基于GLC-KSVD的稀疏表示人臉識別算法
2014-07-03 06:08:10李小霞
兵器裝備工程學報 2014年4期
關鍵詞:特征
封 睿,李小霞
(西南科技大學 信息工程學院,四川 綿陽 621010)
自動人臉識別技術一直是計算機視覺、機器學習和生物識別領域中具有挑戰性的研究課題。2009 年Wright 等[1]提出將稀疏表示理論應用到人臉識別技術中,該方法對光照、遮擋、偽裝有較好的魯棒性。基于稀疏表示的圖像分類(sparse representation classification,SRC)首先用訓練樣本構造一個超完備字典,將待測樣本用字典原子的稀疏線性組合來表示,然后通過待測樣本的稀疏編碼系數實現分類。
稀疏編碼的效果取決于字典的質量。Wright 等用整個訓練樣本集構造字典,在實踐中為了獲得好的分類效果通常需要大規模的訓練樣本集,導致計算量很大。近年來,國內外學者基于字典學習的思想,提出許多能夠表示給定信號的更加緊湊的小型字典學習算法,取得了較好的分類效果。2006 年Aharon 等[2]提出K-SVD 字典學習算法,得到的新字典能夠很好地表示訓練樣本,但是沒有考慮字典的判別性。文獻[3-6]將稀疏系數作為圖像的特征,在字典學習的基礎上訓練分類器,這些方法將字典學習和分類器設計分開進行,得到的新字典對于分類不是最優的。另外,一些學者通過增加字典的約束條件,得到判別性字典和分類器。2008 年Pham 等[7]在K-SVD 算法中增加了分類誤差約束條件,該算法將字典更新和預測分類器設計過程交替迭代,得到了更利于分類的新字典,但是只能得到一個局部最優解。2010 年張等[8]提出判別性KSVD(DKSVD)算法,同時得到全局最優的判別性字典和線性預測分類器,但是在字典較小的情況下不能保證稀疏系數的判別性。2010 年楊等[9]對每一個類別分別進行字典學習和分類器設計,但是該算法在類別多的情況下十分耗時。2013 年胡等[10]通過Fisher 判別準則約束稀疏系數,得到具有判別性的新字典,但是不適于類別多的情況。
為了減小稀疏編碼的計算量,通常需要通過特征提取對原始圖像進行降維,常采用下采樣、Eigenface、Fisherface 及隨機投影等方法來提取圖像的整體特征。文獻[1]表明在特征維數足夠高的情況下,SRC 算法對整體特征不敏感,即使是隨機投影都能達到較好的識別效果,但是實踐中訓練樣本的數量往往是有限的,而整體特征容易受到光照、表情、姿態、局部變形等影響,不能很好的表示樣本。Gabor 濾波器能夠有效地提取圖像在多個方向、多個尺度上的局部特征,并被成功的應用到人臉識別技術中[11-14],從圖像的局部區域提取的Gabor 特征對光照、表情和姿態等都有更強的魯棒性。
考慮字典學習在稀疏表示圖像識別中的作用以及Gabor特征對光照、表情和姿態的魯棒性,本文提出一種基于Gabor特征和標簽一致字典學習的GLC-KSVD 稀疏表示人臉識別算法。首先提取樣本多尺度多方向的Gabor 特征,將訓練樣本的Gabor 特征矩陣作為初始特征字典,然后通過字典學習同時得到全局最優的判別性字典和線性分類器。學習到的新字典能夠很好的對信號進行稀疏表示,并且對于任意大小的字典,編碼系數都具有很強的判別性,來自同一類別的樣本具有相似的稀疏系數,通過一個簡單的線性分類器就能達到較好的識別性能,同時也減小了計算代價。
1 字典學習
字典學習是為了從樣本中學習一個能夠更好地表示或編碼給定信號的一組基。令Y=[y1…yN]∈Rn×N表示N 個n維輸入信號,則字典學習模型表示為:

