PCA算法在P2P加密流量識別中的研究與應用
2012-06-25 03:31:14羅丞,葉猛
電視技術 2012年3期
關鍵詞:特征
羅 丞,葉 猛
(武漢郵電科學研究院電信系,湖北 武漢 430074)
隨著寬帶互聯網時代的到來,用戶對信息實時性的需求越來越高,隨之出現了基于P2P技術的寬帶共享工具。這類工具給用戶帶來了高實時性的體驗,但同時也給寬帶運營商帶來了監(jiān)管困難的窘境,識別這些應用產生的流量是目前運營商關注的重點。因此,針對P2P應用流量的識別技術應運而生。
目前主流的應用層協(xié)議識別技術主要分為以下3類[1]:基于應用協(xié)議固有特征的識別技術,應用層網關識別技術和行為模式識別技術。
基于P2P技術的軟件將網絡上原本孤立的服務器資源及P2P資源整合在一起,這使得其信令交互部分特征較為明顯,而數據下載部分由于加密導致特征模糊。傳統(tǒng)的指紋匹配技術致力于從算法優(yōu)化角度改進匹配速度,但是在面對特征更加模糊的加密流量時,必須綜合多種特征從多維度來識別,多維度帶來的直接問題就是算法的復雜度呈指數級上升,太多特征導致系統(tǒng)處理過慢,用戶響應時間過長,嚴重影響系統(tǒng)使用,而如果能夠以較少量的特征來識別流量就可以加快識別過程,提升用戶使用感受。當所要分析的對象特征太多、維度太高時,可以嘗試通過某些有損的降低維度算法來降低冗余維度,保留主要維度,使得所分析對象特征更顯清晰[2]。
盡管P2P加密流量的特征有很多,但可以通過降維來獲取有用的少量特征。在本文中,采用主成分分析(Principal Component Analysis,PCA)[3]來使得 P2P 加密流量的復雜特征降維,以降低多維匹配帶來的復雜性。
1 PCA算法
1.1 PCA 算法原理
已知有n個d維數據樣本x1,x2,x3,…,xn,指定其中一點Q(q1,q2,q3,…,qd),求在總的樣本中與之距離最近的k個點。
計算步驟如下:
1)首先求散布矩陣(離散度矩陣)
先對n個樣本的每一維數據進行處理,求出n個樣本每一維對應的均值,即得d個均值m1,m2,m3,…,md。然后用每個樣本點的每一維數據與相應維的均值作差,對于每一個樣本點即得 xi1-m1,xi2-m2,xi3-m3,…,xid-md這d個數據(其中xi表示n個數據中下標為i對應的數據類),然后以這d個數據構造一個d行1列的矩陣,接著求其轉置矩陣,原矩陣與轉置矩陣相乘即得到一個d行d列的對稱矩陣。最后將這n個對稱矩陣進行矩陣加法運算即得到離散度矩陣。
2)得到離散度矩陣后,求出該矩陣的d個特征值及相應的特征向量,在求解特征值與特征向量時,由于由第一步知道,所求的離散度矩陣是對稱矩陣,故可采用雅可比法求矩陣的特征值與特征向量,然后將其特征值按大小遞減順序進行排序。
3)取第一個,也就是最大特征值對應的特征向量e,作為后面投影操作參照向量。
