基于JDBC的通用數據庫訪問和星表錄入工具*
2012-01-25 01:26:36袁海龍鄧小超張昊彤
天文研究與技術 2012年1期
關鍵詞:數據庫
袁海龍,董 建,鄧小超,張昊彤,李 鋒,王 堅,金 革
(1中國科學技術大學近代物理系,安徽 合肥 230026;2中國科學院國家天文臺,北京 100012)
大面積天區多目標光纖光譜天文望遠鏡(LAMOST[1])是目前多目標光纖光譜觀測中最先進的望遠鏡,具備優越的巡天能力,能同時觀測4000個目標,每個觀測夜能觀測上萬顆星,預計年觀測量能上百萬。LAMOST巡天的主要科學目標有星系紅移巡天、類星體巡天、恒星與銀河系觀測計劃和多波段巡天的光學證認[2],進行巡天的星表由天文研究人員根據研究的需要進行篩選。巡天戰略系統(SSS[3])的主要任務是根據天文學家的觀測需求和觀測約束條件,管理觀測星表,制定觀測計劃,部署望遠鏡的巡天過程,以盡可能高的效率完成巡天。
在巡天觀測系統的體系架構中,星表數據庫處于中心位置。星表數據記錄了每個觀測目標的坐標、自行、星等、觀測要求等重要信息。星表數據來源于世界各地天文臺的“成像巡天”,天文研究人員根據研究的需要選擇觀測對象,并匯總到觀測星表數據庫統一規劃。然而,數據來源往往分散存儲在各個不同類型的數據庫系統,并且經常有各自不同的數據格式,傳統的執行方案是針對各個數據庫安裝不同的數據訪問終端、篩選觀測目標、導出數據、使用輔助工具轉換格式、使用SSS數據庫的終端導入星表,這是一個費時費力的過程。因此,提供一個方便簡潔的星表選擇和錄入環境是有必要和有意義的。
為了建立友好的數據訪問和星表錄入支持環境,本文以JDBC(Java Database Connectivity,Java數據庫連接)技術為基礎,首先分析了用戶層的具體功能,然后對用戶層的具體功能建立模塊進行設計,接著對底層的核心問題逐個解決,最終組合完成整個系統的功能。在具體實現中應用了面向對象的編程原則和模塊化的編程思想,保證了系統的健壯性和擴展性。
1 功能分析
望遠鏡巡天觀測是一個多方合作、業務分工的運行過程,參與的角色主要有:天文研究人員、天文研究人員數據處理助手、巡天觀測管理人員、巡天觀測軟件助手以及望遠鏡觀測操作人員。天文研究人員根據具體的科研課題,在天文研究人員數據處理助手的協助下,選擇一批觀測目標,并向巡天觀測管理人員提交;巡天觀測管理人員為每一批觀測目標劃分觀測時間和制定優先策略,然后由巡天觀測軟件助手入庫;巡天觀測軟件助手根據觀測約束條件制定觀測計劃,然后遞交給觀測操作人員;觀測操作人員根據觀測計劃進行觀測并獲得觀測數據。針對這樣一個運行環境,對系統的功能進行了規劃:
(1)具備多種數據庫類型驅動支持,以及對新類型的擴展性
(2)有效管理多個數據庫星表服務,實現數據服務器的地址簿
(3)協作用戶建立數據庫連接,提供數據庫服務的基本信息一覽
(4)搭建SQL語句編輯的友好環境
(5)數據查詢結果顯示平臺
(6)輸出星表選擇結果到數據文件
(7)建立數據源到本地星表數據庫的數據映射關系
