基于標簽的Folksonomy機制研究——以CiteUlike為例
2010-07-12 08:08:52劉向紅
圖書館理論與實踐 2010年5期
●劉向紅,宋 文,姚 朋
(1.承德石油高等專科學校 信息中心,河北 承德 067000;2.中國科學院 文獻情報中心,北京 100080)
1 引言
Folksonomy是近年來流行于網絡的一種用戶參與、主導的資源自組織方式,是web2.0時代的一個重要技術輔助手段。現在,很多應用Folksonomy的網站成為web2.0的明星網站,如國外的del.icio.us、Flickr、43-Things、CiteUlike、Connotea等,國內的豆瓣網、天天網摘等。這些網站允許用戶根據自己的需要自由選擇自然語言,即使用Tag(標簽)存儲和管理自己的信息資源,并提供分享和交流的平臺。Tag之間是平等的關系,不必考慮等級結構,每個Tag相當于用戶對資源的一個分類。信息專家ThomasVanderWal將這種信息分類方式命名為“Folksonomy”。國內對Folksonomy的譯法很多,如大眾分類法,自由分類法,大眾標注,分眾分類法等,本文采用“自由分類法”的名稱。
Folksonomy這種組織形式的特點是自由、共享和動態更新,能夠迎合用戶的需求,體現用戶價值,促進集體交流,是一種基于用戶合作的分類方式。本文以國外著名的學術網摘CiteUlike為例,對社會化標簽系統中的Folksonomy機制進行分析研究。
CiteULike與del.icio.us很類似,同樣是一款免費的社會化書簽網絡工具,是專門為學術研究人員提供組織學術文章的網站。它可以幫助學術工作者分享、儲存和組織他們正在瀏覽的文獻形成個人資料庫。支持Tags、RSS訂閱、設定優先權、內容輸出到BibTeX、EndNote文獻管理系統和由BibTeX輸入內容,并支持按Tags和作者查詢以及提供用戶組等服務。[1]
Citeulike使用簡單,注冊后無需安裝插件,如果是PubMed、SD等學術數據庫中的文章,收藏時點幾下鼠標就可自動添加作者、期刊名、文章卷期、頁碼、出版商、摘要等信息,形成標準的引文格式。而且所有的這些工作均在瀏覽器中完成,不需要安裝什么特別的插件。[2]
2 數據集
本文的研究目的是通過數據收集和圖表分析,分析用戶與所標注資源的關系、用戶與所使用標簽的關系、用戶使用標簽的時間變化規律以及標簽的共現關系和聚類特性,旨在探討社會化書簽系統中用戶的標注行為特征,驗證標簽的資源組織能力。
筆者通過GoogleReader,使用CiteUlike[3]提供的RSSFeed服務,抓取了CiteUlike網站2008年12月21日至2009年6月30日時間段以Folksonomy作為標簽檢索的數據233條,去重后獲取183篇文獻,得到一組資源概況數據集,其中每條數據都包括文獻題名、作者、發表時間、文獻出處、用戶名以及標注人數。統計工作圍繞這個數據集展開。
通過統計,可以看到,被標引最多的資源是Scott Golder和 Bernardo A.Huberman 2005年發表的 《The StructureofCollaborativeTaggingSystems》,有 246個個人用戶、62個群用戶都標引了該資源。被標注次數較多的資源和作者,說明其被關注程度較高,在某種程度上可視為有關Folksonomy研究的核心資源和核心作者。
