基于GPU的高速鐵路扣件實時探測技術
2011-06-11 03:35:18王夢雪陶衛楊金峰吳芳趙輝王衛東任盛偉
大連交通大學學報 2011年6期
關鍵詞:檢測
王夢雪,陶衛,楊金峰,吳芳,趙輝,王衛東,任盛偉
(1.上海交通大學 電子信息與電氣工程學院,上海 200240,2.中國鐵道科學研究院,北京 10081)
0 引言
扣件在鐵路系統起到固定鐵軌的重要作用.而現今,扣件檢測主要依靠的是鐵路工人的沿線排查,速度慢效率低.特別是近年來高速鐵路的興起,其封閉環境更增加了人工巡檢的難度[1].目前國際上對此常用的解決方案多為視覺自動化檢測技術,即在巡檢車上掛載高速相機,拍攝扣件圖片,對圖片進行處理分析,實現自動化檢測.
但是,由于傳統的圖像處理與模式識別存在信息量大、處理速度低的缺陷,扣件在線探測速度低一直是影響該方法實際應用的軟肋.到目前為止,國內外扣件最快檢測速度出現在西日本鐵路公司2006年的新干線141系綜合檢測車上,但也只在150 km/h左右.
隨著我國高速鐵路事業的發展,其對扣件檢測的速度要求越來越高.特別是我國近期開通的京滬高鐵,其對檢測速度的要求更是達到了400 km/h以上.由此可見,提高扣件在線檢測速度的要求迫在眉睫.
針對這個問題,本文提出了一種基于GPU加速的扣件在線檢測技術,可以準確地識別扣件缺失狀況,同時將處理速度大幅度提高,滿足了400 km/h高鐵試驗速度的在線探測要求.
1 系統組成與工作原理
該鐵路扣件在線探測系統由兩個探測器和一個控制系統組成.左右探測器分別監測左右兩個鋼軌的扣件狀態,檢測信號送入處理系統,進行處理、識別、判斷、存儲和輸出.位置信號來自車輪和車體,報警信號送至車載處理中心.圖1中為單個探測器的組成示意圖.

圖1 扣件探測系統組成原理示意圖
在列車運行過程中,兩臺高速工業相機連續拍攝扣件所在區域的灰度圖像,并對其進行圖像處理和模式識別,最終得到匹配結果,實時檢測了扣件缺失狀況.
采用通用的模式識別算法提取扣件圖像的紋理信息,通過與標準扣件模板進行局部梯度值匹配,并與設定閾值比較,從而判斷扣件缺失情況,具有穩定度高,不隨扣件形狀的改變而失效的優點.其信息量豐富,故處理速度相對較慢,無法滿足高速鐵路的在線探測需求.
GPU原本應用于復雜3D圖形及圖像的處理運算.與CPU相比,GPU是一種高并行度、多線程、擁有強大計算能力和極高存儲器帶寬的多核處理器[2].現今,其最高理論浮點計算速度已經可以達到40Tflops,遠遠高于同期的 CPU.如今,隨著計算統一設備架構(Compute Unified Device Architecture,CUDA)的出現,使得GPU的可編程性能再度得到提升.
所以本文采用了一種基于GPU與CPU協作的處理技術,即GPU負責圖像算法運算,CPU則負責流處理,這樣實現了扣件缺失的高速探測.
2 GPU相關研究
GPU發展到現在,已經遠遠不只圖形渲染圖形處理領域的應用.作為廣義的圖形處理器,大量的并行處理單元和存儲控制單元使其在通用計算方面能比CPU提供更多的運算資源.
NVIDIA GPU使用了CUDA編程模型,對圖形硬件和API進行封裝,使得開發人員把GPU看成是一個包含了許多核許多線程的處理器,并在類似于CPU的編程環境中對GPU進行編程,實現 GPU 的通用計算[3].
本文主要以新一代的Fermi架構GF100[4]來說明CUDA的軟硬件架構.從硬件架構來看,GF100包含四個圖形處理團簇(GPC,Graphic Processing Core).每個GPC包含一個光柵引擎和四個SM(Streaming Multiprocessor,多線程流處理器)單元以及一些存儲單元.如圖2中所示.
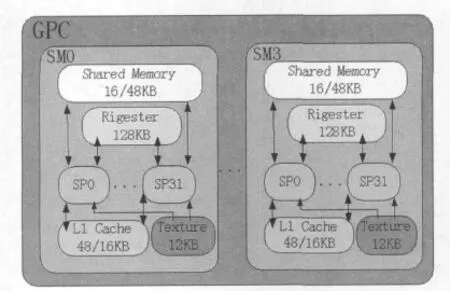
圖2 GPC架構
軟件上,CUDA對底層硬件的封裝,使其對外顯示出線程的三層組織結構,如圖3所示.具體如何組織網格(grid)由啟動kernel函數時提供的配置參數決定[5].執行配置的第一個參數指定網格的維度,第二個參數指定塊的維度,如 kernel Function<<<dimGrid,dimBlock> > > (…),dimGrid表示一個Grid中的Block數量,而dim-Block則表示一個Block中的thread數量.

