DIF值和樣本量對SIBTEST檢測方法的影響研究
2012-11-08 08:05:42朱乙藝韋小滿
中國考試 2012年9期
朱乙藝 韋小滿
1 引言
近年來,項目功能差異(differential itemfunctioning,簡稱DIF)是心理與教育測量領域的一個研究熱點。到目前為止,有很多的方法可以用于檢測DIF,檢測DIF的方法包括MH方法、STND方法、LRDIF方法、基于IRT的方法、MIMIC方法和SIBTEST方法等。不同的DIF檢測方法的檢驗力(即正確識別率)是不盡相同的,即便對于特定的某種檢測方法而言,其檢驗力也不是固定不變的,有一系列因素影響著其檢驗力。影響DIF檢測方法檢驗力的因素包括樣本量、測驗長度、被試的能力分布、DIF項目的比例、DIF值的大小等。國外學者對這些檢測DIF的方法進行了很多比較研究,也做了很多探討這些檢測方法的影響因素的研究。通過這些研究,國外學者探討了各種DIF檢測方法的效率及優缺點,為實踐者選擇合適的DIF檢測方法提供了很好的依據。在國外學者的啟發下,我國學者利用現實存在的成就測驗數據進行了一些DIF檢測方法的比較研究,也對影響DIF檢測方法的因素進行了研究。董圣鴻等認為采用1000人左右的樣本進行DIF分析是完全可取的,如果要更為謹慎的話,那么選用2000人左右的樣本就可以了[1]。李付鵬以某年度6000名考生普通高考文科綜合選擇題的作答數據為樣本,探討了能力水平分組對MH方法檢驗敏感性的影響[2],研究結果表明:不同能力水平分組的檢驗結果均具有較好的一致性;檢驗結果對能力水平分組組數的敏感性較小,MH方法具有較好的穩定性。
應該說,國內對DIF檢測方法的研究有助于對國外的相關研究結論進行驗證,是對DIF檢測方法研究的有益補充。但是國內的研究基本上都是基于實測數據,這就決定了國內的研究和國外的模擬研究相比存在以下兩點不足:
第一,國內的研究由于基于實測數據,所以只能在實測數據的基礎上對變量進行一定程度的操縱。例如,從現有的樣本中隨機抽取一定比例的被試從而實現對樣本量的操縱,但是諸如被試的能力分布、測驗長度等變量則無法自由進行操縱。
第二,國內的研究由于是利用實測數據,因而無法事先知道哪些題目存在DIF,所以無法給出檢驗力和I型錯誤(即錯誤接受率)指標,只能進行相對的比較。在方法的比較研究中,國內的研究一般會觀察若干種檢測方法共同檢測出來的題目個數和每種方法各自檢測出來的題目個數,然后進行相對比較,顯而易見,這樣的相對比較是存在問題的,因為檢測出來的題目并不一定是事實上存在DIF的題目,有可能是錯誤標記為DIF的題目。在方法的影響因素研究中也存在類似的問題,由于事先不知道哪些題目存在DIF,所以無法分離正確識別的題目和錯誤接受的題目。
