基于聯合索引的下一代圖書館學術資源搜索研究
2012-12-06 02:32:22朱本軍
大學圖書館學報 2012年2期
□朱本軍
早期圖書館的數字資源建設思路,一般是根據擬建資源的類型開發出一套完整的資源管理和發布系統:后臺著錄與管理界面+數據庫+前端讀者檢索界面。隨著數字資源類型和用途的越來越多,圖書館資源系統也越來越多,除了本地書目系統和本地數字館藏(如學位論文、古籍等),還有大量期刊數據庫。據不完全統計,高校圖書館目前擁有的資源發布系統包括:
●圖書館網站:1個或多個,如門戶、圖書館博客等;
●本地書目系統:1個,如自動化集成系統;
●本地數字館藏系統:1個或多個,如學位論文、古籍(多個);
●本地或遠程電子書系統:1個或多個,如方正電子書、NetLibrary等;
●商業數據庫:幾十個至幾百個不等,如Pro-Quest、EBSCO、JSTOR、中國期刊網、維普數據庫等。
各類資源呈分布式異構發展,系統之間差別較大:大多數系統基本上都是獨立的系統,數據不能被其他系統調用;各系統用不同程序語言(如JAVA、PHP、C等)開發;各系統在內容、結構、服務方式和管理策略上各不相同;各個系統的元數據著錄格式也各不相同,有自定義的(多見于本地自建資源系統)、有遵循區域規范的(如CALIS元數據標準規范、CNMARC、USMARC等)、有遵循行業規范的(如用于圖書在線交換的ONIX標準)等。由于各系統分布式異構,很難將所有的資源整合在一起揭示,給圖書館用戶帶來了諸多額外負擔[1]:增加用戶選擇和熟悉各資源分布的時間;各資源系統內容交叉重復,增加了讀者信息鑒別和去重的時間;各資源系統之間數據的關聯度低,增加用戶知識銜接的負擔。如何快速有效查找和利用圖書館的數字資源是圖書館一直面臨的重要課題。
本文在對圖書館學術資源檢索模式進行回顧的基礎上,評介一種基于索引的學術資源搜索引擎及其工作模式。基于整合索引的學術搜索引擎較好地解決了資源查找效率和顯示的問題,是下一代圖書館學術資源檢索的趨勢。為使讀者深刻理解這種基于索引的學術搜索引擎,本文對常見的三個典型代表SUMMON、Google Scholar和SCIRUS進行案例分析和研究。
1 圖書館資源檢索的模式:歷史回顧
1.1 本地資源檢索模式:實時檢索和本地索引
本地獨立資源管理與發布系統可能在功能上有的復雜有的簡單,有的也有API數據接口,它們有大致相同的系統架構:元數據著錄與后臺管理+數據庫+用戶檢索界面。這樣的系統目前在圖書館分布非常普遍,典型的例子如圖書館自動化集成系統、方正學位論文系統、圖書館門戶等。
