高職院校學生網絡輿情分析系統的研究*
2011-02-02 00:57:20婁建瑋
濰坊學院學報 2011年2期
婁建瑋
(濰坊職業學院,山東 濰坊 261031)
0 引言
隨著社會自由度的逐漸開放和大眾傳媒的進一步普及,輿情(public opinion sentiment)在當前社會的政治和生活中發揮著越來越重要的作用。合理正確的輿情引導,成為秩序建設的特殊形式,也是構建和諧社會的重要組成部分。與此同時,隨著高職院校的院校網絡迅速建設,“網絡化生存”正逐漸成為學生在校生活的重要方式,使得高職院校的校園輿情也出現了與網絡相結合的新特征。校園輿情同公眾輿情一樣,是大學生作為輿情主體基于自身的某種利益,對校園現實或社會現實的反映和對自身意愿的表達[1]。同時校園論壇已經成為學生發表輿情的重要平臺。
因此,基于校園論壇建立一個有效的輿情熱點推薦系統,通過信息化技術了解學生當前的思想狀態,幫助學生管理人員快速尋找到當前學生的輿情熱點,并對學生進行恰當的引導,對學生管理工作不無裨益。本研究以校園網絡服務器中的論壇數據庫話題記錄表為基礎,提出一種基于Web數據挖掘的關鍵詞權重評分協同過濾聚類算法為主線,來達到匯集輿情熱點的目的。
1 論壇輿情挖掘中的數據過濾
面對網絡上的海量數據,首先使用數據過濾來解決網絡輿情數據信息量大、數據噪聲多等問題。以學校服務器上的論壇數據庫為基礎,從tb_User表、tb_Topic表、tb_Revert表等數據表中使用聯合查詢獲得相應數據。對學生用戶發表的話題,進行前置轉換與處理,將發表話題ID、發表用戶登陸名、發表時間、話題內容長度、瀏覽次數和回復次數等四項數據作為分析的基礎,本文以表1為例進行分析。