4)將樣本中的所有數據類,投影到特征向量e上,投影操作方法就是由數據類的d個數據構成的一個行向量與列特征向量e作矩陣乘法運算,故由此得到n個點的投影坐標t1,t2,t3,…,tn,將這n個投影坐標進行排序,然后求出所求點對應的投影坐標值。找到該坐標值后,以該點為中心,向兩邊展開搜索,直到找到k個臨近數據類滿足要求。
5)由于兩個數據類之間的真實距離大于或等于投影距離,即d(x,Q)≥d(tx,tq),由于已經將所有點的投影點進行了排序操作,故以所求點Q對應的投影點tq為起始點向兩端逐個搜索,找到k個數據類,然后將這些數據類與所求點之間的距離計算出來,對其進行排序操作(如按大小遞減排序),則第一個為dmax,以后向兩端每搜索一個點,就先計算數據類與所求點之間的投影距離,如果該距離小于dmax,則該數據類可能是要求的k臨近點中的一個,之后需要計算它與所求點之間的真實距離,再與已經存放的k個數據類對應的距離進行比較,選擇是插入還是舍棄。如果搜索到數據類的投影值與所求點對應的投影值之間距離大于dmax時,則搜索停止進行。
1.2 加密數據處理
上述算法過程結合到具體的數據包特征識別上,就是每個樣本都是一個獨立的以太網數據包,這些樣本的維度就是數據包的相應特征,這些特征應該由包長度、端口號、上層協(xié)議類型、某些位置的字節(jié)值(變長,由于不同的P2P應用具有不同的通信結構,具體的字節(jié)特征應該根據不同的應用來確定,高維特性也就表現在這里)等構成。根據上述算法得到離散度矩陣C=A AT,A的每一行是一種特征差,A的列數就是數據包的個數。算法就是求矩陣C的特征向量。為了簡單,只取其中部分的特征向量,這些特征向量對應于某些特征值,通常是前M個大的特征值。這樣便得到了M個特征向量。接下來就是將每個包在這M個特征向量上作投影,得到一個M維的權重向量w=(w1,w2,…,wm),一個P2P流有多個包,于是將對應于這個P2P流的權重向量求平均作為這個流的權重向量。對于每個新來的包,先求得一個權重向量,與流庫中每個流的權重向量作比較,如果小于某個閾值,則認為其屬于已知P2P流,否則丟棄。
2 P2P加密流量識別方案
針對PCA對于高維數據的優(yōu)勢,在識別具體業(yè)務流量之前首先分析該業(yè)務的軟件行為,通過抓包摸清楚該業(yè)務的更多詳細特征,特征越多,識別精度越高。在此基礎上應用PCA算法降維度,保留有用特征,提高系統(tǒng)識別實時性,從而達到兼顧實時性與識別率的較好狀態(tài)。
2.1 軟件行為分析
通過對P2P工作原理的研究,可以將P2P的通信數據按照其行為模式分為以下3類[4]:
第一類是初始化通信過程,該過程主要完成P2P用戶入網注冊、廣告接收、信息同步等功能,其特點是服務端端口固定,載荷區(qū)特征明顯。對于這部分數據采用“端口+流+特征”模式來識別,記為A模式。
第二類是P2S通信過程,該過程主要完成同種資源搜索、多點資源下載、本地資源上傳等功能,其特點是服務端端口較為固定,載荷區(qū)數據加密但特征固定,請求包長度較固定。對于這部分數據采用“端口+流+特征+包長度”模式來識別,記為B模式。