本地獨立資源管理與發布系統的檢索模式有兩種:一是實時檢索數據庫(如圖1)。這種檢索模式一般在數據量比較小的情況下使用。這種實時檢索數據庫模式的缺點非常明顯:在數據量非常大的情況下,查詢響應的效率非常低。以圖書館的自動化集成系統為例,一般擁有幾十萬甚至上百萬條書目記錄,如果采用實時檢索數據庫的方式,每一次顯示結果,需要幾秒、十幾秒的等待時間。
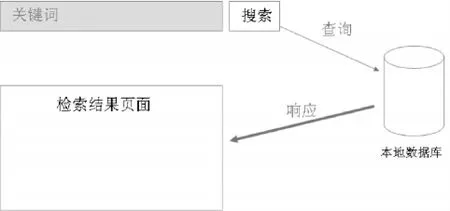
圖1 實時檢索數據庫模式
在數據量比較大的情況下,一般采用第二種方式:數據庫本地索引模式(如圖2)。這種模式的工作機制是:在檢索之前對系統數據庫關鍵詞做索引,索引后每秒可以檢索幾百萬條數據,大大提高查詢和使用圖書館資源的效率。各高校使用的自動化集成系統,大部分都采用了這種模式。
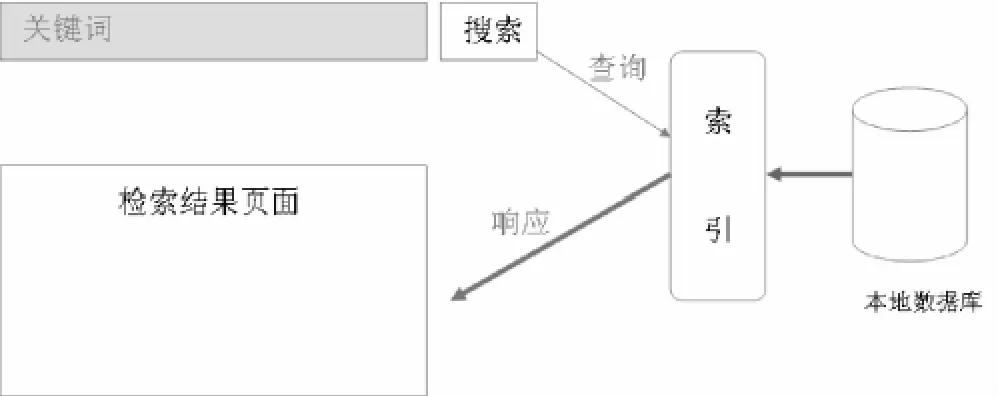
圖2 本地數據庫索引模式
1.2 分布式異構資源檢索模式:聯邦檢索
隨著圖書館資源越來越多,圖書館的資源系統更多呈分布式發展:每個圖書館都有十幾個甚至幾十個資源系統的檢索入口。分布式資源系統增加了用戶選擇和熟悉各資源分布情況的負擔,并且各資源系統本身也存在內容交叉重復,各資源系統之間數據的關聯度低的狀況,不利于圖書館資源的綜合利用。圖書館開始考慮以單一檢索入口檢索分布在圖書館的所有學術資源的方式,比較典型且在圖書館應用廣泛的例子是利用聯邦檢索系統檢索商業數據庫。
聯邦檢索,有時稱為整合檢索、元搜索、同步檢索、跨庫檢索、并行檢索或廣播檢索,包含三個過程(如圖3)[2]:(1)用戶發出查詢請求,聯邦檢索引擎對查詢請求進行語法轉換,然后廣播到各數據庫檢索引擎;(2)各數據庫檢索引擎將查詢到的結果反饋給聯邦檢索系統,聯邦檢索系統對反饋的結果進行合并、查重等實時處理;(3)將處理后的結果集以一種簡潔、統一的格式展現在結果頁面。
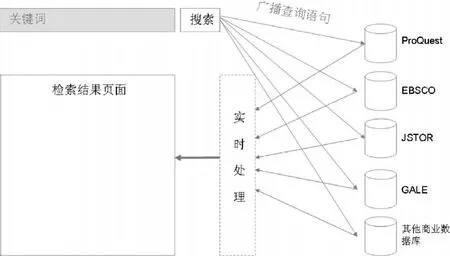
圖3 分布式資源聯邦檢索模式
聯邦檢索的前提是每個資源系統都有一個本地搜索引擎,聯邦檢索將各個本地搜索引擎整合在一起而不管資源系統本身的架構,因此聯邦檢索可以將異構和同構的資源系統整合在一起。應用聯邦檢索系統,圖書館不僅可以整合檢索電子期刊商業數據庫(如JSTOR、EBSCO、ProQuest等商業數據庫),還可以整合檢索本地館藏目錄、本地數字館藏(如學位論文、特藏庫等)等。
雖然聯邦檢索解決了圖書館分布式異構系統通過同一入口揭示所有學術資源的問題,但是也有很多問題:
一是檢索速度受網絡、聯邦檢索服務器性能和數據源服務器性能影響較大。檢索時間包含廣播查詢語句到各搜索引擎的時間、數據源服務器處理查詢請求的時間、各資源系統返回查詢結果的響應時間和在聯邦檢索服務器上對查詢結果進行查重等處理的時間。這些時間又受到網絡連接速度、聯邦檢索服務器和數據源服務器性能的影響。
