面向兵棋游戲的多層級(jí)智能體架構(gòu)
2025-02-09 00:00:00余曉晗袁鐸姚昌華
指揮控制與仿真 2025年1期





摘 要:兵棋游戲的復(fù)雜性,增加了單一技術(shù)構(gòu)建的智能體,在兼顧粗粒度策略調(diào)整和細(xì)粒度行動(dòng)控制方面的難度,限制了智能體效能。為此提出了面向兵棋的“意圖-任務(wù)-行動(dòng)”多層級(jí)智能體架構(gòu),旨在為兵棋游戲提供一種能夠整合多種技術(shù)優(yōu)長(zhǎng)的智能體建模技術(shù)。該架構(gòu)通過自上而下的分解傳遞機(jī)制,將作戰(zhàn)策略逐步分解、轉(zhuǎn)化為可執(zhí)行的任務(wù)和動(dòng)作。使用有限狀態(tài)機(jī)、聯(lián)盟博弈和行為樹等技術(shù)分別實(shí)現(xiàn)了智能體架構(gòu)的各層級(jí)架構(gòu)。當(dāng)前智能體適用范圍嚴(yán)格限定于陸戰(zhàn)戰(zhàn)斗環(huán)境。最后在兵棋平臺(tái)上與多個(gè)基準(zhǔn)AI進(jìn)行多輪次對(duì)抗實(shí)驗(yàn),驗(yàn)證了該架構(gòu)的可行性和有效性。
關(guān)鍵詞:兵棋游戲;智能體;多層級(jí);有限狀態(tài)機(jī);聯(lián)盟博弈;行為樹
中圖分類號(hào):TP18 文獻(xiàn)標(biāo)志碼:A DOI:10.3969/j.issn.1673-3819.2025.01.009
Multi-level agent architecture for war games
YU Xiaohan1, YUAN Duo1, YAO Changhua2
(1. Army Engineering University, Nanjing 210001;
2. Nanjing University of Information Science and Technology, Nanjing 210044, China)
Abstract:The complexity of war games poses challenges for single-technique-built agents, as it requires balancing between coarse-grained strategic adjustments and fine-grained action control, thus limiting agent performance. To address this, this paper proposes a multi-level agent architecture for military strategy games based on the \"Intent-Task-Action\" framework, aiming to integrate various technical strengths for intelligent agent modeling in these games. Through a top-down decomposition and propagation mechanism, this architecture progressively breaks down combat strategies into executable tasks and actions. Techniques such