基于元學習和輕量化注意力機制的小樣本圖像檢索方法
2025-03-04 00:00:00宋阿隆崔學榮
物聯網技術 2025年5期
摘 要:圖像檢索算法在化工廠安全防護中起著重要作用,但是部分化工廠圖像檢索任務由于其場景特殊,缺乏標記樣本,圖像檢索精度較低。為解決上述問題,提出基于元學習和輕量化注意力機制的小樣本圖像檢索方法,基于元學習思想構建小樣本圖像檢索框架,使用深度可分離卷積提取圖像特征時能夠降低網絡復雜度;為增強網絡的特征提取能力,在深度可分離卷積中引入注意力模塊,構建輕量化注意力機制的特征提取網絡。試驗結果表明,采用該方法進行圖像檢索時的mAP是65.41%,參數量是2.13 MB,計算量是5.98 GFLOPs;與其他網絡相比,降低了參數量和計算量,提高了檢索精度。
關鍵詞:圖像檢索;小樣本;元學習;深度可分離卷積;注意力機制;輕量化
中圖分類號:TP183 文獻標識碼:A 文章編號:2095-1302(2025)05-00-04
0 引 言
與一般的圖像檢索場景[1]相比,化工廠的圖像檢索任務場景比較特殊,受安全性和隱私性限制,部分圖像檢索任務缺少訓練樣本,此時傳統的圖像檢索算法的檢索精度較低。因此,亟需基于少量圖像構建泛化能力強的圖像檢索模型。
目前,主流的小樣本[2]問題解決方法是元學習(Meta-Learning)[3],元學習方法模型可從不同的子任務中學習面對一個新任務時如何較好地進行泛化。與模型無關[4]的元學習(Model-Agnostic Meta-Learning, MAML)方法是其中重要的一種,其核心思想是使模型能夠在一系列任務上學習,快速、有效地適應新任務。
將元學習和度量學習(Metric Learning)[5]相結合是針對元學習方法進行研究的主流方向之一。文獻[6]提出了關系網絡(Relation Network),對輸入的關系進行建模,通過學習樣本之間的關系進行圖像處理。文獻[7]提到的原型網絡(Prototypical Network)是通過學習每個類別的原型向量,將輸入樣本映射到這些原型向量的空間中,再通過最接近的原型進行圖像匹配。
上述元學習方法均面向的是圖像分類任務,對于圖像檢索問題,情況有所不同。圖像檢索是在一個圖像數據庫中根據查詢圖像找到相似的圖像,這種任務不同于圖像分類任務,因為它不需要識別圖像的類別,只需要在圖像集合中尋找與查詢圖像相似的圖像。上述元學習方法對樣本質量要求高,且要求模型不能太復雜。基于上述原因,提出一種基于元學習和輕量化注意力機制的小樣本圖像檢索方法MS-LCAM。該方法通過構建小樣本圖像檢索框架和輕量化特征提取網絡,有效地提高小樣本圖像檢索的精度。
1 MAML算法概述
1.1 MAML算法原理
元學習與傳統的深度學習思想不同,傳統的深度學習需要大量的訓練數據,從而模擬該任務的模型參數,而元學習是從不同的任務中學習經驗與知識,做到“學會學習”。元學習分為元訓練和元測試兩個階段,元學習問題一般包含兩個數據集:目標數據集Ds和輔助數據集Dh,Ds內僅含有少量的帶標記目標樣本,Dh數據集內包含足夠多的帶有標簽的樣本,可以根據目標數據集制作。在元訓練階段,每次會在輔助數據集Dh中采樣得到不同子任務,在每個子任務中,從輔助數據集中選擇出N個類,然后從N個類中選取K個樣本構成了支持集Support Set,查詢集Query Set會在N個類中的剩余樣本數據中采樣得到,這種任務被稱為N-way K-shot任務[8]。在元學習訓練階段,使用構建的子任務訓練模型,學習經驗與知識。在元學習測試階段,使用目標數據集Ds提供的帶標簽的數據與元訓練階段學到的知識對網絡進行微調,可以在新任務上迅速學習和適應。
1.2 MAML算法缺點
MAML是一種元學習框架,可以幫助模型在小樣本情況下快速適應新任務。然而,MAML并不是設計用于解決小樣本圖像檢索任務的框架,在解決小樣本圖像檢索任務時,需對MAML框架進行優化。
