改進的RBF文本分類算法
2011-08-04 06:37:18王欣欣賴惠成
通信技術 2011年12期
王欣欣,賴惠成
(新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046)
0 引言
目前國內外基于內容信息過濾的研究主要集中在核心算法上,基本上可以概括用戶模板的構建及其算法研究和用戶模板與文本的匹配技術兩個方面,這兩個方面是文本信息過濾的兩大關鍵技術。
很多分類技術應用到文本分類中,取得了良好的效果,包括神經網絡、支持向量機[1]以及決策樹方法等,而其中利用神經網絡方法的文本分類,關鍵是提取出既能比較全面地反映文檔類別的信息,又有利于神經網絡學習的特征;其次對應著選取的特征,需要設計合適的網絡結構來分類,因此提出一種基于互信息的特征提取[1],結合聚類算法的思想,采用基于樣本中心的 RBF分類算法進行分類實驗,并給出仿真結果。
1 文本分類系統
簡單地說,文本分類系統的任務是:在給定的分類體系下,根據文本的內容自動地確定與文本關聯的類別。自動文本分類即根據統計模式識別思想,將文本表示成特征向量,然后用訓練文本對事先選定的分類器進行訓練,直接或間接地提取出蘊涵在訓練文本中有關各個文本類的統計特性,并根據這些特性確定出分類準則,最后依據這些準則對未知文本進行分類決策。一個典型的文本分類系統如圖1所示。
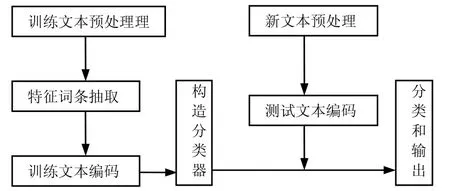
圖1 文本分類系統
2 聚類算法
典型的聚類過程主要包括數據(或稱之為樣本或模式)準備、特征選擇和特征提取、接近度計算、聚類或分組、對聚類結果進行有效性評估等步驟[3]。
K-means聚類算法是聚類分析中使用最為廣泛的算法之一[4],算法步驟如下:
②對每個樣本 xi找到離它最近的聚類中心 zv,并將其分配到 zv所標明的類 uv;
③采取平均的方法計算重新分類后的各類心;
3 基于KPCA的RBF神經網絡分類算法
比較常見的文本分類算法有:類中心向量、樸素貝葉斯、支撐向量機、決策樹、神經網絡、k最近鄰、動態聚類等[5]。
核主成分分析(KPCA)是一種對多元數據進行統計分析的技術,利用輸入空間中預先定義的核函數直接計算特征空間中的向量點積,可以對特征空間實施降噪、降維和去相關性。
