改進的視頻會議系統混音算法及實現
2011-05-22 02:26:10鄒力子
通信技術 2011年2期
鄒力子, 劉 林
(西南交通大學 信息科學與技術學院,四川 成都 610031)
0 引言
隨著互聯網技術的快步發展,在互聯網上傳播的數據類型逐漸增多。視頻會議系統應運而生。人類的溝通和交流,主要采用聽和說兩種方式,語音的傳輸成為衡量視頻會議系統性能最重要的一項指標。因此,對視頻會議系統中的混音算法進行研究具有重要意義。
終端對語音信號的處理必須解決的問題是多路的語音數據怎樣在本地進行混合以及播放。它會受到自身同步,延時,與視頻同步等多方面影響。在實際的應用中,語音經混合后對聲卡緩沖區的溢出是其最大的問題。
這里介紹一種混音結構,及新型改進的混音算法。在混音的質量、效率、溢出率、時延及擴展性方面和現有的混音算法進行了比較。實驗結果表明,該算法結合了人類語音的特性,根據不同場景的需求,在抑制混音溢出的同時,提高混音的質量,降低時延,具有很好的實用潛力。
1 混音算法分析
聲音是由物體振動所產生的一種壓力波。響度、音調和音色是聲音的三個主要特征。在自然界中,人耳聽見的語音則是來自四面八方聲音的疊加。對于視頻會議系統來說,需要將來自各處的語音數據在時域進行混合。語音信號的抽樣及量化都放在了聲卡芯片上。常用的聲卡為 16位,量化精度多為16 bit。在眾多操作系統如Linux中,聲卡緩沖區的數據類型通常為signed short,范圍在-32768~32767。多路混音后,幅值有可能超出聲卡可接受的范圍而造成聲音的失真。以下是幾種常見的解決辦法[1]。
(1)直接箝位法
當混合后語音強度超出緩沖區數據類型范圍時,以最大幅值來替代。這樣直接箝位會造成語音波形的人為削峰,在破壞語音信號特性的同時會促使噪音的產生。
(2)均值化混音
均值化混音在將各路語音進行疊加之后,并除以混音的路數來保證混音后不溢出。但隨著混音路數的增加,在多個混音源不在同一時間發聲的情景時,來自任一方的語音信號將被多路均分,造成音量較小而不能辨識。
(3)對齊混音
可以說是均值混音的變型,這里主要分為強對齊和弱對齊。在強對齊中,對聲強較大的混音路給予較大的混音權重,原話音較大的語音路得到增強,缺點是淹沒了話音較小的語音。弱對齊對聲強較小的混音路給予較大的混音權重。這樣音量較小的混音路話音得到放大,缺點是同時也放大了背景噪音。
以上算法雖然簡單,但都存在溢出檢測及混音質量方面的問題。下面介紹一種新型改進的混音方案及算法。
2 改進的混音算法
在基于SIP的視頻會議系統中,根據信令分發和媒體混合的不同,有多樣的構成方式[2]。就媒體流混合方式來說,有集中式混合與終端混合之分[3]。
這里設計如圖1的分布式混音模型,相比集中式混音,服務器端不進行媒體流的處理,而只執行會議系統的管理策略。終端接到分發過來的語音數據,進行解碼處理后,即開始混音。這種模式不混入終端自身出發的語音包,不受回聲的影響。綜合來看,這樣的混音系統復雜度適中,可減輕會議服務器的壓力。延時較集中式混音也有減少,對于實時應用的系統來說,性能的提升很大。
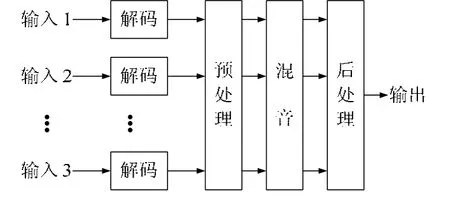
圖1 分布式混音模型
這里設計為面向中小企業及學校教學用視頻會議系統,參與人數在5人以下。會議參與者共同發聲的可能性較小,強烈溢出的幾率也比較小。因為語音信號具有短時的相關性,時間通常在10 ms到30 ms,即這里所說的一個幀。這里在設計混音算法時兼顧溢出及平滑處理,并且以語音幀為單位,算法流程如下:
①初始化衰減因子f_see為1;
②統計一幀數據內的信息,包括最大峰值的絕對值,一幀內的短時能量及過零率;
③將最大絕對峰值與16 bit數據寬度做比較,判斷是否溢出。如果溢出,求出合適的衰減因子并更新(f_see=MaX/sos,Max為最大幅值絕對值,sos為最大絕對峰值與前一幀衰減因子的乘積),并用最新的衰減因子與本幀數據相乘,輸出到聲卡緩沖;
④如果沒有溢出,則根據短時能量和過零率的計算來動態改變衰減因子。并用最新的衰減因子來輸出本幀數據到聲卡緩沖;
⑤讀取下一幀,再次執行第2步。
當幀長選擇為10 ms時,1 s內有100幀,每幀包含80個樣本。第二步中短時能量的計算公式如公式(1)。

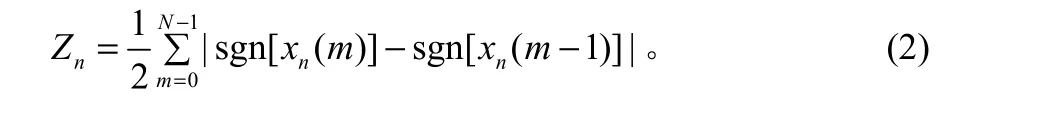
對溢出的判定,文獻[4]中所采用的衰減因子法,對每幀的每個樣本和衰減因子相乘。在常用的定點處理器中,較多的乘除法將會大量消耗 CPU的資源,帶來時延。隨意更改樣本間相對大小會導致混合后語音的失真。這里設計按幀對語音信號進行時域平滑處理,它不會改變語音的內容。通過平滑處理,一幀的語音信息按照比例縮小,語音特征參數(如共振峰及基音周期等)的大小不會改變,語音信號的波形和音色也不會改變[5]。
