應用數據挖掘技術識別財務報表舞弊的方法研究
2010-04-26 07:20:38周芳
財務與金融 2010年3期
周 芳
財務報表舞弊是利用虛假財務信息誤導投資者等報表使用者做出錯誤的決策,所以財務報表舞弊不僅損害了投資者以及債權人等報表使用者的利益,而且對資本市場的健康發展,資源的有效配置,經濟的良好運行都有很大的危害。財務報表舞弊主要是針對財務報表信息進行的舞弊,典型的舞弊手段涉及虛構收入、提前確認收入、利用混淆資本性支出和收益性支出調節成本費用、利用會計政策和會計估計變更調節利潤、隱藏負債、利用資產減值、關聯方交易、資產重組等手段對會計信息進行粉飾。
一、傳統識別財務報表舞弊的方法
對財務報表進行審計,并“合理保證”財務報表在總體上不存在重大錯報是注冊會計師的主要職責,那么如何識別被審計單位財務報表是否存在舞弊是考驗注冊會計師審計技術的關鍵。《中國注冊會計師審計準則1141號——財務報表審計中對舞弊的考慮》中強調利用分析性復核、詢問、考慮是否存在舞弊風險因素、職業懷疑態度和項目組內部討論等風險評估程序識別舞弊導致的重大錯報風險。
(一)利用財務數據分析識別舞弊
在審計實踐中注冊會計師為了能夠更有效的識別虛假財務報表,通常使用一些暗示可能存在舞弊的“紅旗標志”或預警指標,這些指標大多圍繞財務數據計算得出,例如毛利率、應收賬款周轉率、存貨周轉率、資產負債率、流動比率、凈資產收益率等指標,計算觀察這些指標的異常發展趨勢(縱向比較和橫向比較)可以幫助注冊會計師識別可能存在的財務報表舞弊。
另外,其他財務預警信號也可能會暗示存在財務報表舞弊,例如公司進行的大量的(或大額的)非常規交易,例如股權轉讓、受讓、債務重組、非貨幣交易等資產重組活動;公司為復雜的交易采用較為激進的會計政策和方法,例如利用衍生金融工具進行的交易、融資租賃業務等;公司期末發生較多的會計政策變更、會計估計變更、會計差錯更正;公司關聯交易很多;管理層拋售自身企業的股票;審計報告屬于非標意見報告;更換注冊會計師;股價異常波動;信息披露不及時;盈利有別于同行業其他企業,趨勢相反或增長過快等。
公司所處的行業狀況、法律和監管環境存在的預警信號可能表明公司面臨舞弊的壓力或機會。公司治理和內部控制的相關評價信息也可以幫助注冊會計師有效識別被審計單位是否存在財務報表舞弊的機會,例如股權結構、董事會、審計委員會、獨立董事等方面是否存在功能性缺陷導致管理層或者是大股東操縱財務報表數據以達到操縱股價或盈余的目的。
以上這些財務報表舞弊識別的技巧和方法的運用效果在很大程度上離不開注冊會計師個體的從業經驗和判斷技能,缺少系統性、科學性。而且最大的問題是,被審計單位財務報表舞弊發生并不一定伴隨著上述所有指標或信息的異常變化,有些指標或信息不發生變化,指標或信息之間甚至可能發生相反的變化,那么就很難判斷財務報表是否存在舞弊,缺少系統的模型或工具作為輔助手段幫助注冊會計師進行科學、系統、全面的專業判斷。為了克服已有識別方法和技巧的局限性,提高判斷的準確性和效率,很多學者利用數據挖掘技術來識別財務報表舞弊。
根據Usama M.Fayyad給出的定義:數據挖掘是從大量的數據中挖掘出隱含的、未知的、用戶可能感興趣的和對決策有潛在價值的知識和規則。數據挖掘技術可粗分為:統計方法、人工神經網絡方法、決策樹方法、基于范例的推理方法、遺傳算法、粗集方法、模糊集合方法等。統計方法可細分為:回歸分析、判別分析、聚類分析、主成分分析等。人工神經網絡方法可細分為:前向神經網絡(BP算法、徑向基函數網絡等)、自組織神經網絡、反饋式網絡等。
二、利用統計學技術識別財務報表舞弊的方法
這種方法是當前應用最多的識別財務報表舞弊的數據挖掘技術。
(一)方法描述
1、單因素方差分析法
