數據挖掘技術在保險客戶理賠分析中的應用
2010-05-22 08:06:26李迪安謝邦昌
統計與決策 2010年4期
陳 希 ,李迪安 ,高 星 ,陳 帥 ,謝邦昌
(1.廈門大學 經濟學院,福建 廈門 361005;2臺灣輔仁大學 統計資訊學系,臺北)
0 引言
隨著人們收入水平的提高和消費意識的改變,保險產品日益增多,公眾對購買保險的熱情越來越高,保險行業也隨之迅速發展。與此同時,決策者在獲取利益時應注意到行業存在的巨大風險。保險業與其他行業相比,最大的差異在于它是以多樣化的風險為經營對象的特殊服務業。不同的客戶有著完全不同的需求,也為保險公司提供不同的收益率。在保險業,通常根據客戶價值、客戶貢獻、客戶理賠風險、保險市場、保險產品等進行細分。本文掌握的是保險公司的客戶資料,主要針對客戶的理賠索取這類保險業面臨的主要風險進行闡述。另外,高風險客戶的索賠直接造成保險公司的理賠支出,而理賠是關乎保險公司盈利的重要事宜。
在保險行業過去的客戶理賠的研究中,少有涉及數據挖掘的領域,多半利用傳統統計方法或是單純的專業分析,這些方法雖然能夠發現“發生理賠”的一些表面特征,如重復投保、高額投保、頻繁投保等,但可能都忽略了海量數據中隱含、尚未被挖掘出的寶貴信息,而數據挖掘為另一種從不同角度切入的新方法。保險公司可以利用數據庫中多年來收集起來卻沒有實際運用到的寶貴數據,通過數據挖掘的技術,了解所擁有的客戶的特征,以及其中具有何種特征的客戶存在著高風險。根據數據挖掘的結果,也可以更清楚知道未來目標的客戶群在哪里,針對目標客戶群推行保險理賠產品進而獲得更大的效益。
本文利用數據挖掘技術對客戶理賠概率進行預測,按理賠概率高低將客戶分成若干等級,從而有針對性地對理賠概率高的客戶增加保險金額度或提高保險費率,或者將這部分客戶群作為非重點營銷對象,達到了運用“針對不同理賠風險等級的保戶銷售有差異的保險產品”的營銷戰略,從而最大程度地分散非系統性風險同時降低公司保險投資風險,避免經濟損失。
1 研究目的及數據挖掘流程
本文借助數據挖掘分類算法,對高風險保戶的理賠風險建立一個科學的分析與預測模型,在模型基礎上設定未來客戶“是否發生理賠”的最適分割點,幫助決策者做出適當的營銷策略。
