SSAS神經(jīng)網(wǎng)絡(luò)算法在呼叫中心運營中的預(yù)測應(yīng)用
2014-03-20 11:13:50葉曉波
楚雄師范學(xué)院學(xué)報 2014年3期
關(guān)鍵詞:數(shù)據(jù)挖掘模型
王 松,葉曉波,楊 昌
(楚雄師范學(xué)院計算機信息管理中心,云南 楚雄 675000)
1.引言
隨著計算機應(yīng)用技術(shù)和網(wǎng)絡(luò)技術(shù)的不斷發(fā)展,各種業(yè)務(wù)系統(tǒng)在給商家管理方便的同時,也積累了海量的電子數(shù)據(jù)。隨著數(shù)據(jù)挖掘技術(shù)和數(shù)據(jù)挖掘工具的不斷發(fā)展,對業(yè)務(wù)應(yīng)用產(chǎn)生的數(shù)據(jù)可從更多方面進行“挖掘”,Microsoft SQL SERVER Analysis Services(SSAS)以其容易上手、快速、便捷等特點得到廣泛應(yīng)用。若事先對業(yè)務(wù)數(shù)據(jù)沒有任何期望,可利用此工具的SSAS神經(jīng)網(wǎng)絡(luò)模型知道是否會有任何值得關(guān)注的發(fā)現(xiàn),探查可能的相關(guān)性,分析多個輸入和輸出之間的復(fù)雜關(guān)系,使業(yè)務(wù)團隊可以用來理解數(shù)據(jù)中的趨勢。本文主要介紹數(shù)據(jù)挖掘中的神經(jīng)網(wǎng)絡(luò)算法在對某呼叫中心數(shù)據(jù)進行預(yù)測分析中的應(yīng)用,用一個實際案例說明用SSAS神經(jīng)網(wǎng)絡(luò)算法建立的用于呼叫中心運營中的預(yù)測分析挖掘模型。
2.SSAS神經(jīng)網(wǎng)絡(luò)算法
Microsoft神經(jīng)網(wǎng)絡(luò)使用由最多三層神經(jīng)元 (即“感知器”)組成的“多層感知器”網(wǎng)絡(luò) (也稱為“反向傳播Delta法則網(wǎng)絡(luò)”)。這些層分別是輸入層、可選隱藏層和輸出層。
輸入層:輸入神經(jīng)元定義數(shù)據(jù)挖掘模型的所有輸入屬性值及其概率。
隱藏層:隱藏神經(jīng)元接收來自輸入神經(jīng)元的輸入,并向輸出神經(jīng)元提供輸出。隱藏層是向各種輸入概率分配權(quán)重的位置。權(quán)重說明某一特定輸入對于隱藏神經(jīng)元的相關(guān)性或重要性。輸入所分配的權(quán)重越大,則輸入的值越重要。權(quán)重可為負值,表示輸入抑制而不是促進某一特定結(jié)果。
輸出層:輸出神經(jīng)元代表數(shù)據(jù)挖掘模型的可預(yù)測屬性值。
SSAS神經(jīng)網(wǎng)絡(luò)算法可描述為:

圖1 SSAS神經(jīng)網(wǎng)絡(luò)算法

圖2 集合N
實際的做法:


3.實例分析
3.1 實例概述
本文以某呼叫中心反映工作效率的指標信息為數(shù)據(jù)依據(jù),原始數(shù)據(jù)包括某個月內(nèi)呼叫中心的運轉(zhuǎn)情況。原始數(shù)據(jù)主要包括如下屬性:FactCallCenterID(數(shù)據(jù)導(dǎo)入到數(shù)據(jù)倉庫中時創(chuàng)建的一個任意鍵)、DateKey(呼叫中心的運營日期)、WageType(指示當(dāng)天是工作日、周末還是節(jié)假日)、Shift(指示為其記錄呼叫的輪班時間,此呼叫中心將工作日劃分為四個輪班時間:AM、PM1、PM2和Midnight)、LevelOneOperators(指示值班的一級接線員的數(shù)量)、LevelTwoOperators(指示值班的二級接線員的數(shù)量。員工必須達到一定數(shù)量的工作小時數(shù)后,才有資格成為二級接線員)、TotalOperators(此輪班時間內(nèi)存在的接線員的總數(shù))、Calls(此輪班時間內(nèi)收到的呼叫數(shù))、AutomaticResponses(完全通過自動呼叫處理來處理的呼叫數(shù))、Orders(由呼叫產(chǎn)生的訂單數(shù))、IssuesRaised(由呼叫產(chǎn)生的需要后續(xù)操作的問題的數(shù)量)、AverageTimePerIssue(應(yīng)答一次來電所需的平均時間)、ServiceGrade(指示此輪班時間的“掛斷率”)。掛斷率是呼叫中心經(jīng)常使用的一個指標。掛斷率越高,說明客戶的滿意度越差,因此丟失潛在訂單的可能性也就越大。掛斷率是按輪班時間計算的。數(shù)據(jù)跟蹤每個班次的操作員人數(shù)、呼叫數(shù)和訂單數(shù)、響應(yīng)時間和基于“掛斷率”(能夠反映客戶失望度)的服務(wù)等級標準。使用神經(jīng)網(wǎng)絡(luò)算法生成一個模型,用來理解數(shù)據(jù)和其中的趨勢。并嘗試解決哪些因素會影響客戶滿意度,呼叫中心如何能夠改進服務(wù)等級這兩個問題,根據(jù)結(jié)果,生成可用于預(yù)測的邏輯回歸模型。使用該預(yù)測來幫助規(guī)劃呼叫中心的運營。
3.2 部分屬性柱形圖
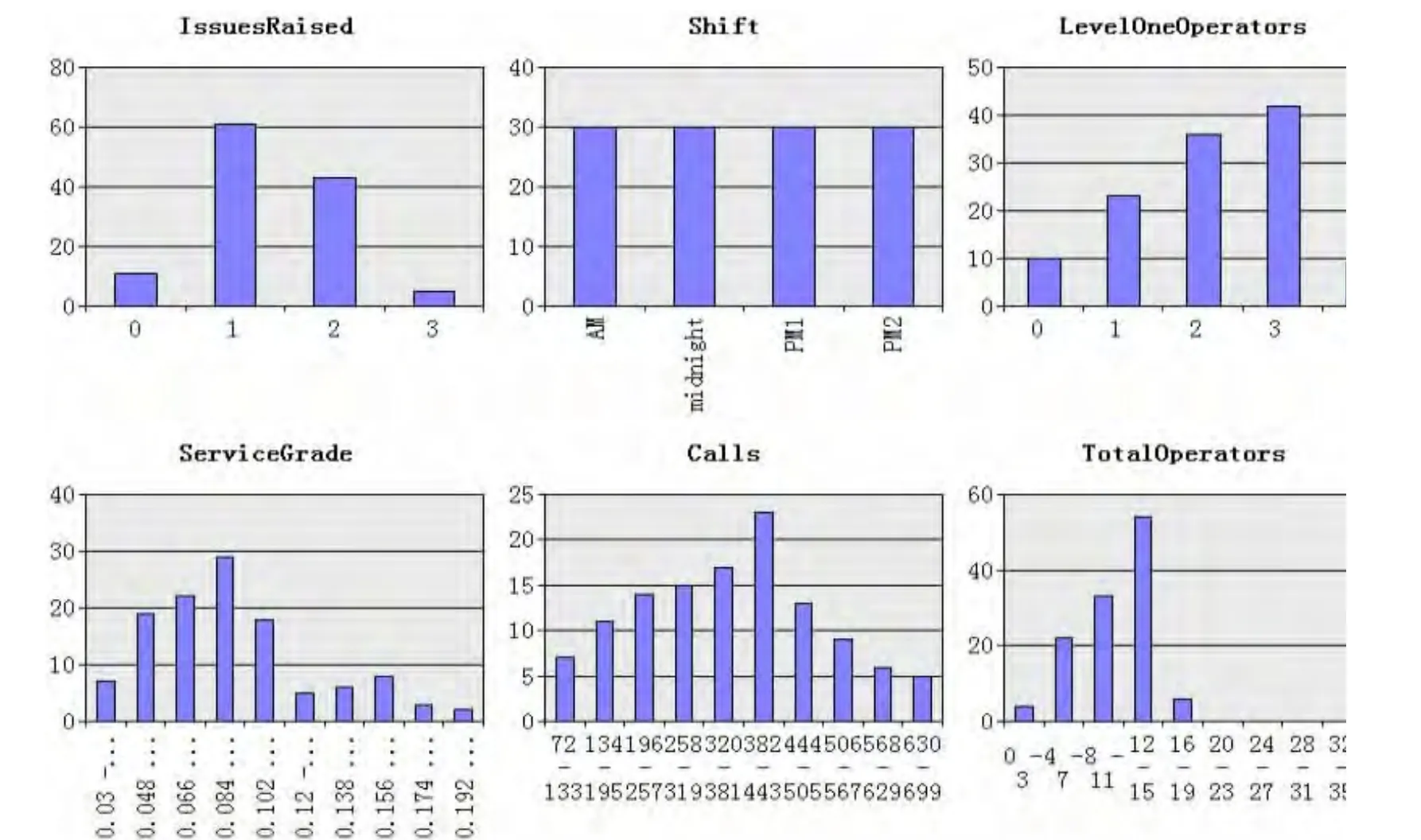
圖 3 IssuesRaised、Shift、LevelOneOperators、ServiceGrade、Calls、TotalOperators柱形圖
3.3 挖掘模型中趨勢的透視圖