(8)輸出星表選擇結果到本地數據庫
用戶層模塊之間既相互獨立又存在一定的依賴性。每一個模塊有自己的核心功能,對外提供開放的接口,同時隱藏具體實現;為了實現某些高級功能,部分模塊需要引用其他模塊的功能,同時確保自身不失去獨立性,保證了模塊的內聚性。
將用戶功能進行劃分,最終還要進行組合。用戶層框架負責將各個具體的功能模塊組合起來,在需要的情況下調整業務邏輯關系。用戶層框架可以是圖形界面形式,也可以是文本會話形式。前者直觀形象,后者流暢便捷。
2 具體設計
本系統的具體設計分兩個層次、兩條線路進行。一個層次是用戶層,設計的線路為分析羅列具體功能、設計和實現子功能模塊、組合功能模塊成為整體;另一層次是關鍵問題解決,線路是發現問題、解決問題、發現問題、解決問題的這樣一個循環交替的持續過程。在前面的具體功能模塊已經討論了第一個層次的設計,接下來將逐步對一些具體的問題進行分析和解決。
系統的設計采用Java語言,一切面向對象,在實現系統功能的同時,保證了可維護性和復用性。在一個軟件項目的開發周期中,項目的維護比項目的開發可能要花費更多時間和費用,因此從一開始就提高可維護性和復用性是必要的。為了保證系統的可維護性和復用性,設計過程堅持接口隔離原則和迪米特法則。接口隔離原則,也稱為角色劃分原則。它表示在一個系統中,一個接口代表一個角色。每個角色有自己的接口,避免重疊。迪米特法則(Law of Demeter,LoD),即最少知識原則(Least Knowledge Principal,LKP),表示一個對象對其他對象盡可能了解的少。模塊之間聯系越多,開發和維護的費用就越多。
2.1 JDBC 訪問技術
JDBC是Java語言訪問數據庫的標準,目前已經發展成熟并得到了各數據庫廠商的驅動支持,例如:Oracle、MySQL、SQL Server、DB2、Sybase和informix等等。JDBC采用分層設計,上層是JDBC API,這是標準的訪問接口,下層是JDBC驅動程序API,這是由具體的數據庫生產廠商按照一定的標準提供的。同時,JDBC也可以通過JDBC/ODBC橋連接,訪問ODBC驅動程序,繼而訪問數據庫。基本的JDBC數據庫訪問步驟為:
(a)獲取數據庫訪問信息:ip、端口、SID、用戶和密碼
(b)獲得連接對象Connection
(c)創建會話Statement
(d)執行SQL語句得到結果集ResultSet
(e)處理結果集
(f)回收內存資源 (包括ResultSet、Statement、Connection)
JDBC的設計貫徹了面向接口編程的思想,這是用一個程式訪問各個類型數據庫的基礎。對于應用程序,JDBC都采用標準的上層API,這些都是標準的接口,而具體的設計由每個數據庫相關的驅動程序實現,因此對于應用程序而言,底層實現的差異幾乎是不受影響的。應用程序可以采用一致的運行方式對不同類型的數據庫進行訪問。
2.2 多數據庫類型管理
