基于CPU+GPU異構計算的編程方法研究
2011-05-22 02:26:10袁慶華沈健煒
通信技術 2011年2期
馮 穎, 袁慶華, 沈健煒
(解放軍總后勤部檔案館, 北京 100842)
0 引言
近年來,基于中央處理器(CPU)+圖形處理器(GPU)的混合異構計算系統開始逐漸成為國內外高性能計算領域的熱點研究方向。在實際應用中,許多基于CPU+GPU的混合異構計算機系統表現出了良好的性能。但是,由于各種歷史和現實原因的制約,異構計算仍然面臨著諸多方面的問題,其中最突出的問題是程序開發困難,尤其是擴展到集群規模級別時這個問題更為突出。
1 基于CPU+GPU異構計算的編程方法
1.1 基于CPU+GPU異構計算系統的優勢
基于 CPU+GPU的異構計算系統是指在傳統計算機系統中加入GPU作為加速部件并配合CPU共同承擔計算任務的新型系統。相比于傳統的單純以 CPU作為計算部件的同構系統,異構系統優勢明顯。首先,GPU能夠更出色的完成某些特殊應用,例如對于追求浮點運算性能的應用來說,目前GPU的浮點運算能力已經遠遠超過CPU,圖1說明了近幾年GPU與CPU浮點運算能力的對比[1];其次,原先只用于圖形處理領域的 GPU正在逐漸向通用計算方向發展,在各GPU生產廠商的大力推動下,一些原先制約GPU通用化的障礙(如硬件結構、編程模型)已經不同程度地得到了克服;最后,當今單純由 CPU搭建的高性能計算機系統遇到了許多難以克服的問題,例如擴展性問題、功耗問題等,而使用GPU加速部件可以很好地解決這些問題。
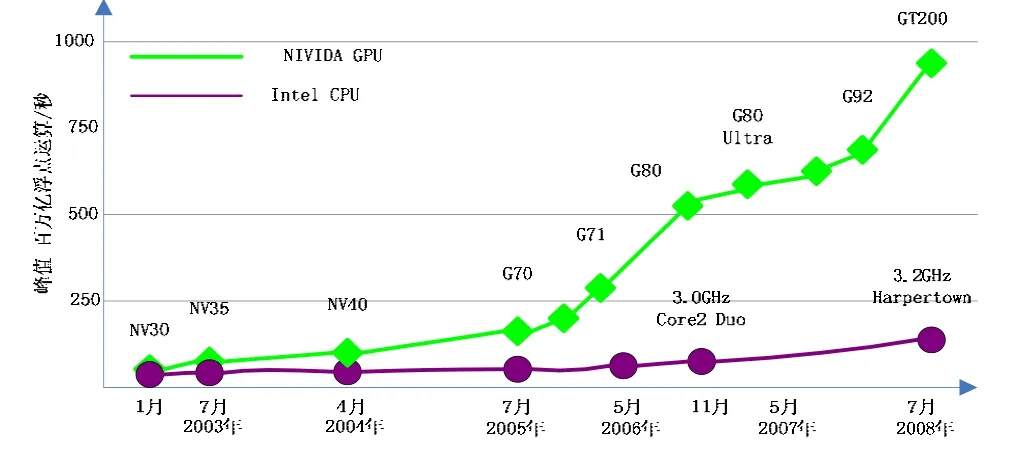
圖1 CPU與GPU浮點性能比較
1.2 基于CPU+GPU異構計算系統編程方法面臨的困難
雖然基于CPU+GPU的異構計算發展迅速,但是由于各種歷史和現實原因制約,異構計算仍然面臨諸多方面的問題,其中,最突出的是程序開發困難的問題。究其原因:一是 GPU的最初設計目標是專業圖形處理而非通用計算,這導致了GPU本身的體系架構對通用計算存在很多硬件制約,例如數據傳輸限制、缺少數據校驗機制、雙精度性能偏低等,這使得程序開發人員在使用 GPU進行通用計算時不得不專門考慮這些問題。二是 GPU軟件開發的編程模型及編程方式還不成熟,盡管英偉達(NVIDIA)公司推出的計算統一設備架構(CUDA)技術已經大大降低了GPU通用計算開發的難度,但是要程序開發人員轉變長期以來的CPU模式X86編程習慣并非易事,而如何處理以往應用中的大量遺留代碼也是個挑戰。三是異構計算的標準開放計算語言(OpenCL)推出時間還比較短,盡管各 GPU主要生產廠商都已經宣布對OpenCL進行支持,但就目前來看,基于OpenCL的應用和開發還遠未形成氣候。
2 目前可用的程序開發方法及適用場合
目前,適合于CPU+GPU異構計算的程序開發方法可以大致分為以下四類:基于底層圖形應用程序接口(API)的開發方法、基于低層次抽象的輕量級 GPU編程工具、基于高層次抽象的函數庫或模板庫和基于高層次抽象的使用編譯器的方法。
2.1 基于底層圖形API的開發方法
這是GPU通用計算領域早期使用的主流方法,在新的GPU上一般仍可使用。這種方法要求開發者必須熟悉GPU硬件底層圖形 API,并需要設法將程序映射到圖形處理過程。一般使用開發圖形庫著色語言(GLSL)等圖形繪制語言進行編程。