另外,筆者所獲取的83%的資源出版年限集中在2005年—2009年,2007年和2008年尤為集中,這與Folksonomy一詞在2005年開始在網絡上出現有關,同時也說明,人們對近期出現的資源較為關注,越遠期的資源關注度越低。
筆者還發現這些文獻作者數量為2—4人的最多,占64%;作者為1人的僅占23%;5個作者以上的文獻占13%,這表明,科學研究越來越趨向于合作,而非單打獨斗。[4]
3 統計結果分析
3.1 用戶與資源的關系
筆者按照用戶標注數量排序后得到一組“用戶標注資源數量”數據集,其中每條數據包括:用戶名、標注次數。表1顯示,有1224名用戶參加了這183條資源的標注活動,共發生了3662次標注活動,平均每個用戶標注2.99次,平均每條資源被標注的次數是20.01次;標注活動最頻繁的兩個用戶分別標注了53條資源和48條資源,共有24個用戶的Folksonomy標注行為超過20次。這說明近兩年人們對有關Folksonomy的研究還是非常關注的。
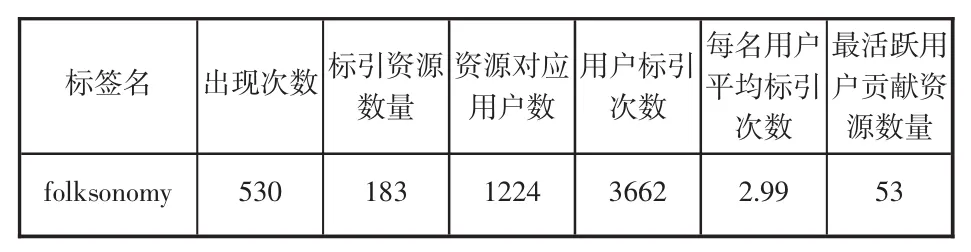
表1 基于folksonomy的資源及其對應的用戶
通過分析用戶數目與標注行為數目之間的關系,筆者發現大多數的標注行為是由相對較少的用戶產生的,標注資源數大于20篇的用戶數占用戶總數的0.19%,他們占有了17.9%的標注行為數(即標注篇數);標注資源數為1篇的用戶占了用戶總數的56.9%,而標注行為數(即標注篇數) 僅為總數的1.9%。這表明:數量較少的用戶標注行為頻次高,而大多數用戶的標注行為頻次較低,呈現“長尾(Long-Tail)”現象,遵循冪律分布規律,也就是說,數量較少的用戶貢獻了大部分資源。
3.2 標簽與用戶的關系
ThomasVanderWal、AdamMathes等多位學者均指出,標簽的使用情況也遵循冪律分布(Power Law):一方面,代表用戶共同知識的一部分標簽被多數用戶使用,具有較高的使用頻率;另一方面,存在大量“個性化”的標簽,僅對少數用戶甚至個人有意義,這些標簽的使用頻率很低,但在數量上卻比成為“熱門類目”的標簽龐大很多。
筆者選取了本組數據中被標注次數最多的1篇文獻 《The Structure ofCollaborative TaggingSystems》,統計了其2007年1月至2009年6月的標簽使用情況,得到一組共現標簽數據集,其中每條數據包括:用戶、標簽、標注時間。
統計數據顯示:該文獻在此時間段共被標注了148次,其中個人用戶標注125次,群用戶23次,共使用了349次標簽,平均每個用戶使用2.35個標簽,出現的共現標簽數為98個,還有10人未使用標簽。
作者將數據集中標簽的序號和標簽使用人數兩列的數據取值映射到坐標系中,標簽的序號作為自變量x,標簽的使用人數作為因變量y,用柱形圖表現標簽與標簽使用次數的關系,圖像呈現出明顯的冪函數的特征。