as Finite State Machines, Coalition Games, and Behavior Tree are employed to implement the different levels of the agent architecture. The application scope of the realized agent is preliminarily defined as the tactical level scenario of the land combat unit. Finally, through multi-round adversarial experiments with various benchmark AI on a war gaming platform, the feasibility and effectiveness of the proposed architecture are validated.
Key words:war games; agent; multilevel; finite state machines; coalition games; behavior tree
兵棋游戲作為一款軍事訓(xùn)練和決策模擬工具,已經(jīng)成為模擬戰(zhàn)爭(zhēng)的重要手段,開發(fā)兵棋智能體成為人工智能研究的一個(gè)重要方向[1-4]。
為了更真實(shí)模擬戰(zhàn)爭(zhēng),兵棋游戲越發(fā)復(fù)雜龐大,涉及算子的類型越發(fā)多樣,行動(dòng)越發(fā)細(xì)致,智能體的開發(fā)面臨著巨大策略空間和超長(zhǎng)行動(dòng)序列,單一的智能體技術(shù)很難兼顧總體局勢(shì)把控與精確行動(dòng)控制。諸如有限狀態(tài)機(jī)的智能體方法[5-8],能夠建模專家知識(shí),實(shí)現(xiàn)作戰(zhàn)策略的結(jié)構(gòu)化表示,善于在局勢(shì)變化中產(chǎn)生優(yōu)秀策略,但這類方法難以在可控的復(fù)雜程度下細(xì)化到行動(dòng)控制層面。近年來流行的深度強(qiáng)化學(xué)習(xí)智能體建模方法[9-10],雖非常善于敏銳察覺態(tài)勢(shì)變化,為算子提供最佳作戰(zhàn)行動(dòng),但兵棋的超長(zhǎng)行動(dòng)序列加大了深度強(qiáng)化學(xué)習(xí)訓(xùn)練難度,限制了算子行動(dòng)的遠(yuǎn)期作用。單一智能體技術(shù)的不足,在越是復(fù)雜的兵棋游戲中,體現(xiàn)越是明顯。將不同優(yōu)勢(shì)的智能體技術(shù)整合在一起是解決該問題的一種思路。
鑒于此,本文提出了“意圖-任務(wù)-行動(dòng)”的三層級(jí)智能體架構(gòu),該架構(gòu)可整合有限狀態(tài)機(jī)、聯(lián)盟博弈、行為樹等技術(shù),構(gòu)建多技術(shù)融合的智能體:有限狀態(tài)機(jī)建模上層作戰(zhàn)意圖,用于智能體調(diào)整作戰(zhàn)策略;聯(lián)盟博弈建模作戰(zhàn)任務(wù)的分配,用于促成算子間的協(xié)同與協(xié)作;行為樹建模算子行動(dòng)方式,用于根據(jù)態(tài)勢(shì)變化精準(zhǔn)控制算子行為。