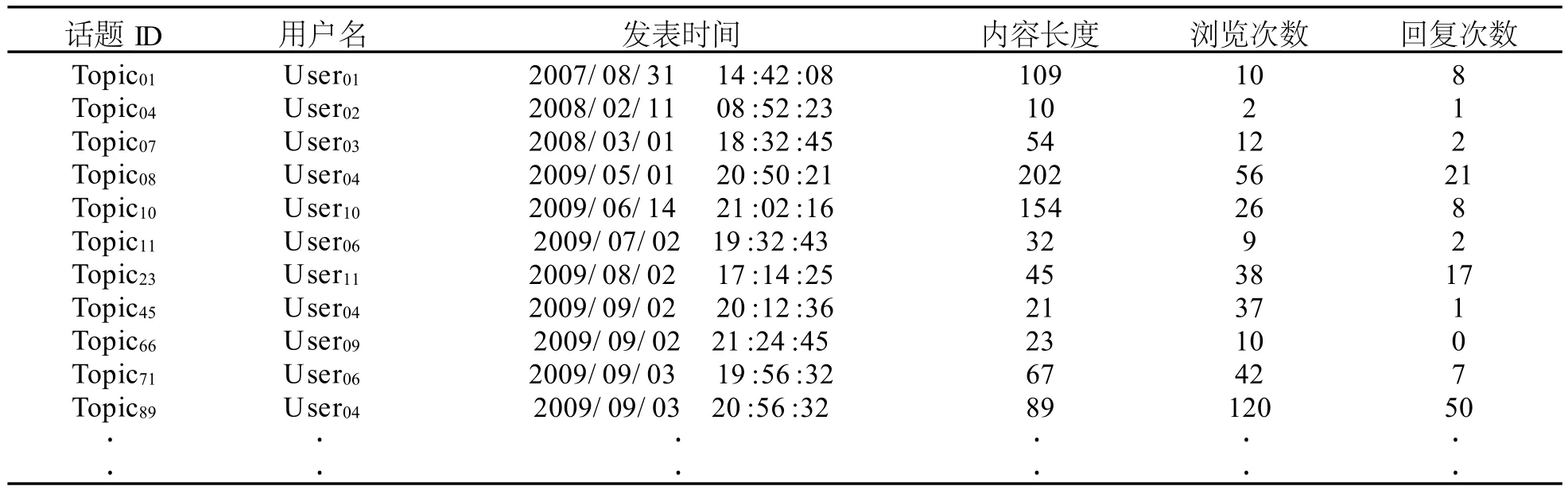
表1 前置處理后的數據表
根據從服務器數據庫中所擷取出的學生所發表帖子數據內容特性,可根據定義數據取用的限制條件,過濾出有效的數據。而在本研究中,定義了三項限制條件。
1.1 時間限制
本研究立足于對當前學生輿情的分析與引導,一般而言,學生關心的輿情熱點存在季節性的差別,因此本研究首先針對前置處理后的數據,擷取出2009年的記錄,如表2所示。表2為表1的延續,其中的數據僅保留發表于2009年的話題記錄,其余記錄皆忽略不計。
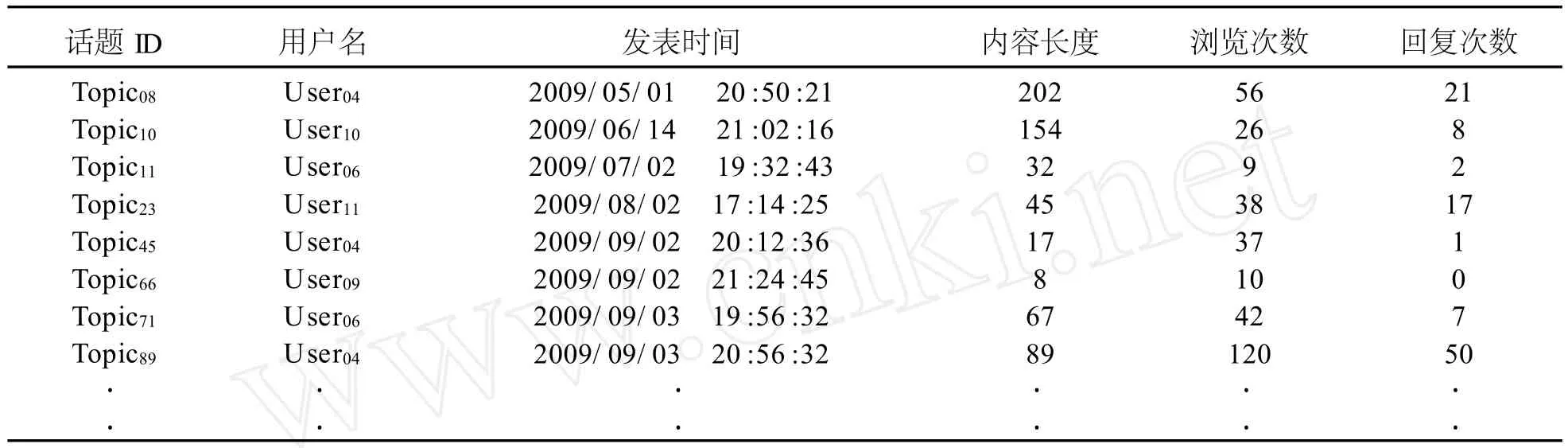
表2 時間限制
1.2 內容長度限制
學生用戶以設定的賬號與密碼登入論壇發表話題,鑒于每個學生用戶具有不同的發表目的,具有明確發表意向的用戶往往會有較多文字內容的描述。為了使分析結果具有較高的參考性,排除部分學生用戶較少字數話題的干擾項,本研究定義了一個最低內容字數的門坎值,以過濾出為獲得用戶積分而發表的字數較少無實際內容的話題,如表3所示。表3為表2例子的延續,其中話題字數小于5個字的,其瀏覽記錄將忽略不計。
1.3 興趣度限制
當在論壇上學生對一個話題的瀏覽次數(點擊率)和回復次數很高時,我們可以稱學生對該話題具有較高的興趣度。所以本研究定義了一個最低點擊率門坎值,以過濾出點擊率和回復次數之和低于門坎值的用戶話題,如表4所示。表4為表3的延續,其中學生在論壇上發表的某個話題如果沒有引起足夠的興趣度即瀏覽次數和回復數之和低于12次的,將被忽略。
