基于數(shù)據(jù)挖掘的體育成績管理系統(tǒng)的設計
2014-02-20 01:18:12宋建駟
電子測試 2014年16期
宋建駟
(陜西科技大學,西安,710021)
基于數(shù)據(jù)挖掘的體育成績管理系統(tǒng)的設計
宋建駟
(陜西科技大學,西安,710021)
隨著我國信息化的不斷發(fā)展,使得我們已經(jīng)進入了新的大數(shù)據(jù)時代。因此,對信息的挖掘成為大數(shù)據(jù)下比較典型的特征。本文利用當前比較流行的數(shù)據(jù)挖掘技術(shù)中的決策樹算法,并結(jié)合學生體育測試成績,實現(xiàn)了對學校相關(guān)數(shù)據(jù)的挖掘,更好的利用體育教師對學生的教學。
數(shù)據(jù)挖掘;決策樹SLIQ 算法;體育成績測試;ASP.NET
隨著高等教育的不斷發(fā)展,對學生體質(zhì)的關(guān)注成為當前社會和學校共同關(guān)注的焦點。而如何更好的提高大學生的身體素質(zhì),并通過科學合理的數(shù)據(jù)分析和挖掘,為體育部教師、學校等提供可行性、科學性的方案,成為高校共同思考的一個問題。對于此,本人結(jié)合自身的工作,并結(jié)合當前的計算機技術(shù),對該話題進行了一定的思考,并設計了一套可應用于大學生體育成績挖掘的系統(tǒng),以更好的為各位體育老師提供準確性的教學參考。
1 系統(tǒng)設計關(guān)鍵技術(shù)
1.1 ASP.NET 技術(shù)
該技術(shù)是由美國的微軟公司根據(jù)需求開發(fā)的,其是以.NET的平臺而進行設計。而在設計中,該技術(shù)更多的是通過對動態(tài)頁面技術(shù)而實現(xiàn)對網(wǎng)頁的制作,簡單的說就是依靠網(wǎng)絡的軟件制作。而隨著該技術(shù)的在網(wǎng)頁設計中的使用,受到越來越多的人的喜愛,其主要的原因是該技術(shù)具有如下的優(yōu)勢:
(1)ASP.NET是在.NET和ASP兩者技術(shù)的基礎上共同提出來的,因此,該技術(shù)集合了兩者的之間的優(yōu)勢;
(2)在該技術(shù)中包含著很多的控件,這些空間可大大縮減軟件愛好者原本必須用語言變成才能實現(xiàn)的功能,從而使得軟件的開發(fā)變得簡單和簡易。
(3).NET架構(gòu)原本可支持多種形式的開發(fā)語言,因此,該技術(shù)不僅豐富了原本框架開發(fā)中的類,同時還可多種語言進行運用。
(4)該技術(shù)其優(yōu)點還表現(xiàn)在其強大的可移植性。這主要因為該技術(shù)的存儲是通過HTML,因此,只要儲存HTML的代碼,則可將其移植到新的軟件中,從而大大的縮短了軟件開發(fā)的時間。
1.2 SQL Server 數(shù)據(jù)庫
SQL Server 數(shù)據(jù)庫管理系統(tǒng)是當期比較流行的數(shù)據(jù)庫管理系統(tǒng)之一。該管理系統(tǒng)通過SQL 語句,實現(xiàn)對各種數(shù)據(jù)的查詢、刪除、添加和修改等功能,并可實現(xiàn)對不同數(shù)據(jù)的存儲。同時該系統(tǒng)多別使用在分布式的系統(tǒng)中,因此,其具有操作方便、功能強大等忐忑第三,從而實現(xiàn)對數(shù)據(jù)的多種訪問。在系統(tǒng)中,我們采用的是SQL Server 2008管理系統(tǒng),其主要的原因是該數(shù)據(jù)庫支持多種開發(fā)語言,并支持XML表格訪問;其次是多種技術(shù)封裝,有利于對技術(shù)的集成利用;其次其提供的性能更可靠,安全性更好。
1.3 數(shù)據(jù)挖掘技術(shù)
數(shù)據(jù)挖掘技術(shù)根據(jù)不同的分類,其可以被分為很多種不同的種類。而根據(jù)其挖掘的任務的不同,可以將數(shù)據(jù)挖掘技術(shù)分為如數(shù)據(jù)總結(jié)、分類挖掘、聚類方法等。而一般的數(shù)據(jù)總結(jié)在現(xiàn)實中如OLAP多維分析;分類挖掘則如貝葉斯、非參數(shù)、決策樹等;聚類方法則包括統(tǒng)計方法。而在該系統(tǒng)的設計中我們采用基于決策樹的SLIQ 算法。(其具體應用文中敘述)
2 系統(tǒng)功能設計
根據(jù)對體育成績管理的需求分析,我們將其系統(tǒng)功能分為系統(tǒng)管理、成績管理、測試類型管理、測試項目管理、成績分析幾大功能模塊。
其中,系統(tǒng)管理包括對系統(tǒng)相關(guān)數(shù)據(jù)的維護、備份和參數(shù)設置等,同時還包括對系統(tǒng)相關(guān)用戶權(quán)限的設置,對用戶的信息的刪除、編輯和添加,對系統(tǒng)相關(guān)信息的發(fā)布。
