基于內容的音樂語義特征描述方法
2013-09-19 10:29:30張二芬徐淮杰
電子設計工程 2013年1期
張二芬,徐淮杰
(河海大學 計算機與信息學院,江蘇 南京 211100)
音樂是能夠代表人們情感、個人風格、精神狀況以及有關人性的其他方面的一種交流方式。盡管很多時候,對于同一首歌,不同的聽眾會給出不同的關鍵詞來描述,然而聽眾還是常常試圖使用關鍵詞來描述他們聽到的歌曲。使用關鍵詞的描述確實能夠反應音樂的一些內容,比如音樂的旋律、風格、表演樂器和用途等[1]。而且,對于聽眾來說,人們并不關心也不熟悉音樂的較底層音頻特征,而對于較高層的關鍵詞比較熟悉也比較感興趣。根據這一觀點,本文提出一種方法,能夠找到音樂的低層特征和高層語義描述之間的聯系,給出音樂的豐富的關鍵詞的描述,這將在音樂的相似度比較、基于內容的音樂檢索及推薦等方面提供很大的方便。
1 總體設計
該方法實現的總體結構圖如圖1所示,這里的每一個音樂文件都要經過短時窗的特征提取,組成一系列音頻特征向量,關鍵詞的選擇即是選取將要訓練的語義關鍵詞,并找到與關鍵詞相關的歌曲,將這些歌曲作為訓練集。這里的參數模型GMM是針對要進行訓練的每一個關鍵詞,取得關于其在音頻特征空間上的一種分布,每一個分布使用混合高斯模型(GMM)建模。每一個關鍵詞的GMM的參數估計是由和此關鍵詞相關的一系列歌曲組成的音頻內容來估計。通過GMM的參數估計,得到歌曲的關鍵詞的概率分布,從而得到語義特征向量,完成基于內容的音樂語義特征描述。
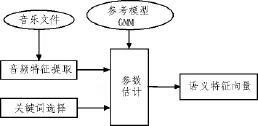
圖1 總體結構圖Fig.1 Structure diagram of the overall structure
2 音樂特征提取
音樂是一種重要的音頻類型,具有節奏、旋律和調性等要素,是人聲、樂器等發聲體配合所構成的聲音。除了聲波形式以外,音樂還可以用樂譜來進行表示,基于聲波形式的信號可以得到音樂的低層特征。特征提取是指尋找原始音頻信號的表達形式,提取能夠代表原始信號的數據[2]。一般采用的技術路線有2條:1)從疊加音頻幀中提取特征,其原因在于音頻信號是短時平穩的,所以在短時提取的特征比較穩定。2)從音頻片段中提取,因為任何語義都有時間延續性,在長時間刻度內提取的音頻特征可以更好地反映音頻所蘊含的語義信息,一般是提取音頻幀的統計特征作為音頻片段特征,特征參數提取圖如圖2所示。
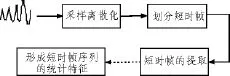
圖2 特征參數提取圖Fig.2 Diagram of the extracting of characteristic parameters
文中對基于音頻幀的低層特征進行了如下內容的提取。
1)節奏(tempo)音樂的節奏是一個廣義詞,包括音樂中與時間有關的所有因素,它指音樂運動中音的長短、強弱的變化規律,比如語義關鍵詞標注為 happy,excting,powerful等關鍵詞,相應的tempo值比較高,相反,語義關鍵詞標注為sad,tender,sleeping等關鍵詞,相應的 tempo值比較低。
2)旋律清晰度(pulseclarity)估算旋律清晰度,揭示了節拍的強度,強度越強,能量越大,信息量就越大。這一特征對于關鍵詞標注為流派的genre-pop,genre-soul,genre-rock等的區分性意義很大。
3)主調(mode)估計音樂的主要感覺,返回 major和minor的值,如果值大于0,且越大于0,預測的就是 major越多,反之值越小于0,minor越多,主要表征的是音樂信號的頻率信息。
4)調性(key)主要包括7個與主因有固定關系的音色的調因系統(如E大調)。在西方音樂中,調性一直是音樂的結構基礎。
5)清晰度(keyclarity)調性的清晰程度,找到最好的調。
6)音調中心(tonalcentroid)是在色譜圖的基礎上加入了和弦結構信息(五度循環圈)得到的六維信息,主要表征的是音樂信號的頻率信息,能夠檢測和弦的變化,反應音樂的旋律特征。