基于面向對象的編程思想,從數據庫訪問領域提取出數據類型這個通用語言,并構建類,命名為DBType。它包含描述一個基于JDBC的數據庫類型的所有必要信息,包括驅動類完整類名、數據庫訪問URL、簡要描述信息。類對象分為實體類和值對象,這里為DBType增加一個標識符字段,作為實體類設計。在這個基礎上實現資源庫,應用了工廠模式中的多例模式,這個類命名為DBTypeData。DBTypeData的業務功能包括工廠構造方法、資源庫的管理方法、數據持久性業務方法。數據庫類型具有持久保存的價值,需要持久性業務。按照MVC構件規則,將數據模型與視圖控制分開設計,使得業務邏輯條理清晰。相關類圖見圖1。
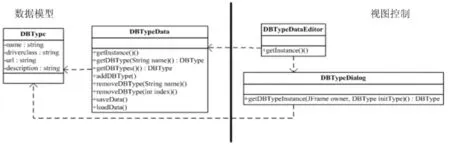
圖1 數據庫類型DBType相關類類圖Fig.1 Class diagram of related classes of the DBType
由于有JDBC的良好支持,訪問不同數據庫的差異體現在代碼參數上,不需要代碼結構的變動。JDBC的數據庫訪問需要給出兩個主要參數:數據庫驅動類路徑和數據庫訪問URL。同時根據需要給出用戶名和密碼。程序自動判斷在給出的URL參數中是否具有用戶和密碼內容。如果有,則在運行時用實際內容替換;否則,使用獨立的語句說明用戶與密碼。
擴展系統對一個新類型的數據庫的訪問變得非常容易。首先,獲取數據庫廠商針對這個數據庫的驅動程序;然后,根據驅動程序的說明文檔獲得驅動類路徑、訪問URL結構等信息;將驅動程序庫文件添加到軟件程序的類路徑中;調用數據庫類型管理模塊的DBTypeDataEditor組件,添加新的數據庫類型,配置這個類型的標識名、驅動類及訪問URL,然后保存。這樣系統就能識別新的數據庫類型,并采用相應的訪問手段進行連接。圖2是數據庫支持類型管理器界面。
2.3 多數據庫服務管理
為了訪問具體的數據庫,在數據庫類型類之上,建立一個數據庫服務類,命名為DBServic,用于描述一個具體數據服務的所有連接信息。以此為出發點,進一步實現數據庫服務的增加、刪除、查詢以及持久性業務。相關類的關系圖見圖3。
這樣的構造方式實際上為系統建立一個數據庫服務的地址簿,方便重復使用。數據庫服務類DBService為實體對象,具有一個標識name字段,具有唯一性。數據庫服務實例對象通過type字段信息,獲得數據庫類型的實例對象,從而建立關聯性。圖4是數據庫服務管理器界面。
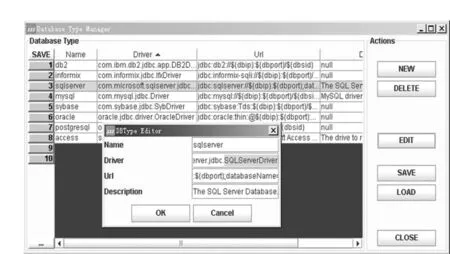
圖2 數據庫類型管理器Fig.2 Class Manager of the database
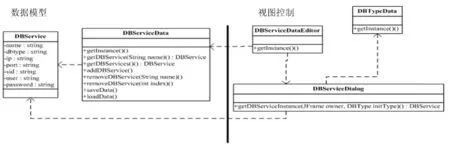
圖3 數據庫服務類DBService相關類圖Fig.3 Class diagram of related classes of the DBService
2.4 SQL查詢語句編輯支持環境
