網(wǎng)絡購物小數(shù)定律在大數(shù)據(jù)和EWA學習模型下的修正
2015-02-18 04:57:08龔誼承徐一娉
統(tǒng)計與決策 2015年11期
龔誼承,徐一娉
(武漢科技大學a.理學院;b.冶金工業(yè)過程系統(tǒng)科學湖北省重點實驗室,武漢430065)
0 引言
隨著網(wǎng)絡的發(fā)展,數(shù)據(jù)流集合的規(guī)模已從GB到PB甚至以ZB(1021)等單位來計數(shù)。學者們敏銳地注意到其規(guī)模性、即時性、非線性性和可獲得性符合大數(shù)據(jù)的特征,并開始利用大數(shù)據(jù)展開對網(wǎng)絡經(jīng)濟的探討。但是,探討如何利用大數(shù)據(jù)減少消費者可能受到虛假評價誤導而犯下小數(shù)定律錯誤的文獻尚有待發(fā)展。本文以網(wǎng)絡大數(shù)據(jù)的出現(xiàn)為契機,將網(wǎng)絡用戶評價視為帶噪音的大數(shù)據(jù),將網(wǎng)購視為消費者和商家的一種群體博弈,利用EWA學習模型分析消費者在瀏覽帶噪評價數(shù)據(jù)時從小數(shù)定律向大數(shù)定律對應的理性策略修正的過程。以期減少消費者網(wǎng)上購物的風險,或有助于政府充分利用網(wǎng)絡經(jīng)濟大數(shù)據(jù)成立市場監(jiān)管機構,引導消費者遠離“小數(shù)定律”陷阱而靠近理性決策有利于大數(shù)據(jù)時代網(wǎng)絡經(jīng)濟市場的更好運行。
1 用戶評價誤導網(wǎng)絡消費者的小數(shù)定律視角
小數(shù)定律[1]是Amos Tversky和Daniel Kahneman總結出來的一種行為經(jīng)濟學規(guī)律,用以說明人們在面臨不確定環(huán)境時,往往會違背基本的大數(shù)定律而不由自主地濫用“典型事件”導致忘記“基本概率”。在網(wǎng)絡購物行為中,消費者面臨產(chǎn)品質(zhì)量、賣家信譽等諸多不確定因素,此時他們?yōu)g覽到的一些典型用戶評價可能給他們深刻印象,進而使他們忘記正確評價賣家的信譽和產(chǎn)品的質(zhì)量需要大量的評價數(shù)據(jù)才能得到穩(wěn)定的均值,于是他們很可能受到這些典型評價數(shù)據(jù)的誤導而犯下“小數(shù)定律”的錯誤。具體地講,本文注意到評價數(shù)據(jù)量過小或者評價數(shù)據(jù)被篩選過是當今的網(wǎng)購環(huán)境下誘發(fā)“小數(shù)定律”錯誤的兩大因素。
1.1 數(shù)據(jù)量過小容易導致網(wǎng)購中的小數(shù)定律錯誤
大數(shù)定律強調(diào)樣本的數(shù)目要盡可能大,這樣其樣本均值就會收斂于真實的期望。事實上,樣本數(shù)目過小會導致樣本平均值更加不穩(wěn)定。