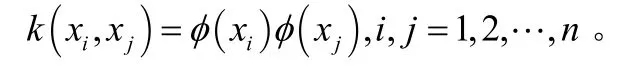
RBF神經網絡是由輸入層、隱層和輸出層3層神經元構成的典型前向神經網絡。
RBF神經網絡中隱層和輸入層之間權值(中心點 cj和中心寬度σj)的選擇是影響整個網絡性能優劣的關鍵。
(1) cj的確定
采用K-均值聚類算法[6]確定 cj,找到具有代表性的樣本點作為RBF神經網絡隱層神經元中心,從而可以極大地減少隱層神經元數目,降低網絡復雜度。
(2)σj的確定
σj決定了RBF神經網絡隱層神經元感受域的大小,對網絡的精度有很大影響。通常應用K-均值聚類算法后,對每個cj,可以令相應的σj為cj與屬于該類的訓練樣本之間的距離的平均值,即:cj和σj確定之后,采用梯度下降算法來獲取權值wij。RBF神經網絡的輸出層對隱層神經元的輸出進行線性加權組合,并增加一個偏移量 w0,可表示為:

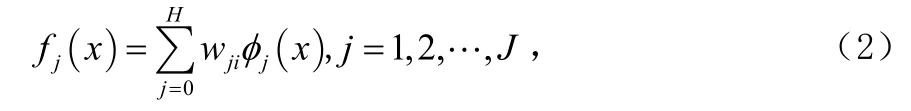
式中H和J分別表示隱層和輸出層神經元個數,nxR∈表示輸入向量,ijw為隱層第 j個神經元和輸出層第i個神經元之間的連接權值。
4 實驗設置
4.1 預處理模塊
實驗語料集的預處理采用中科院的ICTCLAS分詞系統進行。目前,在文本信息處理問題上,文本的表示主要采用向量空間模型。向量空間模型的基本思想是以向量的形式來表示文本。
4.2 特征表示模塊
常用的特征提取方法有:潛在語義索引,文檔頻數,信息增益,期望交叉熵,互信息,文本證據權,CHI統計等[7]。采用詞和類別的互信息量作為特征項抽取的判斷標準。其中:
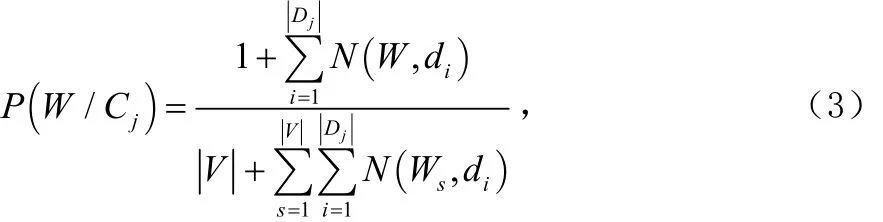
為詞條W在類別 Cj中占的比重,Dj為 Cj類的訓練文本數,N (W ,di)為詞W在 di中的詞頻,V為 Cj類的總詞數,為所有詞在該類的詞頻和。
而P(W)與上面的計算公式相同,只是把所有的訓練樣本組成一個“總類”,就是計算詞條在總類中的比重,即:
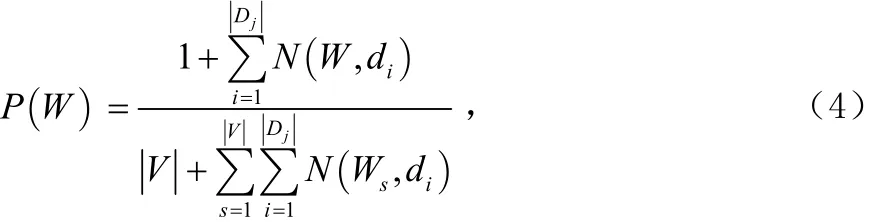
4.3 特征降維模塊
考慮到輸入空間mR 線性不可分,要在映射得到的特征空間F中變得線性可分,或者以較高的概率線性可分,核函數形式采用多項式核函數:其中θ取0,q取大于等于1的正整數。

實驗驗證,q取3時RBF神經網絡分類器取得較好的分類性能.