結構化查詢語言SQL(Structured Query Language)是訪問數據庫的標準語言,向普通的數據用戶提供友好的語句編輯環境是必要的。由于SQL語言本身功能靈活多變,難以簡單概括,并且不同的數據庫在一些細微的特性上有不同的實現,支持編輯的環境著重于概括最基本的業務。根據系統的需求,選擇提供了以下功能:
(a)顯示當前數據庫連接中,具備訪問權限的表名、視圖的名稱、結構信息;
(b)顯示當前選取的若干表和視圖的屬性列的信息;
(c)自動生成基本的SQL查詢語句;
(d)保存與載入SQL語句腳本的功能。
圖5和圖6分別是SQL語句編輯界面和記錄查詢界面。

圖4 數據庫服務管理器Fig.4 Service Manager of the database
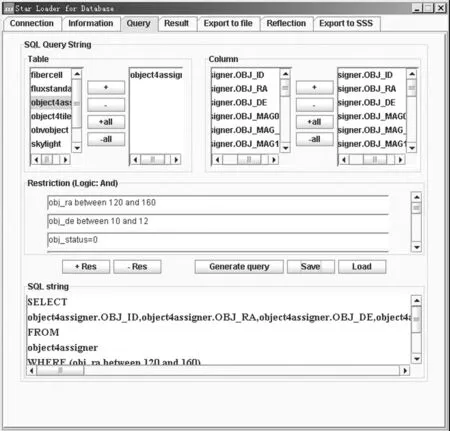
圖5 數據庫SQL語句編輯器Fig.5 SQL Query String Editor
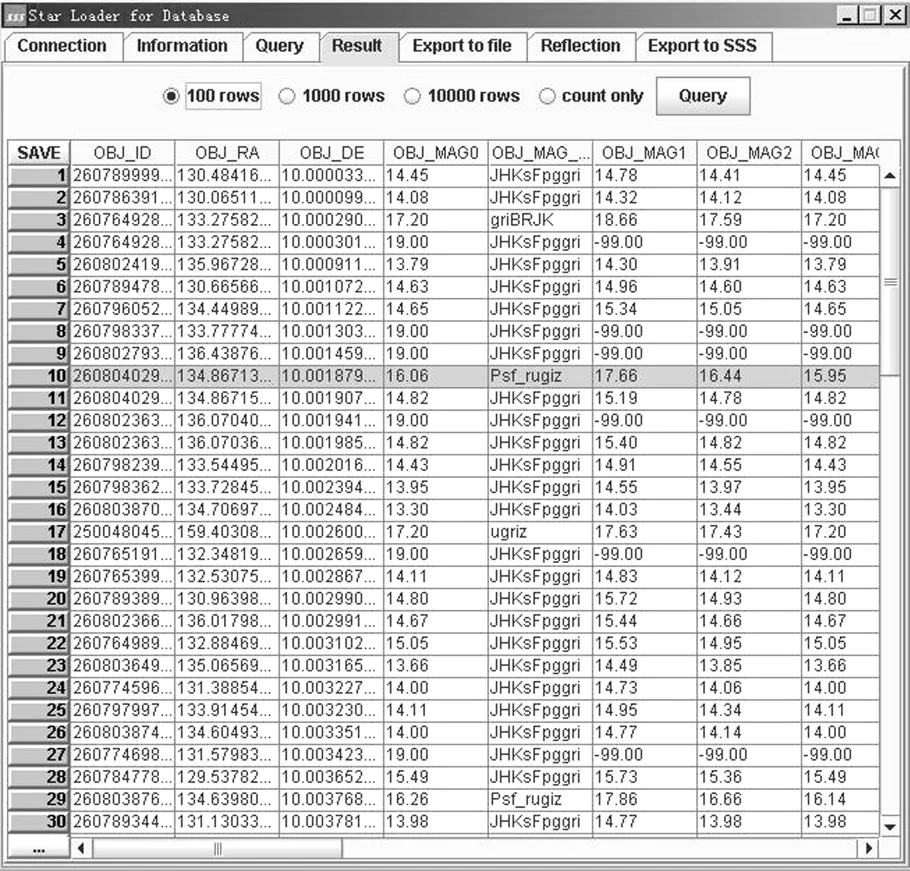
圖6 數據集獲取與顯示界面Fig.6 Result Set Generation and Display Interface
2.5 星表數據轉換映射
星表數據轉移可以分3個步驟完成:從源數據庫得到結果集(ResultSet);建立源數據與目標數據的屬性列映射關系并進行轉換;將轉換后的記錄(Record)插入目標數據庫。這里的目標數據庫就是巡天戰略系統當前的星表數據庫。為實現數據映射,需要一個通用接口,它描述了3層基本信息:目標數據庫表名;目標數據表有哪些屬性列;每一個屬性如何根據結果集取值。在描述這3層基本信息的同時,需要考慮幾個輔助特性:數據模型與視圖控制分開設計;提供結果集可選列作為參考信息;可為部分列設置常量值;可選擇自動生成ID(例如應用于LAMOST的HTM[4]級數);目標數據表及其結構存在一定程度上的可變性。
為實現這些功能和特性,建立了類DBReflection作為數據模型。DBReflection以獨立的表名描述目的數據表的類型;采用HashMap作為描述各個屬性列的轉換方式,允許在本地數據庫結構發生變化的情況下以最低的費用實現升級。視圖控制類由DBReflectionEditor實現,支持面向用戶的編輯功能。
目前,主要為系統實現了3個類型的映射:觀測目標、天光星和流量定標星。三者的數據結果略有不同,編輯器DBReflectionEditor在不需要進行深層次代碼修改的情況下,能夠動態地反映DBReflection數據的變化。
2.6 JDBC的內存安全控制
通常星表數據庫的數據量都是上千萬甚至上億,在用戶選擇具體數據庫之前是不能預知的,確保程序不會因為數據量過大而導致內存溢出是很重要的。Java虛擬機本身從系統安全考慮對溢出進行了合理處理,但是有必要在軟件實現上采用合理的方式避免溢出,這是杜絕異常的根本手段。
從工作流程的角度來看,需要重點進行內存管理的階段有3個:查詢源數據庫獲得結果集;轉換結果集為目標數據結構;將轉換后的結果存儲到目標數據庫。控制每次處理的記錄數量是避免溢出的關鍵。具體做法有如下幾條。