二是檢索結果集比較淺,且是偏態的。由于返回和檢索時間比較長,為減少用戶等待時間,聯邦檢索系統會先從各個資源系統返回少數結果。這種結果并不是對所有資源綜合計算后的結果,而是按照返回的時間順序給出的結果。
三是對結果集很難進行組織和相關度排序。主要是因為檢索返回的結果都是動態的。
1.3 本地資源和分布式資源混合檢索:混合模式
為了進一步提升資源檢索效率,圖書館采用了另外一種方式:本地索引和聯邦檢索相結合的混合模式。混合檢索比較典型的產品,如下一代圖書館目錄Primo、Encore、AquaBrowser等。它們可以通過一個統一的、帶不同標簽可切換的檢索入口(如圖4)完成本地資源和遠程資源的檢索:當用戶要檢索圖書館本地資源時,只需要切換到搜索框上面的“本地館藏”標簽即可;當用戶要檢索遠程的商業數據庫時,則切換到“數據庫”標簽即可。

圖4 混合檢索用戶界面
混合檢索的實現機制(如圖5)是:將圖書館本地的所有資源,包括本地館藏目錄、本地數字館藏(如機構庫、特藏庫等)進行統一索引;而對分布在遠程的商業數據庫仍然實現聯邦檢索。混合檢索模式解決了圖書館本地所有資源快速響應和結果集組織與顯示的問題,但對于遠程商業數據庫仍然不得不采用聯邦檢索模式。
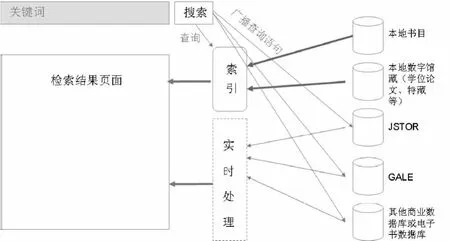
圖5 混合檢索模式
2 下一代圖書館資源整合檢索模式:基于聯合索引
混合檢索模式雖然解決了用戶單一資源檢索入口的問題和本地資源集中快速訪問的問題,但是仍然沒有解決聯邦檢索中遠程數據庫檢索和獲取慢、相關度不高和結果集排列混亂的問題。
下一代圖書館的學術資源搜索引擎,采用本地數據和遠程數據統一集中索引的方式達到對圖書館全部學術資源整合檢索的目的(圖6)。
在這種模式下,圖書館擁有和使用的所有學術資源(包括元數據、文章全文)在提供用戶檢索之前,全部被提前處理成規范的、結構化的XML數據。此外,還在XML數據的基礎上進行查重、FRBR、內容增強(將其他網站的數據整合到單條記錄中豐富記錄信息,如封面、目錄等)等處理,最后集中索引形成一個龐大的索引數據庫。
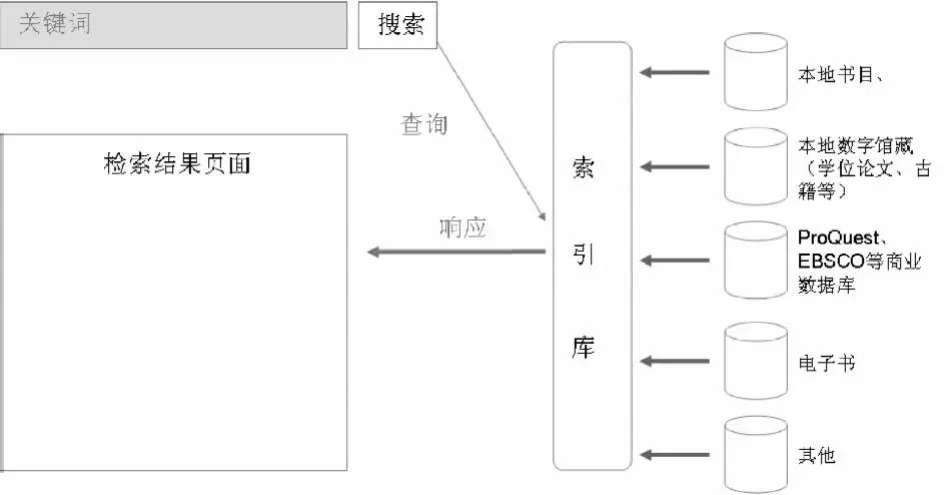
圖6 下一代圖書館學術資源聯合索引檢索模式
經過查重、FRBR和內容增強等處理后的索引庫,不僅解決了資源重復、不同版本多條顯示、記錄信息量少的問題,而且可以每秒幾百萬條記錄的速度提供實時查詢響應。除此以外,由于數據通過XML進行了非常好的結構化組織,資源和資源之間可以形成某種關聯,結果集也可以通過web2.0技術得到非常好的組織和排列。