因此,為了能夠自由地操縱實驗變量并且給出令同行信服的檢驗力和I型錯誤指標,國內的學者有必要基于模擬數據進行DIF檢測方法的研究。本研究探討了DIF值和樣本量對SIBTEST檢測方法的影響效應,以期一方面探明DIF值和樣本量對SIBTEST檢測方法的檢驗力和I型錯誤之間的關系,另一方面為國內學者未來開展模擬研究時選取DIF值提供參考。
2 SIBTEST方法概述
SIBTEST方法(Simultaneous Item Bias Procedure)是由Shealy和Stout于1993年提出的一種DIF檢測方法。SIBTEST方法采用潛在能力作為匹配變量,用回歸校正方法來估計匹配分數(Bolt&Stout,1995)。SIBTEST方法的DIF指標為[3]:
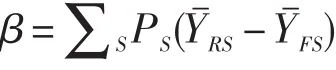
其中,PS為第S能力水平組中答對該項目的人數比率,、分別是第S能力水平組中參照組和目標組被試在該題上的平均得分。
SIBTEST還包括一個顯著性檢驗:Z=β/σ(β)來檢驗項目的功能差異量是否顯著:
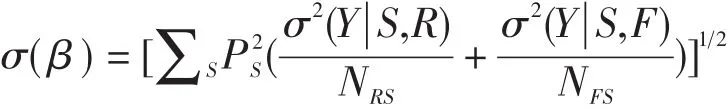
其中,σ2(Y|S,G)是匹配測驗分數為S的G組(G=R或F)被試在所研究的項目上得分的方差。Z近似于N(0,1)的正態分布(Hua-Hua Chang&Jhon Mazzeo,1996),如果Z大于1.96或小于-1.96時(α=0.05,雙側檢驗),則拒絕零假設,即認為該項目存在DIF。
SIBTEST設計了一個迭代程序,把被懷疑存在功能差異的項目排除在匹配標準之外。此外,SIBTEST不僅可以對單個項目進行項目功能差異檢驗,還可以對一批項目進行項目束功能差異檢測[4]。
3 研究方法
3.1 數據產生
題目的作答數據是利用三參數邏輯斯蒂克項目反應模型(3PLM)來產生的,在該模型中,單維能力為θ的被試正確作答題目i的概率為:
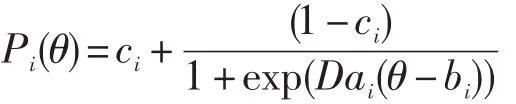
其中,ai為題目i的區分度參數,bi為題目i的難度參數,ci為題目i的偽猜測系數,D為量尺化系數(一般取D=1.7)。