圖3 kernel組織結構
而GPU理論性能的描述主要從以下幾個方面描述:
(1)CGMA(Compute to Global Memory Access),是在CUDA程序的某一區域內每次訪問全局存儲器時,執行浮點操作運算的次數.
(2)Speedup(加速比),此項指標是指對于同一算法的實現,GPU與CPU的耗時比值.記CPU耗時為ts,GPU耗時為tp,則
3 扣件探測算法在GPU上的實現
3.1 算法實現步驟
實際算法在GPU上進行并行計算主要有以下步驟:
(1)將主機端內存中的圖像數據和模板紋理通過PCI-E總線傳輸到設備端全局存儲器,并綁定到GPU的紋理存儲器中.
(2)對輸入圖像數據進行邊緣提取,抽樣濾波以及模板匹配等處理,將匹配結果存入全局存儲器中以便送回給主機端.
(3)將匹配結果傳出給主機端,方便進行顯示,分析.
具體算法流程及存儲器設計如圖4所示.此算法利用GPU的高吞吐量,采用一次向GPU壓入N幅圖像,降低了平均每幅圖像的傳輸延時;通過充分利用shared memory的塊內快存儲特性,減少了程序對global memory的讀寫次數,對提高CUDA kernel的性能有很大意義;使用了texture memory對圖像進行梯度的計算,同樣提高了算法穩定性和快速性.

圖4 算法流程圖
3.2 GPU程序的優化
影響CUDA kernel函數性能的因素主要有以下三個:CPU-GPU之間的數據傳輸延時;全局存儲器的訪存頻率(CGMA值);kernel函數的結構組成(分支、循環).下面會分別對這三點進行詳細分析,并針對本文的算法進行優化處理.
下面是一組未經過優化的實驗數據,如圖5所示.50表示一次傳入GPU的圖像數為50幅,1表示一次傳入一幅.圖像分辨率分別為160 dpi×120 dpi,320 dpi× 240 dpi.

圖5 多幅圖一次傳入性能比較
從圖中可以很明顯的看出,一次壓入50幀比一次壓入1幀的平均每幀傳輸延時減少了50~100倍,這是由于多次傳輸會浪費GPU大量warp線程,而一次傳輸會大大減少這種浪費.鑒于這個原因,本文采用大吞吐量設計,考慮GPU一次處理多幀圖像,降低每幀的平均延時.
其次,CGMA同樣對CUDA程序性能影響很大.CGMA能綜合反映出許多對執行效能有影響的因素如I/O效能,內存架構,cache的一致性.例如,NVIDIA公司生產的GTX470支持全局存儲器的訪問帶寬為135.9 GB/s,則對于單精度浮點數的加載速度不會超過33.975Gflops(135.9/4).如果CGMA比值為1.0,即執行一次單精度浮點運算即加載一次全局存儲器數據,則每秒鐘可執行的浮點操作也不會超過33.975Gflops,這相對于GTX470理論最高單精度浮點處理速度1.633Tflops來說,實在是相形見絀,限制了硬件良好性能的充分發揮.所以提高CGMA比值,是提高kernel函數性能的關鍵.
本文針對提高CGMA使用了兩種方法:第一,選擇將圖像數據和模板紋理數據均綁定到紋理存儲器,從而減少對global memory的讀寫.紋理存儲器(texture memory)是由GPU用于紋理渲染的圖形專用單元發展而來,有著無需考慮圖像訪問越界等獨特的特性,從底層的存儲機制來說,紋理存儲器是一種SP訪問全局存儲器的不嚴格機制,以緩沖來自全局存儲器的數據.一旦將全局存儲器中的某一區域與紋理存儲器綁定,那么只有當緩沖失敗的情況,才會訪問全局存儲器,大大減少了訪問global memory的次數,提高了CGMA比值.第二,將分塊技術與數據預取技術相結合.即充分利用塊(block)內共享存儲器(shared memory)(快讀寫,速度接近寄存器),在使用當前數據元素時預取下一個數據元素,將其從其他存儲器(如 global memory)加載到共享存儲器[6].
另外,指令混合也是CUDA優化技術的一種.其旨在kernel函數中減少循環和遞歸的使用,通過減少對有限的指令帶寬的占用來提高GPU的指令執行速度.但是由于本算法固有的循環維度比較大的特性,此項技術的可行性不高,所以本文只對源程序的一個10×10的小循環做了循環展開,不過運算速度卻大大提高.實驗結果會在4.1節中給出具體分析.
4 GPU加速性能實驗研究
本文中采用了七彩虹 iGame GTX470-GD5 CH版顯卡,其GPU為NVIDIA公司的GTX470型號,核心頻率為607MHz,顯存1280MB;CPU采用Intel Core2 Duo 2.7GHz,內存 2GB.編程環境為Windows下 Visual Stdio 2008(VC++9.0).
實驗中,為了得到統計性能更好的數據,我們對每次的實驗數據量都進行了20次平均.
4.1 指令混合優化實驗
指令混合前后GPU耗時實驗數據如表1所示.從表1中可以看出,塊的大小在性能中起著主要作用.在塊大小比較小的時候,循環展開對性能的提升基本沒有作用.這是由于,當塊大小比較小時,全局存儲器的帶寬處于飽和,性能瓶頸會出現在存儲器的讀寫上,循環展開對此將失去優化意義.而當塊大小足夠大時,此時指令混合和數據預取技術就顯得尤為關鍵,本例中,僅僅一個10×10的循環展開就讓性能提高了20%~40%,可見此項技術的優化潛力還是很大的.

