基于關聯分類方法的web用戶興趣預測的研究
2011-02-19 07:48:50于春霞宋新旗
制造業自動化 2011年2期
于春霞,宋新旗
YU Chun-xia,SONG Xin-qi
(黃河科技學院,鄭州 450063)
1 數據準備
試驗數據主要是其中的用戶點擊流文件。它包括217個屬性,777,480個記錄;測試數據集包括215個屬性,164,364個記錄。它的文件大小是1.148.6M,包含了很多原始記錄,每個記錄是一個網頁瀏覽,同時也包括了用戶的信息。
我們會從表中發現有許多重復的會話和用戶信息,另外原始的文件太大,其中有許多屬性與我們的問題關聯不大,如email,country等屬性,于是我們從中挑選了三十多個屬性,如服務器日志本身記錄的信息客戶端IP,服務器名稱,用戶請求,日期,協議版本等,用戶的一些信息性別,年齡,職業,住址等。在這些屬性上面作投影,從而我們的訓練數據得到很大的精簡。在此基礎上,通過前面描述的數據凈化,用戶識別,會話識別等過程處理后,形成一個預處理的會話文件,其中的重復的會話信息和用戶信息可以合并。
在經過預處理的web日志中尋找事務的方法如下[1]:
1)根據每一個訪問者的IP,劃分日志,即在日志中找到每一個訪問者的訪問記錄集。
2)對每一個訪問者的訪問記錄集,根據C進行分割,找到每一個訪問者的每一次訪問記錄集,這時,每一個訪問者的每一次訪問記錄就構成了一個訪問事務。
3)最終按時間排序的所有訪問事務形成訪問事務集T。
每一個用戶訪問事務相當于用戶對站點的一條訪問路徑。用戶的訪問事務集就是全體用戶在一個時間段內對站點的訪問路徑集T,T構成了我們進行挖掘的基礎。
2 基于關聯分類方法的web用戶興趣預測
下面我們考慮解決問題2的方法,我們的目的是要預測用戶將要訪問含有那些品牌的網頁。我們的事務集T包括的屬性有網頁瀏覽的信息,如請求者的地址,請求的網頁地址,請求時間等屬性;另外,還包括用戶的一些信息,如收入,職業,年齡等。我們要特別注意的是最后的一個屬性(ViewedBrand:Hanes,AmericanEssentials,DonnaKaran,Other,Null)。這是因為在我們的點擊流文件中,有很多用戶訪問了含有Hanes,AmericanEssentials,DonnaKaran品牌的網頁,于是,我們把含有這些品牌的網頁各作為一類;訪問含有其他品牌的網頁的比例非常小,所以我們把所有這些含有這些品牌的網頁作為一類,用Other來表示;最后我們把不含有品牌的網頁用Null來表示。下面運用上章討論的關聯關則分類方法將在己有的事務集上找出所有可能的CARS,然后用這些CARS構造一個分類器來預測用戶的興趣。方法是這樣的,我們把ViewedBrands屬性看成類別屬性,剩下的屬性當作條件屬性去處理。在挖掘關聯規則以前,我們先要確定最小的支持度和可信度。經過多次試驗之后,我們發現最小的支持度為0.1%,可信度為70%時,試驗的效果較好。我們分別用傳統的分類規則挖掘算法和改進后的用于web挖掘的分類規則挖掘算法進行處理。
下面是兩算法所用的時間對比圖:

圖1 傳統的和用于web使用挖掘的類別關聯規則挖掘算法效率對比圖
從圖1中,可以看出改進后算法效率有很大的提高,這是因為改進的算法首先采用FP-growth算法挖掘頻繁項集,這要比Apriori算法的效率要提高一個數量集;另外,對頻繁項集中不包含決策屬性值的頻繁項集不做任何操作,因為這些頻繁項集無法產生所需的類別關聯規則;其次對剩余的頻繁項只以頻繁項中的決策屬性值作為規則的類別屬性Y,其余條件屬性值組合作為規則的前件(condset)來生成規則;所以算法效率有很大的提高。
分析我們的所得的規則,明顯看出當用戶訪問了Fashionmall網頁或Winniecooper網頁時,他就很可能訪問Hanes,DonnaKaran商標;而當用戶訪問了Mycoxpons網頁或Tripod網頁時,他就很可能訪問AmericanEssential商標。為了更好的描述實驗結果,設REL表示在測試數據集中的某一類別網頁頻道集合,RET表示在測試數據集中我們預測的某一類別網頁頻道集合。我們先作如下定義:
Recall=RET∩REL/REL,表示在測試數據集中,我們預測的某一網頁頻道類別集合實際上與某一類別頻道集合的百分比。
Precision=RET∩REL/RET,表示在測試數據集中,某一類別頻道與我們預測的某一類別頻道的百分比。實驗結果如表1所示:

表1 傳統關聯分類方法的預測性能
事實上,Recall衡量了我們能預測多少用戶對某個網頁頻道感興趣,Precision衡量了預測的準確性。在上面的實驗數據中,我們可以看出,傳統的關聯分類方法和在改進后用于web使用挖掘的關聯分類方法在預測的準確性方面差別不大,但在效率方面,兩者差距較大。它們的Recall的值是相當不錯的,基本上達到了50。預測也是很準確的,Precision的值也基本上達到了90%。