該種方法先考察舞弊公司和控制樣本公司(正常的非舞弊公司,以下同)兩個樣本組的11個指標的欺詐期間與欺詐前一年的差額,并進行正負號的調整后,對于舞弊公司來說使之變動方向一致,然后將各樣本指標值轉化為(0,1)二元變量,即將指標數值>0的賦為1,數值≤0的賦為0,其次將各樣本公司在指標系列中出現的正值進行加總,計為變量n,對該變量在兩個樣本組間的分布差異進行方差分析,結果顯示舞弊組公司再考察的指標系列中出現正值的次數在統計上顯著大于正常組公司,在總體誤判個數最低的前提下,然后選擇一個I型錯判個數較小(即將會計舞弊公司誤判為正常公司的次數)的n值作為識別財務報表舞弊的一個依據,大于該n值,判斷為舞弊,反之為正常。總體準確率為86%,I型錯判率為20%,Ⅱ型(即將正常舞弊公司誤判為會計舞弊公司的次數)錯判率7%。
2、多元判別分析法(Multivariate Discriminant Analysis:MDA)
該方法通過若干指標建立多元線性回歸模型,通過舞弊組公司和正常組公司的相關數據回歸得出相關系數的估計值,根據兩樣本組同類均值處的線性判別函數值的不同,找出判別點,如果一家公司相關指標數據代入判別模型,判別得分高于判別點的說明存在財務報表舞弊嫌疑,小于判別點則說明這家公司不存在財務報表舞弊的行為。總體準確率為70.1%,I型錯判率為33.3%,Ⅱ型錯判率26.5%。
3、離散選擇模型(Discrete Choice Models:DCM)
(1)雙值因變量的線性概率模型 (Linear Probability Models:LPM)
LMP是普通線性回歸的一種變形,其因變量Y是0-1型變量。假設Yi=1的概率(即公司違約的概率)為Pi,則Yi=0的概率(即公司不違約的概率)為1-Pi,于是我們可以把線性概率模型寫成以下形式:
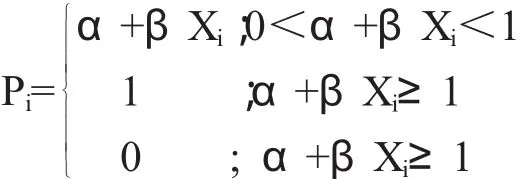
該模型同樣也要選擇一個判別點,如果一家公司的相關數據代入模型得到的數值大于判別點的說明有財務報表舞弊的嫌疑,否則判定為正常公司。線性概率模型的最大優點就是直觀易懂,βj度量了在保持其他因素不變的情況下,因素χj的變化導致舞弊概率變化的幅度,βj的絕對值越大,說明因素χj在眾多影響公司違約的因素中所起的作用就越大。回判準確率在75.82%,預測準確率在66.67%。
(2)二元Logit回歸模型
該模型是現有文獻中使用頻率最高的判別模型。財務報告舞弊的識別模型表示如下:
P=eY/(1+eY)
Y=α0+α1X1+α2X2+…+αnXn+ε
如果一家公司的財務數據代入該模型得出的P大于0.5說明該公司被判別為舞弊公司,小于0.5則被判為正常公司。
(3)二元Probit回歸模型
Beneish(1999)以1987-1993年間受美國證監會處罰的74家公司為會計舞弊樣本,選用8個財務指標,建立Probit回歸預測模型,該模型準確率達到75%。同時也指出了該模型的缺陷:財務數據的歪曲必須是產生于盈余管理而非其他因素;該模型只能鑒別增加收益的盈余管理,對于減少收益的行為則無能為力。
4、貝葉斯判別法
此外,李延喜等(2007)運用貝葉斯判別分析進行橫向對比與分類判別,通過構建利潤操縱和無利潤操縱兩類分類識別模型,如果一個公司的被選指標計算后Y利潤操縱〉Y無利潤操縱,則判定該公司具有利潤操縱行為,否則為無利潤操縱行為。模型的回代法的正確率在71.4%,交互驗證法的正確率為68.6%。
5、系統聚類分析法
系統聚類法先將數據標準化變換后,先各自成一類,然后每次將最相似的兩類合并,合并后重新計算新類與其他類的歐式距離,一直到持續到所有對象歸為一類為止。
(二)統計學分析方法識別舞弊方法的述評
利用統計方法識別舞弊公司的判別率相差較大,主要原因就是選擇的模型不同,每一種模型都有各自的條件要求,如果忽略了模型內在的假設條件,那么回歸的結果就會出現偏差。