按照CRISP-DM(跨行業數據挖掘方法論)的標準,數據挖掘在保險業中的應用可以劃分為以下六個步驟:商業理解、數據理解、數據準備、建立模型、模型評估與模型發布。第一,商業理解:明確挖掘目標,即找出高風險理賠客戶特征,指導公司進行營銷決策;第二,數據理解:本文使用的數據來自中國臺灣某著名保險公司,數據集共29個變量,變量類型有類別型、布爾型和順序類別型,不同類型的變量對應于所要解決的不同問題;第三,數據準備:一方面對龐大而復雜的數據進行預處理,剔除缺失數據,并區分目標變量與解釋變量,另一方面從描述統計角度篩選出高風險客戶數據集;第四,建立模型:針對不同的數據挖掘目標和數據特性,采用不同的挖掘算法建立模型;第五,模型評估:對產生的模型結果需要進行比對驗證、準確度驗證、支持度驗證等檢驗以確定模型的價值,文中除了用增益圖和分類矩陣進行評估之外,還利用驗證集考查模型的泛化能力;第六,模型發布:只有把模型發布到決策者手中,才能真正通過數據挖掘降低保險公司發生理賠業務的概率與成本。
2 高風險保戶理賠概率建模分析
2.1 數據準備
本研究使用的數據來自中國臺灣某著名保險公司自1981年至2002年間投保傷害險和健康險的客戶資料。該資料共包含65535個客戶樣本,共29個字段(依次編號為Q1至Q29):客戶基本信息(Q1~Q6)、投保數據基本資料(Q7~Q24)和理賠信息(Q25~Q29)三個資料組。
(1)數據預處理。①屬性概化。將存在缺失值以及可用其他同類屬性來代替它的較高層概念的那些屬性刪除。比如:保額與保額組別、繳費年期指示與繳費年期、投保年齡與年齡組別、已繳保費與已繳保費組別等含義重復,僅保留“組別”字段;而理賠總金額可以通過理賠件次和理賠金組別進行推斷,故刪之。②相關分析。一方面要減少輸入變量之間的冗余度,保證計算的效率和輸出的簡捷;另一方面,與輸出變量無關的輸入可能會延誤甚至誤導挖掘進程,因此要保證輸入變量與輸出變量(有無理賠)之間有一定的相關度。此外有些屬性可以根據邏輯上直觀的判斷決定取舍。在相關分析基礎上,又把理陪件次、投保件次、理賠金組別等字段刪去。預處理后變量的詳細說明見表1。
(2)數據準備。本分析主要關注高風險客戶是否會發生理賠。在65535條客戶記錄中,無理賠客戶占96.77%,有理賠客戶只占3.23%。因此,首先需要界定“高理賠風險客戶群”:將17個解釋變量與因變量(有無理賠)做交叉頻數分析,通過各個解釋變量對理賠情況的發生概率找出對有無理賠分布產生重要影響的因素,界定出一個特殊的客戶群體。經分析,把具有表2中屬性特征的保戶界定為高理賠風險保戶。
依據以上的特征,把具有以上特征的保戶從總體中分離出來,共有19335個保戶,該人群中受理賠的比例為10.96%,遠高于總體比例受理賠3.23%。因為所有的理賠記錄都發生在這一人群中,其所具有的理賠風險是遠高于其它保戶的,因此對高理賠風險保戶群體是否會發生理賠進行建模將更有現實意義。