在MAML框架下,對模型要求嚴格,要求模型不能太復雜。在每個子任務的訓練樣本數量很少的情況下,如果模型過于復雜,可能會在任務訓練階段學習到任務特定的噪聲,而不是泛化到新任務的規律。
2 MAML框架改進
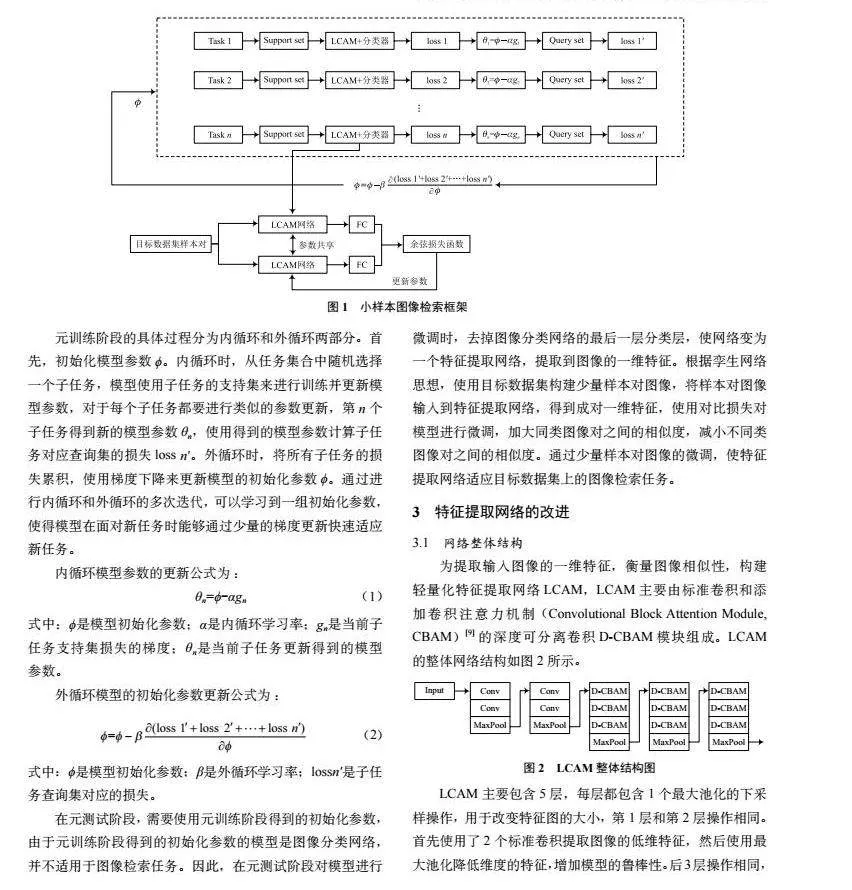
對MAML框架進行改進,使其適用于小樣本圖像檢索任務,得到小樣本圖像檢索框架MS。MS分為2個階段:第1個階段是元訓練階段,根據MAML思想在輔助數據集上劃分小樣本圖像分類子任務,訓練出圖像分類網絡;第2個階段是元測試階段,在這個階段會刪除元訓練階段的圖像分類網絡的最后一層分類層,保留其他層作為元測試階段的特征體提取網絡,在元測試階段對特征提取網絡進行微調,使其提取的特征更適用于圖像檢索任務。MS框架如圖1所示。
元訓練階段的具體過程分為內循環和外循環兩部分。首先,初始化模型參數?。內循環時,從任務集合中隨機選擇一個子任務,模型使用子任務的支持集來進行訓練并更新模型參數,對于每個子任務都要進行類似的參數更新,第n個子任務得到新的模型參數θn,使用得到的模型參數計算子任務對應查詢集的損失loss n′。外循環時,將所有子任務的損失累積,使用梯度下降來更新模型的初始化參數?。通過進行內循環和外循環的多次迭代,可以學習到一組初始化參數,使得模型在面對新任務時能夠通過少量的梯度更新快速適應新任務。
在元測試階段,需要使用元訓練階段得到的初始化參數,由于元訓練階段得到的初始化參數的模型是圖像分類網絡,并不適用于圖像檢索任務。因此,在元測試階段對模型進行微調時,去掉圖像分類網絡的最后一層分類層,使網絡變為一個特征提取網絡,提取到圖像的一維特征。根據孿生網絡思想,使用目標數據集構建少量樣本對圖像,將樣本對圖像輸入到特征提取網絡,得到成對一維特征,使用對比損失對模型進行微調,加大同類圖像對之間的相似度,減小不同類圖像對之間的相似度。通過少量樣本對圖像的微調,使特征提取網絡適應目標數據集上的圖像檢索任務。
3 特征提取網絡的改進
3.1 網絡整體結構
為提取輸入圖像的一維特征,衡量圖像相似性,構建輕量化特征提取網絡LCAM,LCAM主要由標準卷積和添加卷積注意力機制(Convolutional Block Attention Module, CBAM)[9]的深度可分離卷積D-CBAM模塊組成。LCAM的整體網絡結構如圖2所示。
LCAM主要包含5層,每層都包含1個最大池化的下采樣操作,用于改變特征圖的大小,第1層和第2層操作相同。首先使用了2個標準卷積提取圖像的低維特征,然后使用最大池化降低維度的特征,增加模型的魯棒性。后3層操作相同,使用3個相同的D-CBAM模塊提取圖像的高維特征,然后經過最大池化降低維度特征,減輕模型的過擬合風險并保留主要特征。經過5層操作后,特征進入全連接層輸出圖像一維特征。LCAM同時兼備深度可分離卷積和CBAM的優點,使得網絡更加輕量、高效。
3.2 輕量化特征提取模塊
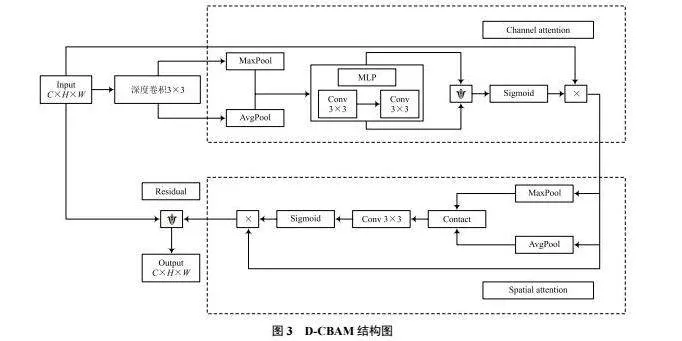
使用深度可分離卷積提取特征時,網絡復雜度雖然下降,但特征提取能力也隨之下降。為增強網絡判別性特征的提取能力,在特征提取網絡中使用CBAM注意力模塊。構建了輕量化注意力特征提取模塊D-CBAM,如圖3所示。
對于大小是C×H×W的輸入特征,D-CBAM模塊首先進行深度卷積,沿通道將特征分為C個,每個特征的大小都是1×H×W,對C個子特征分別進行標準卷積,提取圖像特征。深度卷積通過多個卷積層逐層堆疊,可以逐漸學習到輸入數據的層次化特征,捕獲輸入數據的局部和全局特征。
將深度卷積的結果經過CBAM注意力模塊,CBAM模塊能夠自適應地學習圖像中不同區域的通道注意力和空間注意力,有助于提取更具區分性的特征,強化關鍵信息,增強模型對圖像中重要特征的關注,從而提高圖像檢索性能。