在網(wǎng)購前,消費者經(jīng)常難以確定網(wǎng)上商品的質(zhì)量與如商家所描述的那么好,此時購物評價對消費者的決策起到了重要的作用。筆者對某款手機在淘寶網(wǎng)上選取紅心、藍鉆、藍冠和皇冠四個等級各10家網(wǎng)店來收集數(shù)據(jù),其中淘寶網(wǎng)商家由紅心到皇冠的信用等級是由低到高的。信用評價由每一次交易成功后的買家作出,按照5顆星為好評滿分值,0顆星為最差評,超過3顆星的評價視為好評,其基本的統(tǒng)計結果見表1。
從表1可見:信用等級高的商家,其成交量基本上會更高。但并非信用等級高的商家獲得的好評率就更有優(yōu)勢:比如藍鉆網(wǎng)店評價一個月的均值為4.8,而藍冠的僅為4.75。可見,消費者依據(jù)寥寥數(shù)百條評價所呈現(xiàn)的高達97%以上的好評率而相信商品本身具有與評分相符的品質(zhì),進而做出的購買決策可能已掉入小數(shù)定律錯誤中。因為在歷史成交量小的商鋪中,其評價數(shù)據(jù)是小樣本,但消費者錯誤地運用了大數(shù)定律的結論:商品的歷史性評價代表了商品的實際品質(zhì)的平均水平。由此可見當網(wǎng)購質(zhì)量不確定時,消費者容易將從大樣本中的結論錯誤地移植到小樣本中的原因是:受到了自身所能了解的評價數(shù)據(jù)之數(shù)目的限制。
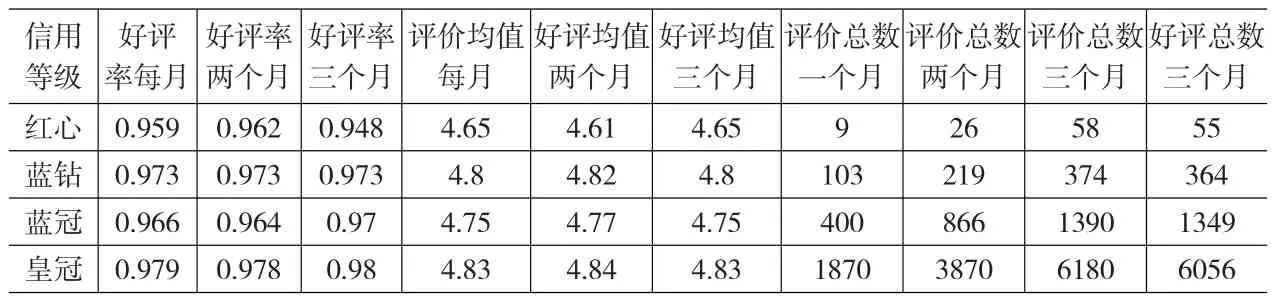
表1 淘寶網(wǎng)四種信用類型商家所獲評價的統(tǒng)計結果
1.2 被篩選的數(shù)據(jù)容易導致小數(shù)定律錯誤的產(chǎn)生
為避免小數(shù)定律誤區(qū),網(wǎng)購消費者做決策前一般會盡可能多地搜尋相關評價信息。但如果這些大量的評價信息是被篩選過的,他依然會被誤導而陷入小數(shù)定律的錯誤、偏離理性。
這個道理可以通過一位股票投資者的經(jīng)歷來說明。假設通過親身經(jīng)歷,該股票投資者發(fā)現(xiàn)一位基金經(jīng)理在過去兩年中的投資業(yè)績好于平均情況,于是他就傾向于得出這位經(jīng)理要比一般經(jīng)理優(yōu)秀的結論。然而事實可能是:他所搜集的親身經(jīng)歷的數(shù)據(jù)是他人精心篩選的,其實與基金經(jīng)理的水平無關。情況可能是這樣的:基金經(jīng)理選定某支股票,第一周發(fā)10000條短信預言其漲跌,其中5000條說該股票漲另外5000條說跌;第二周向其中說對的5000人再發(fā)一短信,其中2500條說該股票漲而另2500條說該股票跌;第三周他再向說對的2500人發(fā)短信,其中1250條說該股票會漲,另1250條說該股票會跌。最后有1250人會發(fā)現(xiàn)這位股神大哥連續(xù)3次說對該股票的漲跌,于是會得出這位經(jīng)理對該股票的漲跌預測是要比一般經(jīng)理優(yōu)秀的結論。然而仔細回顧這起事例會發(fā)現(xiàn):他得出的結論其實與該經(jīng)理的預測股票價格漲跌的真實能力無關,根本原因是其所觀測到數(shù)據(jù)是被精心篩選之后呈現(xiàn)出來的。
類似地,網(wǎng)購的消費者如果參考的消費者評價數(shù)據(jù)也是經(jīng)過商家以某種手段篩選而來的,那么即使樣本數(shù)據(jù)的規(guī)模夠大,其得到的關于商品質(zhì)量的結論依然可能是受到誤導的。