第三類是P2P通信過程,該過程主要完成對點資源下載、本地資源上傳等功能,其特點是服務端端口動態(tài)變化,載荷區(qū)數據加密但比特序列有規(guī)律。對于這部分數據采用“流+字節(jié)特征”模式來識別,記為C模式。
有了分類的數據,再有針對性地對不同的類別進行不同模式的抓包識別。為了對P2P流量進行有效的分析,定義以下術語:
1)流:用五元組來標識一個連接,即源IP、源port、目標IP、目標port、傳輸層協(xié)議[5]。一個數據包到來后先識別它是否屬于已知流,如果屬于即直接返回,這樣可以節(jié)省大量的CPU資源。
2)字節(jié)特征:數據包載荷區(qū)字節(jié)的綜合規(guī)律。這些規(guī)律需要人為的挖掘,通過對數據包的反復閱讀和猜測來確定某種字節(jié)序列[6]。例如迅雷的P2P加密流量,其中有很大一部分數據包載荷區(qū)的前4 byte符合“0x**000000”的特征,“**”為非零值。
3)識別優(yōu)先級:把識別規(guī)則按照一定順序分配不同優(yōu)先級,優(yōu)先級高的先識別。這里把“流”列為最高優(yōu)先級,其次是“端口”、“特征串”、“字節(jié)特征”、“包長度”。
2.2 代碼實現
結合上述思想可以將程序分為4個模塊[7]:
1)程序初始化模塊
該模塊主要實現讀取配置文件(流庫的權重參數)、啟動其他模塊線程的功能。
2)數據包采集模塊
Libpcap是Unix下非常方便的數據包截獲API,利用Libpcap函數庫可以編寫抓包模塊,實現從服務器的指定網卡抓包[8]。首先定義網卡描述符,再通過pcap_open_live函數打開指定網卡并循環(huán)抓取線上的數據包。
3)數據包處理模塊
抓取的數據包經過該模塊的處理應該可以順利地標示出屬于P2P的流量。首先定義一系列表示TCP/IP協(xié)議棧各層包頭的結構體,定義五元組結構體(即“流”結構體,再包含一些標識位),并聲明一個“流”指針的容器,利用pcap_loop函數對每一個抓取到的數據包進行回調函數的處理,這里的回調函數可以定義并實現操作數據包的方法,根據識別優(yōu)先級來對數據包進行層層過濾和分配。首先提取數據包的五元組信息,根據這些五元組找出其所屬的流,查看此流是否已經存在,用一個泛型指針遍歷“流”容器,如果此流已經存在并且已經進行了標識,則直接返回。否則,新建一個流,并且提取該包相關特征,依據PCA算法得到經過處理后的特征權重、再將該權重與已知流的權重作比較,以此來判斷該包是否屬于P2P通信。
4)統(tǒng)計輸出模塊
該模塊每隔一段時間打印一次數據包處理結果,其中包括總抓包數目、已識別的包數目、識別率等信息。
3 實驗步驟及結果分析