如圖1所示,排序在前幾位的標簽具有較高的使用次數,代表使用頻率高的熱門類目,但這樣的標簽是極少數,使用次數超過30的標簽僅2個;隨著標簽序號的值增大,對應標簽的使用次數減少,并且這一下降的趨勢非常迅猛,使圖像的前半部分具有很大的切線斜率絕對值;在接下來的一段取值區間中,圖像經過一個短暫的過渡后,走勢逐漸趨于平穩,圖像的后半段分布的是使用頻率低的標簽,即使用人數為2或1的標簽達到67個,占據本篇文獻標簽數量的68.37%,形成了一條基本與x軸平行的“長尾”,也就說大多數標簽屬于個性化標簽,不代表用戶的共識。
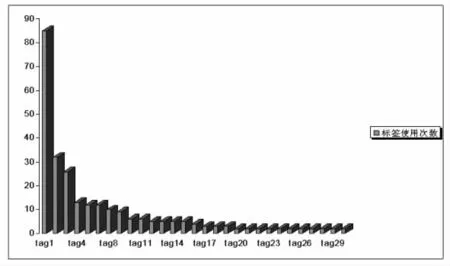
圖 1 《The Structure of Collaborative Tagging Systems》標簽使用情況
而使用人數超過2的標簽,它們中的一部分反映了用戶的共識,如tagging和folksonomy,去除拼寫錯誤和單復數形式,這兩個標簽的使用人數是85和38,分別占總標注人數的57.4%和25.7%,可以說,tagging和folksonomy就是用戶對這篇文獻的網絡自由分類名稱。
以上的數據分析驗證了用戶對標簽的選擇遵循冪律分布規律。這一特征與文獻計量學中的齊夫定律很相似。這類冪律分布的現象普遍存在于自然界和人類社會中,統計物理學家將這類現象稱為“無標度現象”,即系統中個體的尺度相差懸殊,例如互聯網、人際網,這些網絡中不同節點所擁有的連接數都遵循冪律分布規律。
3.3 標簽隨時間的變化情況
在CiteUlike中,每個用戶的標引記錄是按照時間先后順序排列的,這有助于了解用戶標簽隨時間推移的分布情況。筆者選取了標注這183條資源的用戶中標注活動最活躍的兩名用戶ianturton和brusilovsky,分別提取了他們所有標簽中使用率最高的前4個標簽隨時間變化的的情況,二者都是2006年開始有標注行為的,其標注行為如表2,然后借助Excel統計出這些標簽的使用率隨時間的增長情況,具體結果如圖2—圖3,其中橫坐標代表時間,縱坐標代表該標簽的使用率,而不同的標簽則用不同顏色表示。
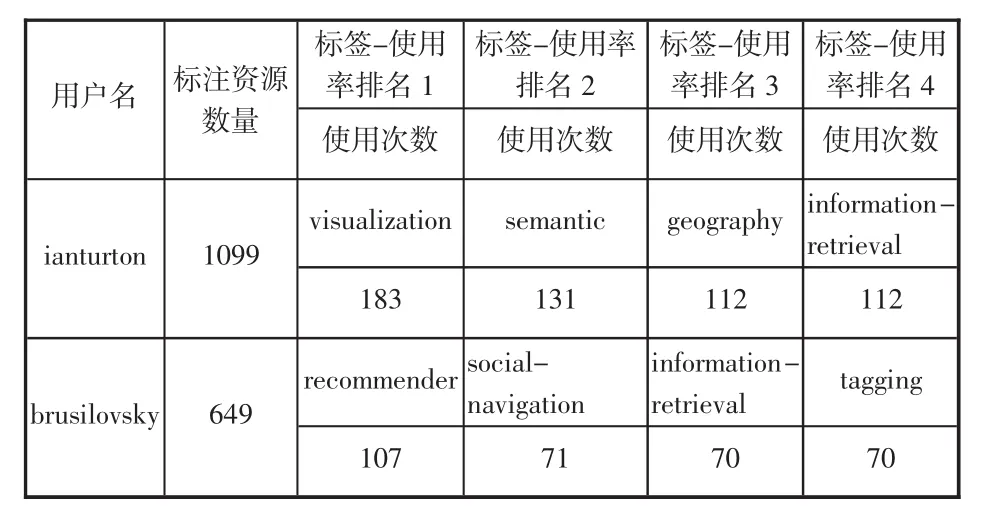
表2 用戶使用標簽情況
在標簽增長曲線中,線段的斜率代表標簽使用率的增長速度。線段在某段時間內向上的斜率越大,表示該標簽的使用率增長就越快;向下的斜率越大,表示該標簽的使用率減少越快,高位平行線段表示該標簽在這段時間內使用率較高,呈勻速增長,而低位平行線段則表示該標簽在這段時間內的使用率較低,用戶很少使用,甚至可能沒有使用。
通過圖2和圖3,筆者發現:
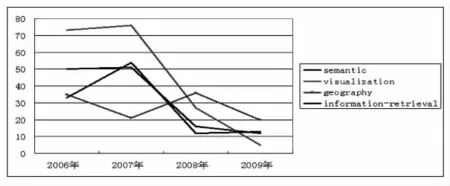
圖2 用戶ianturton的標簽變化情況
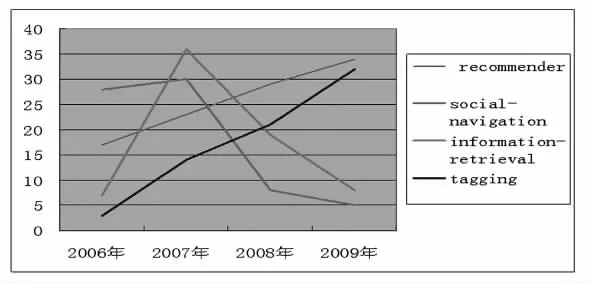
圖3 用戶brusilovsky的標簽變化情況
(1)在每個用戶的每個標簽增長曲線中都存在一個頂點,說明在這個時間點,用戶對標簽的使用達到一個高峰。如用戶brusilovsky在2007年對information-retrieval這個標簽的使用達到頂峰,說明2007年的某個時間點,brusilovsky非常關注這方面的資源,或許對之在進行集中研究。