2 基于網(wǎng)絡評價大數(shù)據(jù)的小數(shù)定律修正思路
評價數(shù)據(jù)可能導致的小數(shù)定律成為影響網(wǎng)購進一步發(fā)展的阻力,因此改善這種經(jīng)濟誤區(qū)的途徑令人期待。筆者嘗試將客觀上快速發(fā)展的網(wǎng)絡大數(shù)據(jù)與主觀上調(diào)整博弈策略的EWA學習模型相結合,以期為消費者避開小數(shù)定律提供一種參考途徑。
2.1 大數(shù)據(jù)使可獲得的評價數(shù)據(jù)的樣本量和可信度同時提升
關于大數(shù)據(jù)的熱烈討論由此在學術界和商業(yè)界備受關注。雖然目前還沒有一個明確的關于大數(shù)據(jù)的定義,但是對于大數(shù)據(jù)的特征描述已經(jīng)有了一些共識,筆者采用周濤(2013)所描述的四個特點[2]:其一,數(shù)據(jù)規(guī)模巨大且持續(xù)保持高速增長;其二,數(shù)據(jù)價值的增長與規(guī)模的增長正相關;其三,數(shù)據(jù)能充分發(fā)揮其外部性并通過與某些相關數(shù)據(jù)交叉融合產(chǎn)生遠大于簡單加和的巨大價值;其四,一般研究人員和開發(fā)人員可以自如獲取數(shù)據(jù)的邏輯片段并進行分析處理。
從單個消費者的角度看,由于網(wǎng)絡消費者最初掌握的數(shù)據(jù)一般比較少,而且他們一般是單次與某個商家進行交易,所以基本屬于小樣本認識。但是他們可以通過其他人的交易經(jīng)歷來能獲得更多的評價數(shù)據(jù),以擺脫典型事件的影響。隨著網(wǎng)絡競爭的發(fā)展,網(wǎng)絡評價數(shù)據(jù)不再是某幾個大型數(shù)據(jù)門戶網(wǎng)站的專利,一般的用戶不僅是數(shù)據(jù)的生產(chǎn)者也同時可以稱為數(shù)據(jù)的利用者,比如CNNIC就提供了一種免費獲得網(wǎng)絡經(jīng)濟大數(shù)據(jù)的途徑。因此,網(wǎng)絡大數(shù)據(jù)使得消費者可以獲得的評價數(shù)據(jù)的樣本量極大地提升了。注意到在大數(shù)據(jù)時代,我們面對的數(shù)據(jù)樣本就是過去資料的總和,樣本就是總體,所以需要合適的數(shù)據(jù)分析技術[3]。為了充分挖掘出評價大數(shù)據(jù)的價值,筆者以為可以采用交叉驗證的思想,將線上評價數(shù)據(jù)集作為基礎數(shù)據(jù)集按照一定的比例來細分為訓練集和測試集,將線下評價數(shù)據(jù)集作為驗證數(shù)據(jù)集,實行線上與線下評價數(shù)據(jù)的交叉驗證。由于線下評價基本來源于消費者3度以內(nèi)的真實的社會網(wǎng)絡,其評價的可信度比較高,所以線上與線下評價數(shù)據(jù)的交叉驗證有助于提高網(wǎng)絡評價數(shù)據(jù)的可信度,從而有利于消費者對商品質(zhì)量做出更正確的判斷。