難度參數b是從N(0,1)正態分布中隨機選取的,區分度參數a是從N(0.5,0.2)正態分布中隨機選取的,偽猜測系數c設定為0.2,具體的題目參數見表1。能力θ是從N(0,1)正態分布中隨機選取的。測驗的長度為40,即測驗包含40道題目。
兩級記分的題目作答數據是通過以下的過程得到的:首先通過上面的方程分別計算每個被試在每道題目上的正確作答概率,然后從U(0,1)一致性分布中隨機選取一個數字,如果該數字小于Pi(θ),則將該被試在題目i上的作答記為1,如果該數字大于Pi(θ),則將該被試在題目i上的作答記為0。
目標組和參照組的能力分布均為N(0,1)正態分布,即目標組和參照組的能力是一致的。選取第5題來產生DIF,第5題的難度為-0.208,為中等難度;區分度為0.808,為中等區分度。DIF的引入是通過改變目標組的題目難度參數來實現的,即有利于參照組的DIF項目是通過bF=bR+來產生的。
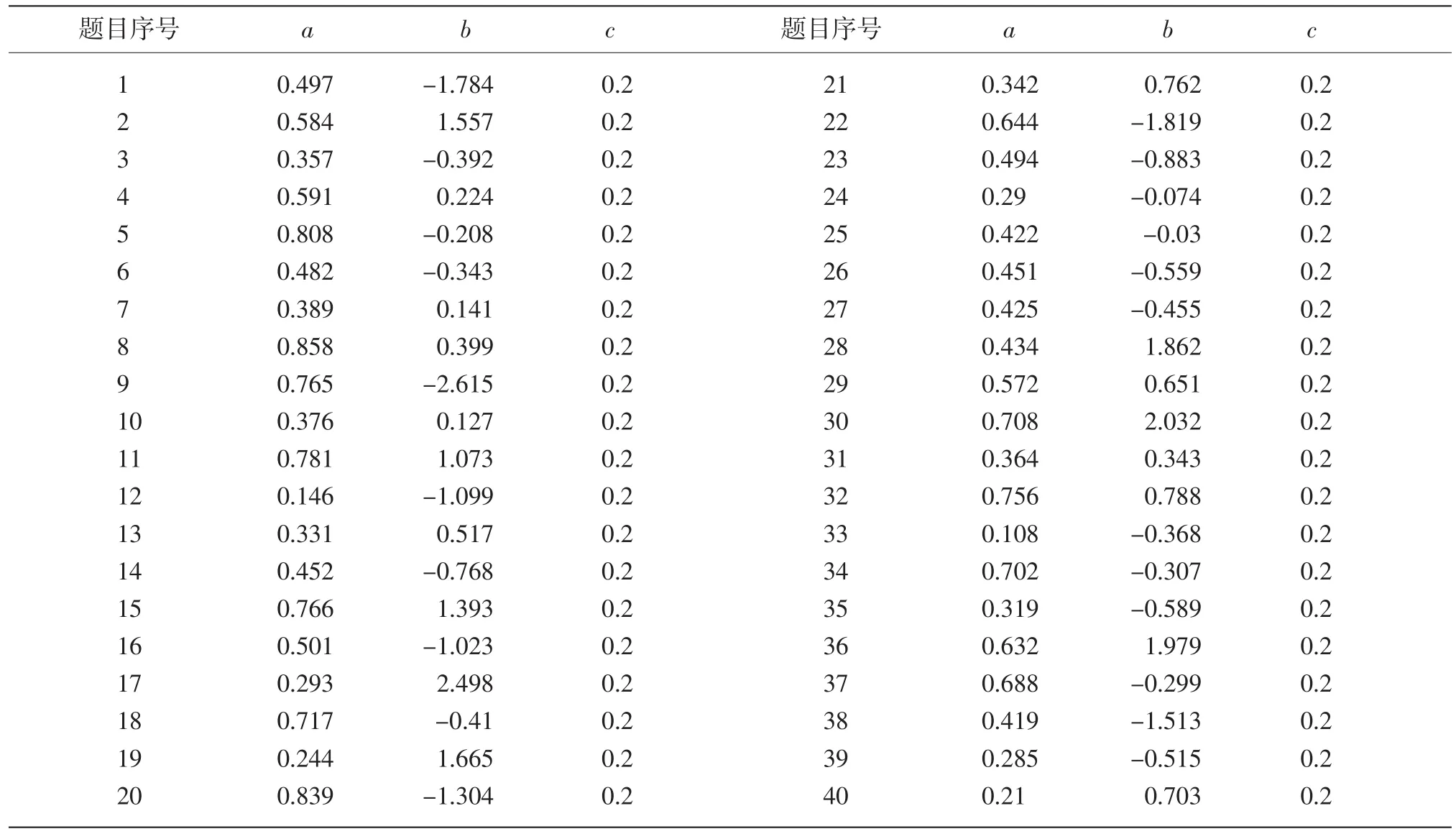
表1 用來產生題目作答數據的參照組的題目參數
3.2 研究設計
本研究操縱了兩個變量:DIF值和樣本量。DIF值指的是目標組和參照組的DIF項目的項目反應函數之間的面積,DIF值包含6個水平,分別是0.24、0.32、0.40、0.48、0.56和0.64,在產生DIF項目時對應的Δb分別是0.3、0.4、0.5、0.6、0.7和0.8。樣本量包含6個水平,分別是250、500、1000、2000、5000、7000。因此,總共有6×6=36種條件,每個條件產生100個復本。
3.3 分析過程
SIBTEST方法的DIF檢測是通過William Stout和Louis Roussos開發的SIBTEST軟件[5]來進行分析的,判定題目存在DIF的標準是p<0.05,分析過程中分別記錄每種條件下的檢驗力和I型錯誤。
4 研究結果
在本研究中,SIBTEST方法檢測結果的檢驗力的操作定義是在100個復本中第5題被標記為存在DIF的比例。Cohen(1988)提出在0.05顯著性水平上如果檢驗力>0.80則可以認為檢驗力是充分的[6]。
