樣本量估計及其在nQuery和SAS軟件上的實現——均數比較(一)
2012-12-04 02:59:38段重陽陳平雁
中國衛生統計 2012年1期
關鍵詞:方法
呂 朵 段重陽 陳平雁
樣本量估計是研究設計中的一個極為重要環節,如何正確估計樣本量即使對于統計專業人員都是較難把握的技能。目前,無論是統計專業人員還是非專業人員在實施樣本量估計時大多面臨以下三個問題:其一,目前國內尚缺乏系統地介紹樣本量估計方法的文獻,從而導致在實驗設計階段進行樣本量估計時手段受限,尤其涉及到臨床試驗中應用較多的非劣性檢驗和等效性檢驗,以及一般研究中非參數檢驗、多元回歸和相關分析的樣本量估計方法。其二,由于國內的教科書、專著和一些相關的期刊論著在介紹樣本量估計方法時缺乏源頭文獻的引用,加之某些設計的樣本量估計方法不止一種,我們采用的方法是否準確和權威?我們應用的究竟是誰提出的方法?其三,樣本量估計的應用軟件并不普及,如果依靠研究人員自己編程會有相當難度。
鑒于上述原因,我們以樣本量估計專業軟件nQuery Advisor 7.0〔1〕為依據(因為該軟件目前被國際上公認為樣本量估計的權威軟件之一,同時得到美國FDA的認可),系統介紹樣本量估計方法,給出計算公式及其權威出處,通過實例加以說明,并附有nQuery Advisor 7.0的操作主界面和樣本量估計中參數設置的界面,以及SAS 9.2軟件實現的程序,便于廣大讀者應用。為了驗證nQuery Advisor 7.0計算結果的準確性,同時用SAS 9.2軟件及R語言由雙人乃至三人獨立編程進行驗證,以確保無誤。由于篇幅所限,本系列文章將側重基于差異性檢驗與等效性檢驗的樣本量估計方法,基本不涉及基于可信區間的樣本量估計方法。有關R語言實現的程序將有另文介紹。
全部內容按統計分析方法分為五個部分,分別為均數比較、率的比較、生存分析、相關分析、回歸分析的樣本量估計,詳細目錄見表1。所涉及的參考文獻均列在每個部分的結尾處。
因本文涉及的樣本量計算公式較多,凡公式中出現的相同符號統一定義如下:
α:檢驗水準;
1-β:檢驗效能;
s:取1代表單側檢驗,取2代表雙側檢驗;
MSE:均方差;
CV:變異系數;
各類參數:如μ(總體均數)、σ(總體標準差)等,這些參數一般未知,通常根據優先順序 — 預試驗結果、他人研究結果、假設等三種方式進行估計。
若個別公式中的符號與上述定義不符,或另有含義,將以個別公式的定義為準。
1 均數比較
1.1 單樣本均數的比較
1.1.1 差異性檢驗
1.1.1.1 單樣本t檢驗
方法:O'Brien和Muller(1993)〔2〕給出的單樣本t檢驗的樣本量估計是建立在自由度為n-1,非中心參數為的非中心t分布基礎上。其檢驗效能的計算公式為:
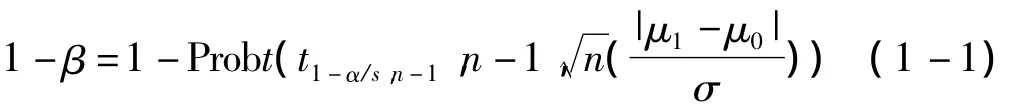

表1 樣本量估計方法目錄
式中,μ1為預期總體均數;μ0為已知總體均數;σ為預期的總體標準差。
在計算樣本量時,一般先設定樣本量初始值,然后迭代樣本量直到所得的檢驗效能滿足條件為止。此時的樣本量,即研究所需的樣本量。
【例1-1】某研究欲驗證從事鉛作業男性工人的血紅蛋白含量是否與正常成年男性平均值(140 μg/L)有差異。預試驗測得從事鉛作業男性工人的血紅蛋白含量均值130.83 μg/L,標準差 25.74 μg/L。如果設定α為5%水平,檢驗效能為85%,雙側檢驗,統計分析采用單樣本t檢驗,試估計樣本量。
nQuery Advisor 7.0實現:設定檢驗水準 α=0.05;雙側檢驗,即s=2;檢驗效能取1-β=85%。依據上述基礎數據可知,μ1=130.83,μ0=140,σ =25.74。在nQuery Advisor 7.0主菜單選擇:
Goal:Make Conclusion Using:⊙Means
Number of Groups:⊙One
Analysis Method:⊙Test
方法框中選擇:One group t-test for difference in means
在彈出的樣本量計算窗口將各參數鍵入,如圖1-1所示,結果為n=73。即本試驗的最少樣本量為73例。