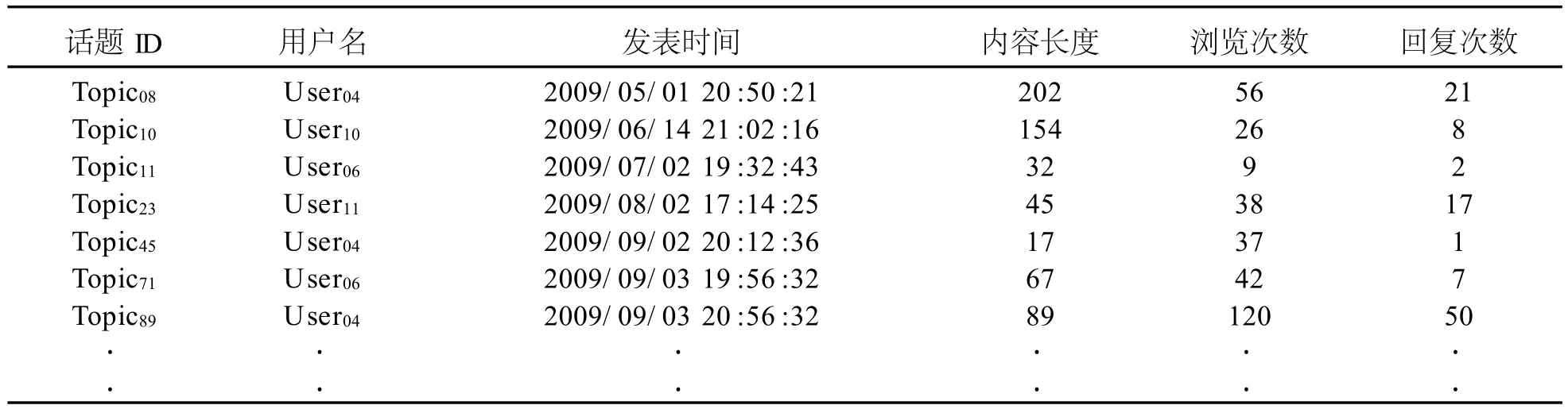
表3 內容長度限制
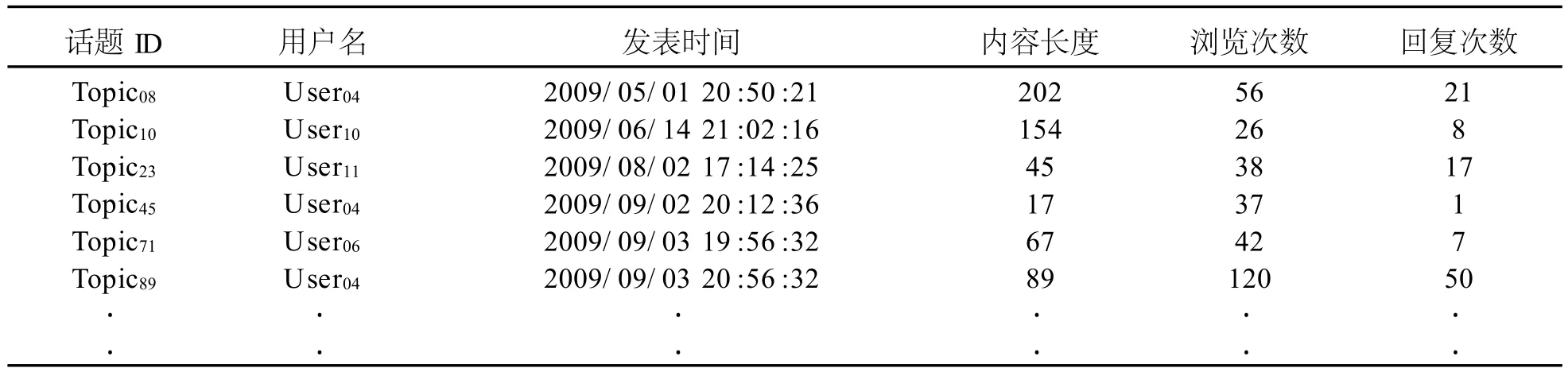
表4 興趣度限制
根據本研究所定義的三項限制條件,上述例子最后得到表4的話題瀏覽記錄,大幅降低了待處理的數據量。
如何有效地描述互聯網輿情指數,如何精確地判定某個網絡突發事件發生,如何準確地將網絡突發事件類別化等等,所有這些問題都源自互聯網輿情關鍵詞的挖掘技術。因此,在下個步驟中,要從被選數據集中獲得相應的輿情關鍵詞集分類。
2 輿情關鍵詞集的分類
2.1 輿情關鍵詞挖掘方法概述
首先,互聯網可用的信息源非常豐富,為了避免所研究的問題過于龐雜,我們將網絡輿情的信息源限定到校園網絡服務器的BBS論壇上。BBS最主要的信息傳遞方式是話題的文本信息,為網絡輿情的發生和變化提供了平臺,因此可以也應當考慮用代表文本信息的特征詞,即輿情關鍵詞對網絡輿情進行必要的描述。從話題的文本信息中挖掘輿情關鍵詞并對其進行必要的分類。
2.2 輿情關鍵詞集的選取
本文依據校園網絡的BBS論壇等文本內容均是網絡輿情的直接反映,可以作為語料集的待選信息源。內容頁面是用戶感興趣信息的主要載體,一個內容頁面中包含了圖像、動畫、音頻、超鏈接等豐富的信息表達方式,但最主要的信息傳遞方式還是正文的文字信息。為了簡單起見,本文只處理正文信息,為此我們將原始語料集中網頁結構信息,以及圖像、動畫、音頻、超鏈接等信息統一屏蔽,僅僅保留原始語料集的正文信息。