從表2中可以看出,當DIF值較小時(0.24和0.32),在樣本量小于2000時,SIBTEST方法的檢驗力隨樣本量的增大而增大,當樣本量大于等于2000時,檢驗力達到最大值,不再隨著樣本量的增大而增大;當DIF值為中等大小時(0.40、0.48、0.56),在樣本量小于1000時,SIBTEST方法的檢驗力隨樣本量的增大而增大,當樣本量大于等于1000時,檢驗力達到最大值,不再隨著樣本量的增大而增大;當DIF值很大時(0.64),當樣本量大于等于500時,檢驗力達到最大值,不再隨著樣本量的增大而增大,樣本量對SIBTEST方法的檢驗力的影響可以忽略不計。
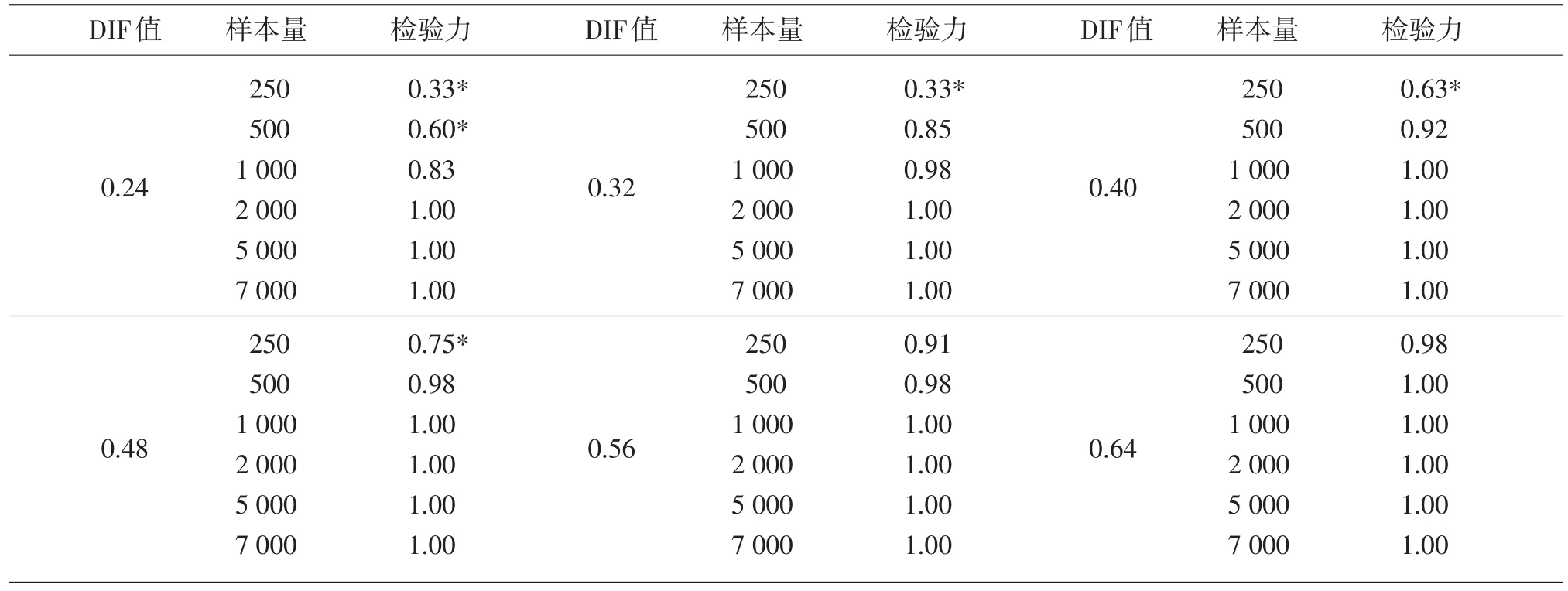
表2 不同DIF值和樣本量條件下SIBTEST方法的檢驗力
表2顯示,當樣本量小于等于500時,SIBTEST方法的檢驗力隨著DIF值的增大而增大;當樣本量為1000時,在DIF值較小時(0.24和0.32),SIBTEST方法的檢驗力隨著DIF值的增大而增大,當DIF值達到中等大小以后,SIBTEST方法的檢驗力達到最大值,不再隨著DIF值的增大而增大;當樣本量大于等于2000時,SIBTEST方法的檢驗力均為最大值。
在本研究中,SIBTEST方法檢測結果的I型錯誤的操作定義是不存在DIF的項目被錯誤地標記為存在DIF的比例,根據Bradley(1978)提出的嚴格、保守的檢測結果穩健標準,如果I型錯誤介于0.025到0.075之間,那么可以認為檢測結果是穩健的[7]。
從表3可以看出,在所有的DIF水平上,當樣本量大于等于2000時,SIBTEST方法的I型錯誤隨著樣本量的增大而增大,而樣本量小于2000時,SIBTEST方法的I型錯誤的變化與樣本量的變化沒有明顯的關系。
表3顯示,當樣本量小于等于1000時,SIBTEST方法檢測結果的I型錯誤的變化與DIF值的變化沒有明顯的關系;當樣本量大于等于2000時,I型錯誤大致隨著DIF值的增大而增大。
5 討論
5.1 DIF的產生方法
在以往的模擬研究中,基于研究者對DIF產生原因的理解差異,模擬研究中DIF的產生一般有兩種思路:第一種思路是基于單維的項目反應理論模型,通過改變目標組的題目參數來引進DIF;第二種思路是基于多維的項目反應理論模型,沒有DIF的題目只測量首要維度,存在DIF的題目除了測量首要維度外,還測量到了其他維度。現有的大多數DIF模擬研究是采用第一種思路來產生DIF的,研究者們傾向于采用第一種思路是因為目前單維的IRT理論較為穩健,前人用該思路來產生DIF積累了很多寶貴的經驗,用該思路來產生DIF操作較為簡單。