7)調強度(keystrength)計算key的強度。
在提取特征參數過程中,首先將音樂文件轉換成單聲道wav格式的音頻,每段音樂的位速是256 kbps,采樣大小是16位,采樣頻率為16 kHz,音頻格式為PCM。參考MIRtoolbox工具包[3],提取時間采用的是幀長5 s,幀移0.5 s,提取以上所述特征參數,得到1維的節奏(tempo),1維的旋律清晰度(pulseclarity),1維的主調 (mode),1維的音調(key),1維的音調清晰度(keyclarity),6維的音調中心(tonalcentroid),24維的調強度 (keystrength), 最終組成一個35維的長時特征矢量,這個步驟是在matlab環境下進行的。每首歌曲用一個txt文檔保存其按幀提取出來的的特征矢量。
3 音樂的語義特征標注
如何描述音樂的語義特征是一個關鍵問題。隨著生活條件的提高,人們越來越注重精神品味的培養,在不同的場合人們將需求不同的音樂,對音樂的用途提出了越來越明確以及細致的要求,這就要求我們能夠對音樂進行全面的剖析和描述。本文使用 Computer Audio Lab 500(CAL500)數據集[1]。其具體做法是,通過用戶一邊試聽音樂一邊對音樂進行關鍵詞標注的方法,對語義標簽給出了一個清晰的定義集本。這些語義詞包括18種表示情感的標注,如emotion-happy,notemotion-happy等;36種表示流派的標注,如 genre-pop,genrerock等;29種音樂器具的標注,如instrument-bass,instrumentpiano等,等等。這個數據集要反應出語義詞與歌曲之間聯系的程度,因此對于每一首歌,在給出一系列關鍵詞標簽的同時,也給出了標簽對應的分值。這樣每一首歌,都由一個數值向量來表示,其數值分布在0到1之間,0表示這首歌與這個關鍵詞不相關,1表示極其相關。
對于接下來要做的模型的訓練,要進行關鍵詞的選擇,即選擇要進行訓練的關鍵詞,找出這個關鍵詞分值大于0的這些歌曲,作為訓練集,生成基于關鍵詞的模板。
4 實 驗
4.1 混合高斯模型(Gaussian Mixture Models,GMM)原理
GMM[4]訓練的過程,首先需要進行樣本的選擇。對于每一個單詞來說,要進行一個GMM的訓練,訓練樣本集的選擇即是與這個單詞相關的歌曲。這里選擇單詞標注值大于0的歌曲作為訓練樣本集,實驗中,500首歌中隨機選擇85%作為訓練集,剩下的15%作為測試集。
高斯混合模型由M個多維的高斯概率密度函數線性加權求和構成,可以用公式表示如下:
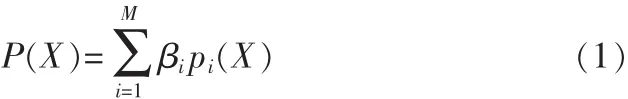
其中X是N維音頻信號特征矢量,M是混合高斯模型的階數,pi(X)是高斯混合模型分量,βi是對應高斯混合分量pi(X)的加權因子。
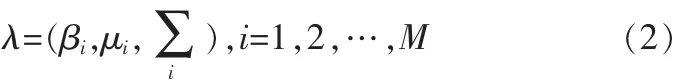
在獲得了音樂的低層特征之后,GMM的訓練即是估計模型的參數,即通過最大似然估計法,給定訓練矢量集的情況下,尋找合適的模型參數,使得GMM的似然函數最大[5-6]。
高斯混合模型的似然函數表達式如:
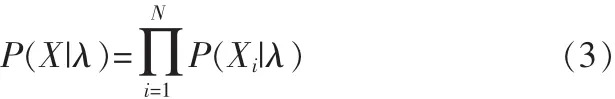
其中 X 為訓練矢量集,X={x1,x2,…,xn}。
對于高斯混合模型的階數M的選擇,一般情況是M選取的大一些比較好,但也并不是M越大越好,況且隨著M的增大,對于訓練的時間成本也造成很大了影響。文中使用M為9的混合高斯模型進行訓練,得到基于關鍵詞的模板的均值和方差以及對應的權重。
4.2 語義特征向量的形成
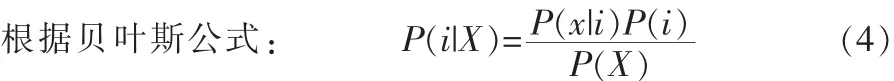
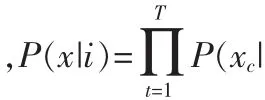
經過GMM的訓練得到詞匯庫中每一個關鍵詞的均值和方差,接下來使用貝葉斯法則去計算每一個關鍵詞的先驗概率[1]。i),根據全概率公式得到
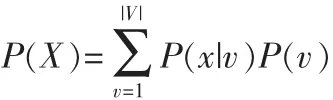
這樣可得
