智能電網中基于數據挖掘技術的可再生能源消費預測建模
2015-01-14 07:29:38侯晨偉謝云芳
科技視界 2015年11期
侯晨偉 謝云芳 溫 鵬
(河北農業大學機電工程學院,河北 保定071001)
1 數據挖掘理論
數據挖掘就是從海量的數據中提取隱含在其中,人們事先未知的但又是潛在有用的信息和知識,并將其表示成最終能被人理解的模式的高級過程[1-2]。數據挖掘技術從一開始就是面向應用的,不僅是面向特定數據庫的簡單檢索查詢調用,還要對這些數據進行微觀、中觀乃至宏觀的統計、分析、綜合和推理,來指導實際問題的求解。同時還可以通過發現事件間的相互關聯,對未來的活動進行預測。比如通過對空間負荷的預測,可以了解待研究地區未來的電力負荷增長走向,及其連帶一系列的社會問題如城市電網規劃、各類建筑用地及居民安置規劃等[3]。數據挖掘的數據包括數據倉庫、數據庫或其它數據源。所有的數據都需要再次進行選擇。
1.1 數據挖掘的分類
(1)根據挖掘的數據庫類型分類:每一類數據庫系統可能需要自己的數據挖掘技術。
(2)根據挖掘的知識類型分類:即根據數據挖掘的功能分類,如特征化、區分、關聯和相關分析、分類、預測、聚類、離群點分析和演變分析。一個綜合的數據挖掘系統通常提供多種 和/或集成的數據挖掘功能。
(3)根據所用的技術類型分類:這些技術可以根據用戶交互程度,或所用的數據分析方法描述。
(4)根據應用分類:不同的應用通常需要集成對于該應用特別有效的方法[1]。
1.2 數據挖掘的步驟
(1)數據收集。從數據庫中獲取基本分析所需的數據。指標數量越多,歸納研究越易發現存在的潛在規律。但若過多,符合條件的樣本就會減少,從而影響預測效果。
(2)數據預處理。包括消除噪聲、推導計算缺值數據、消除重復記錄等。可通過專用軟件的頻率分析來實現。如果同一個變量的缺失值很多,可以丟掉這個變量。
(3)數據轉換。主要目的是削減數據維數或降維,即從初始特征中找出真正有用的特征以減少數據挖掘時要考慮的特征或變量個數。主要有零維特征法和全維特征法。
(4)數據挖掘。先確定挖掘的任務或目的,如數據分類、聚類、關聯規則發現或序列模式發現等。再決定使用什么樣的挖掘算法。算法的選擇有兩個考慮因素:一是數據的特點;二是要根據用戶或實際運行系統的要求。最后實施數據挖掘操作,獲取有用的模式。
(5)結果的解釋和評估。目的是剔除冗余或無關的模式;根據需要轉換成可視模式;若不滿足用戶要求,則退回到發現過程的前面階段重來。
2 智能電網數據的特點
(1)實時性高。電力系統每時每刻都在產生大量的數據,包括反映一次運行狀態的各種數據。
(2)數據量大。除實時數據外,各種在線離線分析計算程序也會產生大量的數據。
(3)數據格式多樣。數據可能存儲于各種關系型數據庫、文本文件和二進制文件中,這些數據源往往彼此獨立,難以實現數據共享,導致大量數據冗余和不一致。
(4)歷史數據極具價值。電力系統是個連續系統,它在某時刻的運行狀態將會影響隨后的狀態或者趨勢。對歷史數據的妥善保存和深入分析勢在必行。
3 可再生能源消費預測建模
智能電網的一個重要組成部分就是各種可再生能源。風力發電、太陽能光伏發電、生物質發電、潮汐能發電、地熱能發電等等,且各類可再生能源的發電成本、電能質量及在電網中占的比重都不同。為了深入研究可再生能源的使用情況,對2001~2010年連續十年內某地區電力用戶消費的可再生能源類型進行統計,對各種可再生能源類型進行編碼:A=太陽能,B=風能,C=其他清潔能源。將電力用戶從原始數據庫中抽取出來,并編上號(1-N)。按年份進行升序排列,組成表1。
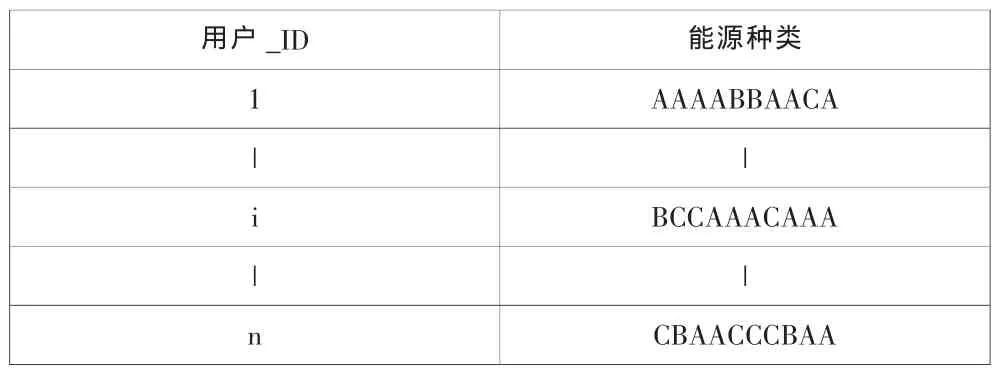
表1 特征信息庫