表1 變量預處理及其編號

表2 高理賠風險保戶具有的屬性特征
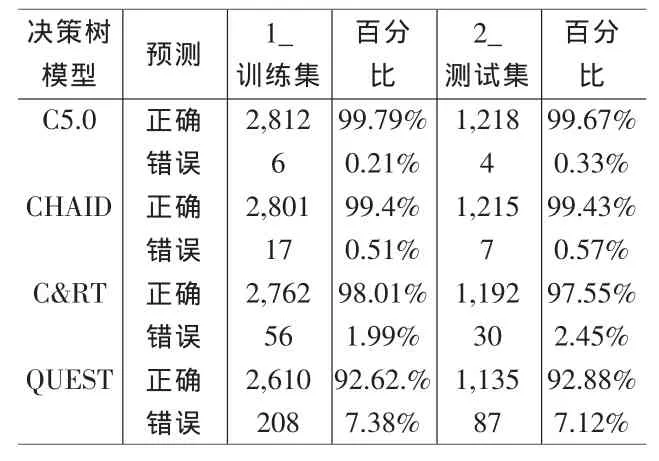
表3 四種決策樹算法在兩類數據集上的預測準確率
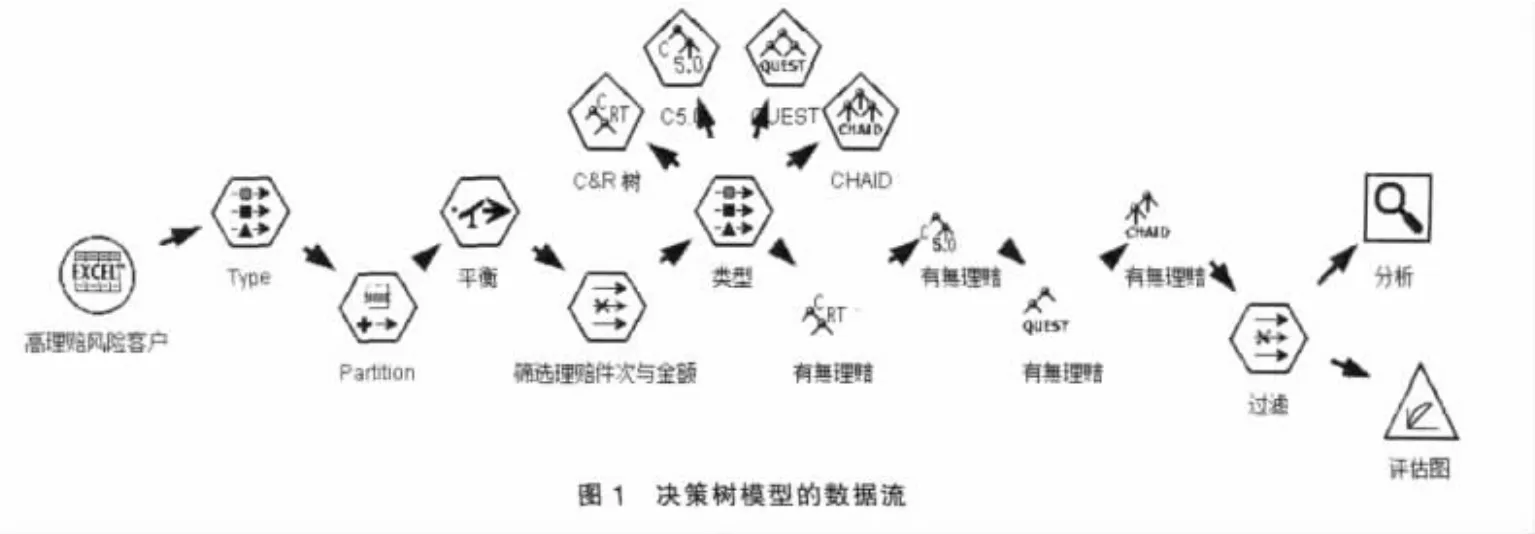
2.2 高理賠風險保戶建模分析
在分離出的高理賠風險客戶群中,無理賠客戶的占比仍高達89.04%。由于分類算法對存在有偏數據的處理效果是相當不理想的,因此在進行決策樹挖掘算法前,應對高理賠風險客戶數據再次預處理,使得有無理賠客戶分布基本平衡。在SPSS-Clementine軟件中,通過設置平衡節點,就能使數據分布均衡。經處理,無理賠客戶占比46.77%,有理賠客戶占比53.23%,代價是樣本量的下降。在此基礎上,使用分類算法對高理賠風險客戶做深入挖掘。
2.2.1 決策樹模型。Clementine12.0提供四種決策樹算法:C5.0、CHAID、C&RT和Quest。利用Type節點設置輸出輸入變量,再通過Partition節點將數據集分成70%測試集和30%訓練集,使用訓練集建立分類模型,再將模型運用于測試集,利用混淆矩陣度量模型的性能。決策樹模型的數據流如圖1所示。
對四種算法分別建立起模型之后,再透過Analysis節點可以得到表3所示,關于四種算法在兩類數據集中的預測準確率。分析得出C5.0模型在兩大數據集的預測效果是最好的,再取C5.0模型結果來分析高風險理賠保戶共有的一些個人信息特征。
(1)分類規則。表4是由C5.0模型使用推進方法產生“有理賠”結果的部分規則集,各規則集的估計精確度在88%以上。由規則集,可歸納出“發生理賠”的客戶主要具有以下特征:已婚,女性,老年人居多,職業類別為0,主要集中在臺北、新竹及臺中地區,以月繳或年繳方式,投保月份主要是下半年。
(2)樹模型。對C5.0模型使用推進方法得到的樹模型如圖2所示,每個節點位置顯示的直方圖為在該節點中的觀測值在因變量(有無理賠)上的取值分布情況,在非末端的節點方框下方的變量名,表示其子節點的劃分變量,而具體取值則在其子節點上方均有標示。

表4 產生有理賠結果的規則條件(僅取其中4條)