上述方法所實(shí)現(xiàn)智能體在未經(jīng)更廣泛場(chǎng)景驗(yàn)證之前,其應(yīng)用范圍初步界定于陸戰(zhàn)戰(zhàn)斗環(huán)境,且主要聚焦于分隊(duì)?wèi)?zhàn)術(shù)層級(jí)的場(chǎng)景。為驗(yàn)證本文提出架構(gòu)的實(shí)用性,在廟算兵棋平臺(tái)上的分隊(duì)級(jí)想定中進(jìn)行了仿真實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果表明,本文架構(gòu)相較單一智能體技術(shù)有較大優(yōu)勢(shì)。
1 多層級(jí)智能體架構(gòu)設(shè)計(jì)
針對(duì)上述問題,提出面向兵棋游戲的“意圖-任務(wù)-行動(dòng)”多層級(jí)智能體架構(gòu)。
1.1 整體架構(gòu)設(shè)計(jì)
在面對(duì)復(fù)雜的兵棋游戲想定時(shí),做出有效決策需要考慮多種因素。將智能體分層,不同層級(jí)分別履行不同的職責(zé),將復(fù)雜、模糊的決策問題分解為許多規(guī)模較小、界線清晰的子問題來處理,使得復(fù)雜的決策問題變得易于理解和解決。最終,決策由上到下,由粗到細(xì),完成由總體策略到單個(gè)算子行為的決策過程。如圖1所示,本文設(shè)計(jì)的智能體架構(gòu)分為三層:作戰(zhàn)意圖層、任務(wù)分配層和算子行動(dòng)層。
在三層架構(gòu)中,作戰(zhàn)意圖層負(fù)責(zé)產(chǎn)生我方總體策略,作戰(zhàn)意圖層分析判斷戰(zhàn)場(chǎng)整體態(tài)勢(shì)并制定作戰(zhàn)意圖,并將其傳遞給任務(wù)分配層進(jìn)行進(jìn)一步細(xì)化。任務(wù)分配層根據(jù)作戰(zhàn)意圖層的策略,通過戰(zhàn)場(chǎng)態(tài)勢(shì),為算子分配目標(biāo)和任務(wù),實(shí)現(xiàn)有組織、有協(xié)作的進(jìn)攻或防御。算子行動(dòng)層在接收任務(wù)后,生成符合態(tài)勢(shì)的具體行動(dòng),生成的算子行動(dòng)輸入兵棋推演引擎中,推進(jìn)戰(zhàn)場(chǎng)態(tài)勢(shì)變化。
三層架構(gòu)的多層分工將決策問題拆分成多個(gè)子問題,更加有助于解決問題。由于每一層都是相對(duì)獨(dú)立的模塊,單個(gè)層級(jí)的錯(cuò)誤或異常不會(huì)影響其他層,從而降低了整個(gè)系統(tǒng)出現(xiàn)故障的風(fēng)險(xiǎn)。這樣做還有助于提高智能體靈活性,各層級(jí)都可以根據(jù)需要選用合適的技術(shù),在某個(gè)層級(jí)所采用技術(shù)達(dá)不到預(yù)期效果時(shí),可在無(wú)需調(diào)整其他層級(jí)的基礎(chǔ)上,針對(duì)性地進(jìn)行修改或替換。
1.2 作戰(zhàn)意圖層
作戰(zhàn)意圖層聚焦于總體決策,在對(duì)戰(zhàn)場(chǎng)的整體態(tài)勢(shì)進(jìn)行判斷后決定下一步我方的總體策略。解決總體上的“做什么”問題。
作戰(zhàn)意圖層首先要進(jìn)行的是對(duì)戰(zhàn)場(chǎng)整體態(tài)勢(shì)的判斷,通過收集、分析戰(zhàn)場(chǎng)數(shù)據(jù),確定當(dāng)下戰(zhàn)場(chǎng)的各種關(guān)鍵因素的狀態(tài)和趨勢(shì)。具體實(shí)現(xiàn)中,可根據(jù)推演引擎發(fā)送的地形、我方算子狀態(tài)和敵方算子狀態(tài)等信息,分析得出敵我雙方目前實(shí)力對(duì)比、主要目標(biāo)情況以及上一個(gè)任務(wù)的完成情況等。