測試類型管理主要根據(jù)高校體育教學大綱而進行設置的。而起主要包括對類型的添加、刪除等功能。測試類型添加:該類型主要是添加新的測試類型,同時在添加到過程中系統(tǒng)會自動根據(jù)其添加的內(nèi)容進行驗證,包括該類型是否合法和為空;測試類型的修改,則主要是對原來的測試的類型進行相關(guān)的修改,并將最后的修改結(jié)果自動保存到相應的數(shù)據(jù)庫當中去;類型刪除主要對原來的數(shù)據(jù)進行刪除;分值權(quán)重設置是對每個不同的測試類型下其分值的相關(guān)權(quán)重進行的比例的相關(guān)設置。
測試項目則是對本學期不同科目考試的項目進行設置,如籃球、排球、跳高等項目。而管理則是在這個基礎上對這些考試項目的刪除、添加和修改,以及對不同的項目的分值權(quán)重的設置。
3 系統(tǒng)整體架構(gòu)設計
對該系統(tǒng)的實現(xiàn),我們采用三層結(jié)構(gòu),并采用ASP.NET技術(shù),實現(xiàn)動態(tài)頁面訪問,數(shù)據(jù)庫采用SQL Server 2008 數(shù)據(jù)庫。服務器操作系統(tǒng)采用WINDOW Advanced Server,并安裝IIS6.0。其具體的架構(gòu)如圖1所示。
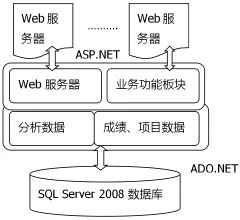
圖1 系統(tǒng)整體架構(gòu)設計
4 數(shù)據(jù)挖掘技術(shù)應用
在該系統(tǒng)中,我們選用SLIQ 算法,是因為該技術(shù)是基于ID3算法、C4.5算法,集合兩種算法的優(yōu)點,是兩種算法的改進型。因此,我們采用該算法。同時我們以體育成績和就業(yè)能力的關(guān)系進行挖掘為例,具體應用過程主要包括以下幾個步驟:
4.1 數(shù)據(jù)處理
所謂對數(shù)據(jù)的處理,是將不同結(jié)構(gòu)的數(shù)據(jù)進行合并,從而得出比較模糊的數(shù)據(jù)表格。而在這里的所謂的數(shù)據(jù)處理并不是簡單的數(shù)據(jù)合并,而是將不同的數(shù)據(jù)類型進行統(tǒng)一的、規(guī)范的處理,其需要統(tǒng)一數(shù)據(jù)中矛盾的地方,如字段名、單位長度等,從而形成最初的數(shù)據(jù)挖掘。
4.2 數(shù)據(jù)清洗
所謂的數(shù)據(jù)清洗,其實質(zhì)就是將系統(tǒng)中存在的噪聲數(shù)據(jù)、空白數(shù)據(jù)等進行刪除,并通過數(shù)據(jù)倉庫的形式,建立唯一的關(guān)聯(lián)表格的過程。
4.3 決策樹的創(chuàng)建
我們以學生成績與就業(yè)的關(guān)系作為該數(shù)據(jù)挖掘的示例,通過上述的數(shù)據(jù)處理和數(shù)據(jù)的清洗,并通過決策樹建模,我們可以得出以下的決策樹結(jié)果。
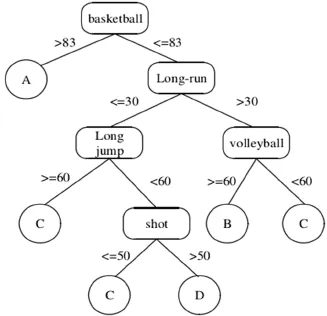
圖2 基于SLIQ 決策樹生成
其實現(xiàn)代碼:
1) fill in config information;
2) create and sort Attribute List, create Glass List;
3) create root:
4) scan class list in order to fill class histogram of root node;
5) push root to queue1; // queue1 是當前葉子節(jié)點隊列
6) if(root 為純節(jié)點) exit(0);7) white (not empty queue1) do
8)for each of the attribute A do //計算最佳分裂方案
9)if (A is a numeric attribute) then //數(shù)值型
10)for every record of A From 0 to maxn- 1 do
11)change class histogram:
12)if(treenode.newinfogain>treenode.infogain) then
13)update tree node 's threshold information
14)else if (A is a categorical attribute) //離散型
15)for every record of A from 0 to rnaxn- 1 do
16)add class information to the node //記錄每個屬性值對應的類的總個數(shù)
17)greedy algrithm to compute the split
