基于Web數據挖掘的科研協同服務模式探索
2012-04-29 00:44:03王彩虹
現代情報
2012年5期
王彩虹
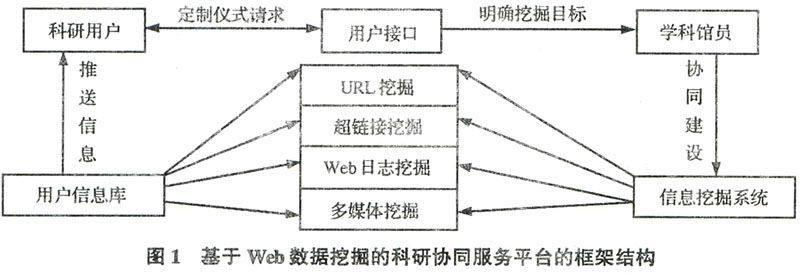
[摘要]Web數據挖掘技術是實現個性化科研協同服務的關鍵技術。本文以學科館員協同高校科研教師完成重大科研項目為目標,以Web數據挖掘技術為基礎,綜述了Web數據挖掘的概念、研究方法、國內外研究現狀以及學科化科研協同服務的內涵。設計了科研協同服務平臺及其運行機制,力求為學科館員融入高校科研一線提供新的思路和決策。
[關鍵詞]Web數據挖掘;學科館員;科研協同服務
DOI:10.3969/J.issn.1008—0821.2012.05.013
[中圖分類號]G250.7
[文獻標識碼]A
[文章編號]1008—0821(2012)05—0051—04
隨著我國科技水平的不斷發展,高等學校生源和就業問題的加劇,高校生存和發展的競爭變得日益激烈。在全方位的競爭當中,教師的科研實力是衡量學校辦學水平的最重要砝碼,已經成為高校爭取排名的堅強武器。教師科研項目或課題的申報越來越需要強有力的論據材料和論證方法來支撐,其項目研究也不斷尖端化細致化。一些骨干教師在繁忙的教學工作中,擔負著國家級自然科學基金或社會科學基金等重大項目的研究任務。在其項目申報、項目研究、項目結題發布過程中,迫切希望高校圖書館的學科館員能為其項目研究提供合理的信息導航和信息過濾等服務工作。因此,研究如何在網絡環境下,以“用戶為中心”,采用恰當的Web數據挖掘技術,挖掘出科研教師用戶急需的信息資源,協助其解決科研過程中遇到的實際問題,是學科服務深層次化、個性化的一個新領域,具有獨特的研究優勢。
1 Web數據挖掘鮮活科研協同服務
登錄APP查看全文