在完成態(tài)勢(shì)分析后,根據(jù)態(tài)勢(shì)分析結(jié)果進(jìn)行決策以產(chǎn)生當(dāng)前我方策略。目前決策的方式基本是基于專家知識(shí)的,即結(jié)構(gòu)化地表示人類專家知識(shí),基于此制定符合當(dāng)前態(tài)勢(shì)的策略。下節(jié)介紹了使用有限狀態(tài)機(jī)結(jié)構(gòu)化表示專家知識(shí)并從中產(chǎn)生策略的方法。
最后作戰(zhàn)意圖層將產(chǎn)生的策略傳入任務(wù)分配層,進(jìn)行下一步作業(yè)。
1.3 任務(wù)分配層
任務(wù)分配層的主要目標(biāo)是根據(jù)上層下達(dá)的策略制定作戰(zhàn)任務(wù),為每個(gè)算子合理分配任務(wù),解決“怎么做”“誰(shuí)來做”的問題。
任務(wù)分配層首先根據(jù)上層下達(dá)的作戰(zhàn)策略,結(jié)合當(dāng)前態(tài)勢(shì)明確具體任務(wù)劃分和任務(wù)目標(biāo)。在對(duì)任務(wù)進(jìn)行詳細(xì)分析的基礎(chǔ)上,包括分析任務(wù)的難度、所需的兵力、預(yù)計(jì)的完成時(shí)間等,將任務(wù)分配給具有相應(yīng)能力的算子,期間還要充分考慮算子之間的協(xié)作配合,提高完成任務(wù)的可能性。在推演進(jìn)行中,還要能夠根據(jù)態(tài)勢(shì)變化,動(dòng)態(tài)調(diào)整任務(wù)分配方案,增強(qiáng)智能體的應(yīng)變能力。
任務(wù)分配層的主要意義在于確保上層下達(dá)的作戰(zhàn)策略得到最優(yōu)落實(shí),充分體現(xiàn)算子特長(zhǎng),考慮多個(gè)算子執(zhí)行任務(wù)時(shí)的協(xié)同與協(xié)作,提升整體作戰(zhàn)效能。下節(jié)中使用聯(lián)盟博弈,在優(yōu)化整體作戰(zhàn)效能的基礎(chǔ)上,完成算子任務(wù)分配。
1.4 算子行動(dòng)層
算子行動(dòng)層根據(jù)具體情況計(jì)劃算子的行動(dòng),即如何根據(jù)實(shí)時(shí)戰(zhàn)場(chǎng)態(tài)勢(shì),為算子生成當(dāng)前最佳作戰(zhàn)行動(dòng),解決單個(gè)算子的“做什么”問題。
在廟算平臺(tái)的兵棋對(duì)抗中,單個(gè)算子的任務(wù)由移動(dòng)、射擊、奪控等多種行動(dòng)組合完成,在執(zhí)行這些行動(dòng)時(shí)要考慮其機(jī)動(dòng)路徑的安全性、對(duì)敵方算子的通視情況、是否在友軍算子的掩護(hù)下等因素。算子行動(dòng)層就是在盡可能多地考慮戰(zhàn)場(chǎng)影響因素后,得出當(dāng)下最佳行動(dòng),即完成算子行為控制。算子行動(dòng)層生成當(dāng)前最佳行動(dòng)后,智能體將算子行動(dòng)指令列表傳輸給兵棋游戲引擎,推動(dòng)態(tài)勢(shì)演進(jìn)。
2 架構(gòu)實(shí)現(xiàn)
