基于主題網絡爬蟲的網絡學習資源收集平臺的設計
2010-10-18 07:53:20鄭志高劉慶圣陳立彬
中國教育信息化 2010年1期
鄭志高,劉慶圣,陳立彬
(1.陜西師范大學 新聞傳播學院知識媒體研究所,陜西 西安710062;2.西安陸軍學院 軍訓教研室,陜西 西安 710108)
基于主題網絡爬蟲的網絡學習資源收集平臺的設計
鄭志高1,劉慶圣1,陳立彬2
(1.陜西師范大學 新聞傳播學院知識媒體研究所,陜西 西安710062;2.西安陸軍學院 軍訓教研室,陜西 西安 710108)
收集現存于網絡中的信息,對其進行加工、處理使其成為可用的學習資源是網絡學習資源建設中一項重要工作,主題網絡爬蟲為在網絡學習資源建設過程實現信息的自動收集提供了可能,本文以此為基礎設計了一個能滿足資源建設需要的網絡學習資源收集平臺并對設計過程中的關鍵問題進行了分析。
主題網絡爬蟲 網絡學習資源 網絡學習平臺設計
收集現存于網絡中的各類信息,對其進行加工、處理使其成為可用的學習資源是網絡學習資源建設中一項重要工作,在其過程中資源建設者面臨兩大難題:
(1)如何高效、快速地從網絡海量信息中篩選出資源建設所需的各種信息;
(2)如何使加工完成的資源更新速度跟上網絡信息快速更新的速度。
這兩個問題的解決不能靠人工操作完成,較好的解決方案是使用功能程序輔助資源建設者進行信息收集和檢測,目前被廣泛使用于網絡搜索引擎的網絡爬蟲能較好地解決上述兩個問題,本文就網絡爬蟲在網絡學習資源建設中的應用方法進行研究。
一、主題網絡爬蟲及其工作原理
網絡爬蟲是一個網頁自動提取程序,它從一個或若干初始網頁開始,獲取包含在其中的URL(Uniform Resourcl Locator,統一資源定位符)進行網頁抓取,在抓取網頁過程中,從被抓取的網頁中抽取新的URL放入抓取隊列,直到滿足系統設定的停止條件終止抓取過程。主題網絡爬蟲是根據一定網頁分析算法過濾與主題無關的鏈接,只保留主題相關的鏈接進行網頁抓取。[1]主題網絡爬蟲工作原理如圖1所示。[2]
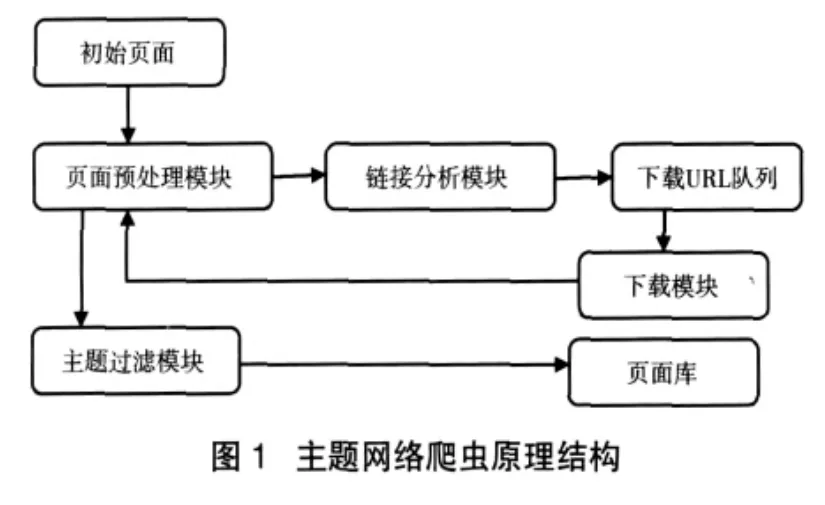
主題網絡爬蟲各個組成部分功能如下:
(1)初始頁面:包含超鏈接的一個或若干個網頁,主題網絡爬蟲從中獲取要抓取的起始頁面。
(2)頁面預處理模塊:用于頁面的分析和去除頁面中的無用信息(如廣告鏈接等)。
(3)鏈接分析模塊:用于分析頁面中提取的超鏈接,并將有效鏈接放入下載URL隊列等待抓取。
(4)下載模塊:從下載隊列中獲取URL進行網頁抓取。
(5)主題過濾模塊:對抓取的頁面按照主題進行過濾,去除跟主題無關的頁面,將滿足條件的頁面放入頁面庫。
(6)頁面庫:用于存放被抓取滿足條件的頁面。
根據其工作原理,主題網絡爬蟲能夠從一個或若干個初始頁面開始自動收集分析滿足特定要求的頁面并對其進行保存,完成信息的收集。因而在網絡學習資源建設過程中,可以以此為基礎設計一個自動收集信息的平臺有效地解決前文所述網絡學習資源建設過程中面對的兩個難題。
二、平臺的結構及運行流程
1.將主題網絡爬蟲直接應用網絡學習資源的收集會產生的問題