在樣本溢出并進行衰減處理后,需要一個機制來進行有效補償。這里對首先衰減因子進行歸一化處理,將衰減因子f_see映射成 320等分進行運算,用整型量 ppp來表達,即f_see=ppp/320,ppp為320與f_see相乘后取整。由于在語音編解碼上采用了G.711協議,A律壓擴,增強對小信號的量化精度,對小信號的調節較為豐富[6]。這里設置ppp的增減上下限為160到320。在長期混音的過程中,使語音處于小信號敏感的部位,避開粗糙的大信號,調節至人耳舒適的范圍。
歸一化的衰減因子 ppp的增減依據語音信號過零率的判斷,以及相鄰兩幀短時能量的比較。在第4步進行動態衰減因子的計算時,參考第2步對語音人聲的短時能量及過零率的檢測。根據文獻[7]中的經驗值,取10 ms幀的語音過零率閾值為4。當實際檢測的過零率在4以上時,粗略判定其為語音信號幀,之后對相鄰語音信號幀進行短時能量的比較,當語音的短時能量縮小時逐步增大衰減因子,當語音的短時能量增大時逐步縮小衰減因子。這種對衰減因子的動態恢復,將增強混音后信號的收斂性及健壯性。
3 嵌入式實現及結果分析
為了對比改進的混音算法的性能,將寫好的混音算法放在視頻會議系統實際運行的嵌入式環境下來測試。該款處理器為TI公司的DaVinci系列片上系統DM6446-594異構雙核處理器。其中混音算法放在 ARM 端運行,該 ARM 核為ARM9系列,運行頻率為297M。這里共采集3路語音,一路為純背景噪音,一路為人聲,聲強靠近溢出位置,另一路為人聲,聲強適中。兩路人聲均采用較難區分的男聲。測試結果如圖2、圖3和圖4所示。
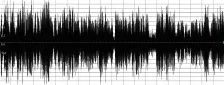
圖2 單純衰減
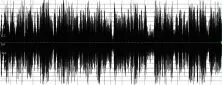
圖3 定步長單增衰減因子
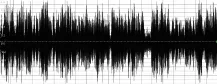
圖4 動態更新衰減因子
由混音后時域波形圖可見,圖2為采用單純溢出衰減算法的混音過程。隨著混音過程的推進音量逐漸減小。當某一刻出現混音高峰時,造成極小的衰減因子,音量變得很小而不可恢復。圖 3為參考文獻[5]中采用的定步長單增恢復衰減因子的方法,這種混音方式會使得音量一直維持在最大值附近,聲音刺耳,噪音強烈。它增加了下次混音的溢出幾率,增加了溢出檢測和新的衰減因子計算,消耗資源,帶來時延。圖4為這里改進的算法,采用按幀衰減,區別于文獻[5]的按樣本處理,減少了定點處理器的乘除法操作,提升了計算性能。其衰減因子采用歸一化細分,并設置上下限。采用短時能量及過零率來對人聲識別并動態更新衰減因子。該混音效果聽起來平滑,噪音很小、無爆破音,混音后完全沒有溢出現象發生。
4 結語
這里提出了按語音信號特征,以語音幀為單位的衰減因子法解決混音溢出問題,在算法上進行改進,提升了溢出處理的性能。并且提出了用短時能量及短時過零率來對人聲語音進行粗檢測及衰減后的補償恢復,提升了混音質量。用戶可依據網絡環境對兩種算法進行搭配選擇。通過在定點處理器 ARM9上的實現以及結果分析證明,該算法的性能及效果較好。
[1]王文林,廖建新,朱曉明,等.多媒體會議中新型快速實時混音算法[J]. 電子與信息學報,2007,29(03):690-695.
[2]IETF RFC 4353-2006. A Framework for Conferencing with the Session Initiation Protocol[S].
[3]IETF RFC 4245-2005. High-Level Requirements for Tightly Coupled SIP Conferencing[S].
[4]張微,毛敏. 多方電話會議系統中混音溢出問題的一種改進算法[J].電子器件, 2007,30(01):294-296.
[5]周敬利,馬志龍,范曄斌,等. 一種新的多媒體會議實時混音方案[J].小型微型計算機系統,2009,30(01):169-172.
[6]ITU-T Recommendation G.711-1988. Pulse Code Modulation of Voice Frequencies[S].
[7]劉波,聶明新,向俊濤. 基于短時能量和過零率分析的語音端點檢測方法研究[EB/OL].(2007-02-01)[2010-07-01].http://www.paper.edu.cn/.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
鴨綠江(2021年35期)2021-04-19 12:24:18
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
家庭影院技術(2017年9期)2017-09-26 03:41:45
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