式(1)中,D =[d1,d2,…,dk]∈Rn×k是學習到的字典,X =[x1,x2,…,xN]∈Rk×N是輸入信號Y 的稀疏系數矩陣,T 是稀疏約束因子,‖Y-DX‖表示重構誤差。
K-SVD 算法通過迭代求解式(1),同時得到重構字典D和稀疏系數矩陣X,但是僅考慮了對給定信號的重構性,不利于分類。
2 基于GLC-KSVD 的人臉識別算法
2.1 Gabor 紋理特征集
Gabor 核函數表示為

式(2)中,μ 和ν 分別是濾波器的方向和尺度因子,z =(x,y)表示像素,kμ,ν=kνeiφμ,kν=kmax/fν,φμ=πμ/8,kmax是最大采樣頻率,f 是采樣步長,σ 是高斯函數方差。
選取5 個尺度和8 個方向構造Gabor 濾波器組,然后分別與人臉圖像進行卷積提取Gabor 特征。令I(x,y)表示人臉圖像,將其與Gabor 核函數進行卷積可得:

式(3)中,Gu,v(z)是復數,其幅值包含了圖像局部能量的變化,用來描述圖像的特征。每幅圖像分別與40 個Gabor 濾波器進行卷積,然后對每個幅值矩陣進行下采樣、向量化,最后將這40 個列向量連接起來,構成增廣Gabor 紋理特征向量:
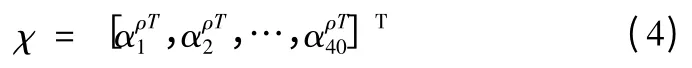
2.2 GLC-KSVD 算法
基于GLC-KSVD 的人臉識別算法用訓練樣本的Gabor特征向量χ 代替公式(1)中的原始訓練樣本Y,構成Gabor 紋理特征集G=χ(Y)=[χ(y1),χ(y2),…,χ(yN)]。GLC-KSVD算法在字典學習模型中加入標簽一致約束條件,再通過KSVD 算法得到一個同時具有重構性和判別性的字典。下面分別在式(1)中加入標簽一致正則項(GLC-KSVD1)及結合標簽一致和分類誤差的正則項(GLC-KSVD2)。
2.2.1 GLC-KSVD1 算法
一個線性分類器的性能取決于輸入的稀疏系數的判別性。為了在字典D 上得到具有判別性的稀疏系數,在式(1)中加入標簽一致正則項,GLC-KSVD1 字典學習模型為

式(5)中,α 是正則化參數,Q=[q1,q2,…,qN]∈RK×N是輸入信號G 的判別式稀疏系數矩陣,A 是線性變換矩陣,‖Q-AX‖表示判別式稀疏編碼誤差。假設G =[χ1,χ2,…,χ6],D =[d1,d2,…,d4],其中χ1、χ2、χ3、d1、d2屬于類別1,χ4、χ5、χ6、d3、d4屬于類別2,那么
稀疏編碼誤差項使編碼系數在任意字典大小下都具有很強的判別性,來自同一類別的信號具有相似的稀疏表示,不需要對每個類別進行分類器學習,只需要一個簡單的線性分類器就能達到良好的分類性能,同時減小了計算成本。
2.2.2 GLC-KSVD2 算法
為了得到更好的分類性能,在式(5)中加入分類誤差項,GLC-KSVD2 字典學習模型為

