不同缺失機制并存時偏倚校正的模擬研究*
2014-04-03 07:47:10趙俊康榮惠英孟繁龍
中國衛生統計 2014年4期
趙俊康 王 彤 榮惠英 孟繁龍
弱勢人群的醫療救助問題一直以來備受世界各國政府關注[1]。這部分弱勢人群的特點是收入偏低,極易陷入因貧致病和因病致貧的惡性循環中。根據第四次國家衛生服務調查結果[2],我國約有38%的居民生病不去看醫生,經醫生診斷該住院治療而未住院的達21%,其中70.3%的人未住院的主要原因仍然是“經濟困難”。這些潛在患者不選擇就醫使得從醫院收集數據仍然很難估計出這部分非從業人群的全部醫療費用需求。低收入非從業人群更可能由于貧困等原因得到高于普通人群的致病機會,因此若用一個總的平均水平來估計弱勢人群醫療費用的實際需求將明顯低估這種需求。
這種由于個體自我行為(因經濟困難自主選擇不就醫)所導致的樣本選擇偏倚,單靠好的抽樣設計是無法消除的。需要注意的是患病但自我選擇未就醫者應答表現出的0消費與真正未患病而不就醫者的消費真值是不同的,即自我選擇未就醫者的醫療消費真值未知,應視為缺失數據[3]。將這類真值未知的0消費數據刪除或者直接取因變量為0來應用多元線性回歸等常規的統計學分析方法就忽視了這種無應答偏倚;同時,像這類較大規模的社會學或流行病學調查中無應答偏倚也是常態而不是偶然[4],故而針對不同缺失機制下的無應答偏倚探討其校正方法成為國內外學者長期以來關注的問題。
Rubin等人于1976年提出的缺失機制主要包括完全隨機缺失MCAR(missing completely at random)、隨機缺失MAR (missing at random)和非隨機缺失NMAR(not missing at random)三類[5]。在MCAR假定下,對完全觀測個體使用的任何分析方法仍然有效;在MAR假定下,主流觀點是采用多重填補MI(multiple imputation)對隨機缺失進行填補繼而得出無偏估計[6];而對于由于自主選擇不就醫而導致的NMAR,本研究選用適合于該類型數據的受限因變量(limited dependent variable)統計模型來進行校正[7-9]。
隨機缺失機制下的多重填補方法
1.多重填補的具體步驟
多重填補(MI)主要由三個獨立的步驟組成:填補階段、分析階段和合并階段。MI其實是包含了一組方法的一個廣義的術語,在其框架內的所有的方法中都含有這三步過程。圖1描述了整個過程。
填補階段 分析階段 合并階段
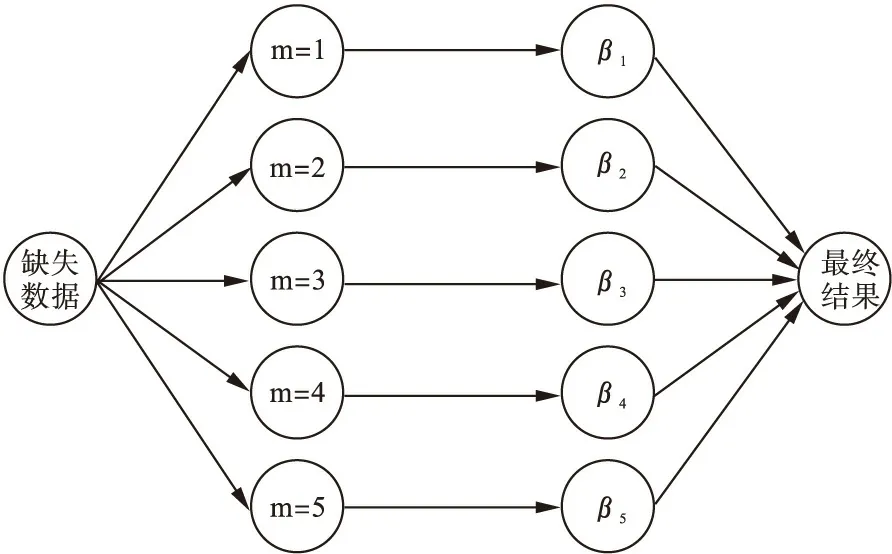
圖1 MI的三個步驟
(1)填補階段為每個缺失值抽取m個估計值進行填補,從而構成m個完整數據集,這m個數據集中只有觀測數據是相同的,填補值一般不等。(2)分析階段:分析步的主要分析對象就是填補好的數據集,這一步將應用數據原本完整時所用到的相同的方法來分析。唯一的區別在于要對每個完整數據集分別使用該方法處理,因此將分析m次。對于本研究中包含自主選擇性缺失的醫療費用數據,這一步可使用填補后的多個數據集與選擇性偏倚導致的因變量為虛假0(視為缺失)的數據合并進行樣本選擇模型分析以解決選擇性偏倚導致的那部分缺失,繼而得出m個樣本選擇模型擬合結果。(3)合并階段:綜合這m個擬合結果,根據Rubin(1987)提出的針對參數估計值與標準誤的合并準則[10],最終得到對目標變量的統計推斷。