(a)執行SQL查詢時,為Statement設置FetchSize,即每次從數據庫服務器提取的記錄數量,這樣執行查詢就能避免結果集ResultSet產生溢出;對一般性的查詢,可針對查詢會話Statement限制每次查詢的最大記錄數,即設置MaxRow,以限制內存使用量。
(b)從結果集映射到目標數據,建立一個數據緩存,對緩存的大小進行限制;數據轉換結果暫存到緩存,當緩存滿時則一次處理緩存數據,然后清空緩存并繼續原來的工作。
(c)針對一些具體數據庫類型,采用特殊的手段。JDBC采用橋接設計模式,將上層用于程序員的標準API與下層由數據庫廠商實現的驅動分離開來,上層負責接口,下層負責實現。對于不同的數據庫,在實現上可能有些細微的差別。例如標準JDBC接口可以針對會話語句Statement,設置每次從數據庫端提取到本地內存的記錄數量,以控制內存空間,這個量即FetchSize;配置合理的FetchSize,即使一次搜索的記錄數量上萬,甚至上億,都能確保內存不溢出;而MySQL數據庫由于驅動實現上的原因,不能自由地設置FetchSize,只能選擇一次獲得全部結果集或者一次取一條記錄。因此,使用MySQL搜索大數據量時建議采用如下語句:

(d)嚴格處理數據庫資源(Connection、Statement和ResultSet)的申請和釋放。在正常運行的情況下,程序按照一定的步驟創建資源、使用資源、釋放資源。在運行異常的情況下,也要主動釋放資源,作為善后工作。例如,在Try-Catch語句之后,配合Finally語句,確保資源的釋放。Java虛擬機本身提供了自動垃圾回收功能,能夠自動釋放大部分虛擬機資源,但是由于SQL驅動的情況較為特殊,而且牽連到具體實現,有些資源需要主動釋放。
(e)使用資源共享和重復利用。例如,使用連接池技術和準備好會話(PreparedStatement)。下面是一段數據庫訪問代碼示例:
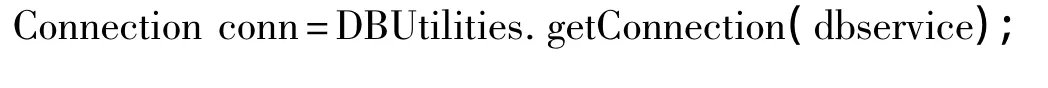

3 功能測試
為了實際測驗選星和數據錄入的功能,本文進行了一組數據錄入測試。分別選用MySQL、SQL Server和Oracle作為源數據庫,數據記錄數目為1295 134,分別設置數據格式轉換緩存的記錄數為1、50和500,目標星表ID分別使用直接引用和自動生成HTM級數兩種方式,比較不同情況下將數據進行轉移花費的時間。測試在Windows XP平臺進行,虛擬機版本為1.6,虛擬機內存大小為默認設置,忽略網絡質量產生的影響。測試結果見表1。
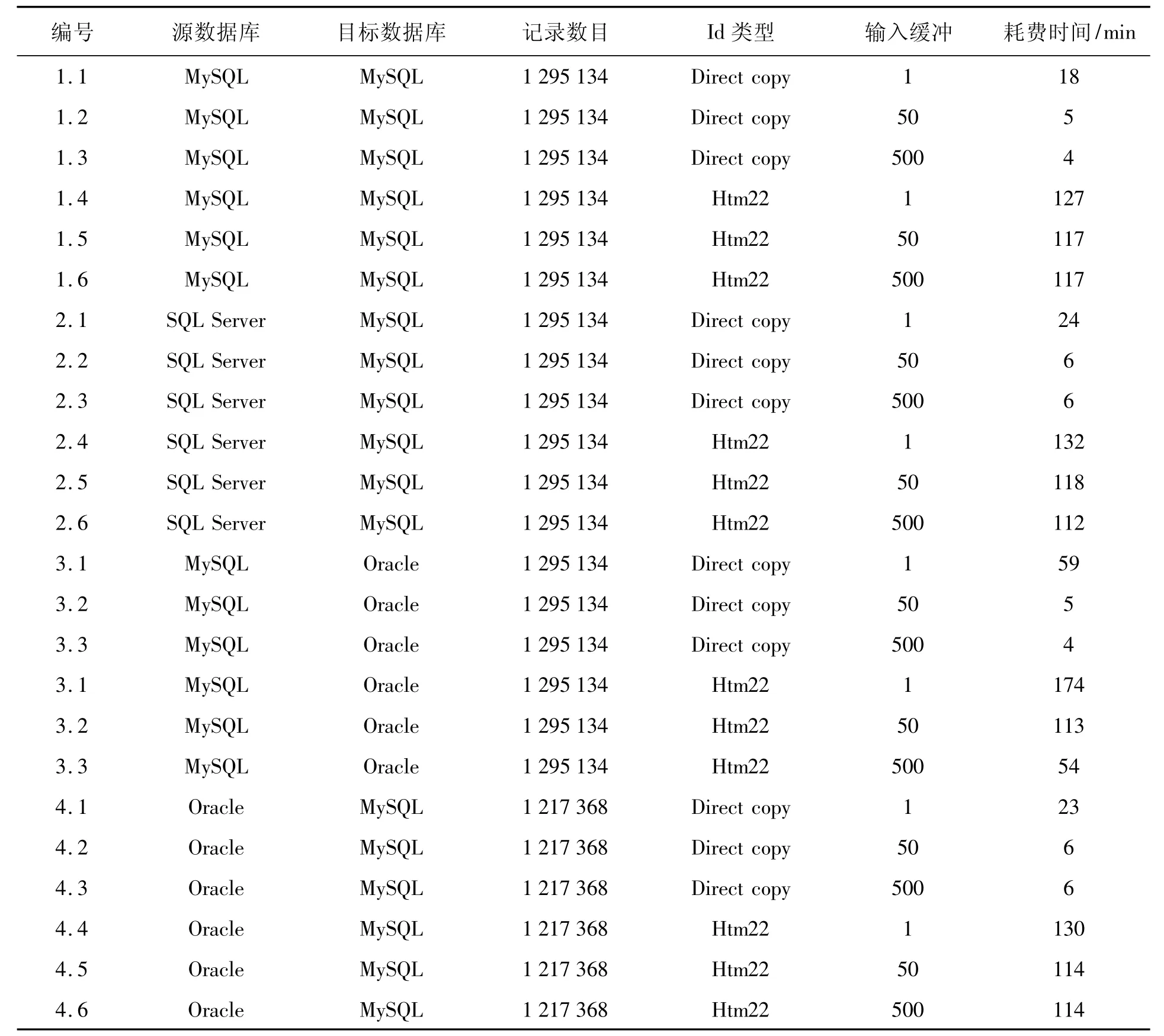
表1 選星和星表錄入工具功能測試結果Table 1 Test results of object selection and data-entry input