3 基于索引的學術搜索引擎案例研究
基于索引的圖書館學術資源整合檢索模式,很早就在各大型商業數據庫中使用,如美國的洛斯阿拉莫斯國家實驗室(Los Alamos National Laboratory)、加拿大多倫多大學(the University of Toronto)、丹麥技術知識中心(the Technical Knowledge Center of Denmark)、德國的馬克思普蘭克學會(the Max Planck Society)等,它們都提供了存儲在本地的大量電子期刊檢索服務,用戶只要在檢索界面輸入關鍵詞,很快就能獲得相關文章的全文鏈接[3]。
這種基于學術資源索引模式的產品趨于成熟,并于最近幾年在圖書館相關行業被廣泛使用。比較典型的例子,如專用于科學信息檢索的SCIRUS[4]、Google Scholar學術搜索引擎[5],圖書館系統提供商360Serials Solution公司的SUMMON產品、Innovative公司的Encore Synergy[6]、EBSCO Host公司的EDS(EBSCO Discovery Service)產品,以及Ex Libris公司的Primo Central產品。下面對Google Scholar學術搜索、SUMMON和SCIRUS三個產品進行案例研究,以便對基于索引的搜索模式有更深入的了解。
3.1 Google Scholar學術搜索引擎
Google Scholar學術搜索于2004年10月面世。自其推出以來,即受到教育和學術科研機構的青睞。
Google Scholar學術搜索引擎本質上是在學術資源索引庫的基礎上架設一個Google搜索引擎(如圖7)。其中Google搜索引擎采用了Google公司專有的PageRank相關度頁面排序技術,返回的結果帶有引文信息、版本信息等學術信息。其學術資源索引庫集中了大量的各類學術資源,包括普通網頁中的學術論文、同行評議文章、學位論文、圖書、預印本、文摘、技術報告等學術文獻,文獻來源于學術出版物、專業學會、預印本庫、大學機構,內容從醫學、物理學到經濟學、計算機科學等橫跨多個學術領域[7]。
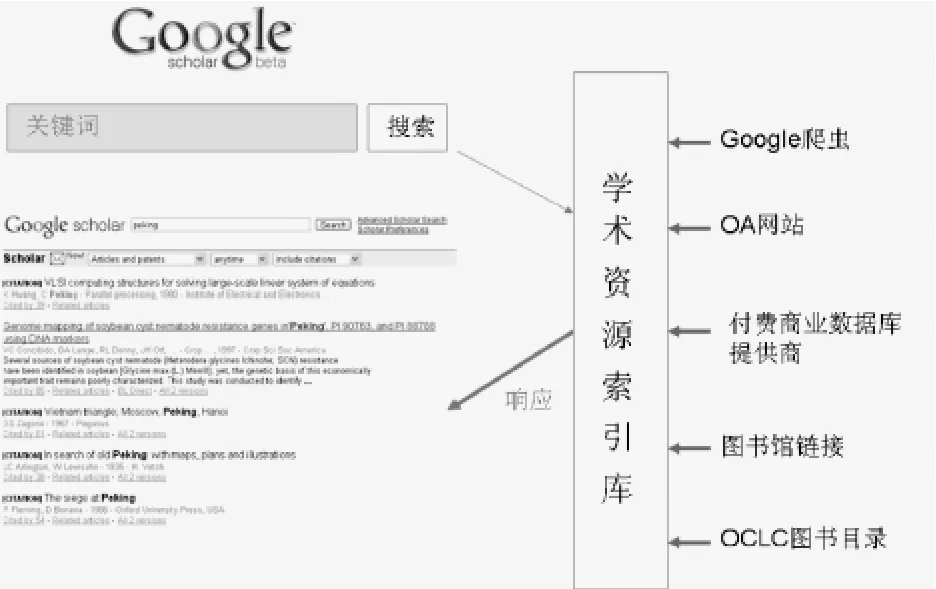
圖7 Google Scholar學術搜索
Google Scholar學術資源索引庫中的數據大致有如下幾個方面的來源[8]:一是Google爬蟲搜集到的網上免費的學術資源,包括已經發表的論文、論文的預印本、工作報告、會議論文、調研報告等有學術價值的文獻。二是開放獲取的期刊網站,如英國牛津大學出版社、斯坦福大學的High Wire出版社出版的學術期刊,大部分已被Google Scholar所涵蓋。三是付費電子資源提供商,通過與Google Scholar合作向Google Scholar提供電子數據庫的元數據和摘要。四是圖書館鏈接,Google Scholar通過向圖書館發出免費鏈接邀請,讓圖書館提供本地學術資源數據,并提供面向這些圖書館資源的鏈接和查詢。五是OCLC提供的書目數據[9]。