由相對年份來標識交易,用戶號來標識用戶屬性,則R[X][Y]唯一標識了X號用戶在Y+2009年主要使用的可再生能源類型。這里提出的N階轉移矩陣的數學基礎是馬爾科夫鏈。算法的前提是:交易是歷史相關的,其考慮程度由N決定,N階矩陣意味著考慮前N年的交易歷史。對于具有相同的前N年歷史記錄的用戶群G1和具有相同前N-1年和今年的歷史記錄的用戶群G2,若G1的前N年歷史記錄與G2的前N-1年和今年的歷史記錄相匹配,則G1在今年對能源類型的選擇分布成為G2在明年對能源類型的選擇的概率分布。
定義S(n,STRING)函數為以第n年結尾的R[X]的子串與STRING相匹配的用戶數。如S(8,AAA)是指第6、7、8年的消費的主要可再生能源類型為風能的用戶總數。為了方便起見,假定采用3階的轉移算法,并假定當前年份為N。生成數據項集I的3階全排列集合PI{AAA,BAA,CAA,AAB,BAB,CAB,AAC,BAC,…,CCC}。遍歷R數據庫,對PI的每一項STRING生成S(N,STRING)。也就是,考慮歷史記錄(考慮的深度取決于階數),對用戶的偏好性按其序列不同而分類。根據已生成的S(N,XYZ)計算得S(N-1,XY)。這也就是將上一年的用戶對消費類型的選擇作為標準。將S(N,XYZ)/S(N-1,XY)上一年份的序列XY向今年Z的轉移率作為今年序列XY向明年Z轉移的概率,即Pxy→z=S(N,XYZ)/S(N-1,XY)。從而建立預測模型的轉移矩陣P。
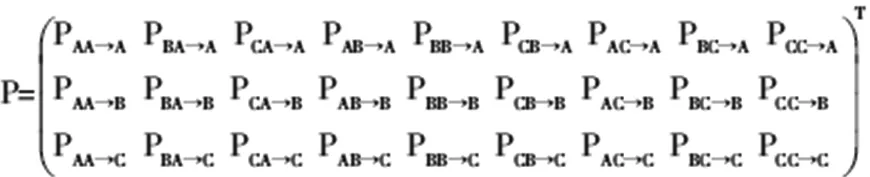
P矩陣是9*3的矩陣,其行向量對應于數據項集I,而列向量則對應于發生向量C。發生向量C就是S(N,XYZ)的用戶分布。顯然,C是個9維的向量。因而,結果向量Z=C*P是3維的對應于數據項集I的向量。這正是預測模型的預測結果。
擴展至n階的轉移模型只需將PI擴充成數據項集I的n階全排列集合。轉移矩陣P相應地擴展成3^(n-1)*3的矩陣。其中的轉移概率為:)。同樣,C 也 擴展成3^(n-1)的向量。
4 結論與展望
對于在智能電網龐雜的數據體系里開展信息分析處理工作而言,數據挖掘技術是一種行之有效的技術。它可以輔助決策者發現數據里面潛藏著的不易發現的知識和信息,也可以基于現有數據對未來進行預測。它值得電力和信息領域的研究者們攜手進行更深層次的研究。必須指出的是,構建智能電網時有必要站在更高的高度考慮問題,從信息系統的全局來看待數據挖掘與其他構件的相互關系。因為智能電網不同的參與者對信息系統有不同的需求,各個構件都有擅長的范圍。同時還應當看到,數據挖掘并不是萬能的。它是一個循環往復的過程,需要分析人員理解現有業務系統,進行細致的準備,建立模型并分析結論和預期的差別。分析人員還需要靈活設計并進行數據分析和挖掘的過程,以避免靈感的丟失。
[1]Jiawei Han,Micheline Kamber.Data Mining Concepts and Techniques[M].Morgan Kaufmann publishers,2000.
[2]W.H.Inmon,Claudia Imhoff,Ryan Sousa.Corporate Information Factory[M].Second Edition Wiley Computer Publishing,2002.
[3]Xiong Hao,Li Weiguo,Huang Yanghao,etc.Application of Comprehensive Data Mining Method Based on Fuzzy Rough Set in Spatial Load Forecasting[J].Power System Technology(in Chinese),2007,7(4):36-40,56.
[4]牛東曉,曹樹華,趙磊,等.電力負荷預測技術及其應用[M].中國電力出版社,1998.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