多元判別分析法的因變量和自變量都是隨機變量,誤差項必須符合最小二乘法的嚴格假設條件,而現實中的樣本數據往往并不能滿足這一要求,這就大大限制了多元線形判別模型的使用范圍。應用時,若沒有符合這些假設條件,得到的估計值就不可能是無偏的、有效的。當然,也有許多研究在大樣本的情況下,近似的使用多元線形判別模型。
LMP缺點主要體現在以下幾個方面:第一,模型明顯存在異方差的問題,第二,在 只有兩種取值(0和1)的情況下,隨機擾動項μ已不再服從正態分布,這兩點違背了高斯-馬爾科夫定理,使得我們無法對模型進行最小二乘法的估計和檢驗。當然,在大樣本的情況下采用加權最小二乘估計法可以在一定程度上克服上述的兩個缺陷;最后,簡單的回歸估計所得出來的概率值可能會落到0~1區域之外,這大大降低了LPM模型的解釋能力。而且對因變量的概率服從何種分布并不知道的情況下,也不能使用最大似然法來估計參數。
二元Logit回歸模型較好地克服了LPM模型的缺陷,該模型已知因變量(0-1型變量)的概率分布服從邏輯分布,這樣就可以使用最大似然法來做回歸估計。LPM的斜率是固定不變的,而二元Logit模型的斜率則是可變的。二元Probit回歸模型與二元Logit回歸模型差別不大,不同之處在于該模型是在二元因變量服從正態分布的條件下使用最大似然估計法進行參數估計,因而多數學者選擇采用二元Logit回歸模型。
方軍雄(2003)比較了LPM和二元Logit回歸模型,得出二元Logit回歸模型比LPM優越。毛道維、朱敏(2006)比較了單因素方差分析、多元判別分析、線性概率模型和二元Logit回歸模型識別舞弊的效果,得出二元Logit回歸模型較優。
雖然同樣使用二元Logit回歸方程來識別舞弊,但是總體準確率差別較大。方軍雄(2003)使用該模型的回判準確率在64.84%,預測準確率在72.22%。陳國欣等(2007)使用Logit模型的總體準確率在95.1%。毛道維、朱敏(2006)使用該模型的總體準確率在77.9%。陳收等(2007)使用該模型的回判準確率在80.9%,預測準確率在68.25%。婁權(2003)使用該模型的總體準確率在83.3%。分析其主要原因有:第一,主要是由于指標的選取僅限于財務指標,如果考慮一些非財務指標如公司治理結構特征、管理當局特征等,會提高模型的有效性。第二,由于我國資本市場成立較晚,所以樣本數量不大。所以對一些需要大樣本條件下的模型如果使用小規模樣本的估計效果就不會理想。第三,雖然logit回歸模型是具有二分性質的概率模型,其前提比較寬松,但是使用該模型進行預測時,仍要處理選取指標的多重共線性問題。一般使用多元統計分析中的因子分析法(主成分分析法)或先前或向后逐步回歸法來解決這個問題。總體準確率較高的模型在運用時都對指標的多重共線性問題進行了適當的處理。趙英林、陳素華(2007)采用因子分析法與Logit回歸分析相結合的方法,總的正確率為79.7%。梅國平等(2006)利用主成分分析的統計方法建立多元判別模型識別舞弊的準確率達到95%。
統計方法大部分都是線形模型,因為舞弊的路徑可能是非線性的,因而削弱了線性模型預測結果的準確程度。為了克服線性模型的固有局限,近幾年又發展出神經網絡識別模型、粗糙集等非線性的數據挖掘技術來識別舞弊,總體識別效果較理想。
三、利用神經網絡混合模型識別財務報表舞弊的方法