18)if(treenode.newinfogain>treenode.intogain) then
19)update tree node 's threshold information
20) for each node N in queue1 do //執(zhí)行分裂
21) if (not enough info gain(N)) //執(zhí)行裁剪算法, 判斷是否有必要分裂
22)continue;//沒有必要分裂, 當前節(jié)點成為葉子
23) create left leaf and right leaf;
24) put the two new leaf into queue2; //queue2 是新葉子節(jié)點隊列
25) split the node by split info in the node
26) refresh class list
27) clean the pure node out of the queue2;
28) queue1=queue2;
29) store the tree node into database //將樹轉(zhuǎn)化為線性存儲方式存入 DB
4.4 結(jié)果輸出
通過上述的分析,我們可以得出各科不同的成績和就業(yè)之間的關(guān)系。其中籃球分數(shù)高的,其就業(yè)情況也通常比較好,這說明就業(yè)單位在對學生進行選擇的時候,通常選擇身體體質(zhì)比較好的學生。
5 結(jié)束語
本系統(tǒng)將ASP.NET技術(shù)和數(shù)據(jù)挖掘技術(shù)應用于體育成績管理系統(tǒng),有效的實現(xiàn)了對相關(guān)數(shù)據(jù)的挖掘,并通過HTML頁面將結(jié)果展現(xiàn)給廣大的體育教師,以此更好的實現(xiàn)對體育教學的制定。
[1] 黃芳.基于數(shù)據(jù)挖掘的決策樹技術(shù)在成績分析中的應用研究[D].山東大學,2010,78-83.
[2] Breiman L Friedman,H H R A,Stone C J.Classification Regression Trees[Z].Wadsworth International Group,2010,134-139.
[3] 饒云波,張應輝,等.基于 ASP.NET 的電子商務平臺設計與實現(xiàn)[J].計算機技術(shù)與發(fā)展,2009,16(5):160-162.
Design of the sports performance management system based on Data Mining
Song Jiansi
(Shaanxi University of Science and Technology,Xi'an,710021)
Along with the development of information industry in our country,so we have entered the era of big datanew.Therefore,mining the information be features of typical large data.This article uses the current popular datamining techniques of decision tree algorithm,and combined with the test scores of students in sports,the mining ofschool related data,better use of PE Teachers' teaching to the students.
data mining;decision tree SLIQ algorithm;physical performance test;ASP.NET
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
大眾投資指南(2021年35期)2021-02-16 01:06:26
北京測繪(2020年12期)2020-12-29 01:33:58
甘肅教育(2020年2期)2020-11-25 00:50:04
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
電力與能源(2017年6期)2017-05-14 06:19:37
中國科技信息(2016年20期)2016-12-08 06:39:48
學苑創(chuàng)造·A版(2016年9期)2016-10-10 11:14:12
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