然而,在網(wǎng)絡大數(shù)據(jù)可以獲得的前提下,消費者利用其來規(guī)避小數(shù)定律誤區(qū)的過程中仍有兩個問題需要解決:其一,對賣家宣稱的同等質(zhì)量價格最低這類消息,消費者應該最少瀏覽多少相應的評價信息才能保證其作出的決策已經(jīng)走出小數(shù)定律誤區(qū)?其二,消費者從非理性決策到理性決策的演化過程如何?本文擬從博弈論的角度構建網(wǎng)絡經(jīng)濟系統(tǒng)中經(jīng)濟主體之間的網(wǎng)絡演化博弈模型,得到其演化均衡路徑。
2.2 消費者評價導致的小數(shù)定律的演化博弈分析視角
網(wǎng)購過程中,某個特定的消費者購買某個特定商家產(chǎn)品的行為可以視為一次合作博弈。
消費者考慮的是商品的質(zhì)量、價格、物流速度以及商品對自己效用的大小;而商家考慮的則是成本和收益。網(wǎng)購成功意味著合作博弈形成了合作,其對應價格下各自的收益就是一種雙方認可的分配方案。因此,消費者和某商家之間的一次交易本質(zhì)上是一次合作博弈。
考慮初始狀態(tài)下某消費者與商家之間的一次網(wǎng)購博弈。假設消費者有三種可能的策略,而商家有四種可能的策略,見表2。假設該商家當前擁有的評價數(shù)據(jù)有n條,其中好評m條,意向交易價格為p,商家刷信用的成本為c1,提供貨真價實商品的成本為c2,提供假劣商品的成本為c3(c3<c2)。類似地,假設消費者享用貨真價實商品的主觀效用為u2,享受假劣商品的效用為u3(u3<u2)。設消費評價對消費者主觀感受的積極影響系數(shù)為u1(0<u1<1),當消費者不相信評價而選擇不購買該商品時,其感受半信半疑中挽救了1-u1補償系數(shù)的一大半,假設為九成。一次靜態(tài)博弈模型如表2所示,在此理論上可計算其Nash均衡策略和收益結果。
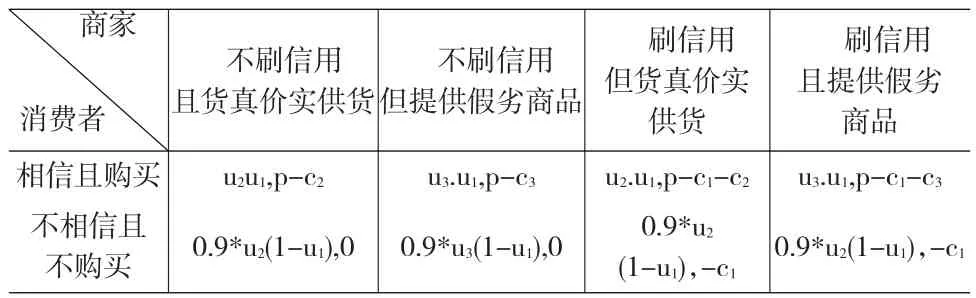
表2 初期代表性消費者與商家的一次評價接觸博弈
2.3 EWA算法的基本思想和原理
由于對商品質(zhì)量的不確定,每次博弈前消費者會參考前期消費者的評價信息來調(diào)整本次的策略,所以一次網(wǎng)購博弈是建立在局中人對網(wǎng)購群體歷史博弈結果的學習和觀察基礎上的,因此一次網(wǎng)購博弈本質(zhì)上是群體博弈演化過程中的某個狀態(tài)。消費者和商家都會通過學習來改善自己的策略,從而達到演化均衡,其學習的效果依賴于具體的策略學習機理。
目前常用到的演化決策機制有四種[4]:最優(yōu)反應動態(tài)機制、復制動態(tài)決策機制,基于隨機過程或群智能優(yōu)化算法的決策機制,以及基于神經(jīng)網(wǎng)絡或強化學習[5]的決策機制。其中,強化學習模型是最常用的兩種動態(tài)決策機制之一,它使成功的策略被加強,但沒有考慮未選擇策略的收益信息和對手的可能信念。信念學習模型[6]試圖使博弈參與者根據(jù)其他參與者先前行動的歷史事件形成對別人會如何行動的信念,根據(jù)這些信念計算各種策略的期望收益,并以較高的頻率選擇能獲得較高期望支付的策略,但沒有考慮到過去選擇成功策略對后來選擇的影響。本文采用1999年由Camerer和Chong提出的經(jīng)驗權重魅力值EWA(experience-weighted attraction)學習算法[7],該學習機理綜合了強化學習和信念學習的優(yōu)點,能更好地融合大數(shù)據(jù)評價信息,同時考慮成功策略的積極評價和不成功策略的消極評價的信念調(diào)整,比強化學習和信念學習有更好的解釋能力。