與英文不同,中文詞匯不像英語中的單詞那樣是自然分割的,有的時候是詞和詞之間緊密連接成為短語。句子中的詞匯需要人為地通過語境來切分,短語所表達的意思會因不同的切分方式而與單個的詞語意不同。在短文本串聚類方面,黃永光等人針對近些年來大量出現的聊天語言和手機短信中的短文本,提出了一種面向變異短文本的快速高效的聚類算法,該算法采取特征串抽取方法,并融合了壓縮編碼的思想,從而加快了處理速度,該方法較適合手機短信等不規范的短文本進行聚類[2]。另外,朱燁行等人為方便BBS瀏覽提取一種新的文本聚類方法,即以分等級的菜單方式組織帖子,該方法類似于找出最長公共特征串,利用頻繁出現的串先聚成小類,再對小類進行合并,進而得到粒度適當的類[3]。在研究BBS、Blog等短文本聚類時,這些技術可以有效的得到正確的關鍵詞和關鍵詞短語。
文獻[4]中給出了如何建立備選網絡輿情關鍵詞語料集,基于統計的中文高頻詞提取,輿情關鍵詞的評價標準、提取算法以及輿情關鍵詞的分類,即網絡輿情關鍵詞挖掘的四個步驟,并在關鍵詞的分類技術上,給出了一種改進了的k-均值(k-means)聚類分析算法。
經過試驗,我們按照已選定網絡輿情的備選關鍵詞原始語料集的分類目錄分別運行進行改進了的k -均值聚類分析程序,剔除重復的關鍵詞,得到代表網絡輿情的關鍵詞。
2.3 輿情關鍵詞集的分類
得到了關鍵詞集以后,為了確定各個關鍵詞分類,選用德爾菲法,根據濰坊職業學院信息工程系中具有多年學生管理工作經驗的各位輔導員的意見獲得大體的關鍵詞分類,然后統計關鍵詞評估因素分類表如表5所示。