P2P應用包含范圍很廣,從下載到共享無所不包,鑒于文章篇幅有限不能完全包括,本次實驗就P2P下載應用中具有代表性的迅雷工具作為實驗對象,采集的樣本數據為預先在真實環(huán)境下抓取的完整的迅雷下載包,所提取的多維特征為迅雷在未下載、BT下載、電驢下載這3種情況下的流特征(迅雷在未下載時為A模式,BT及電驢下載時為B+C混合模式),流庫中保存的權重參數由上述3種情況下分別經過計算得出,例如迅雷在C模式下的某一種流,其前幾個包的長度大概在40 byte左右,采用UDP(用17表示)傳輸,載荷區(qū)特征為0x32000000**(**為可變非零字段,經過計算的平均值為0x06,計算時轉換為十進制),這些特征便可以標識為{40,11,50,0,0,0,6}的均值,再將幾個樣本對上述均值分別求差,并按照算法步驟逐步求解(注意求差過程中僅計算包長度等變量即可),最終可得到該種類型的P2P流的權重,將權重值記錄在流庫的配置文件中,這樣便可以模擬真實環(huán)境下迅雷流量的識別,并且可以保證沒有雜包。
實驗服務器配置為CPU:Intel Xeon E55042 .0GHz×8(8核心),內存為16 Gbyte。
實驗步驟如下:
1)在配置文件中配置網絡信息,如抓包口配置為eth0;
2)打開編譯好的程序文件,等待其初始化完畢;
3)利用服務器的發(fā)包軟件對eth0口進行發(fā)包;
4)觀察程序打印結果,生成數據文件并使用gnuplot繪圖,分析實驗數據。
圖1所示為HTTP情況下的P2P加密流量權重圖,圖中每個點都代表一個流的權重,其中左起第一個點為配置的閾值權重,其他低于該點的代表能夠識別出的流,高于該點的則為未識別的流。由圖1可知HTTP方式下流量分布較為均勻。
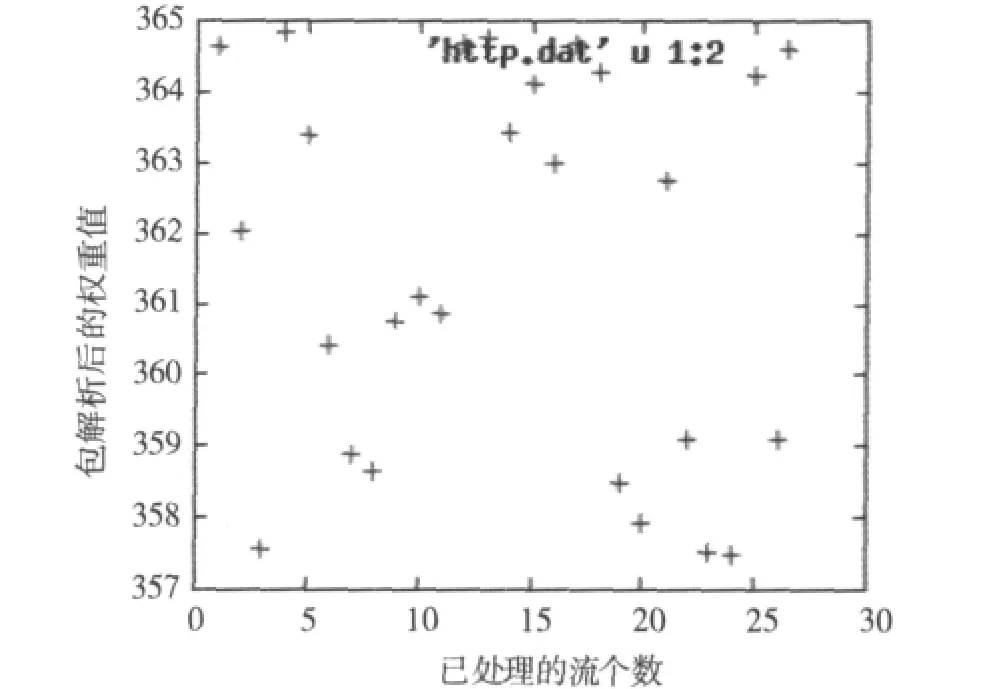
圖1 HTTP方式下權重比較
圖2所示為BT情況下的P2P加密流量權重圖,解圖方式同圖1。圖2中的數據顯示出BT方式下權重的分布情況,可以看出流量分布比較密集,大都分布在閾值權重附近。
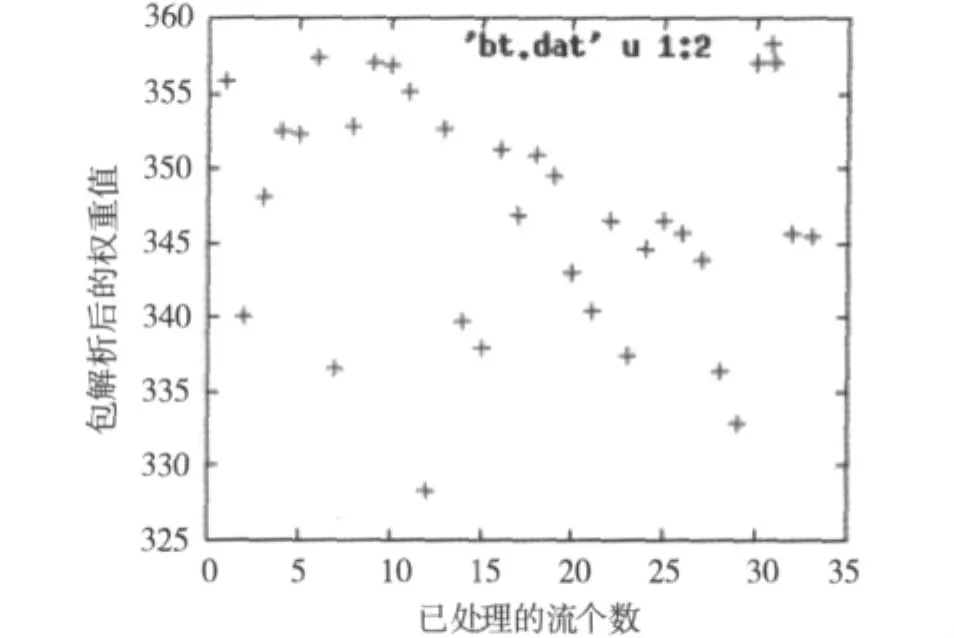
圖2 BT方式下權重比較
如圖3所示為EMLUE情況下的P2P加密流量權重圖,解圖方式同圖1。由圖3可以看出EMLUE情況下的流量分布也比較密集,這從側面說明同種P2P類型的下載流量之間特征相似度較高。
上述實驗中所發(fā)的包分別對應著迅雷在HTTP下載、BT下載、電驢下載的包,為了保證測試結果的普適性,上述3種模式的迅雷包分別在不同的計算機上抓取。表1所示為實驗所得的具體識別率。
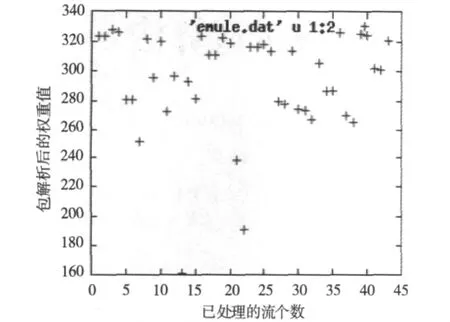
圖3 Emule方式下權重比較

表1 3組不同模式的迅雷流量識別率對比
表中的數據顯示迅雷流量在HTTP方式下識別率最高,其次是BT和電驢,未識別的流量中包含了少量的無規(guī)律加密數據以及無實際數據的雜包,這部分流量可以在后續(xù)工作中再作識別或剔除處理。綜上所述,將PCA方法引入P2P流量識別的策略是可行的,并且是有效的。
為了與其他協(xié)議識別方法作出比較,如表2所示為從實時性、準確性、對加密流量的識別率這3個方面來考察特征串識別、PCA識別以及流行為特征識別3種方法的優(yōu)劣。
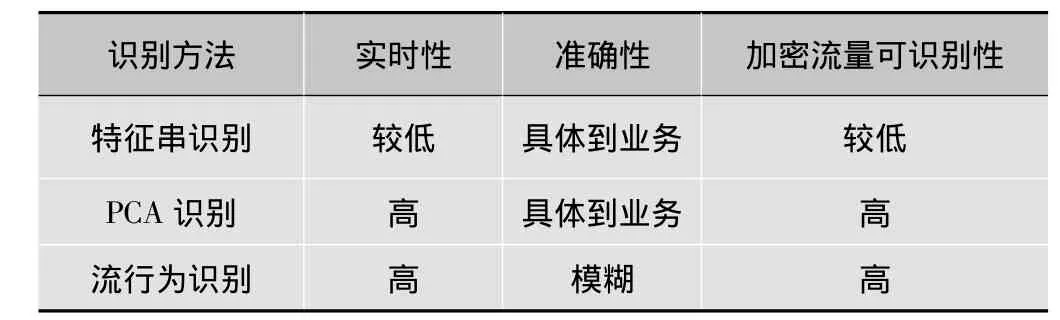
