HPC集群編程模型研究
2012-11-09 06:41:06許建亞田園齊記周慶國
中國教育網絡 2012年4期
文/許建亞田園 齊記 周慶國
HPC集群編程模型研究
文/許建亞1田園1齊記1周慶國2
高性能計算是計算科學的一個分支,研究并行算法和開發相關軟件,并致力于開發高性能計算機。目前較為流行的并行程序設計模型為基于消息傳遞M P I(Message Passing interface)的編程模式,基于共享內存的Ope MP模式和結合MPI+OpenMP的混合編程模型,以及利用GPU作為并行數據計算設備(GPU計算的模式就是在異構協同處理計算模型中,將CPU與GPU結合起來加以利用, 應用程序的串行部分在CPU上運行,而計算任務繁重的部分則由GPU來加速)的MPI+OpenMP+CUDA的三級混合編程模型。本文基于中國科學院近代物理研究所超算中心的深騰 7000G 集群,進行GPU通用計算能力和并行編程模型的研究,采用MPI+CUDA多粒度混合編程模型,節點間使用MPI進行通信,實現粗粒度并行,節點內利用GPU強大的并行數據處理能力,使用CUDA架構實現細粒度的數據并行和線程并行。實驗結果表明,該方法能使并行效率顯著提高,同時證明MPI+CUDA混合編程模型能充分發揮集群節點間分布式存儲和節點內共享存儲的優勢,為CPU+GPU混合架構的集群系統提供了一種有效的并行策略。
高性能計算四個歷程
高性能計算機是信息產業的重要領域,是現代社會科學研究、社會服務、經濟活動中一種極為重要且不可或缺的戰略工具,世界上許多國家對計算能力的建設和計算科學的發展都給予了高度重視。自從1946年ENIAC(Electronic Numerical Integrator And Computer)在美國賓法利亞工程學院的摩爾電子工程學院誕生起,人類對高性能計算的追求就一直沒有停止過,高性能計算經歷了史前時代、向量機時代、大規模并行處理機時代、集群和超級計算機時代四個大的發展階段。二十世紀九十年代中期,隨著Linux操作系統的出現,微處理器和動態隨機存儲器速度的提升,PCI總線的研制成功以及局域網技術的發展,高性能計算的集群和超級計算機時代到來。現在,高性能計算機已經被廣泛地應用到了生命科學、物理、化學、材料等研究領域,還被應用于能源、氣候、環境、金融、游戲等產業與公共服務領域,高性能計算的普及在一定程度上改變了科學研究的方式,已成為繼理論科學和實驗科學之后科學研究的第三大支柱。

深騰7000G集群介紹
深騰7000G集群專為連接GPU 設計。節點機采用基于Intel 架構的商用服務器,節點間通過高速通信網絡實現互連,能夠很好地支持大規模科學工程計算,具有節點選擇豐富靈活、機群域網專業高效、基礎架構完備可靠等技術優點。
深騰7000G集群包含100個計算節點,每個計算節點均含有2個Xeon E5504CPU處理器和2個TeslaC1060GPU處理器, 2GB內存,500GB硬盤。深騰7000G集群安裝的操作系統為Red Hat Enterprise Linux Server release 5.6,采用了著名的開源作業處理系統Torque+Maui的資源管理組合,同時部署了ganglia監控系統,便于系統管理員和用戶實時了解集群的相關運行狀況,并提供了MPICH、Intel MPI等并行計算環境和CUDA-SDK、CUDAToolkit等相關GPU開發平臺,充分利用了集群提供的眾多GPU強大的計算能力。
MPI + CUDA 編程模型研究
MPI和CUDA介紹
MPI ( Message Passing Interfac)e 是一種消息傳遞機制,吸取了眾多消息傳遞系統的優點,是目前國際上最流行的并行編程環境之一,尤其是分布式存儲的可縮放并行計算機和工作站網絡以及集群的一種編程范例。MPI具有可移植性和易用性、完備的異部通信功能、正式和詳細的精確定義等優點,為并行軟件產業的增長提供了必要的條件,在基于MPI編程模型中,計算由一個或多個彼此通過調用庫函數進行消息收、發通信的進程組成。MPICH是MPI標準的一種最重要的實現,本文研究基于MPICH2版本。