EWA學習模型的基本模型如公式(1)、(2)和(3)所示的模型。
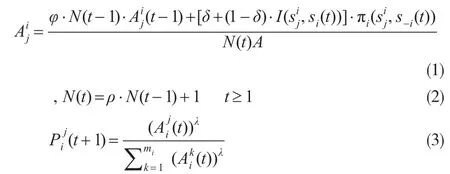
3 模擬算例分析
3.1 基于大數(shù)據(jù)和EWA學習的仿真流程
結合能掌握的評價信息,可以按照如下7個步驟來展開EWA的網(wǎng)上購物仿真。
步驟1:依據(jù)當前掌握的歷史交易評價信息,估算表2所示的博弈模型中的個參數(shù)取值,并將各種策略的初始魅力值理解為表2中的收益值,即商家利潤或消費者的效用大小;
步驟2:根據(jù)每一個策略的初始魅力值,利用(3)式計算其選擇概率;
步驟3:利用Matlab產(chǎn)生一個(0,1)之間的隨機數(shù),根據(jù)該隨機數(shù),選擇賣家和買家的策略;
步驟4:根據(jù)網(wǎng)上購物供需關系進行出清;
步驟5:賣家與買家根據(jù)出清結果計算其利潤;
步驟6:按照式(1)修改策略集合中各個策略的魅力值;
步驟7:若還沒有達到結束的條件,則返回步驟1,結合即時產(chǎn)生的評價數(shù)據(jù),更新表2中的參數(shù)一收益值,開始下一輪學習,當達到終止條件時結束,或者當樣本數(shù)據(jù)用盡時結束。
3.2 消費者與商家的靜態(tài)評價博弈案例的Nash均衡及EWA演化
選擇某款手機的銷售為研究案例,將筆者手動搜集的某一品牌手機三個月累計的四個信用等級商鋪的評價數(shù)據(jù)視為小數(shù)據(jù)樣本。由表1可得到四個等級的商家對應于博弈模型表2中的評價總數(shù)n和好評總數(shù)m。由于評價對消費者的積極影響與其好評率成正相關,但是好評數(shù)太低時的積極影響可以忽略,所以為簡單起見假設積極影響系數(shù)為u1=Max{m/n-1/2,0}。所有店鋪的手機交易價格均為p=1320元,假設消費者對正品手機和假劣產(chǎn)品的效用分別貨幣化為u2=2000和u3=320元。商家提供正品和假劣產(chǎn)品的成本分別為c2=1000元和c3=500元,刷信用的成本c1=min{0.5m,100}.分別算出四種類型商家與消費者的參數(shù)列于表3。
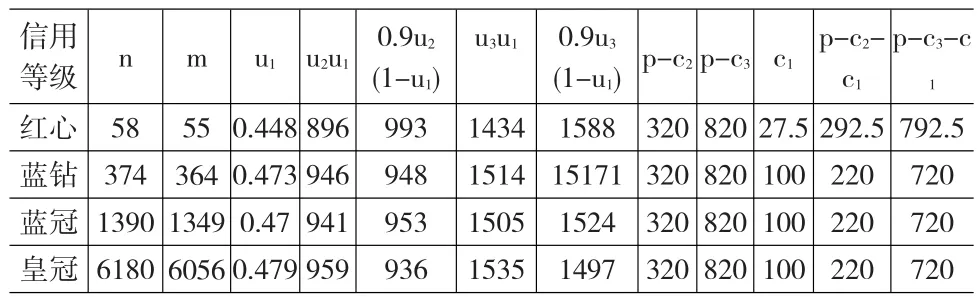
表3 四種類型消費者與商家的一次評價博弈的參數(shù)值及Nash均衡策略
由表3可以得四種類型商家與消費者對應于表2所示博弈模型的收益值,可以發(fā)現(xiàn)前種類型的博弈中均不存在占優(yōu)均衡策略。但是皇冠類型的商家,其占優(yōu)策略均衡是不刷信用且貨真價實地供貨,然而其消費者卻依然不存在占優(yōu)策略均衡。
3.3 基于大數(shù)據(jù)和EWA學習的仿真結果