另一些研究者傾向于采用第二種思路的原因是他們認為多維測驗更符合實際情況,并且認為通過引入新的維度來產生DIF是更為合理的。鑒于技術操作上的考慮,為了保證本研究的可行性,采用第一種思路來產生DIF。在第一種思路下,研究者一般根據其需要選取某種項目反應理論模型(Rasch模型、單參數邏輯斯蒂克模型、兩參數邏輯斯蒂克模型或三參數邏輯斯蒂克模型),然后通過改變目標組的難度參數或者同時改變目標組的難度參數和區分度參數來產生DIF。本研究采用三參數邏輯斯蒂克模型來產生作答數據。
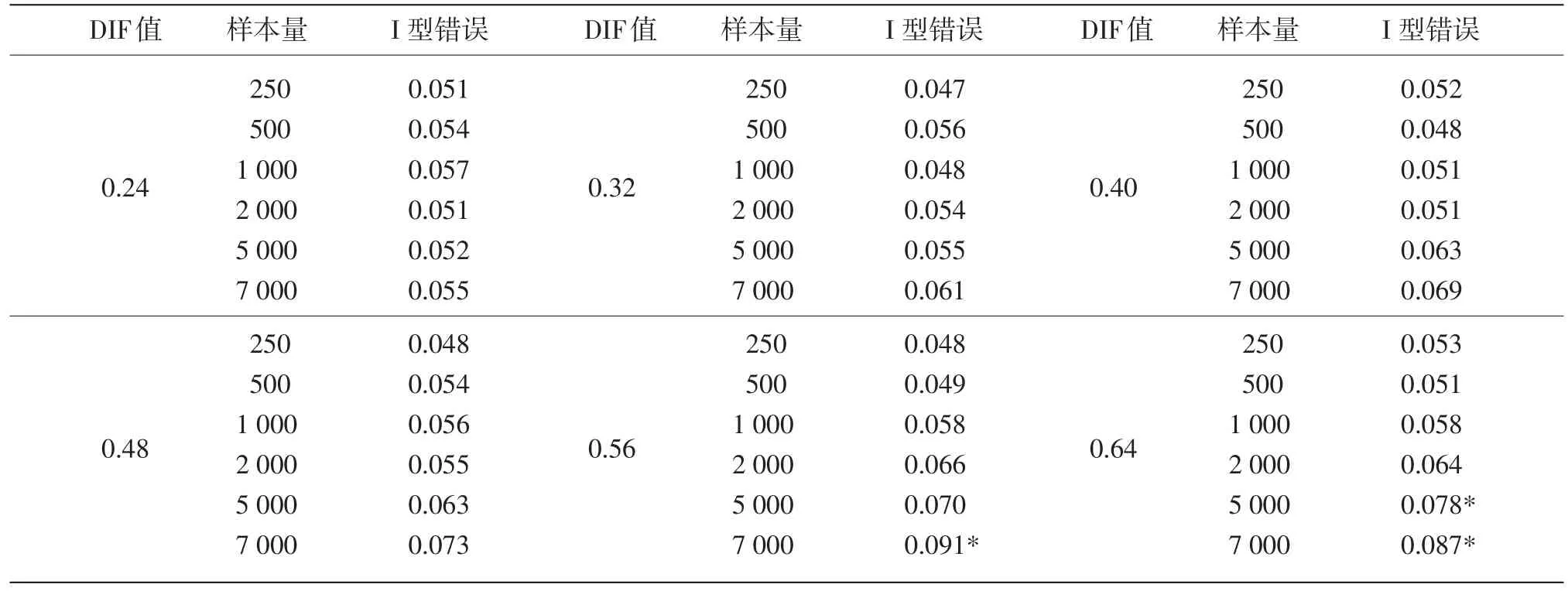
表3 不同DIF值和樣本量條件下SIBTEST方法的I型錯誤
5.2 樣本量和DIF值對SIBTEST方法的影響
樣本量是DIF檢測效果的重要影響因素之一,通過設置不同樣本量的實驗條件來探討樣本量對SIBTEST檢測方法的影響具有重要的理論意義和實踐意義。基于第一種思路來產生DIF時,采用多大的DIF值是一個值得認真考慮的問題。當用某種DIF檢測方法對模擬的數據進行檢測時,DIF值設置得過小或者過大,都可能對DIF檢測的效果造成不良影響。因此本研究的DIF值的變化范圍設置為0.24~0.64。從研究結果來看,樣本量和DIF值確實影響SIBTEST方法的檢測效果,并且樣本量和DIF值對SIBTEST方法的檢測效果的影響存在交互作用。由于本研究所選用的SIBTEST檢測軟件本身的限制,該軟件能檢測的最大樣本量是7000,如果想要檢測更大樣本量的數據,則需要對SIBTEST軟件進行拓展。從本研究的研究結果來看,當樣本量達到5000~7000時,DIF值為中等偏大時SIBTEST方法的檢測效果就不太穩健了。可以想象,如果樣本量增大到2萬或者更大,那么可能DIF值為中等大小時SIBTEST方法的I型錯誤就不再滿足穩健的標準。當樣本量很大的時候,在用SIBTEST方法來檢測DIF前就很有必要采取一些必要的措施,例如對樣本進行隨機抽樣達到降低樣本量的目的,或者在檢測時采用效應值來對抗虛假的統計顯著性。
6 研究結論
(1)在一定的DIF值和樣本量條件下,SIBTEST方法的檢驗力和I型錯誤隨著樣本量和DIF值的增大而增大。樣本量和DIF值太小,會導致SIBTEST方法的檢驗力不充分。樣本量和DIF值過大,不僅對檢驗力的提高沒有幫助,反而會使I型錯誤急劇增大。
(2)當用SIBTEST方法對實測數據進行DIF檢測時,1000~2000的樣本量是比較合適的。