在C5.0決策樹上,第二層右側的節點29有理賠很少,僅有53例,所占比例不到測試集中理賠總數的0.04%。這些客戶的保單狀況為停繳,契約撤銷,解約-保戶主動和注銷-公司主動。事實上,當契約取消、解約或注銷都看成保戶與保險公司的合同中止,因而保險公司也就沒有了理賠義務,故對這部分的保戶可基本忽略。而相應左側的節點1下的子樹很大,覆蓋了大量的有理賠客戶信息。由于分析有理賠客戶的相關信息是本研究的主要目的,因此,我們特別關注有理賠多的節點。從圖中可以清晰看到,已婚的客戶群(節點8)的樣本數最多,有1518個,占53.735%,同時也是發生有理賠事件最多的一類,因此有必要進一步考察該節點。模型以投保月份為是劃分變量對節點8進行分類,雖然各個月份下都有一定的理賠事件發生,但第四層右側的節點16(即投保月份在7月份后)所含的有理賠保戶比左邊的多700多個,且主要集中在新竹和臺中兩個地區;模型將新竹地區的597個有理賠保戶歸為月繳投保一類。同時,臺北地區也有16個理賠的,主要是老年人。跟蹤節點9(投保月份在上半年)到葉節點14這條子鏈可以發現,節點9中204個有理賠保戶被完全分到節點14,其客戶特征為:正常繳費,已婚,4月投保且購買的是健康險。此外,對于最左側的節點4,有理賠客戶僅為217個,也產生了相應的分類規則,即正常繳費,職業類別為0,女性。
綜合分析C5.0模型產生的分類規則及樹模型,發現影響“有無理賠”的主要解釋變量是:婚姻狀況,職業類別,性別,投保月份,保險形態1,地區別,年齡組別,繳別。此外,在以投保月份為屬性進行分類時,下半年投保的有理賠客戶要明顯比上半年的多,為后面模型處理方便,可考慮將投保月份分為上半年和下半年。
2.2.2 支持向量機、貝葉斯網絡以及logistic回歸。首先,在C5.0模型對輸入變量進行屬性約減的基礎上,即在接下去的分類算法模型建立過程中,只將約減后的八個重要變量作為輸入,以有無理賠作為因變量,訓練出新的分類模型,從而得到相應的高風險保戶的理賠概率預測模型;最后根據各個分類預測結果的準確性評估模型。整個建模數據流如圖3所示。
模型建立完畢,此時要估計不同性能的模型,以便選出最好的模型。評估模型優劣的準則有:整體精確性、ROC曲線下方面積、利潤、提升等指標。在此,選用“整體精確性”作為評估模型的準則;由表5和表6判斷出,支持向量機模型優于其他兩個模型。所以選擇支持向量機模型作為最終模型。
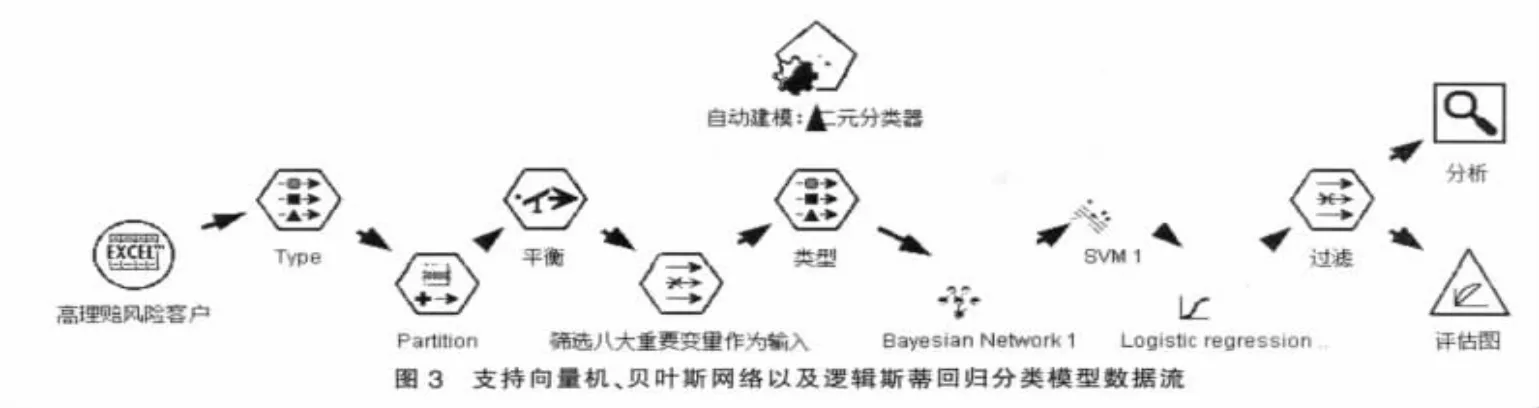

表5 三種分類模型的評估準則得分

表6 分類矩陣表
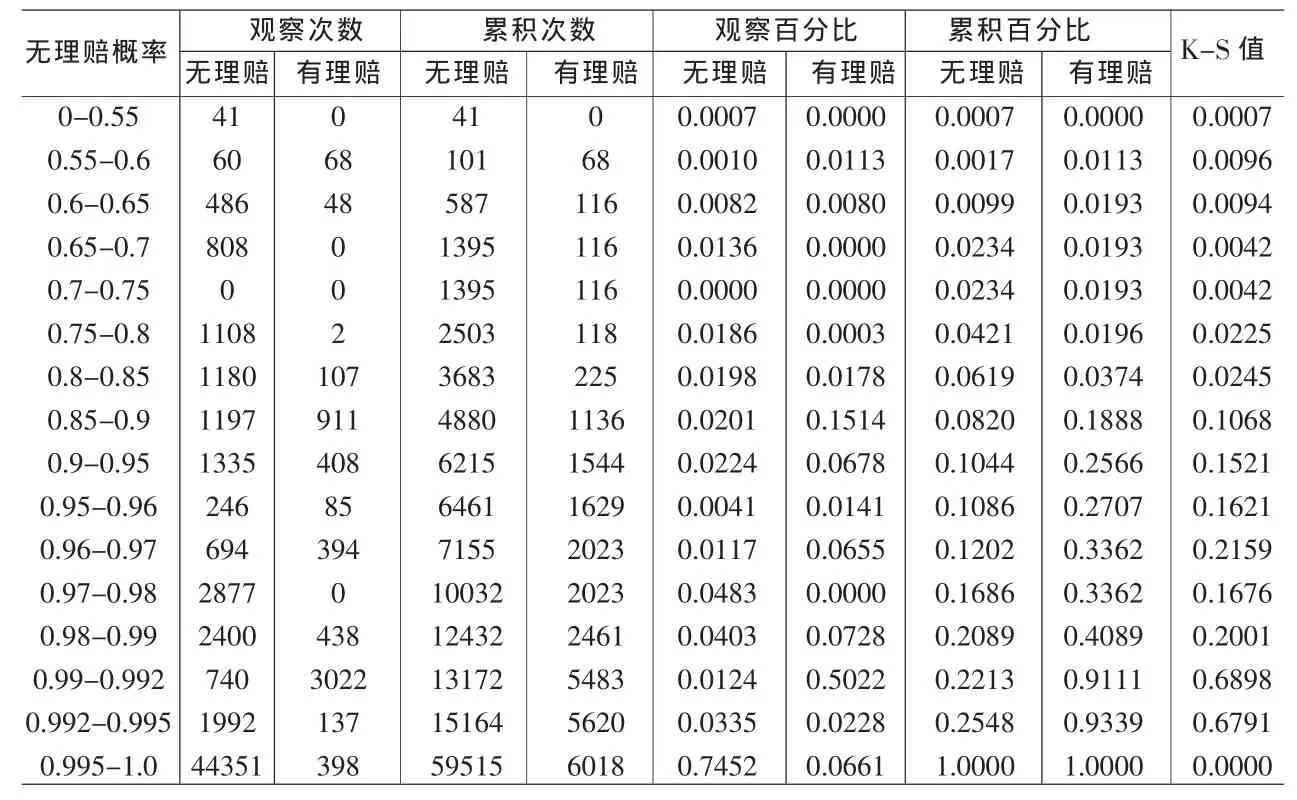