在CBAM后使用一個1×1逐點卷積,對特征進行降維,改變特征的通道數,并且對不同位置上的特征進行信息整合。為了防止網絡退化和梯度消失,在D-CBAM模塊上添加了殘差操作,將D-CBAM的輸入與逐點卷積之后的結果相加,作為整個模塊的輸出。
4 實驗及結果分析
4.1 實驗數據和評價指標
采集化工廠圖像數據構建目標數據集(Target Dataset, TD),將其應用于元測試階段,以此評價本文提出的方法,TD共有5個類別,每個類別包含50張圖像。同時,從其他公開數據集上選取與目標數據集TD相似的數據構建輔助數據集(Auxiliary Dataset for Chemical Plants, ADCP),ADCP共由16個類別組成,每個類別包含100張圖像。
實驗使用平均精度均值(mean Average Precision, mAP)評價算法性能。精度表示前n個結果中有多少是同一類別的,平均精度是不同召回率上的平均值,mAP是對所有平均精度進行平均的結果。將mAP作為綜合性評價指標,能夠更全面準確地評估模型。
4.2 實驗設置
本文方法基于Pytorch深度學習框架實現,在元訓練階段,子任務通過5-way和1-shot的元學習思想對ADCP數據集進行數據劃分,每個子任務中含有5個支持集和5個查詢集,訓練任務每代有24個子任務,使用Adam優化算法[10],內部學習率為0.04,外部學習率為0.001,輸入圖像大小為224×224×3。在元測試階段,根據孿生網絡思想對TD數據集進行小樣本圖像檢索任務劃分,輸入成對圖像,將輸出成對特征的余弦相似度作為損失函數,使用SGD優化算法[11]對模型進行微調。
4.3 實驗結果及分析
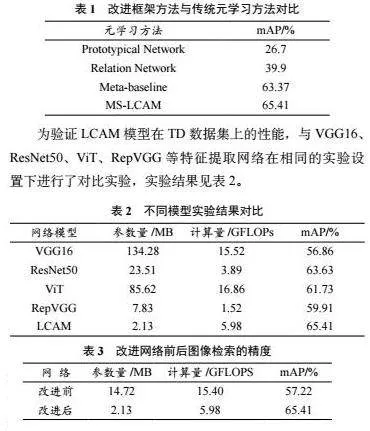
為了驗證對MAML框架的改進是否有利于小樣本圖像檢索任務,將其與其他元學習方法進行了對比實驗。具體而言,其他方法在元訓練和元測試階段均以圖像分類任務為目標進行訓練和微調,獲得圖像分類模型后,直接使用其全連接層輸出作為圖像的一維特征表示。在此基礎上,本文將基于此方法的圖像檢索結果與所提方法進行了對比分析,結果見表1。
相較于直接使用圖像分類模型的全連接層作為圖像特征,本文提出的方法在TD上的圖像檢索準確率最高,mAP達到了65.41%。相較于性能較好的Meta-baseline,本文方法的mAP提高了2.04個百分點。Prototypical Network和Relation Network方法的mAP很低,不適用于小樣本圖像檢索任務。由此驗證了MS-LCAM算法在小樣本圖像檢索任務中的有效性。
由表2可知,LCAM網絡在小樣本圖像檢索任務中取得了最高的mAP,在TD數據集上達到65.41%。相較于VGG16、ViT,LCAM網絡的參數量和計算量明顯降低,檢索性能反而更高。與RepVGG相比,盡管RepVGG計算量較低,但是它的參數量卻是LCAM的3.68倍,且RepVGG的mAP比LCAM低了5.5個百分點。ResNet50的計算量較低,同時圖像檢索性能只比LCAM模型低了1.78個百分點,然而ResNet50的參數量卻是LCAM的11倍。總體而言,LCAM模型不僅在性能上有顯著優勢,而且在參數和計算效率上相對較優。
為了驗證文中所提出的網絡改進策略對小樣本圖像檢索性能的影響,在網絡改進前后進行了圖像檢索實驗對比,結果見表3。改進后網絡的參數量降低12.59 MB,計算量降低9.42 GFLOPs,mAP提高了8.19個百分點,證明了改進模型的有效性,在小樣本圖像檢索任務中使用輕量化網絡可以取得更好的檢索結果。
5 結 語
針對化工廠圖像檢索任務中樣本數據缺乏的問題,提出基于元學習和輕量化注意力機制的小樣本圖像檢索方法。基于MAML和孿生網絡思想構建了小樣本圖像檢索框架MS,同時構建了輕量化注意力機制的特征提取網絡LCAM,在深度可分離卷積中加入CBAM模塊,構建了D-CBAM模塊,降低了網絡復雜度并提高了其在小樣本情況下的特征提取能力。實驗通過構建的輔助數據集ADCP進行訓練,在采集的化工廠小樣本數據集TD上進行驗證。結果表明,相比于現有的模型和元學習方法,本文方法擁有更高的mAP,達到65.41%,為小樣本圖像檢索提供了一個有效的方法。下一步的研究將考慮設計一種損失函數,將評價指標mAP直接應用于模型訓練過程,以提高圖像檢索的性能。
