shù)曲線接近線性,在數(shù)值較大的時候接近對數(shù)曲線(見圖1)。

圖1 線性、對數(shù)、HyperLog以及Logical的函數(shù)曲線
2.2 不同的坐標函數(shù)對流式數(shù)據(jù)顯示的影響 通過使用不同坐標顯示相同的免疫熒光數(shù)據(jù),發(fā)現(xiàn)線性坐標顯示時細胞群體往往聚集在數(shù)軸的一端,難以對群體進行區(qū)分。對數(shù)坐標顯示免疫熒光實驗的數(shù)據(jù)時,細胞群體分布比較清晰,但是進行多色熒光分析進行補償后,有8%的細胞堆疊在基線上,造成視覺誤差,容易對分析結(jié)果造成影響。Logical與HypherLog兩者顯示效果無顯著差異,均能很好地控制堆疊在基線上細胞的數(shù)量,細胞群體分布清晰,補償后群體離散程度較對數(shù)坐標明顯(見圖2)。

圖2 使用4種坐標函數(shù)對同一個數(shù)據(jù)生成散點圖的比較
3 討論
線性坐標就是把數(shù)據(jù)直接按比例顯示在圖形上,其優(yōu)點是簡單直接,能顯示實數(shù)域的所有數(shù)據(jù),一般用于DNA含量的的測定,如細胞周期分析。但細胞表面分子表達情況差異相當大,需要極寬的動態(tài)范圍才能顯示這類型的數(shù)據(jù),而且這類型的數(shù)據(jù)低熒光強度群體離散程度小并近似正態(tài)分布,高熒光強度群體離散程度大接近對數(shù)正態(tài)分布。線性坐標顯示動態(tài)范圍寬的數(shù)據(jù)時,會壓縮數(shù)值小數(shù)據(jù)的顯示范圍,造成細胞群體往往聚集在數(shù)軸的一端。而對數(shù)坐標能拉伸數(shù)值小數(shù)據(jù)的顯示范圍,壓縮數(shù)值大的數(shù)據(jù),擁有較寬的動態(tài)范圍,因此對數(shù)坐標比線性坐標更適合顯示免疫熒光的數(shù)據(jù)。但是對數(shù)坐標的缺陷是無法對<1的值進行變換,因此一般對于<1的值轉(zhuǎn)換為0。
在實際應用中為了消除通道間的熒光滲漏,往往需要對數(shù)據(jù)進行補償運算,該運算是多個通道間的減法運算。運算過程中會把某一通道的檢測誤差引入到其他通道中,因此會造成數(shù)據(jù)離散增大,如果細胞群體被影響通道的熒光強度較低時,數(shù)據(jù)的離散將造成<1甚者負值數(shù)據(jù)的產(chǎn)生,這些數(shù)據(jù)在對數(shù)坐標中堆疊在基線下,使該處細胞密度異常增高,造成假群體的產(chǎn)生[4,6]。從圖2中我們可看到8%的細胞堆在x坐標上。如果設(shè)門分析時忽略了這些細胞,將對結(jié)果造成一定的影響。為了克服對數(shù)坐標的這些缺陷,Parks提出理想的坐標函數(shù)應具備以下特點:(1)函數(shù)可對不同的數(shù)據(jù)進行顯示的優(yōu)化;(2)為了提供足夠?qū)挼膭討B(tài)范圍,更好地顯示高熒光強度的對數(shù)正態(tài)分布數(shù)據(jù),函數(shù)應在隨數(shù)值增大逼近對數(shù)曲線;(3)函數(shù)應在接近0的區(qū)域?qū)ΨQ并近似線性分布,這樣更適合顯示低熒光強度正態(tài)分布的數(shù)據(jù);(4)線性區(qū)域應盡可能平滑地向?qū)?shù)區(qū)域過渡,以避免扭曲地顯示數(shù)據(jù);(5)線性化強度應隨線性范圍增大而增大[4]。
Bagwell及Parks分別提出了HypherLog與Logical函數(shù)。這兩個函數(shù)的特點是能顯示負值的數(shù)據(jù),且小數(shù)值區(qū)域接近線性分布,高數(shù)值區(qū)接近對數(shù)分布,且線性區(qū)與對數(shù)區(qū)能平滑過渡。在實際顯示中通過HypherLog及Logical兩個坐標與對數(shù)坐標比較,發(fā)現(xiàn)對于熒光強度大的細胞群體差異不大。HypherLog及Logical兩個坐標下,熒光強度低的群體比對數(shù)坐標更趨于聚集,更重要的是這兩個坐標下能顯示對數(shù)坐標不能顯示的數(shù)值<1的值。此外,HypherLog及Logical能識別一些因過補償而造成細胞群體落在坐標軸上的數(shù)據(jù),并將之顯示出來。不同數(shù)據(jù)<0的值往往是不一樣的,故HypherLog與Logical需要適當調(diào)整參數(shù)使得數(shù)據(jù)能恰當?shù)仫@示。HypherLog通過相關(guān)系數(shù)b來控制線性區(qū)的斜率,b越大線性區(qū)域越寬,b為0時曲線最接近對數(shù)曲線。但Bagwell發(fā)現(xiàn)b太小會使陰性區(qū)域的原來為一群的群體在視覺上分裂為兩個,因此使用時要注意b的取值。Logical使用負值大小作為參數(shù)對曲線的先行范圍進行控制,通過公式5計算W的值,-W與W之間即為線性區(qū)域。
HypherLog的二階導數(shù)不為0而Logical為0,因此在0附近Logical比HypherLog更接近線性,且更快靠近對數(shù)曲線。從圖2實際顯示中看,這差異并不會對數(shù)據(jù)顯示分析造成很大的影響。
由于不同的參數(shù)會對顯示效果造成一定影響,因此HypherLog與Logical兩個函數(shù)的穩(wěn)定性不如對數(shù)。當進行表達模式分析(如白血病免疫學分型)的時候,細胞群體的位置及走向是極其重要的信息。當數(shù)據(jù)中含有個別極端數(shù)值時,要將其恰當顯示則需要調(diào)整HypherLog及Logical函數(shù)的參數(shù),細胞群體的形狀及位置可能因此而發(fā)生扭曲改變(特別是熒光強度低的群體),容易導致分析錯誤。
對數(shù)函數(shù)能直接運算得到結(jié)果,而HypherLog與Logical無法顯式寫出其函數(shù)形式而無法直接進行運算,因此必須對方程進行求根運算。在分析軟件中,一般使用牛頓迭代法進行求根運算,運算結(jié)果的精度隨迭代次數(shù)增加而增加。HypherLog與Logical二者運算效率遠低于對數(shù)運算。Logical運算的復雜程度大于HypherLog,故其運算效率最低。在進行大數(shù)據(jù)量的分析時我們可以預先建立一個函數(shù)表,進行運算時可通過二分查找法進行檢索,從而極大地提高運算的效率。