3.2 SCIRUS科學信息搜索引擎
SCIRUS是一個由Elsevier Science開發,比Google Scholar更早利用學術資源索引庫的大型搜索引擎。SCIRUS與Google Scholar的不同之處在于SCIRUS專門提供科學信息的檢索。
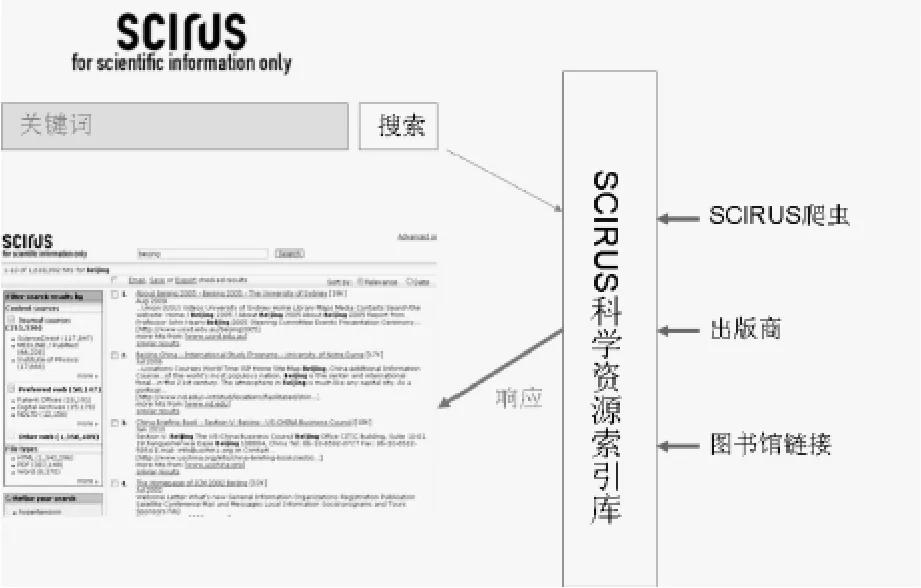
圖8 SCIRUS科學信息搜索引擎
SCIRUS涵蓋的資源的主要來源:一是SCIRUS爬蟲,搜集各與科學相關的網站和文檔,并對這些網站進行深度索引。從其官方資料中了解到其資源主要來自互聯網,目前涵蓋3.8億個與科學相關的網站,包括:1.26億.edu站點、0.4億個.org站點、0.2億個.ac.uk站點、0.38億.com 站點、0.38億個.gov站點和1.18億其他相關科技與社會研究及大學網站[10]。二是出版商,如 NASA、BioMed、ScienceDirect、Royal Society Publishing 等[11]。三是圖書館鏈接,接受來自世界各地的圖書館鏈接[12]。所有這些科技信息網站的索引信息,包括文章、電子印本、同行評價文章、專利、文檔、期刊文章等[13]。
SCIRUS的工作機制(如圖8):首先將不同來源的資源進行索引,形成SCIRUS科學資源索引庫;然后提供SCIRUS專有的搜索引擎界面。
3.3 SUMMON學術資源索引服務
SUMMON是360Serials Solution公司推出的一款數據服務類產品,于2009年1月面世,同年7月開始在全球范圍銷售。目前已有一些大學圖書館用戶,如密歇根州州立大河谷大學圖書館[14]、悉尼大學圖書館[15]、西悉尼大學圖書館[16]等。
SUMMON的原理是提供一種數據服務(如圖9),將不同來源的學術資源和摘要集中索引成一個索引數據庫,并提供開放的API數據接口供其他系統調用。不過,為了更好地利用數據、推廣SUMMON,360Serials Solution公司在推出SUMMON產品的時候在學術資源索引庫上架設了一個用戶界面。用戶界面使用的是一款開源全文搜索引擎Lucene/SOLR,學術資源索引數據庫是對360Serials Solution擁有或與其有合作關系的數據庫提供商提供的所有資源的元數據、摘要甚至全文的索引。