表5 關鍵詞分類表
主要分成了六大類評估因素,在每一個大的評估因素里面,為了方便關鍵詞分類,又細分了各個方面的分支,例如,如果關鍵詞屬于對人評價類評估因素中的教師評教類,則它的分類編號為D。得到了關鍵詞的分類表就可以運用關鍵詞項目評分來匯總輿情熱點。
3 基于關鍵詞評分的協同過濾算法
基于詞匯權重評分的協同過濾算法的基本思想就是對輿情關鍵詞權重評分相似的最近鄰居(如果兩個話題文本的輿論方向大體一致,我們就稱其中一個話題文本為另一個目標話題文本的最近鄰居)的聚類算法。該相似度聚類方法基于這樣一個前提:在單一文本中關鍵詞的出現頻數可以作為用于描述文本的特征向量,如果最近鄰居對相同類別的輿情關鍵詞的權重評分與目標話題非常相似,則這兩個話題文本屬于同一種輿情方向。
在基于校園網絡的大型論壇(BBS)系統中,一個比較明顯的問題在于:當學生用戶數目和發表的話題數目增加很快,關鍵詞的評分數據卻和大幅增加的學生發表的話題成反比。在關鍵詞分布極端稀疏的情況下,根據文獻[5]中提出的基于項目評分聚類的協同過濾推薦算法(K-means聚類算法)可以有效的根據關鍵詞的相似性度量對輿情的方向進行聚合。
4 輿情熱點的推薦
在數據過濾之后,根據關鍵字庫的分類,分析話題關鍵詞的偏好。通過使用關鍵詞表遍歷數據庫,在話題中出現的關鍵詞標記為(關鍵詞類別號,關鍵詞編號),例如(A,14)代表該關鍵詞為A類第14號關鍵詞。在表4的基礎上得到表6。按照話題所包含的某類別的關鍵詞出現次數為評分標準,在表6的基礎上得到表7。
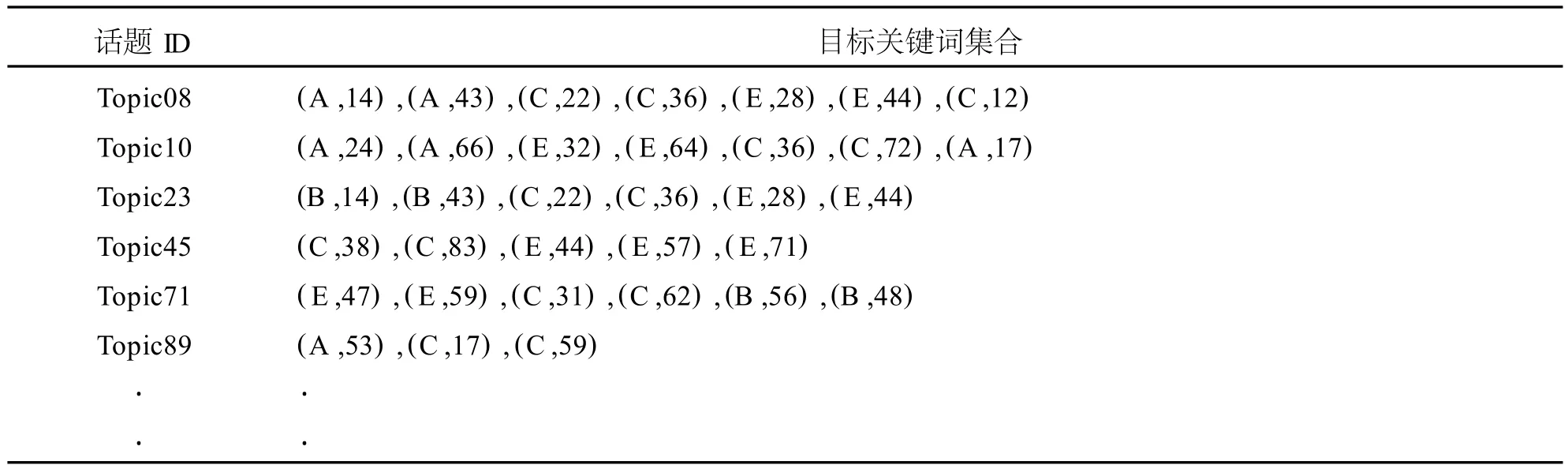