式(6)中,α、β 是正則化參數,H 是輸入信號G 的類別矩陣,W 是線性分類器參數,‖H-WX‖22 表示分類誤差,它使分類器更利于分類。
2.2.3 GLC-KSVD 最優化問題
下面介紹GLC-KSVD2 的最優化求解方法,GLC-KSVD1可以使用相似的方法,GLC-KSVD2 最優化求解模型表示為
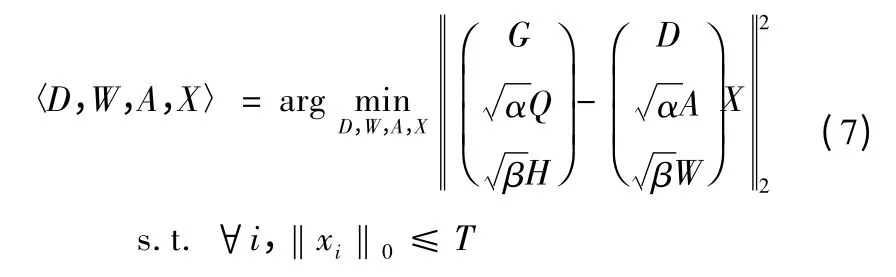
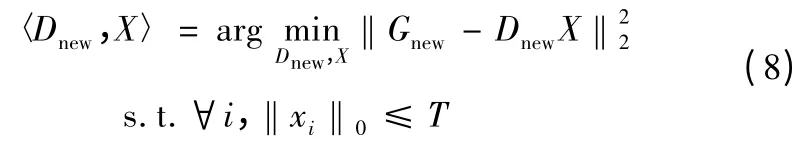
然后,通過K-SVD 算法求得Dnew和X,從而得到D、A、W。GLC-KSVD 算法同時求得D、A、W 的值,解決了局部最優的問題,適用于小字典、類別多的情況,也便于加入其他的判別項。
圖1 顯示了兩個不同的人臉庫中,某一類測試樣本在不同字典上的稀疏系數,X 軸表示稀疏系數的維度,Y 軸表示這類測試樣本的稀疏系數的絕對值之和。第一列曲線對應Extended YaleB 人臉庫的第2 個人(含32 個測試樣本),第二列曲線對應AR 人臉庫的第89 個人(含6 個測試樣本)。圖1(f)和(g)顏色條中的每種顏色代表字典原子的一個類。
不同于K-SVD 和DKSVD,在GLC-KSVD 和SRC、SRC*算法中字典原子和類別標簽相對應,由圖1(f)和圖1(g)可以看出GLC-KSVD 使來自同一類別的樣本具有相似的稀疏表示,與測試樣本同一類別的字典原子對其稀疏編碼的貢獻顯著高于其他的字典原子。稀疏系數的這種判別性對于提高線性分類器的性能十分重要。
2.3 初始化
在GLC-KSVD 算法中,首先需要初始化參數D0、A0和W0。對每一類別分別進行K-SVD 字典學習,然后合并所有學習到的字典來初始化D0,其中每一類字典原子的數目是一致的,每個原子dk的類別標簽被初始化為相應的類別號,且在整個算法中保持不變。初始化D0后,求解G 的稀疏系數矩陣X,然后通過多元回歸模型來初始化A0和W0,計算公式為