2.填補模型
(1)預測均數匹配法(PMM)
預測均數匹配法(PMM)是處理單調缺失模式中定量變量缺失的多重填補方法之一,PMM法的具體填補步驟如下:
令Yj為有缺失值的定量變量,用Yj及其協變量X1,X2,…,Xk均被觀測到的個體觀察值建立回歸模型:
Yj=β0+β1X1+β2X2+…+βkXk
(1)
每次填補產生填補值的步驟如下:
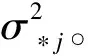
(2)
其中nj是變量Yj未缺失的觀測個體數。
然后,從標準正態分布N(0,1)中抽取k+1個獨立的變量,組成一個有k+1個元素的向量Z,得到新的回歸系數:
(3)
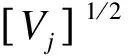
②對于每個缺失值,其預測值為
(4)
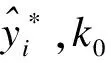
④最后從這k0個觀測值中隨機抽取一個值填補缺失值。
(2) 傾向性得分法
傾向性得分(PS)是指對給定的觀察到的協變量條件下,每個觀察值被分配到某特定處理組的條件概率。PS法的具體填補步驟如下:
①產生一個指示變量Rj,當Rj為0時,表示變量Yj中有缺失值的個體;當Rj為1時,則表示變量Yj中被觀測到的個體。
②擬合logistic回歸模型
logit(pj)=β0+β1X1+β2X2+…+βkXk
(5)
其中X1,X2,…,Xk是Yj的協變量,
pj=Pr(Rj=0|X1,X2,…,Xk)
logit(pi)=log(pi/(1-pi))
③根據模型計算變量Yj上每個個體數據缺失的傾向性得分logit(pj),并根據該得分將所有的觀測分組,一般為5組,如果觀測數量較多,可分為更多的組。
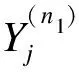
⑤重復以上步驟,直到每一個缺失變量都得到填補。
(3)基于Bootstrap的EM算法
基于Bootstrap的EM算法(EMB)是通過bootstrap算法從參數的后驗密度中抽取新的參數,從而代替其他方法中復雜的抽取過程。該方法不必估計參數的方差矩陣,也不用像期望最大化重要性抽樣EMis(expectation maximization importance sampling)算法那樣進行重要性抽樣,甚至不需要像數據增廣DA (data augmentation ) 算法一樣推導Markov鏈并檢查收斂性,而且還可以應用于非常大型的數據[11]。
EM算法是一種迭代算法,廣泛運用于尋找參數的最大似然估計值,尤其是在缺失數據的問題中非常有用[12]。它的每一次迭代都由兩步組成:E步(求期望)和M步(極大化)。其中E步是在給定已觀測到的數據和當前參數下,求缺失數據的條件期望,然后用這些條件期望值去填補缺失值。M步是當缺失數據被填補之后就像沒有缺失一樣進行的極大似然估計。重復以上兩步,直至前后兩次計算結果達到規定的收斂標準。
將經典的EM算法和Bootstrap算法相結合來從后驗分布中進行抽取。具體填補步驟如下:
①從含量為n的完整數據集Yobs中有放回地抽取m個大小為n的樣本。