Green and Choi(1997)利用神經網絡模型對財務欺詐進行聚類分析。通過使用三種不同的期望方法構建的模型分別為:單一百分比變化神經網絡(SPCNN);普通年數總和平均權重神經網絡(PSYDNN);增量年數總和平均權重神經網絡(ISYDNN)。第二種在混合樣本中得到了最高的正確率。蔡志岳、吳世農(2006)將BP神經網絡與遺傳算法相結合,利用混合BP神經網絡來識別舞弊。BP神經網絡不需要確認自變量與因變量之間的關系是線性的還是非線性的,對變量的分布或彼此之間是否高度相關也無任何要求。而且混合BP神經網絡模型的總體預測正確率和回判正確率都高于二元Logit回歸模型。梁杰等(2006)利用模糊邏輯與神經網絡相結合識別舞弊。劉君,王理平(2006)基于徑向基概率神經網絡模型來識別財務舞弊,其模型綜合了徑向基函數神經網絡和概率神經網絡的優點,得出的模型總體預測正確率86.7%,回判正確率更高。Fanning等(1998)運用Logit回歸、直線判別、二次判別、神經網絡四種方法,結果表明神經網絡模型比其它方法更具預測能力。Lin等(2003)根據會計收益指標和會計收益趨勢構建了基于模糊神經網絡(FNN)的財務舞弊判別模型,FNN模型融合了模糊回歸(Fuzzy logic)、神經網絡(Networks)及其他的方法來模擬人類理性中的不確定性,以提高模型的評價能力。實證結果表明模型可以有效減少審計師的偏見或彌補審計師的不足。
譙虹、賀昌政(2007)利用 GMDH(Group Method of Data Handling,數據分組處理方法)技術,通過計算機篩選出能顯著反映虛假財務報告的關鍵異動指標來識別上市公司虛假財務報告。GMDH是自組織數據挖掘的核心技術,這種方法最大的優點是它能夠避開人為干擾因素,自動從海量的數據信息中挖掘出重要影響因素,歸納性推理,經過計算機自動生成模型。同時,它能自動地將建模的數據分成訓練集、監測集和預測集,從而使得模型具有良好的推廣能力。GMDH技術適應樣本量小,有噪聲的數據,比較適合我國資本市場的情況,并且GMDH方法可以不必顧慮在計量經濟分析模型中變量之間的多重共線性問題,也不用對樣本數據變量正態分布檢驗以及其他處理。GMDH可以同時建立線性和非線性兩種模型,兩個模型的擬合能力分別在82%和84%,模型的預測和推廣能力達到100%。并且,非線性模型擬合能力和推廣能力更強,單獨對于造假公司總體判別率正確率比線性模型高,達到93.33%。而線性模型可以清楚地看到各個主要指標和判別結果的正負相關關系,對于篩選出正常公司能力較高,可以達到90%。
首先,神經網絡一個固有弱點是它的內部結構好像一個“黑箱”,連接權重通常沒有明顯的解釋,也無法量化,導致神經網絡缺乏解釋能力,而且不像計量經濟模型,神經網絡模型既不能確定結果的精確度,也不能確定結果的統計可信性。其次,神經網絡的結構絕大部分來自反復驗證,但是如果“訓練過度”,這種模型對訓練集會有很高的準確率,而一旦離開訓練集應用到其他數據,很可能準確度急劇下降。最后,建立一個神經網絡需要大量的數據和長時間的訓練。
四、利用其他數據挖掘技術識別財務報表舞弊的方法
(一)粗糙集判別法
李政等(2006)利用非線性統計方法——粗糙集來識別舞弊公司,粗糙集對歷史數據的分布也沒有嚴格要求,無需提供問題所需處理的數據集合外的任何先驗信息,比較客觀地描述現實問題的不確定性,同時由所得出的規則可讀性強。但粗集的數學基礎是集合論,難以直接處理連續的屬性。而現實信息表中連續屬性是普遍存在的。因此連續屬性的離散化是制約粗集理論實用化的難點。非舞弊的回判正確率為97.8%,舞弊的回判正確率為66%;非舞弊的預測正確率為98.1%,舞弊的預測正確率為68%。
(二)奔福德判別法
Nigrini是較早將Benford法則應用到舞弊檢驗中的人。他提出滿足三個條件下的數據可以使用該法則進行分析。朱文明等(2007)運用該判別法幫助我們發現大量數據(或數字)的異常。在雇員舞弊、非上市公司等單位的舞弊識別中運用較多。
[1]陳安,陳寧,周龍驤.數據挖掘技術及應用[M].北京:科學出版社,2006:1-20.