上文闡述了多層級(jí)智能體架構(gòu),本節(jié)將有針對(duì)性地選用合適方法作為框架中各層級(jí)的實(shí)現(xiàn)技術(shù),并最終組合成一個(gè)可行的智能體。在架構(gòu)實(shí)現(xiàn)的過程中,也不難發(fā)現(xiàn)本文架構(gòu)的靈活性,各層級(jí)的方法都可分別替換成相同功能的其他方法。
為便于敘述,本節(jié)將在廟算陸戰(zhàn)兵棋平臺(tái)中具體闡述各層級(jí)的實(shí)現(xiàn)方法。廟算陸戰(zhàn)兵棋平臺(tái)有合理的規(guī)則、成熟的環(huán)境和生態(tài),為人們廣泛熟知,是一個(gè)理想的兵棋游戲智能體開發(fā)平臺(tái)。
2.1 基于有限狀態(tài)機(jī)的策略制定
有限狀態(tài)機(jī)(finite state machine,F(xiàn)SM) 是構(gòu)建游戲智能體的智能和行為的常用建模方法之一。它本質(zhì)上是一個(gè)由事件觸發(fā)的在有限數(shù)量個(gè)狀態(tài)之間進(jìn)行轉(zhuǎn)換的模型。它通過將復(fù)雜的智能體的決策抽象為不同的狀態(tài)以及狀態(tài)之間的轉(zhuǎn)換,讓每個(gè)狀態(tài)只需要管理自己的轉(zhuǎn)換條件,從而降低智能體決策的整體復(fù)雜度。由于其實(shí)現(xiàn)簡(jiǎn)單且邏輯結(jié)構(gòu)清晰,有限狀態(tài)機(jī)技術(shù)被廣泛應(yīng)用到動(dòng)作游戲的開發(fā)中。本文使用有限狀態(tài)機(jī)來對(duì)在戰(zhàn)場(chǎng)態(tài)勢(shì)發(fā)生變化時(shí)策略發(fā)生變化的情況進(jìn)行建模,是實(shí)現(xiàn)多層級(jí)智能體架構(gòu)中作戰(zhàn)意圖層的方法。
2.2 基于聯(lián)盟博弈的協(xié)同任務(wù)分配
聯(lián)盟博弈是一種研究參與者之間的合作行為及其對(duì)收益影響的模型。在聯(lián)盟博弈中,參與者可以形成各種聯(lián)盟,形成聯(lián)盟是為了實(shí)現(xiàn)共同的目標(biāo)或增加整體的收益。特征函數(shù)是聯(lián)盟博弈中的一個(gè)重要概念,它為每個(gè)可能的聯(lián)盟指定一個(gè)值,這個(gè)值反映了聯(lián)盟成員通過合作能夠獲得的收益。通過定義特征函數(shù),可以為聯(lián)盟的形成和擴(kuò)大提供合理參考。
使用聯(lián)盟博弈來實(shí)現(xiàn)任務(wù)分配,將每個(gè)算子視為博弈的一個(gè)參與者,算子可以自由地組成聯(lián)盟來執(zhí)行指定任務(wù)。通過設(shè)定一個(gè)特征函數(shù)來為每個(gè)可能的聯(lián)盟計(jì)算出一個(gè)效能值,該值表示該聯(lián)盟完成任務(wù)的能力。這個(gè)特征函數(shù)需要反映聯(lián)盟成員本身的能力以及協(xié)同完成任務(wù)時(shí)的增益。通過求解最大聯(lián)盟值來得到最優(yōu)任務(wù)分配方式。
本文基于效能值和協(xié)作加成值設(shè)計(jì)聯(lián)盟博弈的特征函數(shù)。聯(lián)盟中算子協(xié)同執(zhí)行任務(wù)的總體效用的計(jì)算公式為