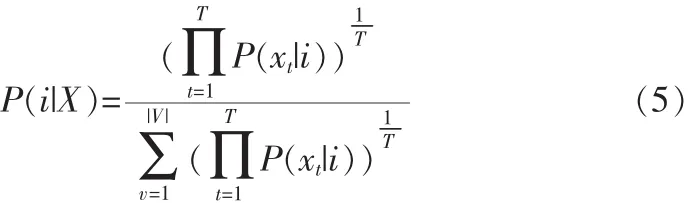
使用公式(5)可以計算出每一個單詞在一首歌里出現的概率。對于一首歌,將得到這首歌的所有關鍵詞模型的概率向量,在這里將這個概率向量稱為語義特征向量,這樣完成了由低層音頻特征向高層語義特征的一個映射。語義特征分布圖如圖3所示,這里是對于air_sexy_boy.wav這首歌的詞匯庫中關鍵詞的語義特征向量分布,圖中還標注出了對于這首歌描述的8個最大概率的關鍵詞。
5 結 論
文中提出的基于內容的音樂語義特征描述方法,采用提取音樂豐富的較低層音頻特征,訓練基于語義關鍵詞的GMM模型,不僅給夠對歌曲進行語義關鍵詞的描述,而且還能夠給出關鍵詞的程度。對于一首歌來說,使用語義特征分布來代表一首歌是十分有意義的,這將對于音樂的檢索或是推薦分析工作都提供了很大的方便。使用語義特征向量來表征一首歌,一方面給出了底層音頻特征到高層語義特征的映射關系,彌補了語義空缺;另一方面,將音頻信息轉化成更易于處理的數值信息,這對于音樂的相似度比較,提供了一個很好的入口。
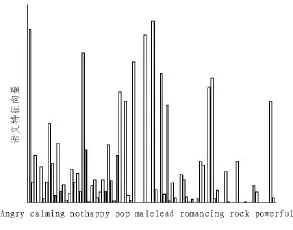
圖3 語義特征分布圖Fig.3 Diagram of the Semantic features distribution
[1]Turnbull D,Barrington L,Torres D,et al.Lanckriet.Towards Musical Query-by-Semantic Description Using the CAL500 Data Set[EB/OL][2012-8-10].http://cosmal.ucsd.edu/cal/pubs/MusicQBSD_SIGIR07.pdf
[2]韓紀慶,鄭鐵然,鄭貴濱.音頻信息檢索理論與技術[M].北京:科學出版社,2011.
[3]Lartillot O.MIRtoolbox1.3.2 User’s Manual[M].Finland:Finnish Center of Excellence in Interdisciplinary Music Research University of Jyvaskyla,2011.
[4]Reynolds A,Rose C.Robust text-independent speaker identification using caussian mixture speaker Models[J].IEEE Transactions on Speech and Audio Processing,1995,3(1):72-83.
[5]Steve Young,Dan Kershaw,Julian Odell,et al.The HTK Book for HTK Version3.4[M].Cambridge University Engineering Department(CUED),2009.
[6]Timo Sorsa and Jyri Huopaniemi Nokia Research Center.Speech and Audio Systems Laboratory.Melodic Resolution in Music Retrieval[EB/OL][2012-8-10].http://ismir2001.ismir.net/posters/sorsa.pdf.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童繪本(2017年24期)2018-01-07 15:51:37
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
東方藝術·大家(2016年6期)2016-09-05 07:30:56
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
外語學刊(2011年1期)2011-01-22 03:38:33