[2]陳亮,王炫.會計信息欺詐經驗分析及識別模型[J].證券市場導報,2003,(8):52-79.
[3]毛道維,朱敏.企業信用狀況的財務判斷方法和模型——基于上市公司財務報告舞弊的實證研究[J].四川大學學報(哲學社會科學版),2006,(3):51-57.
[4]方軍雄.我國上市公司財務欺詐鑒別的實證研究[J].上市公司,2003,(4):40-45.
[5]李延喜、高銳、包世澤、姚宏.基于貝葉斯判別的中國上市公司利潤操縱識別模型研究[J].預測,2007,26(3):56-60.
[6]程永文.聚類分析在識別財務欺詐中的應用[J].合肥工業大學學報(自然科學版),2006,29(10):1316-1319.
[7]陳國欣,呂占甲,何峰.財務報告舞弊識別的實證研究——基于中國上市公司經驗數據[J],審計研究,2007,(3):88-93.
[8]陳收,楊芳,劉瑞.上市公司財務欺詐識別模型及其應用[J].統計與決策(理論版),2007,(3):100-101.
[9]婁權.我國上市公司財務報告舞弊行為之經驗研究[J].證券市場導報,2003,(10):8-12.
[10]趙英林,陳素華.基于因子分析的會計舞弊識別模型[J].山東財政學院學報,2007,(6):57-60.
[11]梅國平,陳孝新,毛小兵.基于主成分分析的企業會計信息失真預測模型[J].當代財經,2006,(2):119-124.
[12]蔡志岳,吳世農.基于公司治理的信息披露舞弊預警研究[J].管理科學,2006,19(4):79-90.
[13]梁杰,位金亮,扎彥春.基于神經網絡的會計舞弊混合識別模型研究[J].統計與決策,2006,(2):152-153.
[14]劉君,王理平.基于概率神經網絡的財務舞弊識別模型[J].哈爾濱商業大學學報,2006,(3):102-105.
[15]譙虹、賀昌政.我國上市公司虛假財務報告的GMDH識別模型[J].軟科學,2007,21(1):45-48.
[16]李政、張文修、鐘永紅.我國上市公司信息披露違規預警模型的缺陷及修正 [J].當代經濟科學,2006,28(2):104-128.
[17]朱文明、王昊、陳偉.基于Benford法則的舞弊監測方法研究[J].數理統計與管理,2007,26(1):41-46.
[18]Brian Patrick Green,Jae Hwa Choi,Assessing the Risk of Management Fraud Through Neural Network Technology,Auditing:A Journal of Practice and Theory,1997,16,(1):14-28.
[19]Fanning,Kurt M.,Cogger,Kenneth O.,Neural Network Detection of Management Fraud Using Published Financial Data,Intelligent Systems in Accounting,Finance and Management,1998,7(1).
[20]Jerry W.Lin,Mark I.Hwang,Jack D.Becker,A Fuzzy Neural Network for Assessing the Risk of Fraudulent Financial Reporting, Managerial Auditing Journal,2003,18(8).
[21]Messod D.Beneish,The Detection of Earnings Manipulation,Financial Analysts Journal,1999,24-36.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代經濟信息(2020年34期)2020-06-08 06:02:42
數學物理學報(2020年2期)2020-06-02 11:29:24
遼寧經濟(2017年5期)2017-07-12 09:39:47
光學精密工程(2016年6期)2016-11-07 09:07:19
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:09
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