本文在上述計(jì)算聯(lián)盟效能值的基礎(chǔ)上,采用迭代優(yōu)化的方式形成穩(wěn)定聯(lián)盟組合,從而完成對(duì)所有算子的任務(wù)分配。使用聯(lián)盟博弈實(shí)現(xiàn)算子的任務(wù)分配,將任務(wù)分配問題轉(zhuǎn)化為了優(yōu)化問題,在理論上保證了解決方案的可行性。聯(lián)盟博弈允許動(dòng)態(tài)形成和調(diào)整聯(lián)盟,這為任務(wù)分配提供了高度的靈活性,可根據(jù)戰(zhàn)場(chǎng)態(tài)勢(shì)動(dòng)態(tài)調(diào)整。聯(lián)盟博弈幫助找到每個(gè)聯(lián)盟成員的最佳貢獻(xiàn),從而提高整體性能,確保資源得到有效利用。
2.3 基于行為樹的算子行為控制
行為樹(behavior tree)是一種樹結(jié)構(gòu),執(zhí)行時(shí)會(huì)從根節(jié)點(diǎn)開始按照指定的順序遍歷,直到終結(jié)狀態(tài)。行為樹通過子節(jié)點(diǎn)控制樹的遍歷順序:通過設(shè)置子節(jié)點(diǎn)的邏輯,可以指定特定的規(guī)則控制下一個(gè)遍歷的節(jié)點(diǎn)。而行為樹的葉子節(jié)點(diǎn)可以執(zhí)行具體的操作:通過設(shè)定葉子節(jié)點(diǎn),可以執(zhí)行具體操作并返回一個(gè)狀態(tài)信息。
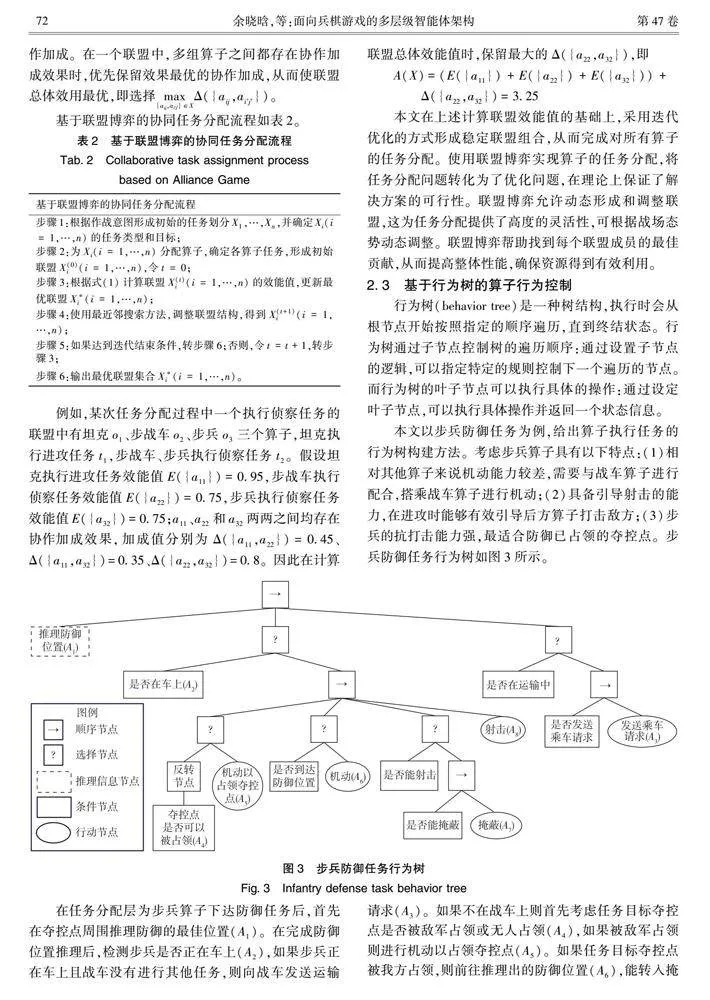
本文以步兵防御任務(wù)為例,給出算子執(zhí)行任務(wù)的行為樹構(gòu)建方法。考慮步兵算子具有以下特點(diǎn):(1)相對(duì)其他算子來說機(jī)動(dòng)能力較差,需要與戰(zhàn)車算子進(jìn)行配合,搭乘戰(zhàn)車算子進(jìn)行機(jī)動(dòng);(2)具備引導(dǎo)射擊的能力,在進(jìn)攻時(shí)能夠有效引導(dǎo)后方算子打擊敵方;(3)步兵的抗打擊能力強(qiáng),最適合防御已占領(lǐng)的奪控點(diǎn)。步兵防御任務(wù)行為樹如圖3所示。
在任務(wù)分配層為步兵算子下達(dá)防御任務(wù)后,首先在奪控點(diǎn)周圍推理防御的最佳位置(A1)。在完成防御位置推理后,檢測(cè)步兵是否正在車上(A2),如果步兵正在車上且戰(zhàn)車沒有進(jìn)行其他任務(wù),則向戰(zhàn)車發(fā)送運(yùn)輸請(qǐng)求(A3)。如果不在戰(zhàn)車上則首先考慮任務(wù)目標(biāo)奪控點(diǎn)是否被敵軍占領(lǐng)或無(wú)人占領(lǐng)(A4),如果被敵軍占領(lǐng)則進(jìn)行機(jī)動(dòng)以占領(lǐng)奪控點(diǎn)(A5)。如果任務(wù)目標(biāo)奪控點(diǎn)被我方占領(lǐng),則前往推理出的防御位置(A6),能轉(zhuǎn)入掩蔽狀態(tài)則轉(zhuǎn)入掩蔽狀態(tài)(A7),如果有敵人進(jìn)入射擊范圍或引導(dǎo)射擊范圍,則進(jìn)行射擊(A8)。
采用行為樹對(duì)算子行動(dòng)邏輯進(jìn)行抽象建模,將復(fù)雜的任務(wù)分解成多個(gè)小步驟,每個(gè)小步驟代表一個(gè)節(jié)點(diǎn),最終將所有節(jié)點(diǎn)組合成一個(gè)行為樹,自頂向下地進(jìn)行決策,實(shí)現(xiàn)了算子根據(jù)戰(zhàn)場(chǎng)情況靈活完成任務(wù)的目標(biāo)。