考慮到網(wǎng)購消費者對過去經(jīng)驗學習的能力比較強,我們設式(2)中的魅力值增長系數(shù)ρ為0.6,但是考慮到魅力值的敏感度不太高,設式(3)中的魅力值反應敏感度λ為0.4。然后,按照上述七個步驟逐步更新每一個策略的魅力值,計算其選擇概率。結束的條件為魅力的代際更新值差別不超過0.05。
首先直接利用小樣本集進行EWA學習的仿真結果。以R軟件模擬該案例的EWA更新博弈結果,發(fā)現(xiàn)紅心、藍鉆和藍冠類型的商家與消費者的評價博弈的演化情形如圖1所示,藍冠類型的商家與消費者的評價博弈如圖2所示,其結果一直沒有穩(wěn)定的趨勢。而皇冠類型的商家與消費者的評價博弈的演化情形如圖3所示,當評價數(shù)據(jù)更新至5千次時,其選擇策略基本穩(wěn)定。生產(chǎn)者選擇不刷信用的比例約為65%,消費者選擇相信評價并做出理性決策的穩(wěn)定比例約為52%。
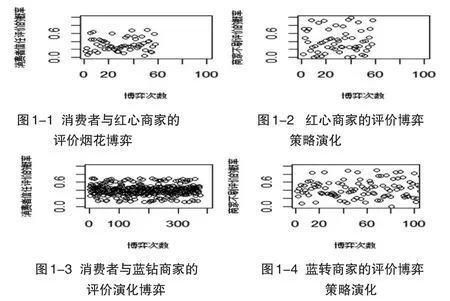
圖1 紅心與藍鉆商家與消費者的評價博弈策略演化
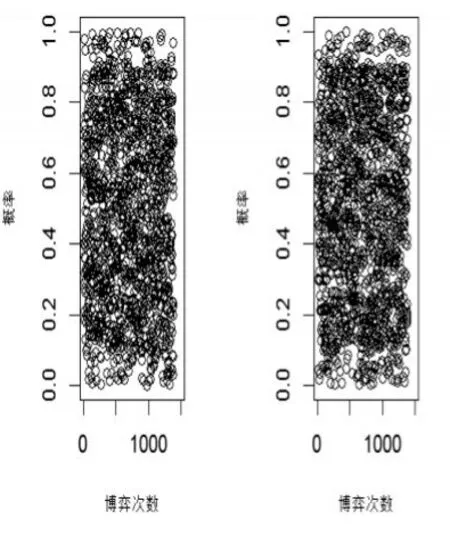
圖2 藍冠商家與消費者的評價博弈策略演化
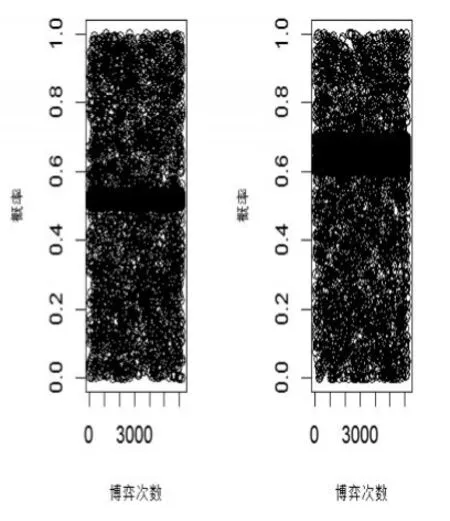
圖3 皇冠商家與消費者的評價博弈策略演化
將網(wǎng)絡可抓取的即時更新的數(shù)據(jù)視為大數(shù)據(jù),2014年3月24日到3月30日,淘寶網(wǎng)的總訪問次數(shù)達到了597824.2萬次。當前CNNIC尚未開通購物評價統(tǒng)計,其中某時間段提供某款手機的商家達到529家。利用該評價數(shù)據(jù),以R軟件模擬該案例的EWA博弈策略的演化,結果表明:藍冠類型的商家與消費者的評價博弈的演化情形如圖4所示,在數(shù)據(jù)更新至約7千次時,其選擇策略基本處于穩(wěn)定值:生產(chǎn)者選擇不刷信用的比例約為69%,消費者選擇相信評價并做出理性決策的穩(wěn)定比例約為76%。而且皇冠類型的商家和消費者的依然處于穩(wěn)定如圖4所示:生產(chǎn)者選擇不刷信用的比例約為84%,消費者選擇相信評價并做出理性決策的穩(wěn)定比例約為81%。
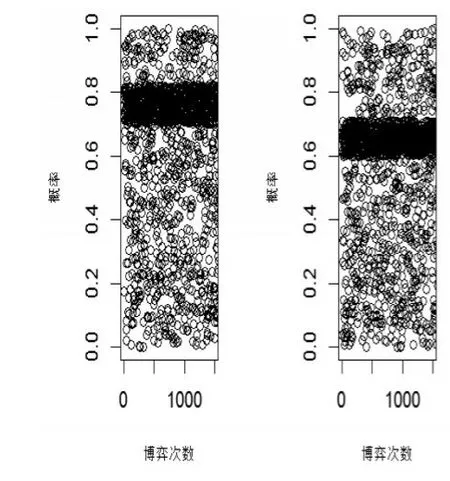
圖4 大數(shù)據(jù)下藍冠商家與消費者的評價博弈策略演化
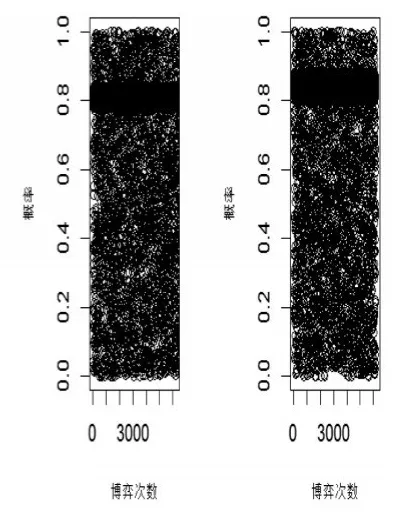
圖5 大數(shù)據(jù)下皇冠商家與消費者的評價博弈策略演化
4 結論
本文利用大數(shù)據(jù)規(guī)模巨大的優(yōu)勢、結合消費者在瀏覽帶噪音的評級信息時對于商品質(zhì)量的學習行為,從博弈策略進化學習的角度討論了消費者避開小數(shù)定律誤區(qū)的途徑。模擬結果顯示:大數(shù)據(jù)使得藍冠類型的商家與消費者的評價演化博弈由不穩(wěn)定轉化為穩(wěn)定,其臨界博弈次數(shù)約為7千次;而對于皇冠類型的商家與消費者的評價博弈,大數(shù)據(jù)下的EWA演化可以提高其良性發(fā)展的網(wǎng)購環(huán)境,其中生產(chǎn)者選擇不刷信用的比例由約65%提升為約84%,表征著商家評價的真實性提高了約19%;而消費者相信評價的穩(wěn)定比例由約52%提升為約81%,表征著消費者信任商家的提高了約29%。