表1 優化前后耗時對比
4.2 GPU加速性能實驗
本實驗對不同分辨率下(160 dpi×120 dpi,320 dpi×240 dpi,640 dpi×480 dpi)的N幅圖同時處理,分別得到CPU耗時和GPU耗時,測時分辨率為0.1 ms.如表2所示.其中GPU運算耗時是指算法在GPU端的計算時間,不包括前期的數據準備以及數據傳輸時間;而總耗時是二者均有的總時間.

表2 耗時測試結果 ms
從表中可以明顯的看出,不論是否計入傳輸時間,獲得的加速比都是很大的.特別是在不計入傳輸時間以及設備端的初始化等工作時間的情況下,加速比可高達500左右.需要說明是,本文CPU中的算法是經過優化處理的,所以得到的加速比的可信度是比較高的.
分析表2,可以得到如下兩個結論:
(1)在數據量比較小時,如圖像只有一幅的情況下,加速比較小;相反,在數據量比較大的情況下,加速比會大大提高.這也正體現了GPU設計的初衷,即提高吞吐量,而并不是與CPU拼單一速度.
(2)Kernel函數的性能優化技術的有機結合對性能的提高有重要意義.從圖中可以看出,當數據量為160×120×50時,加速比一度提升至600左右.這與kernel函數中的線程粒度與數據預取的合理平衡有很大關系.數據量的合理性使得每個SM上運行的線程數量大大提高,這對于整個算法的吞吐量有很大的提升.
(3)數據大到一定數量時,GPU平均每幀的處理時間會出現波動,甚至下降.這是由CUDA底層指令執行流所決定的.GPU中指令是以warp為單位發射的,而每個warp中有32個thread,當數據量變化時,thread數量也會隨之變化,多出一個thread可能就會多一輪warp.所以出現波動是正常可預測的,這也表明,在實際GPU編程中,需要注意thread數量,最好為32的整數倍,這樣可以充分利用硬件資源,減少SM的空載浪費.
另外,本實驗還有一點需要說明:由于本實驗block的維度設計與圖像寬度和圖像數有關,當數據量增加時,block的維度也會隨之增加,當數據量增加到一定程度時,會出現超過CUDA目前計算能力的block最大允許維度(65536),例如,數據量為320 dpi×240 dpi×275 dpi時,程序無法運行.這也很好的說明了,對kernel采用多種技術時,互相之間會相互影響,從而限制了彼此能優化的最大程度.
5 結論
本文圍繞高速鐵路扣件在線檢測的速度難點進行了研究,提出了采用GPU對其中改進的模板匹配算法進行加速的實時檢測技術,并對其的CUDA實現進行了深入分析以及實驗驗證.通過對本算法的GPU加速,可以獲得實時的扣件缺失情況.在不低于200幀/s的高速采樣頻率下,實現了扣件實時在線檢測,達到了平均每幅圖優于0.02 ms的處理速度.在160 dpi×120 dpi圖像分辨率下,一次處理50幀時,GPU的處理速度,相對于CPU計算,從3.996 ms/幀的處理速度提高到了0.022 ms/幀,加速比高達154.由此可見,GPU強大的計算能力及應用前景,GPU的加速技術不僅對于扣件檢測有應用意義,更是為整個高速圖像處理領域提供了重要的參考.
[1]錢廣春,陶衛.基于相關直線法德高速運動目標快速探測方法[J].大連交通大學學報,2011,32(2):79-82.
[2]吳恩華.基于圖形處理器(GPU)的通用計算[J].計算機輔助設計與圖形學學報,2004,16(5):601-612.
[3]柳彬,王開志,劉興釗,等.利用CUDA實現的基于GPU的SAR成像算法[J].信息技術,2009(11):62-65.
[4]NIVDIA's Next Generation CUDA Compute Architecture:Fermi,Whitepaper[M].NVIDIA CORPORATION,2009.
[5]NIVIA CUDA Programming Guide Version 2.0[M].NVIDIA CORPORATION,2008.
[6]JOAO LUIZ DIHL COMBA,DIETRICH CARLOS A,PAGOT CHRISTIAN A.Computation on GPUs:From a programmable pipeline to an efficient stream processor[J].Revist a de Inform tica Tericae Aplicada,2003,X(2):41-70.
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