表6 話題關鍵詞集合
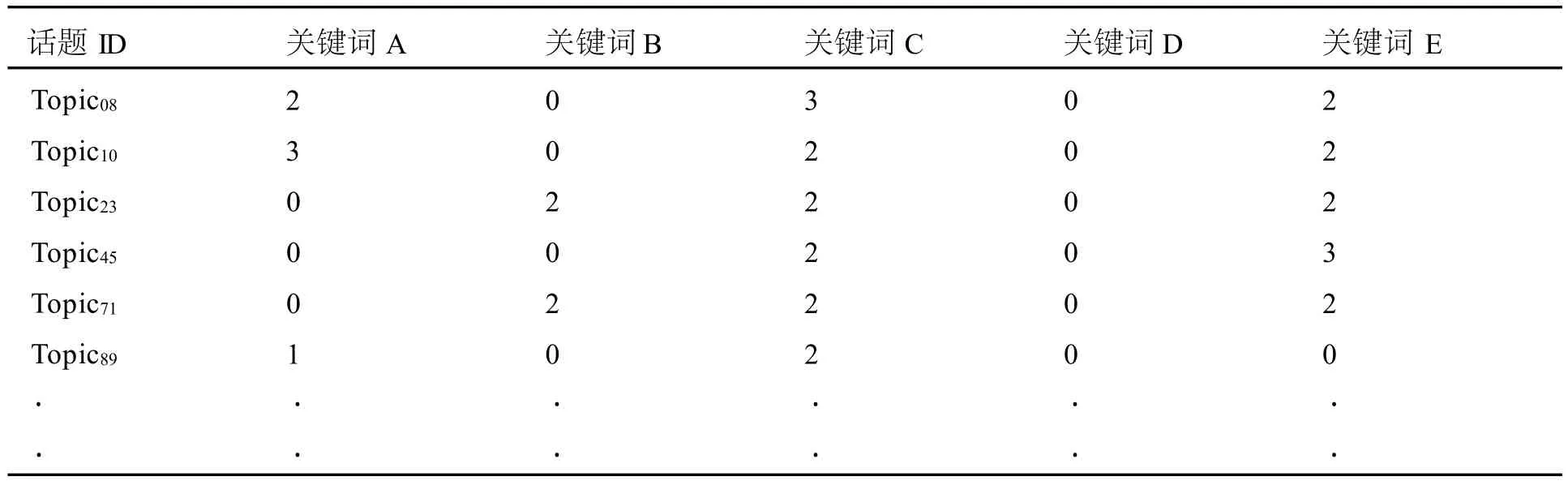
表7 關鍵詞評分矩陣
由于表7為表1一路衍生而來,所以表7中包含的所有話題,均符合文中所定義的時間限制、內容長度限制、興趣度限制。
在整理出目標關鍵詞表和關鍵詞評分矩陣之后,可以把關鍵詞集合評分大體相同的話題聚合在一起,根據協同過濾推薦算法,分別計算話題的相似度。Topic08和 Topic10的相似度近似為1,Topic23和 Topic71的相似度為1,因此 Topic10和 Topic71可以作為輿情方向相似項分別與 Topic08、Topic23進行聚合。這樣可以有效減少分析的數據量并且不影響數據挖掘的結果,為進一步縮減的結果,通過以上的方法,可以得到與合并相近性后的話題集合。接著根據興趣度即點擊率和回復率之和降序擺列,將推薦后興趣度高的話題排放在前面,整理如表8。

表8 關鍵詞評分聚類后的話題集合
在每次聚類時,把相同輿情方向中被合并的話題數目進行記錄,根據表8操作所得的結果,將得到的輿情熱點整理如表9所示。

表9 絡輿情熱點
5 實驗結果與分析
首先從校園服務器上的論壇SQL數據庫中取出論壇的話題及回復話題的記錄,共計52750條記錄,接著根據所定義的限定性條件:
(1)時間限制:2009年11月份、12月份的記錄
(2)內容長度限制:發表的話題字數在10個字以上的。
(3)興趣度限制:瀏覽和回復次數在12次以上的。
過濾后,留下1386條記錄,再使用關鍵詞評分,進行相似度計算,合并相似度近的輿情熱點。(見表10)