②對每一個樣本運行穩定而快速的EM算法,得到一組參數的點估計值μ和∑,共m組。
③用Ycom中的觀測數據分別結合每組參數估計值得出缺失數據的條件分布,并從中抽取填補值,繼而得到m個經填補后的完整數據集。
(4)Markov Chain Monte Carlo方法
Markov Chain Monte Carlo(MCMC)方法在應用于缺失值領域時稱為數據增廣DA算法[13],同EM算法一樣,DA算法也是依次填補缺失值和推斷未知參數的一種迭代方法。區別就在于DA是以隨機的方式對缺失值和參數進行抽取,而EM算法只是缺失值和參數的點估計。
該算法通過填充(imputation)及后驗(posterior)兩步迭代來實現:
①填補步(I-step)
填補的數據是從給定觀測數據、均數和協方差矩陣后的缺失數據的條件分布中隨機抽取得到,從貝葉斯角度來看,該分布又稱為后驗預測分布。
在每次迭代過程中,從事先給定的均值向量μ和協方差陣Σ的初始估計值開始,在給定Yobs下的條件分布P(Ymis|Yobs)中抽取Ymis。
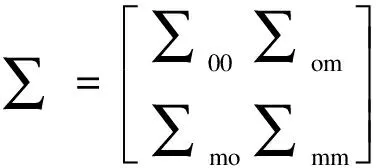
在某個觀測個體具有類似的缺失模式時,令Yobs=y1,就得到均值向量及條件協方差矩陣分別為
(10)
(11)
的多元正態分布P(Ymis|Yobs=y1),也就是Ymis的條件分布。整個I-step可以表述成:
(12)
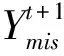
②后驗步(P-step)
由于在多重填補過程中需要產生多個完整的數據集,因此在每個I-step需要不同的均數向量和協方差矩陣,因此P-step的目的就是輪流產生參數估計值。
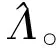
(13)
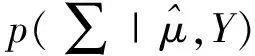
(14)

(15)
這樣從后驗分布中抽取新的參數后,接下來的I-step使用這些新的參數值來產生新的填補值;然后新的填補數據繼續用于下一個P-step,繼而再抽取另一組新的參數估計值。如此循環往復重復這兩個步驟一定的次數,產生一個足夠長的隨機序列:
(16)
該隨機序列是就一條馬爾科夫鏈,并且在一定的正則條件下會收斂到一個穩定分布[14]。當該鏈收斂到一個穩定的分布P(Ymis,θ|Yobs)時,就可以近似獨立地從該分布中為缺失值抽取填補值。
兩種缺失機制并存時的兩階段校正模擬研究
1.模擬設計
首先需要構建出含結果等式和選擇等式的樣本選擇模型,如下所示:
y0=x1+ε
(17)
d0=x2+v
(18)
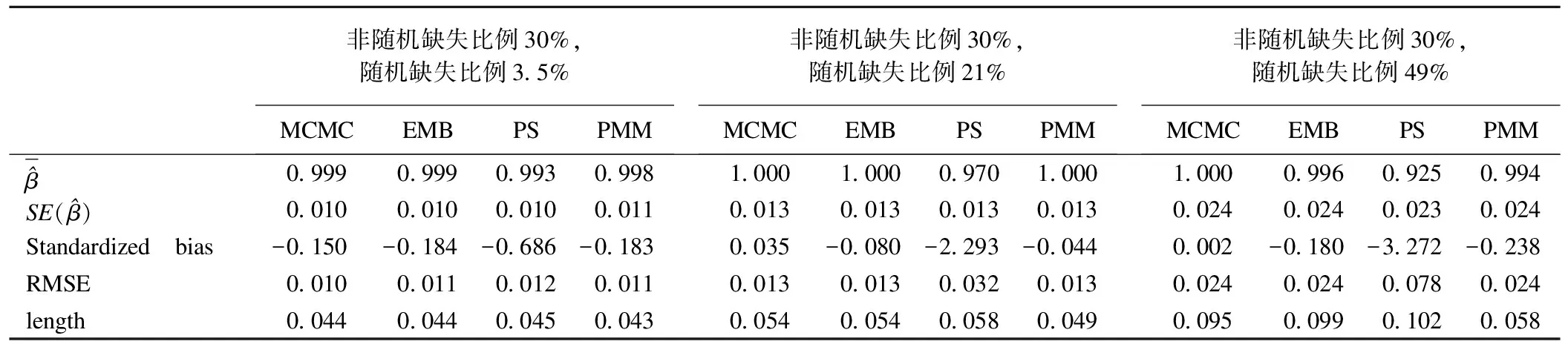
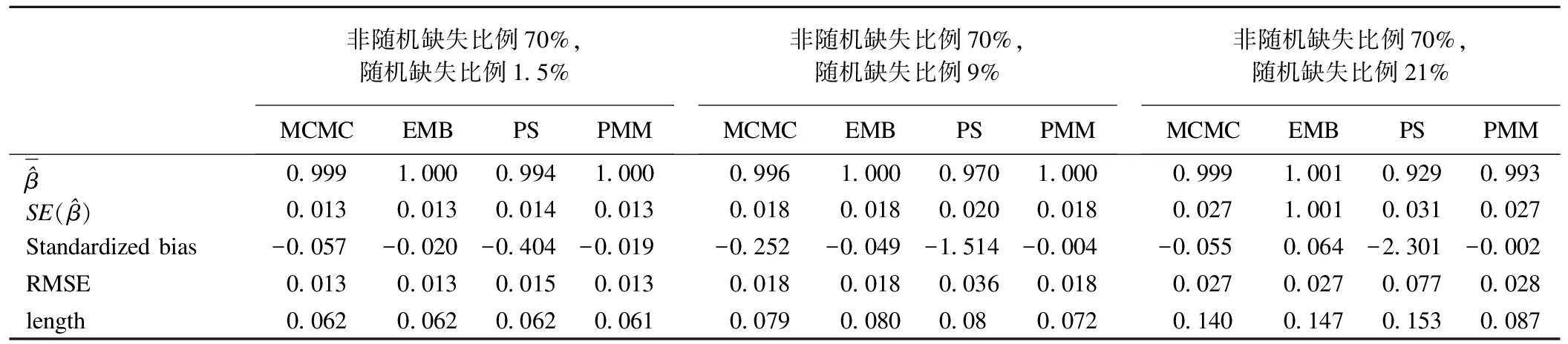
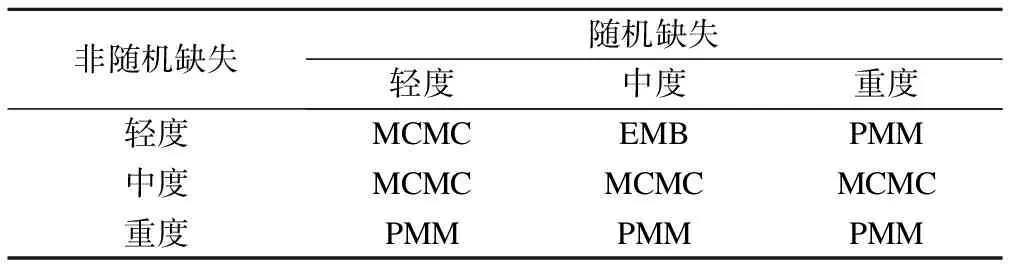