(2)有些標簽在高位平行線段形成頂點后開始迅速向下,或形成低位平行線段,或繼續下降,說明用戶對標簽的關注率在下降。如visualization這個標簽,82%都是在2006年和2007年使用的,說明用戶ianturton在這個時期對可視化這個專題的資源非常感興趣,而2008年以后對之關注度明顯下降。
(3) 有些標簽長期保持持續增長態勢,如用戶brusilovsky的標簽recommender和tagging,說明用戶對標簽的關注率在持續提升。
這些現象表明,標簽的生命周期具有階段性,即用戶研究問題的視角可能是不斷轉移的。若從特定標簽的角度來看,則說明用戶對它的使用率可能是集中在某一個或幾個時間段內,在其余大部分時間內,用戶對該標簽所代表的問題關注度非常低,而對某些標簽來說,用戶對它們的關注則屬于一次性的短期行為。若選取相同時間段來觀察不同標簽的斜率,可以發現,增長趨勢越接近的標簽,其相關性也越高,如圖3中的標簽semantic和information-retrieval。該現象可以從一定程度上反映出這些標簽的共現頻率較高的事實,有助于人們判斷用戶研究熱點的變化情況。
3.4 標簽之間的關系分析
在社會化標簽系統中,標簽之間存在一定的隱性關系,挖掘標簽之間的聯系,有助于更好地理解標簽的語義和用戶行為。一般而言,共同標注某一資源的所有標簽都互為共現標簽,標簽被用戶使用標注同一資源的次數越多,其共現頻率越高,相關度也就越高。標簽的共現關系可以在一定程度上反映出標簽之間的語義關系,如同義關系、層次關系等。
3.4.1 標簽共現強度表達了標簽的相關度
筆者還是選取《TheStructureofCollaborativeTagging Systems》2007年1月至2009年6月的標簽使用情況,查重后共得到98個標簽,然后將所有標簽按照使用次數排序,因為標簽被共同標注的次數越多,其共現頻率越高,它們之間的關系越密切。為了統計準確,在統計過程中合并了標簽詞匯的單復數形式以及明顯的拼寫錯誤,如Folksonomy和folksonomies以及olksonomy(明顯拼寫錯誤),Tag和Tags、Tagx,collaborative-Tagging和ollabrative-Tagging(拼寫錯誤) 等等,用Excel表繪制圖4。圖4是上述資源指定標簽的頻度統計排名分布圖,橫坐標為標簽序號rank(按標簽使用頻率排序),縱坐標為標簽出現的頻次與序號的乘積—f*r。可以明顯看出,標簽的頻度統計排名分布基本符合齊夫定律:C=f*r(rank)
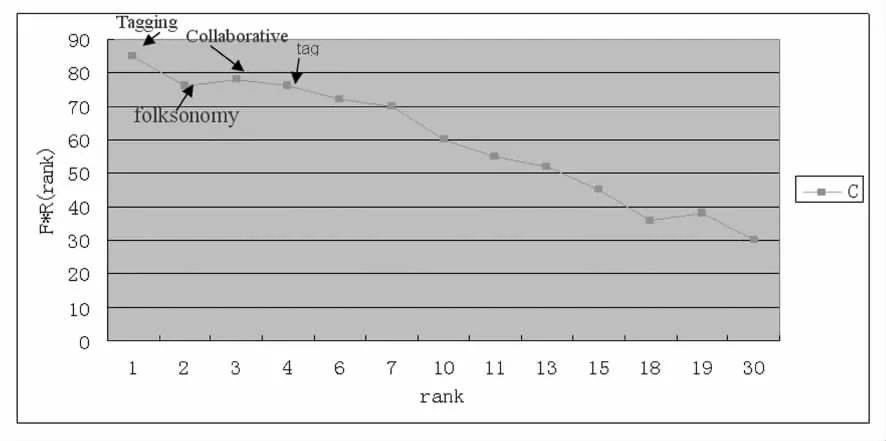
圖4 folksonomy同現標簽的頻度排名分布圖
圖4 顯示,在標簽出現頻次排名較高的部分,曲線相對平坦,即這幾個標簽的C常數(C=f*r(rank)基本相等,這主要是因為:語義相近或重疊的常用詞語(同義詞或近義詞)會在使用上存在競爭關系,或者說并列關系,如“tagging”“folksonomy”和“Tag”之間就存在這種關系。圖中標注了頻度最高的4個共現標簽,我們定義這4個標簽(認為這4個標簽能集中地反映該資源的特征) 為強共現標簽,[5]即這4個標簽共同出現的機會較高,詞義相關度極高。對于某個特定的標簽,其強共現標簽頻率分布顯示出了與該標簽聯系密切的“詞匯”。