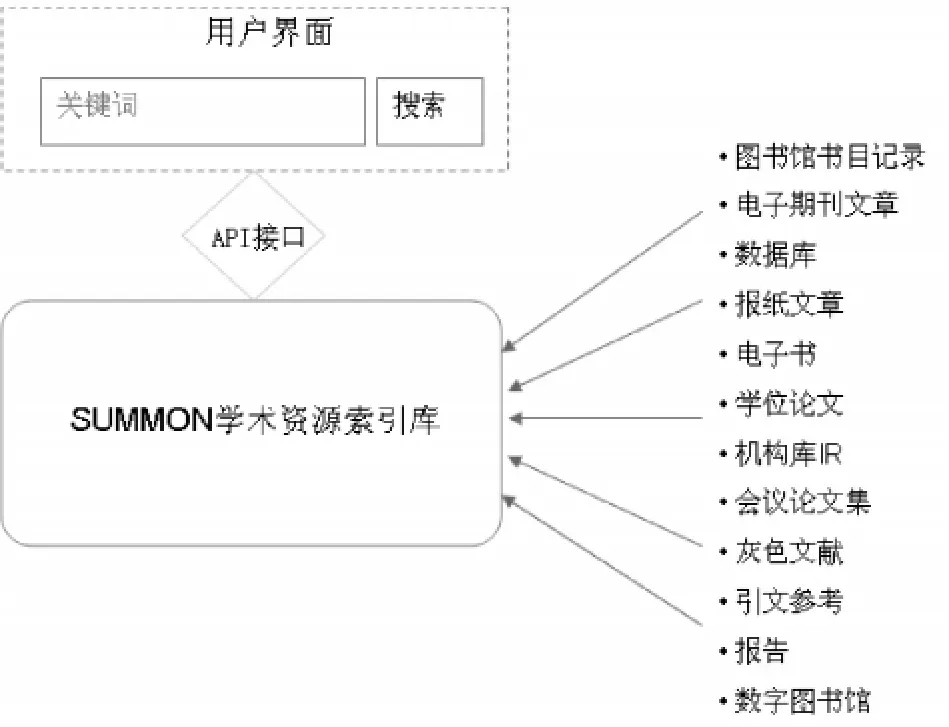
圖9 SUMMON數據服務
SUMMON的學術資源索引的涵蓋范圍可以包括圖書館本地書目記錄、電子期刊文章、數據庫、報紙文章、電子書、學位論文、機構庫、會議文集、灰色文獻、引文、報告和數字圖書館[17]。索引數據主要有兩個來源:一是付費數據庫提供商,通過與內容提供商簽署合作協議來達成,主要是期刊和報紙出版商、電子書出版商和第三方整合者[18];二是購買SUMMON產品的圖書館提交的本地資源,包括本地書目記錄、本地數字館藏和圖書館其他愿意通過SUMMON揭示的資源。
4 結論
從對圖書館學術搜索的三種模式的歷史回顧,以及對三個學術資源搜索引擎的案例研究中,可以看出下一代圖書館學術資源搜索引擎在搜索模式上并沒有特別創新之處,主要是觀念上的變化:從把搜索系統整合在一起的聯邦檢索,轉向把數據整合在一起,將數據作為一種服務,提供面向服務的索引數據。
基于索引的服務模式,不僅解決了單一搜索框高效快速檢索圖書館所有本地和遠程分布式異構學術資源的問題,而且還通過提供標準化、結構化的XML數據解決了結果集的組織和排列問題。這種基于索引的搜索服務將會成為目前和未來圖書館學術資源搜索的主流模式。這也是本文采用“下一代”這個詞的主要原因。
1 李書寧.數字圖書館跨庫檢索技術研究.數字圖書館論壇,2005(2):6-9
2 Péter Jacsó.Thoughts About Federated Searching.Information Today,2004,21(9):17
3 Tamar Sadeh.Google Scholar Versus Metasearch Systems.High Energy Physics Libraries Webzine,2006(12).[2010-06-04].http://library.web.cern.ch/library/Webzine/12/papers/1/
4 SCIRUS.[2010-06-04].http://www.scirus.com
5 Google Scholar.[2010-05-31].http://scholar.google.com
6 Innovative Launches Encore Synergy.[2010-10-04].http://encoreforlibraries.com/2010/04/16/innovative-launches-encore-synergy
7 關于Google學術搜索.[2010-06-04].http://scholar.google.com/intl/zh-CN/scholar/about.html