d=1(d0≥c),d=0(d0 (19) y1=y0·d (20) 取10000例觀測值(n=10000),根據樣本選擇模型的結果等式(17)和選擇等式(18)模擬六個變量x1、x2、y0、d0、ε、v,x1和x2分別取自均值為0,標準差為1,相關系數為0的雙變量正態分布,而ε和v取自均值為0,標準差為1,相關系數為0.75的雙變量正態分布。y0和d0分別通過公式y0=e1+x1+ε和d0=1+x2+v求出。第一步首先對全部10000例觀測值的因變量分別進行輕度、中度和重度截取,即以5%、30%和70%的比例向下截取產生對應于調查中生病但自主選擇不就醫者發生的虛假0消費因變量。可以通過以上截取比例給y0定義一個相應的界值c,當d0>c時,令y1=y0且d=1;當d0≤c時,令y1為缺失且d=0,最后對y1進行對數轉換,對應于使醫療費用值近似服從正態分布。通過調整c的值就可以獲得針對樣本選擇模型不同程度缺失率的非隨機缺失數據。第二步分別在上述三個不同缺失率下,令d=1的個體以5%、30%和70%的比例隨機產生缺失(對應于調查中可能發生的隨機缺失)。這樣就產生9種不同的組合數據。在上述不同組合下,首先對d=1的個體(僅存在隨機缺失)分別應用PMM、PS、MCMC和EMB法進行多重填補,然后把填補后的數據與d=0的數據合并,應用樣本選擇模型的兩步似然估計來獲得各自的回歸系數估計量來校正虛假0消費產生的選擇性偏倚。最后,重復抽樣100次,計算9種組合下兩階段校正方法所獲得結果等式中自變量x1的回歸系數和標準誤。本次模擬分析中,多重填補技術的EMB算法選用了R軟件,PMM、PS和MCMC法選用了SAS軟件,樣本選擇模型分析也選用了SAS軟件。 2.評價標準 在比較兩階段校正方法下樣本選擇模型結果等式回歸系數的優劣時,選用以下三個評價標準[15-16]。 (1) 標準偏倚(Standardized bias) 當標準偏倚落在±0.4區間之外時,偏倚就會對功效、可信區間覆蓋率和誤差率產生明顯的負面影響。因此,將±0.4作為評價標準偏倚的上下界值,即若某方法的標準偏倚絕對值超出0.4,此方法便無法接受。標準偏倚做為評價準確度的指標是方法評價指標中的首要觀測指標。 (2)可信區間平均長度(length) 如果一個方法與另一個方法相比,有相同的或更高的準確度,但得出的可信區間平均卻更短,那么此方法的精確度就更高。 (3)均方誤差的平方根(RMSE) 3.模擬分析結果 表1 四種填補方法下樣本選擇模型結果等式的回歸系數估計值的各項評價標準比較(一) 從表1到表3可知,四種填補方法的標準偏倚絕對值均不等,其中PS法超過了所規定的界值,故該法效果相對不理想;其余三個方法中,均方誤差的平方根和可信區間平均長度均相差不大,因此根據標準偏倚絕對值大小便可判斷出不同缺失機制組合下的填補方法優劣。 綜上,各種情況下不同方法的推薦結果如表4。 表2 四種填補方法下樣本選擇模型結果等式的回歸系數估計值的各項評價標準比較(二) 表3 四種填補方法下樣本選擇模型結果等式的回歸系數估計值的各項評價標準比較(三) 表4 不同缺失機制組合下的填補方法選擇 數據缺失現象在調查研究中非常普遍,它不僅會降低參數估計的效率,同時也給統計分析帶來很大偏倚。根據數據缺失機制,可將數據缺失分為三類:完全隨機缺失(MCAR)、隨機缺失(MAR)和非隨機缺失(NMAR)。