3.4.2 共現標簽之間的層次關系
在標注此文獻的共現標簽中,可以發現以folksonomy為中心,共現標簽的關系呈幾種層級分布:
●從屬關系,上位類:knowledge,socialsoftware,classification,web2.0
●相關關系(同義詞關系):tagging,tag,collaborative-tagging,socialbookmarking,social-tagging
●并列關系,同位類:collaborative-filtering,collective_knowledge,semantic,ontology
通過分析特定的標簽,從詞匯關聯角度可以發現有意義的知識模式和語義關聯。
3.5 標簽的網絡聚類特性分析
聚類分析是一種無監督分類,目標是將資源劃分為有意義的簇(Cluster)或類,每個聚類簇中的資源之間具有較大的相似性,而聚類簇之間的資源具有較小的相似性。[6]通過聚類簇可以聚合同類資源和同類用戶,從而形成網絡上的社團結構。
自由分類得以實現,主要是采用社群成員共同建立的標準來進行分類體系的建構。成員提交的標簽可能千奇百怪,但系統很容易通過統計方法在這些關鍵詞中發現最適合的元數據。自由分類的分類標準是——“對于同一內容,采用使用頻率最高的一個或幾個關鍵字標簽來作為其分類元數據”。[7]
由圖4容易看出,tagging采用的關鍵字使用的頻率最多(85次),其他幾個共現標簽——Tag,folksonomy,collaborative也有較高的使用頻率,那么這幾個標簽可以作為這一資源的元數據標簽,tagging則可以作為這一資源的Folksonomy分類名稱。這是通過自發過程選出的滿足大多數人需要的分類標簽,這種分類方式與主流網絡信息分類體系相比,可以更好地聚合滿足用戶需求、符合用戶分類習慣的資源,并且能幫助用戶更好地理解信息分類,從而更快更準確地找到需要的信息。這種有別于學科聚類、主題聚類的方式可以稱為社群聚類,它是Folksonomy機制的核心部分。[8]這就進一步體現出Folksonomy是一種基于用戶提交關鍵字的分類,它反應的是整個社群的群體意識傾向和知識背景,具有不同成員結構的社群對同一網絡內容就可能形成不同的元數據標簽。本文所使用的數據集就是以Folksonomy為標簽聚合的資源,同時還將對自由分類法具有共同興趣的用戶也聚合在一起。這種聚類方式,可以凸顯出社群成員關心的熱點信息,形成一個特別適合本社群成員特點的信息分類體系。
4 結論
由上述分析我們發現:標簽是用戶在描述資源時自由選用的詞匯,在CiteUlike這樣的社會化書簽系統中,標簽的分布和用戶的標注行為是遵循冪律分布規律的,即少數用戶貢獻了大部分資源,少數標簽具有較高的使用頻率;當標注同類資源時,具有較高使用頻率的少數標簽成為強共現標簽,強共現標簽具有社群聚類功能,聚合了同類資源以及同類用戶。而Folksonomy正是通過同一標簽對不同資源和同一資源對不同標簽的聚合作用來不斷擴充主題(標簽)和資源間的動態聯系的,其作用主要表現在:
(1)從標簽角度聚合資源,可以揭示資源之間存在的內容相關性,反映通過標簽發現新資源的能力;還可以聚合使用該標簽的用戶,通過追蹤他們的標注行為,以類似滾雪球的方式找出許多相關文獻。
(2)CiteUlike這樣的社會化書簽系統可以從資源角度聚合用戶行為,即通過選定某資源,揭示標注過該資源的所有用戶及其采用的標簽,既可以反映不同用戶對同一資源的不同理解,幫助人們從不同角度加深對該資源的認識,又可以發現與之具有相同或相似興趣的人。
(3)同類標簽所標注的資源中被標注次數較高的資源和資源作者,相對這個領域可能較為重要,而且有可能以此發現某一學科新的研究熱點。
(4)CiteUlike可以按用戶來聚合資源,瀏覽某一用戶所有的標引活動,從該用戶對標簽的使用規律能夠分析其研究熱點的變化。
(5)CiteUlike這樣的社會化書簽系統可以通過計算,推薦資源的強共現標簽作為用戶標注資源時的參考,以便于按標簽聚合資源,同時,用戶可以從中學習其它收錄者是用何種標簽描述文獻的,為用戶的標注行為和瀏覽行為提供方便和效率。
(6)可以通過研究某一標簽的共現標簽,深化對用戶對資源的理解。
由此可得出結論:Folksonomy這種分類形式在網絡資源組織和用戶行為研究上都具有獨特的優勢。
[1]學術網絡書簽工具——CiteULike介紹[EB/OL].[2009-06-20].http://www.xxc.idv.tw/blog/xxc/webtryit/academic_social_1.html.
[2]個性化站點:CiteULike.org[EB/OL].[2007-06-20].http://www.guwendong.cn/post/2007/site_citeulike_org.html.
[3]CiteULike[EB/OL].[2009-06-30].http://www.citeulike.org/.
[4]Margaret E I Kipp.TaggingPractices on Research Oriented Social BookmarkingSites[EB/OL].[2009-03-20]http://www.cais-acsi.ca/proceedings/2007/kipp_2007.pdf.
[5]王萍.基于自由分類法的elearning標簽研究[J].中國遠程教育,2008(10):65-70.
[6]王萍.基于自由分類法的e-Learning共現標簽網絡分析[J].中國電化教育,2008(1):99-104.
[7]ACapocci,GCaldarelli.Folksonomies and clustering inthecollaborativesystemCiteULike[EB/OL].[2009-03-31].http://arxiv.org/PS_cache/arxiv/pdf/0710/0710.2835v2.pdf.
[8]周榮庭,鄭彬.分眾分類:網絡時代的新型信息分類法[J].現代圖書情報技術,2006(3):72-75.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