變異范圍小和正態(tài)分布的數(shù)據(jù)(如細胞周期分析)宜使用線性坐標顯示。免疫熒光這類動態(tài)范圍大的數(shù)據(jù)不宜使用線性顯示。如果這類數(shù)據(jù)無需考慮群體形狀走勢等信息,僅僅進行群體劃分,則直接使用HypherLog或Logical進行顯示設(shè)門即可。如果需要進行表達模式分析,建議先使用對數(shù)顯示以了解群體分布情況,再使用HypherLog或Logical進行設(shè)門,以避免負值數(shù)據(jù)的丟失。總之,不同的坐標函數(shù)有其不同的特性,對數(shù)據(jù)的顯示及分析有著重要的影響。因此我們必須對不同坐標函數(shù)的特性有所了解,分析時使用不同的坐標函數(shù)顯示數(shù)據(jù),才能對數(shù)據(jù)有更全面的認識,以避免坐標函數(shù)選擇不當而造成的視覺誤差,進而影響分析結(jié)果。
[1]Muirhead KA,Schmitt TC,Muirhead AR.Muirhead,determination of linear fluorescence intensities from flow cytometric data accumulated with logarithmic amplifiers[J].Cytometry,1983,3(4):251-256.
[2]Watson JV,Chambers SH,Smith PJ.A pragmatic approach to the analysis of DNA histograms with a definable G1 peak[J].Cytometry,1987,8(1):1-8.
[3]Bagwell CB.Hyperlog-a flexible log-like transform for negative,zero,and positive valued data[J].CytometryA,2005,64(1):34-42.
[4]Parks DR,Roederer M,Moore WA.A new"Logicle"display method avoids deceptive effects of logarithmic scaling for low signals and compensated data[J].CytometryA,2006,69(6):541-551.
[5]Moore WA,Parks DR.Update for the logicle data scale including operational code implementations[J].Cytometry A,2012,81(4): 273-277.
[6]Finak G,Perez JM,Weng A,et al.Optimizing transformations for automated,high throughput analysis of flow cytometry data[J]. BMC Bioinformatics,2010,11:546.
Effects of four scaling functions on flow cytometry data visualization.
DU Qing-hua,LI Qing-shan,XU Yan-li.
Department of Hematology,Guangzhou First People's Hospital,Guangzhou Medical University,Guangzhou 510180, Guangdong,CHINA
ObjectiveTo explore the features of four scaling functions,and investigate the selection of 4 scaling functions in data visualization for flow cytometry.MethodsWe compared the features of 4 function curves, and dot plots from a same data file in 4 different scaling functions.ResultsLinear function displays data in a manner of proportion,but it is insufficient in dynamic range.Logarithmic function can stretch displaying the data value near zero,and can compress displaying the large data value,but it can not display data value less than zero.HyperLog and Logical function can display small data value similar to linear distribution,and display large data value similar to near logarithm.ConclusionThere are different features in different scaling functions.We should choose correct scaling function to display in data analyzing of flow cytometry.
Flow cytometry;Scaling function;Data visualization
R446
A
1003—6350(2015)15—2259—03
10.3969/j.issn.1003-6350.2015.15.0814
2015-03-02)
2013年廣東省自然科學基金(編號:S2013010016726)
李慶山。E-mail:qingshanli@hotmail.com