然而,大數(shù)據(jù)來源的多樣性和異構性的優(yōu)勢在本文中沒有得到充分發(fā)揮。如果能充分量化評價中的文本、語音和圖像,就能夠從多維度交叉展示產(chǎn)品特征,評價的真實性將進一步大幅度得到提高,消費者因為評價信息不真實而誤入小數(shù)定律陷阱的可能將一步減少。為了使網(wǎng)購環(huán)境的進一步優(yōu)化,筆者期待著再此方面的進一步深入探討的出現(xiàn)。
[1]K.Busche,P.Kennedy.On Economists'Belief in the Law of Small Numbers[J].Economic Inquiry,1984,22(4).
[2]周濤.什么是大數(shù)據(jù)[EB/OL].http://blog.sciencenet.cn,2012-08-18
[3]朱建平,章貴軍,劉曉葳等.大數(shù)據(jù)時代下數(shù)據(jù)分析理念的辨析[J].統(tǒng)計研究,2014,31(2).
[4]龔誼承,王先甲,李壽貴.校企實習聯(lián)盟模式變遷的進化博弈模型與演化路徑[J].系統(tǒng)工程理論與實踐,2012,32(93).
[5]Roth,A E Erev,I.Learning in Extensive-form Games:Experimental Data and Simple Dynamic Models in the Intermediate Term[J].Games and Economic Behavior,1995,8.
[6]Crawford V.P.Adaptive Dynamicsin Coordination Games[J].Econometrica,1995,63.
[7]Camerer C F.Ho T H.Experience-Weighted Attraction Learning in Normal-form Games[J].Econometrica,1999,67.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
今日農(nóng)業(yè)(2020年20期)2020-12-15 15:53:19
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數(shù)學大世界(2018年1期)2018-04-12 05:39:14
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
發(fā)明與創(chuàng)新(2016年16期)2016-08-21 13:56:16
發(fā)明與創(chuàng)新(2016年21期)2016-05-17 03:57:29
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
時代英語·高三(2014年5期)2014-08-26 02:49:51