針對MAR機制,統計學家們提出了多種方法來校正這種缺失帶來的偏倚,MI就是被廣為推崇的方法之一;針對NMAR機制,由于該機制的復雜性,當前還沒有一種統一的方法來校正這種偏倚,不過當回歸模型中的應變量為非隨機缺失時,某些情況下可以應用樣本選擇模型來糾正這種NMAR帶來的偏倚;但當兩種缺失機制并存時的偏倚糾正方法尚未見有介紹。對此,本研究提出了一個兩階段策略以糾正不同缺失機制造成的偏倚。第一階段首先利用只包含隨機缺失數據的個體對單純無應答缺失按照MAR機制進行多重填補,在第二階段中使用填補后的多個數據集與選擇性偏倚導致的因變量為虛假0(視為缺失)數據合并進行樣本選擇模型分析以校正由于非隨機缺失所造成的偏倚,最后對多個樣本選擇模型擬合結果進行合并。 模擬研究結果表明:當非隨機缺失為輕度時,PS法由于標準偏倚絕對值遠遠超過了規定的界值,所以該法的結果相對不理想;而MCMC、EMB和PMM法均得出較好的結果。不同程度隨機缺失情況下的填補方法選擇為:隨機缺失也為輕度時,MCMC法最好;隨機缺失為中度時,EMB法最好;在隨機缺失為重度時,PMM法最好。 當非隨機缺失為中度時,PS法由于標準偏倚絕對值遠遠超過了規定的界值,所以仍不可取,而MCMC、EMB和PMM法均得出較好的結果。此時,無論隨機缺失程度如何,MCMC法都是最好的方法。 當非隨機缺失為重度時,PS法由于標準偏倚絕對值遠遠超過了規定的界值,所以仍不可取,而MCMC、EMB和PMM法均得出較好的結果。此時,無論隨機缺失程度如何,PMM法都是最好的方法。 本文以醫療費用調查研究中可能出現的兩種缺失為假設背景,探索性地提出兩階段策略糾正這兩種偏倚,希望能為以后在缺失值處理方面的應用提供一些方法學依據。 參 考 文 獻 1.Fisher ES,Bynum JP,Skinner JS.Slowing the growth of health care costs—lessons from regional variation.New England Journal of Medicine,2009,360(9):849-852. 2.衛生部統計信息中心.第四次國家衛生服務調查主要結果.[cited 2010年3月16日];http://www.moh.gov.cn/publicfiles/business/htmlfiles/mohbgt/s3582/200902/39201.htm]. 3.Baer OCJ.Bradley JC,et al.Testing and correcting for non-random selection bias due to censoring:an application to medical costs.Health Services and Outcomes Research Methodology,2003,4(2):93-107. 4.Peytchev A,Baxter RK,Carley-Baxter LR.Not All Survey Effort is Equal.Public Opinion Quarterly,2009,73(4):785-806. 5.Rubin DB.Inference and missing data.Biometrika,1976,63(3):581-592. 