圖1 -1 nQuery Advisor7.0關于例1-1樣本量估計的參數設置與計算結果



圖1 -2 SAS 9.2關于例1樣本量估計的參數設置與計算結果
1.1.1.2 基于差值均數的配對t檢驗
方法:與單樣本t檢驗相同,見式(1-1),只需將μ1定義為預期差值的總體均數μd=μ1-μ2;已知總體均數μ0定義為0;σ為預期差值的總體標準差。
【例1-2】在一項將要開展的減肥新藥臨床試驗中,采用自身前后對照的配對設計。由預試驗得到的初步結果顯示,未服藥前的體重指數(BMI)均數為28.5,服藥治療后的BMI均數為26.0,服藥前后差值的標準差為4.5。如果設定α為5%水平,檢驗效能為85%,雙側檢驗,統計分析采用配對t檢驗,試估計樣本量。
nQuery Advisor 7.0實現:設定檢驗水準 α=0.05;雙側檢驗,即s=2;檢驗效能取1-β=85%。依據上述基礎數據可知,μ1=28.5,μ2=26.0,σ =4.5。在nQuery Advisor7.0主菜單選擇:
Goal:Make Conclusion Using:⊙Means
Number of Groups:⊙One
Analysis Method:⊙Test
方法框中選擇:Paired t-test for difference in means
在彈出的樣本量計算窗口將各參數鍵入,如圖1-3所示,結果為n=32。即本試驗的最少樣本量為32例。
SAS 9.2軟件實現:


圖1 -3 nQuery Advisor7.0關于例1-2樣本量估計的參數設置與計算結果



圖1 -4 SAS 9.2關于例2樣本量估計的參數設置與計算結果
1.1.1.3 單個重復測量因素方差分析
方法:Dixon和 Massey(1983)〔3〕給出的單個重復測量因素方差分析的樣本量估計是建立在自由度為M-1和(M-1)(n-1),非中心參數為 nM(V/σ2·(1-ρ))的非中心F分布上。其檢驗效能的計算公式為:

式中,M為重復水平數;V為各個水平均數的方差;ρ為水平間的相關系數;σ為每一水平的總體標準差。
在計算樣本量時,一般先設定樣本量初始值,然后迭代樣本量直到所得的檢驗效能滿足條件為止。此時的樣本量,即研究所需的樣本量。
【例1-3】一項旨在提高兒童自尊心的心理干預試驗中,用一個滿分為100的兒童自尊心量表分別在干預前、干預后1個月、2個月,3個月對受試兒童進行測量,以評估干預效果。通過預試驗獲得干預前得分為55,第一次測量和一月后第二次測量之間的相關系數為0.7,兩次測量的合并標準差為10。研究者預期經過三個月的干預后得分上升到59.5。試估計本研究在檢驗效能為90%的情況下所需樣本量。
nQuery Advisor7.0實現:設定檢驗水準α=0.05;檢驗效能取1-β=90% 。依據上述基礎數據可知,ρ=0.7,σ =10,M=4。在nQuery Advisor7.0 主菜單選擇:
Goal:Make Conclusion Using:⊙Means
Number of Groups:⊙One
Analysis Method:⊙Test
方法框中選擇:Univariate one-way repeated measures analysis of variance。
注意,這里首先應根據不同時間觀察結果對V進行估計,假設測量得分逐步均勻升高。在菜單欄中選擇:
Assistants:⊙Compute Effect Size
在彈出的計算窗口將各參數鍵入,如圖1-5所示,結果為V=2.813。

圖1 -5 nQuery Advisor7.0關于例1-3樣本量估計的參數計算結果

圖1 -6 nQuery Advisor7.0關于例1-3樣本量估計的參數設置與計算結果
在圖5界面點擊Transfer按鈕,計算結果V值顯示于主對話框(圖1-6),在主對話框再鍵入其他參數,結果為n=40。



圖1 -7 SAS 9.2關于例1-3樣本量估計的參數設置與計算結果
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