早期的GPU產品都是基于分離渲染架構,即圖形渲染過程分為頂點處理、片段處理等幾個過程,這時的 GPU可編程能力比較差。隨著2001年GeForce3的出現,頂點級可編程開始普及,人們開始使用它進行了通用編程。到了2002年人們開始利用紋理著色(Texture Shader)結合基于寄存器組合器(Register Combiner)來求解擴散方程,而到了2003年像素級可編程性出現,很多人開始利用像素程序來求解一般代數問題,甚至有限差分方程組求解(PDEs)和優化問題的求解。這個階段的GPU都是通過底層圖形API向圖形程序員提供可控制能力。最常見的圖形API有兩種:開發圖形語言(OpenGL)和DirectX。OpenGL作為事實上的工業標準已為學術界和工業界所普遍接受;DirectX作為微軟視窗的標準,可以根據 GPU新產品功能的擴充與進展及時定義新的版本以擴充新的接口。
2.2 基于低層次抽象的輕量級編程工具
CUDA是一種將GPU作為數據并行計算設備的軟硬件體系,它是一個完整的用于通用目的計算的圖形處理器(GPGPU)的解決方案,提供了硬件的直接訪問接口,不用像傳統方式一樣必須依賴圖形API來實現GPU的訪問。CUDA采用 C語言作為編程語言,提供大量的高性能計算指令開發能力,使開發者能夠在GPU計算能力的基礎上建立起一種高效的密集數據計算解決方案。CUDA架構如圖2 所示[2]。
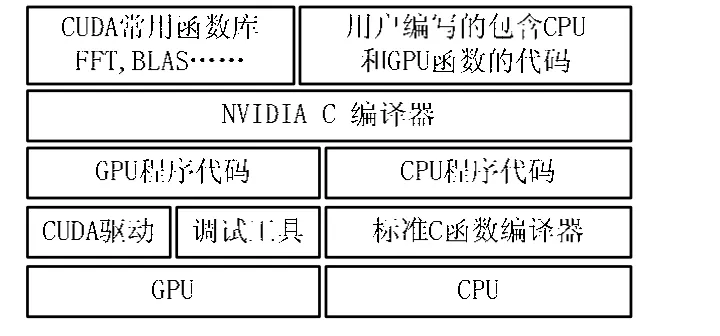
圖2 CUDA架構圖
OpenCL是第一個面向異構系統通用目的并行編程的開放標準和統一的編程環境,適用于CPU、GPU、Cell類型架構以及DSP等其他并行處理器。作為開放標準,可以為CPU、GPU和其他分離的計算設備(這些設備被組織到單個平臺中)所組成的異構群進行編程。作為并行編程框架,OpenCL目前包括一種開發語言、API庫和一個運行系統來支持軟件開發,不必將算法映射到底層圖形API上。
2.3 基于高層次抽象的函數庫或模板庫
CUDA快速傅里葉變換(CUFFT)是一個利用GPU進行傅里葉變換的函數庫,提供了與廣泛使用快速計算離散傅里葉變換的標準C語言程序庫(FFTW)相似的接口。不同的是FFTW操作的數據存儲在內存中,而基于CUDA離散傅里葉變換(CUFFT)的操作數據存儲在顯存,不能直接相互取代,必須加入顯存與內存之間的數據交換,進行封裝后才能替FFTW庫。CUDA線性代數基礎子程序庫(CUBLAS)是一個基本的矩陣與向量的運算庫,提供了與BLAST相似的接口,可以用于簡單的矩陣計算,也可以作為基礎構建更加復雜的函數包,如線性代數程序包(LAPACK)等。CUBLAS操作的數據也存儲在顯存中,同樣需要封裝后才能替代基本線性代數子程序(BLAST)中的函數[3]。
2.4 基于高層次抽象的使用編譯器的方法
基于高層次抽象的使用編譯器的方法是指通過使用指示語句、算法模板以及十分復雜的代碼分析技術、編譯器或語言運行時系統自動生成GPU內核程序。
PGI x86+GPU編譯器是意法半導體子公司Portland Group的高性能并行編譯器產品。它引進一組新指示語句(PRAGMAS)以用來指示哪一部分的代碼可以被映射到GPU上執行。指示語句定義了內核程序區域,描述了循環結構以及它們與GPU上的線程塊和線程之間的匹配。指示語句同時也用于指示哪個數據需要在主設備和GPU存儲器之間復制。
超立方體大規模并行處理語言(HMPP)一個基于標簽語法的多語言程序設計環境,利用它能夠使軟件和目標硬件設備保持獨立,提供將已有應用程序部署到 GPU的有效工具。它同時擁有CUDA和OpenCL代碼生成器,使用HMPP目標代碼生成器可以改進硬件加速的關鍵程序段的性能。代碼生成器用來從原來的C或Fortran程序中提取可以并行化的部分,并將其轉換為CUDA或者OpenCL代碼,不需要使用新的GPU開發語言重寫程序。HMPP工作平臺包括一個C和 Fortran的編譯器、代碼生成器以及一個無縫集成進開發環境中的運行時系統,HMPP工作平臺架構如圖3。
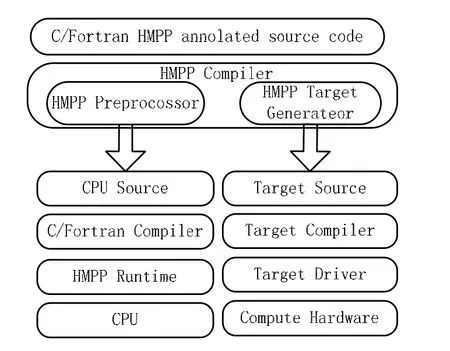
圖3 HMPP工作平臺架構圖
2.5 多GPU設備和GPU集群環境下的程序開發