圖4 按Shift(班次)來進行篩選所生成的AverageTimePerIssue的透視圖
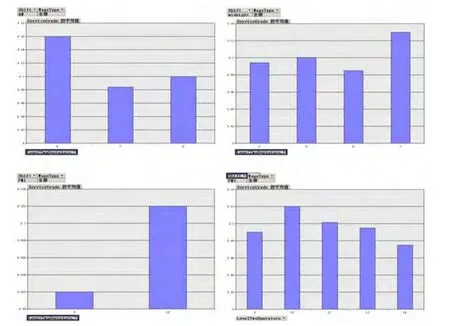
圖5 按Shift(班次)來進行篩選所生成的LevelTwoOperators的透視圖
以圖形方式顯示由模型發(fā)現(xiàn)的響應(yīng)時間和服務(wù)等級之間的相關(guān)性。
3.4 分析可能會影響呼叫中心運營的因素
從挖掘模型分析可知,首要影響因素是AverageTimePerIssue,AverageTimePerIssue介于44—70分鐘之間時,60.6% 的事例發(fā)生在具有最高服務(wù)等級(0.030—0.072)的班次內(nèi),8.30% 的事例發(fā)生在具有最低服務(wù)等級 (0.126—0.210)的班次內(nèi)。可得出結(jié)論:較短的呼叫響應(yīng)時間(44—70分鐘)會嚴重影響較好的服務(wù)等級 (0.03—0.07)。
3.5 創(chuàng)建預(yù)測的挖掘模型
除了分析可能會影響呼叫中心運營的因素之外,還需要就員工如何提升其服務(wù)等級提供一些具體的建議。在此任務(wù)中,將使用生成探索模型時所使用的挖掘結(jié)構(gòu),并添加一個用來通過使用邏輯回歸模型創(chuàng)建預(yù)測。
3.5.1 生成大容量預(yù)測查詢的輸入數(shù)據(jù)
使用數(shù)據(jù)源視圖設(shè)計器創(chuàng)建一個T-SQL語句的命名查詢,用于大容量預(yù)測的源數(shù)據(jù)的聚合視圖。生成大容量預(yù)測查詢輸入數(shù)據(jù)的T-SQL代碼如下:

3.5.2 預(yù)測每個班次的服務(wù)標準

表1 每個班次的示例結(jié)果
3.5.3 預(yù)測呼叫時間對服務(wù)等級的影響

表2 三個不同響應(yīng)時間用作預(yù)測查詢的輸入時的結(jié)果
4.總結(jié)
通過上述對SSAS神經(jīng)網(wǎng)絡(luò)算法的討論,以及利用基于SSAS神經(jīng)網(wǎng)絡(luò)算法建立的挖掘模型應(yīng)用到一個具體實例,通過分析神經(jīng)網(wǎng)絡(luò)算法挖掘模型所發(fā)現(xiàn)的模式,得出了對顧客分類的結(jié)果。根據(jù)結(jié)果,生成可用于預(yù)測的邏輯回歸模型,使用該預(yù)測來幫助規(guī)劃呼叫中心的運營。
[1]JIAWEIHAN MICHELINE KAMBER.Data Mining:Concepts and Techniques,2nd ed [M].Beijing:China Machine Press,2006.
[2]郭麗.SQLServer2005構(gòu)建數(shù)據(jù)挖掘解決方案 [J].計算機與現(xiàn)代化.2007(5):1.
[3](美)陳封能,(美)斯坦巴赫,(美)庫瑪爾著,范明等譯.數(shù)據(jù)挖掘?qū)д?(完整版)[M].北京:人民郵電出版社.2011.
[4]謝邦昌.商務(wù)智能與數(shù)據(jù)挖掘Microsoft SQL Server應(yīng)用 [M].北京:機械工業(yè)出版社.2008.
[5](美)邁克倫南,(美)唐朝暉,(美)克里沃茨著,董艷,程文俊譯.數(shù)據(jù)挖掘原理與應(yīng)用 (第2版)—SQL Server 2008數(shù)據(jù)庫 [M].北京:清華大學(xué)出版社.2010.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