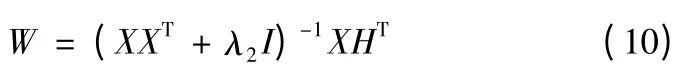
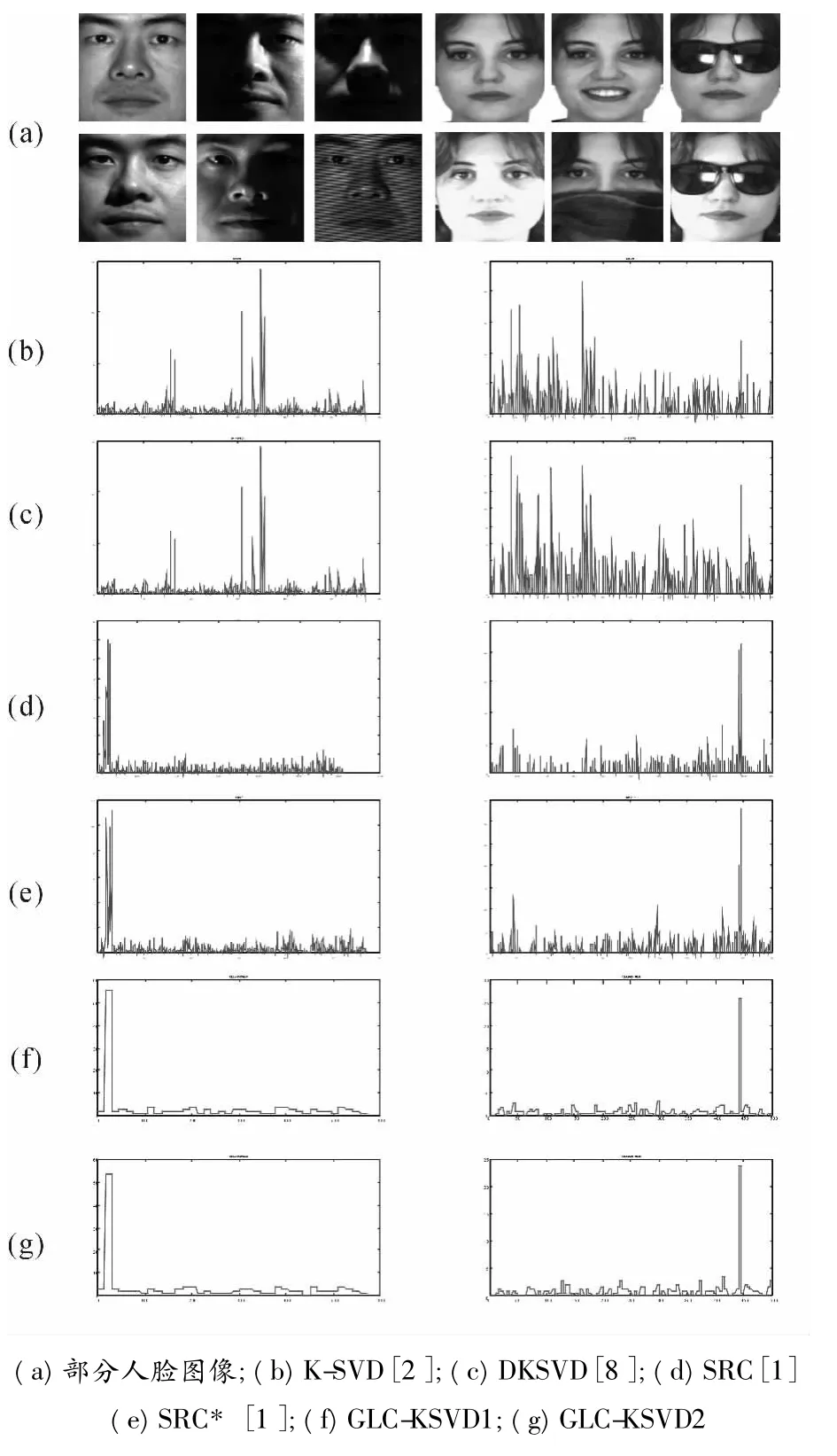
圖1 采用不同稀疏編碼方法的稀疏系數示例
2.4 分類
通過K-SVD 算法求得Dnew,從而得到D = {d1,d2,…,dK}、A={a1,a2,…,aK}、W={w1,w2,…,wK},因為Dnew的每一列是歸一化的,所以在測試過程中需要對D、A、W 進行轉化:
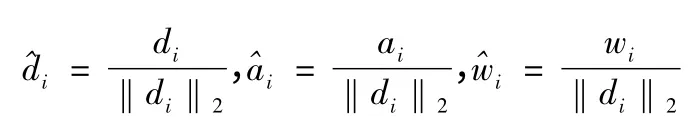
對于測試圖像yi,首先計算出χ(yi)相應的稀疏系數xi:

然后通過線性預測分類器來估計yi的類別:

3 實驗仿真
為了檢驗本文算法的有效性,在Extended YaleB 人臉庫和AR 人臉庫上分別進行實驗,實驗平臺為酷睿2 雙核處理器,主頻2.93 GHz,2 GB 內存。為了保證結果的準確性,實驗結果為獨立運行10 次后的平均識別率和運行時間。
3.1 Extended YaleB 數據庫
Extended YaleB 人臉庫共有38 個人,每個人有64 幅正面人臉圖像,包括光照和表情變化。對于每個人,隨機選擇32 幅用于訓練,其余的用于測試。所有圖像的尺寸歸一化到192 ×168 像素,經隨機投影后特征維數降到504 維,學習到的字典包含570 個原子,每人15 個。不同于K-SVD 和DKSVD,GLC-KSVD 和SRC 一樣,其字典原子和類別標簽相對應,對于SRC 實驗選擇全體訓練樣本和每人15 幅圖像兩種不同的字典,所有的方法使用相同的學習參數。
表1 列出了本文算法和K-SVD、DKSVD、SRC 及采用相同字典大小的SRC* 的識別率。大多數的錯誤識別是因為圖片的光線太暗,參照文獻[11]剔除質量很差的圖片(每人約10 幅),進行了另外一組實驗,實驗結果列在表1 第3 行。

表1 Extended YaleB 上不同方法的識別率 %
由表1 可以看出本文算法的識別率高于K-SVD、DKSVD,且明顯高于采用相同字典大小的SRC* ,GLC-KSVD2 的識別率高于GLC-KSVD1。在原圖庫上GLC-KSVD 達到了96.3%的最高識別率,略低于SRC 的識別率。剔除質量很差的圖片后,GLC-KSVD 達到了99.2%的最高識別率,略高于SRC 的識別率。
表2 列出了本文算法和SRC、SRC*識別一個樣本的平均運行時間,可以看出采用小字典的SRC*、GLC-KSVD1 及GLC-KSVD2 的運行速度比SRC 快,并且本文算法的運行速度比SRC 提高11.9 倍,比選擇相同字典大小的SRC*提高6 倍。
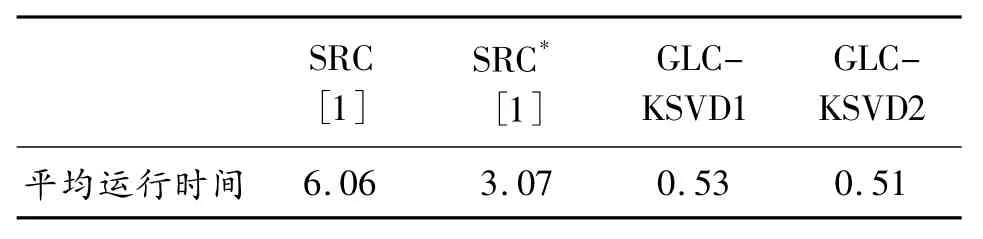
表2 Extended YaleB 上不同方法的平均運行時間 ms
3.2 AR 數據庫
AR 人臉庫共有126 個人,每個人有26 幅正面人臉圖像,包括光照、表情和偽裝變化。從中選取50 名男性和50名女性的2 600 幅圖像用于實驗,對于每個人,隨機選擇20幅用于訓練,另外6 幅用于測試。所有圖像的尺寸歸一化到165 ×120 像素,經隨機投影后特征維數降到540 維,學習到的字典包含500 個原子,每人5 個。對于SRC 實驗選擇兩種不同大小的字典。
表3 列出了本文算法和K-SVD、DKSVD、SRC 及采用相同字典大小的SRC* 的識別率。由表3 可以看出本文算法的識別率明顯高于K-SVD、DKSVD 及SRC* ,并且由于AR庫中人臉圖像存在光照、表情、偽裝等變化,GLC-KSVD 的識別率高于單純采用隨機投影的SRC,達到了97.7%。

表3 AR 庫上不同方法的識別率 %
表4 列出了本文算法和SRC、SRC* 識別一個樣本的平均運行時間,可以看出SRC*、GLC-KSVD1 及GLC-KSVD2 的運行速度比SRC 快,并且本文算法的運行速度比SRC 提高41.9 倍,比采用相同字典大小的SRC*提高11.4 倍。