(1)主題網絡爬蟲工作時需要從一個或若干個起始頁面獲取URL啟動抓取過程,但它本身不能產生,需要資源建設者提供,而且初始頁面的內容會直接影響主題網絡爬蟲抓取的信息的覆蓋率和準確性。
(2)主題網絡爬蟲只能夠按照要求進行頁面的獲取和保存,不能分析其內容的科學性和準確性,而科學準確是學習資源對信息最重要的要求。
(3)主題網絡爬蟲不提供對抓取、保存的信息進行處理的功能,而信息需要進行加工處理才能成為可用的學習資源。
因此以主題網絡爬蟲為基礎構建網絡學習資源收集平臺必須解決這三個問題,綜合網絡主題網絡爬蟲的工作原理和網絡學習資源建設內在的要求,基于主題網絡爬蟲的網絡學習資源收集平臺結構如圖2所示。

2.整個平臺由數據層、系統層和應用層構成
數據層用于保存平臺運行過程中需要以及產生的數據,包括:
(1)初始頁面列表:用于保存初始頁面的URL,初始頁面既可以是已存在于網絡中的頁面,也可以是根據資源建設需要由建設者整理編輯完成的頁面。
(2)保存頁面URL列表:用于保存頁面庫中頁面的URL。該數據可用于注明已下載的頁面的出處以及減少平臺在資源下載過程中對相同位置上的同一資源進行重復下載。
(3)主題列表:用于保存在信息篩選時使用的主題信息,通過修改和設置主題列表可以使平臺收集不同主題的信息,提高平臺的通用性。
(4)頁面庫:用于保存由平臺下載且經過主題篩選的頁面。
系統層核心是一個主題網絡爬蟲,根據網絡學習資源建設需要進行了優化和功能擴展。體現在以下兩方面:
第一,主題過濾模塊每次工作時首先從主題列表中讀取主題,以確定本次工作的主題信息。
第二,下載模塊進行頁面下載時,首先查詢下載頁面的URL是否存在于保存頁面URL列表中,如果存在則跳過該頁面的下載,進行下一個頁面的下載;完成頁面下載后將其URL加入保存頁面URL列表中。
應用層用于平臺運行環境設置和資源的處理,包括:
初始頁面設置模塊,用于初始頁面的編輯和初始頁面URL列表的管理;主題處理模塊,用于主題列表的管理,包括主題的添加、刪除、修改等;學習資源處理模塊,用于對平臺自動收集信息進行處理,使其成為滿足需求的學習資源。不同類型的學習資源建設對信息處理的要求會有所差別,如有些網絡學習資源建設只要求提供資源清單,而有些需要對相關信息進行重組處理,該模塊要根據資源建設要求進行設計,也可以直接使用現有的信息處理軟件。
3.平臺運行流程
(1)用戶根據資源建設需要確定主題信息,使用主題處理模塊將有關信息加入主題列表或者對主題列表中的有關內容進行編輯修改。
(2)用戶收集網絡中與資源相關、代表性的網頁作為起始頁,這些頁面一般要包含豐富的超鏈接,利用初始頁面處理模塊將其URL填入初始頁面列表中或者對列表中的有關內容進行修改;資源建設者也可根據資源建設需要編輯初始頁面并將相關信息填入初始頁面列表。
(3)運行平臺系統層完成信息的自動收集。
(4)運行資源處理程序完成資源的處理。
平臺運行包含四個環節,這四個環節相互獨立,在資源建設和維護過程中,資源建設者可以從任意一個環節開始信息的收集和處理操作;通過反復運行平臺,可以實現跟蹤相關網站中的信息更新,從而使處理完成的資源跟上網絡信息的更新。
三、平臺設計中的關鍵問題