表2 改進后用于web使用挖掘的關聯分類方法的預測性能
下面我們運用ID3算法對web用戶興趣預測,首先,我們來訓練判定樹,然后,來用它來預測用戶的訪問興趣。
試驗結果如表3所示:
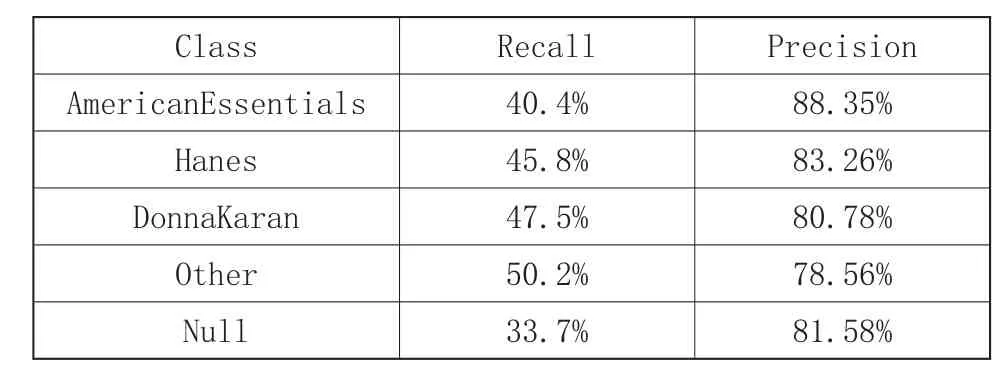
表3 ID3算法的預測性能
在此,我們把這三種方法的試驗效果用點線圖表示出來,我們可以看到,傳統的關聯分類方法與用于web使用挖掘的關聯分類方法在效果上沒有大的差別,但它們的效果明顯的都要比ID3方法的試驗效果好。

圖2 三種方法的試驗效果對比圖
所以,改進的用于web使用挖掘的關聯規則分類算法對web用戶的興趣預測是有效的,一方面,它比傳統的關聯規則分類算法的效率有很大的提高,另一方面,一般而言,它比一些決策樹方法的效果要好。
3 一種基于web挖掘的網站個性化推薦系統結構
站點的個性化服務會針對不同的用戶提供不同的服務,盡最大努力的使用戶方便,快捷的獲得信息,同時,也可以對不同的用戶提供不同的商務活動。它主要是根據用戶以前的訪問信息來提供服務,也就是說,當前用戶已有一個訪問序列,那么具有類似訪問序列的其他用戶(這些用戶與該用戶具有相同的訪問興趣)的下一次訪問可以為該用戶提供推薦[2]。當然,要更好的對用戶提供個性化服務,還必須對站點本身的內容有更好的組織,所以,內容挖掘和結構挖掘對提供個性化服務來說也特別重要。本文提出一種站點的個性化推薦結構,它不僅用到使用挖掘,還要用到內容挖掘等,結構如下所示:
系統主要分為在線部分和離線部分:
離線部分:
使用挖掘:根據網站的結構信息,使用記錄,用戶本身記錄進行使用挖掘,找出站點的使用模式。
內容挖掘:對站點的本身頁面信息,結構信息和從搜索引擎搜到的頁面進行內容挖掘,來更好的對網站的信息進行組織。同時,可以通過搜索引擎來彌補站點本身內容的有限性。
在線部分:

圖3 一種基于web挖掘的網站個性化推薦系統結構
推薦引擎識別出每個用戶的當前交互會話,得到每個用戶的當前訪問序列,進而根據使用模式信息得到用戶的下一些可能訪問的頁面類別,這些頁面的地址被附加到用戶當前訪問頁面的底部,以進行推薦。個節點可以通信,通過競爭機制來獲取信道。每個節點周期性睡眠和監聽信道,如果信道空閑則主動搶占信道,如果信道繁忙則根據退避算法退避一段時間后重新監聽信道狀態。在程序設計中主要采集中斷的方法完成信息的接收和發送。
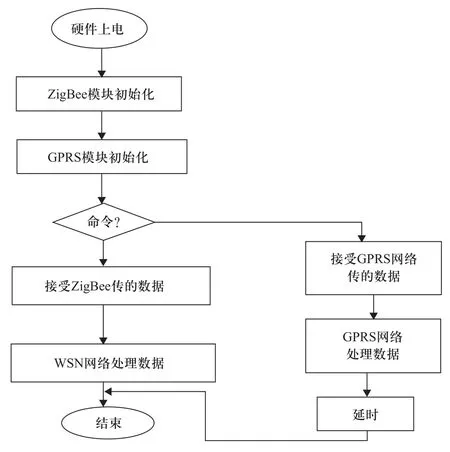
圖3 主程序流程
3 結論
基于無線傳感器網絡的智能小區監控系統結構簡單,耗電量小,布線方便,并能實時監控網絡覆蓋區域的煤氣泄流和火災災害。提高了小區安保控制系統的靈活性及安全性。
[1]鄧瑩,張麗,劉有源.基于無線傳感器網絡的智能建筑安防系統研究[J].中國水運,2007,(5).133-134.
[2]柴淑娟,趙建平,基于無線傳感器網絡的水質監測系統的研究[J].曲阜師范大學學報,2010(36)75-77.
[3]基于CC2430的無線傳感器網絡系統設計[J].電子產品世界,2010,11.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
讀者(2017年5期)2017-02-15 18:04:18
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