參考文獻
[1] 楊慧,施水才.基于內容的圖像檢索技術研究綜述[J].軟件導刊,2023,22(4):229-244.
[2] ZHANG D, PU H, LI F, et al. Few shot object detection via a generalized feature extraction net [J]. Journal of internet technology, 2023, 24(2): 305-312.
[3] 李凡長,劉洋,吳鵬翔,等.元學習研究綜述[J].計算機學報,2021,44(2):422-446.
[4] FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks [C]// Proceedings of the 34th International Conference on Machine Learning. Sydney, NSW, Australia: JMLR.org, 2017: 1126-1135.
[5] HU J, LU J, TAN Y P, et al. Deep transfer metric learning [J]. IEEE transactions on image processing, 2016, 25(12): 5576-5588.
[6] SUNG F, YANG Y, ZHANG L, et al. Learning to compare: Relation network for few-shot learning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 1199-1208.
[7] SNELL J, SWERSKY K, ZEMEL R S. Prototypical networks for few-shot learning [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, California, USA: Curran Associates Inc, 2017: 4080-4090.
[8] 王圣杰,王鐸,梁秋金,等.小樣本學習綜述[J].空間控制技術與應用,2023,49(5):1-10.
[9] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision (ECCV). Springer, Cham, 2018.
[10] LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [C]// Proceedings of the European International Conference on Learning Representations. [S.l.]: [s.n.], 2017.
[11] LU F. An overview of improved gradient descent algorithms for DNN training within significant revolutions of training frameworks [C]// 2021 2nd International Conference on Computing and Data Science (CDS). Stanford, CA, USA: IEEE, 2021: 181-186.