1.如何提高網絡學習資源收集平臺信息搜索覆蓋率
這一問題的解決取決于兩個因素,一是初始頁面的選擇,選擇內容與主題密切相關且包含豐富超鏈接的頁面作為初始頁面(如與資源建設內容相關的主題網站)和適當增加初始頁面的數目可以提高平臺搜索的范圍,從而提高收集資源的覆蓋率。二是平臺核心構件主題網絡爬蟲采用的搜索策略。作為主題網絡爬蟲的核心技術國內外有大量與之相關的研究,文獻[3][4][5][6]對目前國內外比較成熟的搜索策略進行了綜述,以主題網路爬蟲設計網絡學習資源收集平臺,可根據資源建設需要選擇合適的搜索策略。
2.如何提高下載信息的有效性
下載信息對資源建設的有效性取決于主題網絡爬蟲采用的主題搜索算法。高效的主題搜索算法有助于平臺從下載的頁面包含的超鏈接中篩選出與主題密切相關的URL進行頁面下載,從而提高下載信息的準確率。另外與主題內容密切相關的頁面作為初始頁在一定程度上也能提高下載信息的有效性。
3.完成處理的資源是否能跟蹤網絡信息的更新
網絡信息的更新包括兩種情況:一是新信息的添加;二是原有信息的修改。文中設計的平臺可以在一定程度上跟蹤其所能覆蓋網站添加的信息,但不能夠跟蹤網站修改的信息。如果要跟蹤相關網站修改的信息需在平臺中應用網絡爬蟲的資源更新策略以及相關的算法。
4.頁面庫的組織形式
網絡爬蟲對下載的頁面通常采用兩種形式進行存儲:純文件和數據庫。純文件存儲是用統一的文件格式對下載的頁面進行保存,這種方式結構統一,比較容易實現用現有的信息處理程序對其進行處理,但存在不能適應數據的動態變化、如果文件內容缺失會導致程序無法正常讀取等諸多缺點。數據庫存儲方式是將相關數據以記錄形式存入庫中,這種存儲方式比較容易實現對平臺下載的大量數據進行高效管理和維護,而且支持快速查詢,但需要數據庫系統環境的支持,如果用現有的信息處理程序對其進行處理可能會產生程序無法從數據庫中提取數據的障礙。在平臺設計過程中可以綜合考慮資源建設需要和信息處理要求選擇合適的數據存儲方式。
[1]劉金紅,陸余良.主題網絡爬蟲研究綜述[J].計算機應用研究,2007(10):26-29.
[2]戚欣.基于本體的主題網絡爬蟲設計[J].武漢理工大學學報,2009(2):138-141.
[3]陳方,譚愛平.主題爬蟲技術研究綜述[J].湖南工業職業技術學院學報,2008(10):13-16.
[4]劉漢興,劉財興.主題爬蟲的搜索策略研究[J].計算機工程與設計,2008(6):3160-3162.
[5]楊貞.基于本體的主題爬蟲的設計與實現[D].中國優秀碩士學位論文全文數據庫,2008.
[6]周立柱,林玲.聚焦爬蟲技術研究綜述[J].計算機應用,2005(9):1966-1968.
(編輯:楊馥紅)
G250.73
B
1673-8454(2010)01-0036-03
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
中外會展(2014年4期)2014-11-27 07:46:46
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