表4 AR 庫上不同方法的平均運行時間 ms
由實驗結果看出對于一個包含大量訓練樣本的數據庫,與用整個訓練樣本集作字典相比,學習一個小字典可以節省很多時間。GLC-KSVD 算法使稀疏系數具有判別性,只用一個簡單的線性分類器就達到了最好的識別率,同時大大提高了運行速度,尤其是在類別多的情況下,運行速度提高更多。
4 結論
本文提出基于Gabor 特征和標簽一致字典學習的GLCKSVD 稀疏表示人臉識別算法,提取訓練樣本的Gabor 特征來構建初始特征字典,對光照、表情、姿態、偽裝等有更強的魯棒性。GLC-KSVD1 通過綜合重建誤差、稀疏編碼誤差,使編碼系數在任意字典大小下都具有很強的判別性,來自同一類別的信號具有相似的稀疏表示,不需要對每個類別分別進行復雜的分類器學習,通過一個簡單的線性分類器就達到了良好的分類性能,也減小了計算成本。GLC-KSVD2 通過綜合重建誤差、稀疏編碼誤差和分類誤差,使稀疏系數更利于分類。GLC-KSVD 還通過最優化求解方法,得到了全局最優的判別性字典和線性分類器,也便于加入其他的判別項。實驗結果表明,本文算法達到了較好的識別效果,適用于小字典,對表情、偽裝、姿態變化等有更強的魯棒性,且運行速度大大提高,尤其是在類別多的情況下,運行速度提高更多。
[1]WRIGHT J,YANG A Y,GANESH A,et al. Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[2]AHARON M,ELAD M,BRUCKSTEIN A.K-SVD:An algorithm for designing overcomplete dictionaries for sparse representation[J]. IEEE Transactions on Signal Processing,2006,54(1):4311-4322.
[3]MAIRAL M,LEORDEANU M,BACH F,et al.Discriminative sparse image models for class-specific edge detection and image interpretation[C]//Proceedings of the 10th European Conference on Computer Vision. Marseille,France:Springer,2008:43-56.
[4]ZHANG W,SURVE A,FEM X,et al.Learning non-redundant codebooks for classifying complex objects[C]//Proceedings of the 26th Annual International Conference on Machine Learning. New York,USA: ACM,2009: 1241-1248.
[5]BOUREAU Y L,BACH F,LECUM Y,et al.Learning midlevel features for recognition[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco,CA,USA: IEEE Computer Society,2010:2559-2566.
[6]MAIRAL J,BACH F,PONCE J,et al.Discriminative learned dictionaries for local image analysis[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Anchorage,AK,USA: IEEE Computer Society,2008:1-8.
[7]PHAM D,VENKATESH S. Joint learning and dictionary construction for pattern recognition[C]//proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Anchorage,AK,USA: IEEE Computer Society,2008:1-8.
[8]ZHANG Q,LI B X. Discriminative K-SVD for dictionary learning in face recognition[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco,CA,USA: IEEE Computer Society,2010:2691-2698.
[9]YANG J,YU K,HUANG T.Supervised translation-invariant sparse coding[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Francisco,CA,USA: IEEE Computer Society,2010:3517-3524.
[10]胡正平,徐波,白洋.Gabor 特征集結合判別式字典學習的稀疏表示圖像識別[J].中國圖象圖形學報,2013,18(2):189-194.
[11]JIANG Z L,LIN Z,DAVIS L S.Learning a discriminative dictionary for sparse coding via label consistent K-SVD[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Providence,RI,USA:IEEE Computer Society,2011:1697-1704.
[12]張文超,山世光,張洪明,等.基于局部Gabor 變化直方圖序列的人臉描述與識別[J].軟件學報,2006,17(12):2508-2517.
[13]YANG M,ZHANG L.Gabor feature based sparse representation for face recognition with Gabor occlusion dictionary[C]//Proceedings of the 11th European Conference on Computer Vision.Crete,Greece:Springer,2010:448-461.
[14]張娟,占永照,毛啟容,等.基于Gabor 小波和稀疏表示的人臉表情識別[J]. 計算機工程,2012,38(6): 207-212.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