表7 無理賠概率分布表
2.3 模型實施
根據上述模型評價結果,選擇SVM模型來構建“全體高風險保戶”發生理賠概率的評分模型。先將全體高風險保戶帶入訓練得到的SVM模型中,估計出每一個樣本不發生理賠的概率。保險公司可以根據自身所能承擔的風險狀況,來決定適當的概率分割點,作為保險客戶是否發生理賠的一個預測標準,若新客戶不發生理賠的SVM模型預測值高于該分割點,則認為此保戶將不會要求理賠,此時可按照已制定的保險金額度接受其投保申請;反之若低于該分割點,則應該對其提高保險金額度或者保費率。如果保險公司想以客觀的統計方法來確定分割點,則可以通過計算最大的K-S值來獲得SVM模型的最適分割點。
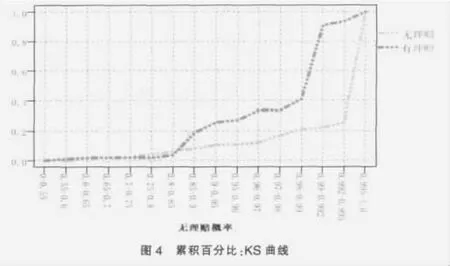
定義“K-S值”:各分數下對應的累計“壞”客戶百分比與累計“好”客戶百分比之差的最大值。在數據挖掘中或信用評分中,K-S值越大,表示評分模型能夠越理想地區分 “好”、“壞”客戶。另外,該評分模型還能繪制出K-S曲線:將所有申請者的信用評分由小到大排列,分別計算每一個分數之下“好”、“壞”客戶累計所占的百分比,再將這兩種累計百分比與評分做在同一張圖形上,得到K-S曲線。
針對高風險客戶發生理賠的概率預測模型,K-S值是由SVM模型估計得到全體樣本的無理賠概率值后,發生理賠的累積百分比減去無理賠的累積百分比所得到的絕對值,計算公式:K-S=sup|Fr-Fn|。K-S 值越大,表示“無理賠”與“有理賠”的累積百分比在該分割點或區間的差異越大,該分割點或區間就越能有效地分辨出高風險保戶發生理賠概率的高低,故可用來決定最適分割點,以判斷無理賠的概率要大于多少時才能被保險公司視為不發生理賠的高風險保戶。計算結果如表7、圖4所示。
模型建立后,需要對模型的預測能力、穩定性進行檢驗后才能運用到實際業務中去。國際上用K-S指標來衡量驗證結果是否優于期望值,具體標準是,如果模型的K-S值達到30%,則該模型是有效的,若K-S值超過30%,則模型區分度越高。
由表4可以發現,SVM模型的K-S值達到68.98%,說明SVM模型具有較好的預測功能,發展的模型具有成功的應用價值。同時,KS達到最大值36.84%的無理賠概率區間為0.99~0.992,因此本研究設定0.99為高風險保戶是否發生理賠模型的最適分割點,即無理賠概率大于0.99的客戶風險相對較低,保險公司可按照已有的保費標準接受其投保申請。
3 結論