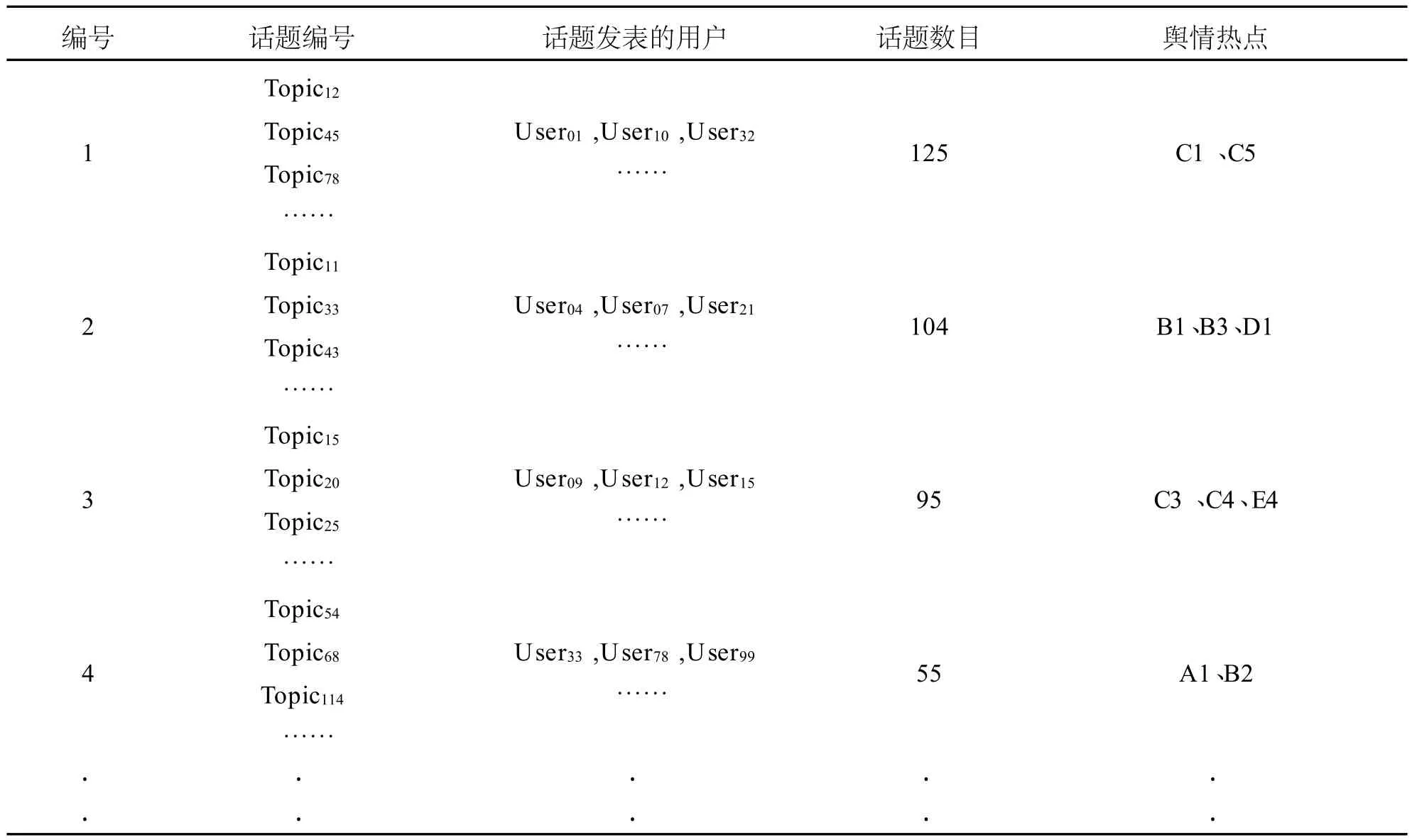
表10 網絡輿情熱點分析
根據匯總出2009年11月份、12月份的學生網絡輿情主要方向有:
(1)部分學生對學校的硬件設備滿意度不高,認為很多學生活動的實施過程形式化,沒有預期的效果。
(2)部分學生對技能大賽還存在疑惑,不知道自己適合哪個方向,哪個方向能出成績。選方向的時候基本是根據對指導老師的認可度進行選擇。
(3)部分學生對2009年11月份的學校獎學金評定過程感覺不公平,獎罰不分明,不少同學對獎學金的評選特別是市級以上獎學金的評選失去信心。
得到了大體的輿情方向后,班主任、輔導員就可以采取班會、座談會等形式,對學生進行積極的開導和引導。
[1]陳文舉,夏泉.試論高校輿論引導與和諧校園建設[J].濟南大學學報,2006,16(6):88-95.
[2]黃永光,劉挺.面向變異短文本的快速聚類算法[J].中文信息學報,2007,21(2):63-68.
[3]朱燁行,戴冠中.一種文本聚類方法及BBS瀏覽機制研究[J].微電子學與計算機,2006,23(8):55-60.
[4]趙旭東.互聯網輿情指數挖掘方法研究[D].哈爾濱:哈爾濱工業大學,2007.
[5]鄧愛林,左子葉,朱揚勇.基于項目聚類的協同過濾推薦算法[J].小型微型計算機系統,2004,24(9):67-68.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
小學教學參考(2015年20期)2016-01-15 08:44:38