根據測試的結果可知:第一,數據格式轉換緩存的大小在約50時,耗費的時間基本穩定,而設置較小的緩存時,每次處理的數據塊較小,在發生數據異常時能避免丟失大量的正常數據,所以選擇緩存為50最為合適,處理速度為20×104/min;第二,LAMOST巡天觀測將采用HTM的22級數作為星表ID,計算過程需要耗費較長的時間,處理速度為1×104/min;第三,3種不同類型的數據庫之間的傳輸測試結果區別不大。考慮到實際情況下,數據量將會更大,而且運行的網絡環境可能不穩定,先進行ID的直接引用,然后再進行處理比較合適。
4 結束語
本文以JDBC技術為基礎,設計和實現了一個通用數據庫訪問與星表錄入工具,能在分布式網絡環境中訪問各種類型的數據資源,使用結構化查詢語言選擇數據記錄,配置數據轉換的映射關系,實現大數據量的星表數據轉移。研究人員可以利用此系統,訪問已有的星表數據庫,根據要求選擇需要的星表,在配置數據轉換映射關系后,實現數據遷移,為巡天觀測提供觀測目標、天光和流量定標星。作為常規的數據庫訪問終端,本系統不限操作系統平臺,不限數據庫類型,以用戶圖形界面的形式,具備協助非專家級用戶連接數據庫、查詢數據、高級數據管理、導出數據和錄入數據等多種通用功能,具有較好的容錯性和大數據量處理能力。
[1]Wang Shouguan,Su Dingqiang,Chu Yaoquan,et al.Special Configuration of a very Large Schmitt Telescope for Extensive Astronomical Spectroscopic Observation [J].Applied Optics,1996,35(25):5155-5161.
[2]褚耀泉.LAMOST科學觀測計劃 [J].中國科學技術大學學報,2007,37(6):591-595.Chu Yaoquan.Scientific Projects of LAMOST [J].Journal of University of Science and Technology of China,2007,37(6):591-595.
[3]Yuan Hailong,Ren Jian,Wang Jian,et al.Design and Realization of Survey Strategy System[C]//Brissenden Roger J,Silva David R.Observatory Operations:Strategies,Processes,and Systems II.Proceedings of the SPIE,2008,7016:44.
[4]Peter Z Kunszt,Alexander S Szalay,Aniruddha R Thakar.The Hierarchical Triangular Mesh[C]//A J Banday,S Zaroubi,M Bartelmann.ESO Astrophysics Symposia.Springer-Verlag,2001:631-637.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