在多GPU設備環境或GPU集群環境下開發程序,除了上面提到的四種程序開發技術之外,還需要其他必要輔助技術。一般來說,管理多個GPU設備可以使用OpenMP技術,在使用CUDA時還能夠使用CUDA提供的特殊功能API來管理多GPU設備;在管理由CPU+GPU異構系統作為節點構造的集群時,可以使用 MPI技術,也可以使用 Charm++技術。具體應用中,OpenMP和MPI配合使用的情況居多。
3 現有編程方法的適用場合及優缺點分析
對于在 GPU通用計算上發展階段積累了大量基于底層圖形API方法程序的開發者來說,繼續使用基于底層圖形API方法仍然適用,這樣可以解決如何處理遺留代碼的問題,不用對原來的程序做太多修改。缺點主要表現為:首先,編程人員必須編寫控制圖形流水線的程序,如分配紋理存儲、構造圖形素元等,這要求編程人員對圖形API以及GPU硬件特點與限制需要有詳細了解。其次,編程人員仍然需要利用紋理、三角形等圖形素元表達他們的算法。此外,這種方式在新的基于統一渲染架構的 GPU產品上運行時的代碼執行效率會有些不足,在開發新程序時相比其他方法也沒有優勢。
對于那些采用少量專業領域算法的應用程序,這種場合中開發者往往無法在標準函數庫找到對應程序,這時最佳的開發方法是使用諸如CUDA、OpenCL之類的基于低層次抽象的編程工具。在這種情況下,影響性能的關鍵代碼往往集中于少量程序段,由開發者完全自己編寫這些代碼是切實可行的,這樣可以充分利用 GPU的具體數據結構以及其他的優化方法,以獲得最佳的加速效果。缺點是一般需要學習一門新的編程語言,不適用于遺留代碼較多的場合。
對于大部分運行時間都用于執行標準函數的應用程序,使用 GPU加速版本的標準函數庫可以很容易地提高執行效率,而獲得效率的關鍵是盡量減少 GPU與主機之間的通訊。基于高層次抽象的函數庫或模板庫方法的缺點是這類函數庫的靈活性稍差,并且有可能造成多余的存儲器訪問。
對于大量使用專業領域算法應用程序的場合,在標準函數庫內找不到對應,而開發者自己編寫全部代碼又不現實,這時可以使用基于編譯器的方法。由于發展時間較短,目前這種方法也存在很多缺點,以Portland Group并沒有很好地隱藏內核程序并行化的復雜度,用戶仍需要去做所有較大的工作,例如如何將嵌套循環結構映射到底層的流處理器。
4 結語
CPU+GPU異構計算模式在當前的高性能計算領域逐漸成為熱點研究方向。文中分析了基于CPU+GPU異構計算模式程序開發面臨的主要困難,總結了當前主要的可用解決途徑和研究方向,并對各種編程方法的適用場合和各自的優缺點進行了詳細分析。目前,GPU產品的硬件架構在向著有利于程序設計的方向不斷改進,學術界和工業界對基于CPU+GPU異構計算的編程方法研究也在快速發展,可以預見,隨著 GPU編程方法研究的不斷深入,基于 CPU+GPU的異構計算系統將會在高性能計算領域發揮更大的作用。
[1]NVIDIA Corporation. CUDA Programming Guide 2.3[Z/OL].(2009-11-02)[2010-06-03].http://developer.nvidia.com/objec t/cuda.html.
[2]NVIDIA Corporation. NVIDIA Tesla GPU Computing Technical Brief 1.0[Z/OL]. (2007-5-05)[2010-06-03]. http://developer.nvidia.com/object/cuda.html.
[3]張舒, 褚艷利. GPU高性能計算之CUDA[Z]. 北京:中國水利水電出版社, 2009.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