3 實(shí)驗(yàn)
本文的實(shí)驗(yàn)部分分為兩部分,第一部分是在兵棋游戲動(dòng)態(tài)變化的環(huán)境中,展示智能體各層級(jí)如何感知并應(yīng)對(duì)態(tài)勢(shì)的變化。第二部分將展示本文構(gòu)建智能體和其他基準(zhǔn)智能體在對(duì)抗過程中的整體表現(xiàn)。
3.1 智能體各層級(jí)效果展示
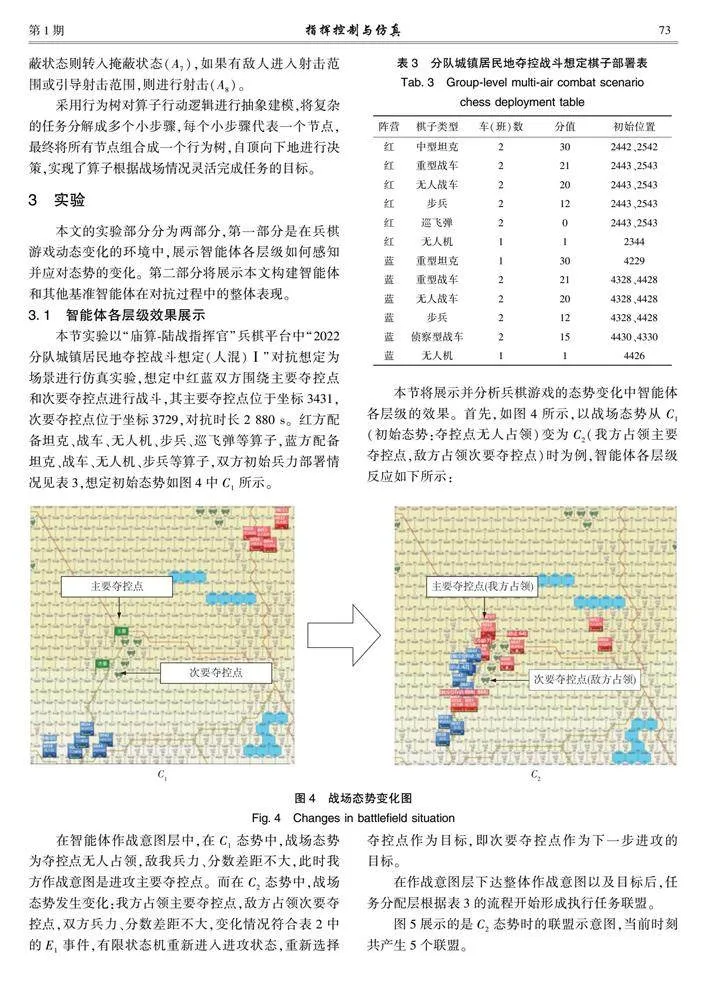
本節(jié)實(shí)驗(yàn)以“廟算-陸戰(zhàn)指揮官”兵棋平臺(tái)中“2022分隊(duì)城鎮(zhèn)居民地奪控戰(zhàn)斗想定(人混)Ⅰ”對(duì)抗想定為場(chǎng)景進(jìn)行仿真實(shí)驗(yàn),想定中紅藍(lán)雙方圍繞主要奪控點(diǎn)和次要奪控點(diǎn)進(jìn)行戰(zhàn)斗,其主要奪控點(diǎn)位于坐標(biāo)3431,次要奪控點(diǎn)位于坐標(biāo)3729,對(duì)抗時(shí)長(zhǎng)2 880 s。紅方配備坦克、戰(zhàn)車、無(wú)人機(jī)、步兵、巡飛彈等算子,藍(lán)方配備坦克、戰(zhàn)車、無(wú)人機(jī)、步兵等算子,雙方初始兵力部署情況見表3,想定初始態(tài)勢(shì)如圖4中C1所示。
本節(jié)將展示并分析兵棋游戲的態(tài)勢(shì)變化中智能體各層級(jí)的效果。首先,如圖4所示,以戰(zhàn)場(chǎng)態(tài)勢(shì)從C1(初始態(tài)勢(shì):奪控點(diǎn)無(wú)人占領(lǐng))變?yōu)镃2(我方占領(lǐng)主要奪控點(diǎn),敵方占領(lǐng)次要奪控點(diǎn))時(shí)為例,智能體各層級(jí)反應(yīng)如下所示:
在智能體作戰(zhàn)意圖層中,在C1態(tài)勢(shì)中,戰(zhàn)場(chǎng)態(tài)勢(shì)為奪控點(diǎn)無(wú)人占領(lǐng),敵我兵力、分?jǐn)?shù)差距不大,此時(shí)我方作戰(zhàn)意圖是進(jìn)攻主要奪控點(diǎn)。而在C2態(tài)勢(shì)中,戰(zhàn)場(chǎng)態(tài)勢(shì)發(fā)生變化:我方占領(lǐng)主要奪控點(diǎn),敵方占領(lǐng)次要奪控點(diǎn),雙方兵力、分?jǐn)?shù)差距不大,變化情況符合表2中的E1事件,有限狀態(tài)機(jī)重新進(jìn)入進(jìn)攻狀態(tài),重新選擇奪控點(diǎn)作為目標(biāo),即次要奪控點(diǎn)作為下一步進(jìn)攻的目標(biāo)。
在作戰(zhàn)意圖層下達(dá)整體作戰(zhàn)意圖以及目標(biāo)后,任務(wù)分配層根據(jù)表3的流程開始形成執(zhí)行任務(wù)聯(lián)盟。
圖5展示的是C2態(tài)勢(shì)時(shí)的聯(lián)盟示意圖,當(dāng)前時(shí)刻共產(chǎn)生5個(gè)聯(lián)盟。
針對(duì)目標(biāo)點(diǎn)位3729形成以下聯(lián)盟:
(1) 進(jìn)攻聯(lián)盟1。聯(lián)盟成員包括重型坦克算子(0058)執(zhí)行進(jìn)攻任務(wù)、重型戰(zhàn)車算子(0048)執(zhí)行進(jìn)攻任務(wù)、步兵算子(0050)執(zhí)行進(jìn)攻任務(wù);