本文利用分類算法對臺灣某保險公司的健康險和傷害險保戶進行了高風險理賠特征發掘和高風險保戶識別,幫助保險公司控制和分散理賠風險,同時為它們針對不同風險等級的保戶銷售相應的保險產品和制定差別保險費率提供依據。綜合全文,我們得出如下結論:
(1)從保戶的個人基本信息來看,婚姻狀況、年齡和性別是區分保戶理賠風險高低的關鍵因素。綜合本文各種模型的實證結果,對于保戶具有“已婚,女性,未滿14歲和老人”特征的當屬高風險理賠人群。因此,對于這部分群體,保險公司應該給予特別關注,并可以適當提高保險費率以分散非系統性風險。
(2)從投保相關信息來看,地域分布、保險形態(或險種)和繳費方式成為劃分保戶風險等級的重要變量。其中,臺北、新竹和臺中是理賠事件的高發地區;健康險業務的開展將使保險公司承擔較之傷害險更大的理賠風險;按月繳納保險費的繳費方式同樣也是高風險理賠客戶具有的典型特征之一。
(3)依據SVM模型實施的結果,無理賠概率0.99是高風險保戶是否發生理賠的最佳分割點處的概率值,即:無理賠概率大于0.99的保戶將被視為 “基本無理賠風險保戶”或“基本不發生理賠保戶”,保險公司可按照一般標準的保費額度或保險費率接受該類客戶的投保申請。對于無理賠概率小于0.99的保戶,保險公司應該“按級”銷售差異產品,即越遠離最佳分割點概率值的保戶,其理賠額度越低,理賠資格審查越嚴格,保費額度越大,保險費率越高。
[1]田今朝,戴穩勝,謝邦昌.保險業的數據挖掘應用[J].中國統計,2005,(02).
[2]王星,謝邦昌,戴穩勝.數據挖掘在保險業中的應用[J].北京統計,2004,(04).
[3]畢建欣.數據挖掘技術在保險領域中的應用[J].華南金融電腦,2004,(08).
[4]吉根林,孫志揮.基于數據挖掘技術的保險業務風險分析[J].計算機工程,2002,(2).
[5]田金蘭.用決策樹方法挖掘保險業務數據中的投資風險分析[J].小型微型計算機系統2000,(10).
[6]鮑觀健.臺灣保險業發展之研究[D].廣州:暨南大學,2003.
[7]李玉泉.大陸保險市場開放對臺灣保險業的機遇與挑戰[J].中國保險,2005,(3).
[8]Jiawei Han,Micheline Kamber.數據挖掘概念與技術[M].北京:機械工業出版社,2001.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
核科學與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