表2 3組不同識別方法的優(yōu)劣對比
相對于傳統(tǒng)特征串識別來說,PCA算法可以適應更大規(guī)模特征而不損失效率,實時性很高;相對于不檢測載荷的流量行為特征模型來說,PCA算法可以更加精確到識別定位哪一種業(yè)務在吞噬網絡帶寬,更有效地為運營商提供判斷依據;而在加密流量識別上,PCA具備多特征識別的天然優(yōu)勢,更多的特征并不會對PCA產生很大影響。
4 小結
P2P流量的識別已經成為網絡管理中的重要部分,本文利用Wireshark軟件,采用逆向工程的方法,分析和研究了P2P的工作原理和通信過程,提取其通信過程中的流特征,但是P2P應用由于其流量加密的復雜性導致特征呈現高維型,而一般的特征串匹配算法都是從改進算法的角度來加快識別速度,本文嘗試引入PCA算法,希望在不損失識別率的情況下對P2P流特征進行降維處理,減少需要處理的特征數,從而加快對P2P流量的識別。由于PCA一般在人臉識別和神經網絡等領域應用較成熟[9],在網絡流量識別方面尚沒有成熟的使用模型,因此這一方法雖然可行,但還有很多工作有待進一步深入研究。
P2P共享技術發(fā)展的過程是一個不斷規(guī)避檢測的過程,這就給識別技術不斷帶來新的挑戰(zhàn),應用協(xié)議也在不斷改進,其特征也在不斷變化,因此流量識別方法也需要隨之進行不斷嘗試和調整。
[1]王鋒.IP業(yè)務識別與控制系統(tǒng)(DPI)的發(fā)展現狀與思考[EB/OL].[2008-11-13].http://www.lmtw.com/tech/Using/200811/47956.html.
[2]王敏,李純喜,陳常嘉.淺談基于PCA的網絡流量分析[J].微計算機信息,2006,22(6):94-95.
[3]張媛,張燕平.一種 PCA算法及其應用[J].微機發(fā)展,2005,15(2):67-68.
[4]蔣海明,張劍英,趙二濤,等.PPLive網絡電視通信機制研究[J].電視技術,2009,33(12):61-63.
[5]陳亮,龔儉,徐選.基于特征串的應用層協(xié)議識別[J].計算機工程與應用,2006,24(4):16-19.
[6]殷曉麗,田端財.P2P流量識別技術分析[J].科技資訊,2009(8):16-17.
[7]胡文靜,李明,劉錦高.基于LIBPCAP的網絡流量實時采集與信息萃取[J].計算機應用研究,2006,1(6):236-238.
[8]MOORE A W,PAPAGIANNAKI K.Toward the accurate identification of network application[C]//Proc.PAM2005.Boston:MA,2005:41-54.
[9]淺談 PCA 人臉識別[EB/OL].[2011-05-01].http://leen2010.blogbus.com/logs/124631640.html.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