CUDA ( Compute Unified Device Architecture )是nVIDIA公司推出的基于GPU的通用計算模型。在CUDA編程模型中,GPU作為一個協處理器能產生大量線程,這種優勢要得益于GPU的物理構造,GPU由許多晶體管組成,專為計算密集型、高度并行化的計算而設計,因而GPU的設計能使更多晶體管用于數據處理,而非數據緩存和流控制。GPU專用于解決可表示為數據并行計算的問題,具有極高的計算密度(數學運算與存儲器運算的比率),因此可通過計算隱藏存儲器訪問延遲,而不必使用較大的數據緩存。通過nVIDIA公司的CUDA技術,開發人員能夠利用GPU解決及其復雜的并行計算難題,開發出前所未有的高性能計算軟件。
MPI+CUDA編程模型
深騰7000G集群下,MPI+CUDA程序的聯合編譯運行環境用Makefile文件完成配置,主要配置文件如下:

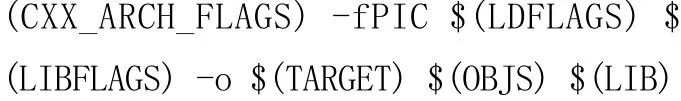
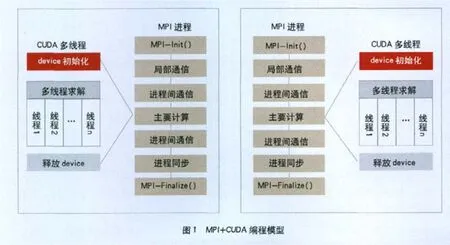
Makefile配置文件主要添加了程序的MPI部分simpleMPI.cpp的編譯和鏈接時用到的函數庫,其中程序的C U D A部分simpleMPI.cu用common.mk文件規則完成編譯和鏈接,最后生成一個可執行的simpleMPI文件。MPI+CUDA編程模型如圖1。
開發人員把問題分解成粗粒度(一個并行任務包含較長的程序段和較大的計算量)的問題,這些子問題可以獨立地并行解決,然后把這些子問題分為更小的細粒度(一個并行任務包含較短的程序段和較小的計算量)任務,然后在集群的不同層次實現并行粒度及優化。集群并行計算的方式,多為啟動多個進程,在各個節點上分別執行,節點間通過消息傳遞的方式通信,最后規約出計算結果。這種方法靈活,能夠適應任務并行、幾何分解、分治等大部分科學計算模式,但由于其通信成本較高,因此多用于任務劃分清晰、通信頻率較低的粗粒度并行。MPI是一種粗粒度并行編程模型。而GPU擁有強大的數據處理能力,可以同時開啟成百上千個線程,是典型的細粒度并行編程模型。對于含有支持CUDA架構的顯卡(GeForce、Quadro以及Tesla產品均采用nVIDIA CUDA并行計算架構,GeForce和Quadro分別是為消費級圖形處理和專業可視化而設計的,只有Tesla產品系列是完全針對并行計算而設計的,可提供廣泛的計算特性)的機群,可以綜合以上兩者的優點,通過消息傳遞機制,將任務分配到各個節點實現粗粒度并發性;在每個節點上,啟用多線程機制,利用共享內存實現快速高效的細粒度并行。這種混合粒度的并行程序的開發既可以發揮每個節點的巨大計算能力,又可以充分利用集群的可擴展性,為大型計算提供一個切實可行的方案。
(作者單位1為中國科學院近代物理研究所 ,2為蘭州大學)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
理科愛好者(教育教學版)(2022年2期)2022-05-05 00:24:02
快樂學習報·教育周刊(2022年13期)2022-04-13 21:33:18
甘肅教育(2021年10期)2021-11-02 06:14:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年18期)2020-10-28 09:07:06
數學物理學報(2020年2期)2020-06-02 11:29:24
甘肅教育(2020年21期)2020-04-13 08:08:42
數學大世界(2018年1期)2018-04-12 05:39:02
光學精密工程(2016年6期)2016-11-07 09:07:19