8 段其憲.Google Scholar成功特性分析.現代情報,2007(7):221
9 Norman Oder.So,Can Google Use OCLC Records?Yes,But.[2010-06-03].http://www.libraryjournal.com/article/CA6695887.html
10 The Range of Scientific Content Scirus Covers.[2010-06-04].http://scirus.com/srsapp/aboutus/#range
11 More About Scirus Information Sources.[2010-06-04].http://scirus.com/srsapp/aboutus/#sources
12 About Scirus Library Partners.[2010-06-04].http://scirus.com/srsapp/librarypartners/
13 About Scirus.[2010-06-04].http://www.scirus.com/srsapp/aboutus/
14 Grand Valley State University Library.[2010-06-04].http://gvsu.edu/library
15 The University of Sydney Library.[2010-06-04].http://www.library.usyd.edu.au/
16 University of Western Sydney Library.[2010-06-04].http://library.uws.edu.au/
17 Summon Overview.[2010-06-04].http://www.serialssolutions.com/summon
18 Summon Content Participants.[2010-06-04].http://www.serialssolutions.com/summon-content-participants/
猜你喜歡
小太陽畫報(2018年1期)2018-05-14 17:19:25
財經(2017年2期)2017-03-10 14:35:35
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國衛生(2015年12期)2015-11-10 05:13:38
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