(3)當用模擬數據進行SIBTEST方法的模擬研究時,如果選用的DIF值較小時(0.24~0.32),那么樣本量不能少于2000;如果選用的DIF值為中等大小時(0.40~0.56),那么樣本量不能少于1000;如果選用的DIF值為較大時(0.64),那么樣本量不能少于500。
[1]董圣鴻,馬世曄.三種常用DIF檢測方法的比較研究[J].心理學探新,2001(1).
[2]李付鵬.能力水平分組對Mantel-Haenszel方法檢驗DIF效應的影響分析[J].中國考試,2011(9).影響分析[J].中國考試,2011(9).
[3]Shealy,R.,Stout,W.A model-based standardization approach that separates true bias/DIF from group ability differences and detects test bias/DIF as well as item bias/DIF.Psychometrika,1993,58:159-194.
[4]Clauser,B.E.,&Mazor,K.M.Using statistical procedures to identify differential item functioning test items.Educational Measurement:Issuesand Practice,1998,17:31-44.
[5]William Stout,Louis Roussos.SIBTESTManual,1996.
[6]Cohen,J.Statistical power analysis for the behavioral sciences.Hillsdale,NJ:Erlbaum.1988,2nd ed.
[7]Bradley,J.V.Robustness?The British Journal of Mathematical&Statistical Psychology,1978,31:144-152.
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
意林原創版(2016年10期)2016-11-25 10:28:30
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