4.4 分類算法模塊
分類算法是文本分類系統的關鍵所在,除RBF神經網絡外,還對BP神經網絡分類算法進行了試驗。對10個分類只建立一個網絡,其中輸入層神經元數和輸入向量的特征維數一致,輸出層神經元數等于總類別數,為10,隱層神經元取64,η取0.05,minE取0.1,maxT 取3 000,徑向基函數采用高斯核函數,即:

5 實驗與分析
對581個文本樣本進行信息編碼,得到10維文本的信息編碼向量581個,其中140個作為訓練樣本,其余441個作為測試樣本,在matlab環境下分別進行BP和RBF神經網絡的分類算法實現,再利用K-means聚類方法作為RBF神經網絡分類算法的核心思想,進行RBF分類,并與BP分類算法比較。進一步改變高斯函數寬度參數進行試驗,觀察其對分類結果的影響。
文本分類系統的最主要的兩個指標是查準率和查全率,所謂的分類正確就是指自動分類結果與人工分類結果吻合。取其中3類的統計結果見表1。
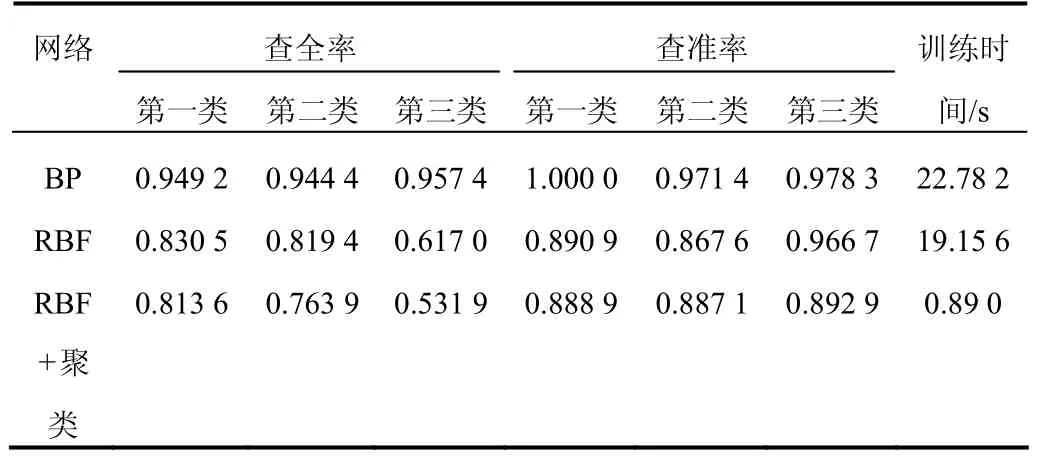
表1 分類中3類的統計結果
由表 1可以看出,RBF網絡分類結果不如 BP網絡的好,但使用給定樣本特征值的平均值作為聚類中心的徑向基網絡分類結果較好,且訓練時間很短。
對以上 3類樣本在利用結合聚類的 RBF文本分類算法時,修改高斯函數寬度參數,查全率與查準率難以同步改善,寬度參數變大時,高斯函數區分能力降低,誤差減小速度變快,最終誤差變小。
6 結語
以基于核主成分分析的神經網絡為基礎,借鑒了聚類算法的思想,采用樣本中心作為 RBF分類算法的核心,并和 BP神經網絡分類算法進行了比較,從實驗得出的誤差曲線圖和統計表格可以看出,在收斂速度和分類效果上,結合聚類的 RBF文本分類算法要好于 BP神經網絡分類算法,充分體現了改進后 RBF分類算法的簡潔和時效性。徑向基函數的寬度參數會影響分類的準確程度和實驗誤差,查全率和查準率不能同時提高,隨著寬度參數的增大,誤差會變小。實驗結果表明,通過結合聚類算法和基于核主成分分析的特征抽取算法,RBF神經網絡分類算法能有效地對輸入空間進行特征降維,并能改善 RBF神經網絡分類算法的分類性能。
[1] KUFIK T, BOGER Z, SHOVAL P. Filtering Search Results Using an Optimal Set of Terms Identified by an Artificial Neural Network[J].Information Processing and Management, 2006(42):469-483.
[2] HUANG J J, CAI Y Z, XU X M. A Hybrid Genetic Algorithm for Feature Selection Wrapper based on Mutual Information[J].Pattern Recognition Letters,2007,28(13):1825-1844.
[3] 孫吉貴,劉杰,趙連宇.聚類算法研究[J].軟件學報,2008,19(01):49-52.
[4] 蔣盛益,鄭琪,張倩生.基于聚類的特征選擇方法[J].電子學報,2008,36(12A):157.
[5] 楊俊. 基于核主成分分析和徑向基神經網絡的文本分類研究[D].安徽: 中國科學技術大學, 2009.
[6] 李燕, 張月國, 李生紅. 基于蟻群算法的文本分類和聚類[J]. 信息安全與通信保密,2009(10):57-58.
[7] 朱杰,劉功申,陳卓.中文文本傾向性分類技術比較研究[J].信息安全與通信保密,2010(04):56-58.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