6.Little RJA.Rubin DB.Statistical analysis with missing data.2nd.Vol.2.2002:Wiley New York:2002. 7.薛小平,史東平,王彤.受限因變量模型及其半參數估計.中國衛生統計,2007,24(2):211-213. 8.張磊.樣本選擇模型的似然估計與兩步估計.現代預防醫學,2007,34(9):1607-1609. 9.張磊.樣本選擇模型及其在醫療費用研究中的應用.[碩士學位論文].山西:山西醫科大學,2007. 10.Donald B.Multiple Imputation for Nonresponse in Surveys.American Journal of Sociology,1987,76:346. 11.Honaker J,King G.What to Do about Missing Values in Time‐Series Cross‐Section Data.American Journal of Political Science,2010,54(2):561-581. 12.Dempster AP,Laird NM,Rubin DB.Maximum likelihood from incomplete data via the EM algorithm.Journal of the Royal Statistical Society.Series B (Methodological),1977:1-38. 13.Tanner MA,Wong WH.The calculation of posterior distributions by data augmentation.Journal of the American Statistical Association,1987,82(398):528-540. 14.Schunk D.A Markov chain Monte Carlo multiple imputation procedure for dealing with item nonresponse in the German save survey.2007. 15.Co1lins LM,Schafer JL,Kam CM.A Comparison of Inclusive and Restrictive Strategies in Modem Missing Data Procedures.Psychological methods,2001,6(4):330. 16.Burton A,et al.The design of simulation studies in medical statistics.Statistics in Medicine,2006,25(24):4279-4292.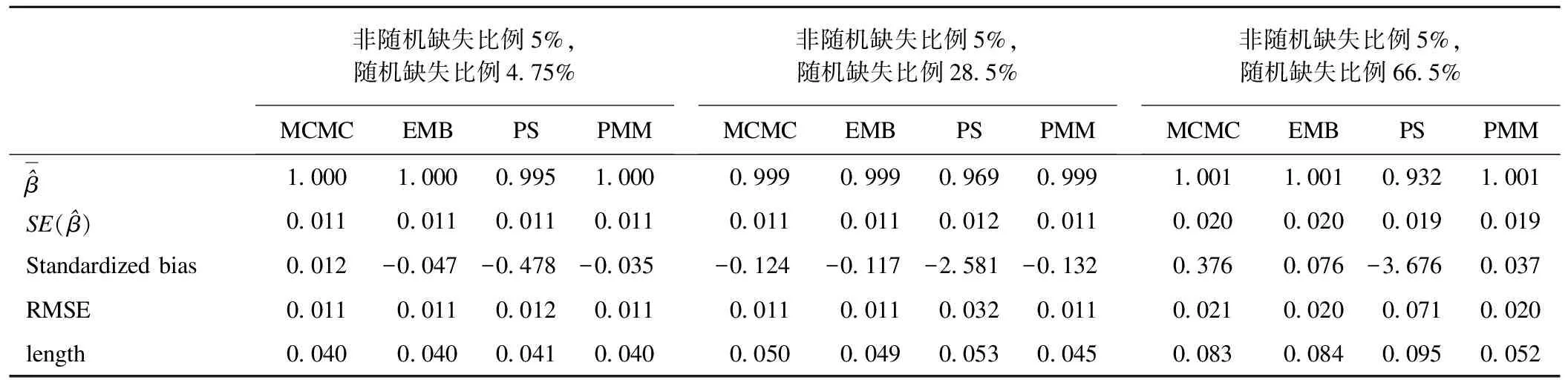
討 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
專用汽車(2016年4期)2016-03-01 04:13:43
Coco薇(2015年1期)2015-08-13 02:47:34