(2) 進(jìn)攻聯(lián)盟2。聯(lián)盟成員包括無(wú)人戰(zhàn)車算子(0053)執(zhí)行進(jìn)攻任務(wù)、無(wú)人戰(zhàn)車算子(0054)執(zhí)行偵察任務(wù);
(3) 偵察聯(lián)盟1。聯(lián)盟成員包括巡飛彈算子(0051)執(zhí)行偵察任務(wù)、巡飛彈算子(0052)執(zhí)行偵察任務(wù)。
針對(duì)目標(biāo)點(diǎn)位3431形成以下聯(lián)盟:
(1) 防御聯(lián)盟1。聯(lián)盟成員包括重型戰(zhàn)車算子(0047)執(zhí)行防御任務(wù)、步兵算子(0049)執(zhí)行防御任務(wù);
(2) 偵察聯(lián)盟2。聯(lián)盟成員包括無(wú)人機(jī)算子(0032)執(zhí)行偵察任務(wù)。
在完成任務(wù)分配后,每個(gè)算子的任務(wù)以及任務(wù)目標(biāo)點(diǎn)都被下達(dá)到算子行動(dòng)層,算子行動(dòng)層開始根據(jù)任務(wù)和當(dāng)前態(tài)勢(shì)計(jì)算算子下一步行動(dòng)。以步兵算子(0049)執(zhí)行針對(duì)目標(biāo)點(diǎn)位3431的防御任務(wù)為例(如圖6所示),根據(jù)2.3節(jié)中的步兵防御行為樹,此時(shí)步兵根據(jù)目標(biāo)點(diǎn)位推理防御位置,選取3432作為防御位置。當(dāng)前步兵算子正在搭乘重型戰(zhàn)車算子(0047),位于3434,與目標(biāo)防御位置距離只有2格,不需要繼續(xù)運(yùn)輸,開始下車。目標(biāo)奪控點(diǎn)已經(jīng)被我方占領(lǐng),步兵算子下車后直接機(jī)動(dòng)至防御位置3432。
智能體在廟算平臺(tái)的分隊(duì)級(jí)想定“2022分隊(duì)城鎮(zhèn)居民地奪控戰(zhàn)斗想定(人混)Ⅰ”上成功運(yùn)行,表明上述方法實(shí)現(xiàn)的智能體適用于處理?yè)碛卸鄠€(gè)算子(如21個(gè)算子)和多個(gè)奪控點(diǎn)(如2個(gè)奪控點(diǎn))的復(fù)雜分隊(duì)級(jí)想定。然而,必須明確界定的是,在未在更復(fù)雜想定中進(jìn)行實(shí)驗(yàn)驗(yàn)證的情況下,當(dāng)前智能體的適用范圍嚴(yán)格限定于陸戰(zhàn)戰(zhàn)斗環(huán)境,且最高不超過分隊(duì)?wèi)?zhàn)術(shù)層級(jí)的場(chǎng)景。這一限定基于智能體所依賴的特定方法論,在未經(jīng)更廣泛場(chǎng)景驗(yàn)證前,其適用性具有明確的邊界。
3.2 智能體表現(xiàn)
進(jìn)行智能體之間的對(duì)抗比賽是評(píng)估其優(yōu)越性的一種常用方法。通過讓不同的智能體進(jìn)行對(duì)抗,觀察它們?cè)趹?zhàn)斗中的表現(xiàn),以評(píng)估它們的優(yōu)劣。本節(jié)實(shí)驗(yàn)采用了“廟算-陸戰(zhàn)指揮官”兵棋平臺(tái)中的兩個(gè)典型想定——“2022分隊(duì)城鎮(zhèn)居民地奪控戰(zhàn)斗想定(人混)Ⅰ”(簡(jiǎn)稱“想定I”)與“2022分隊(duì)城鎮(zhèn)居民地奪控戰(zhàn)斗想定(人混)II” (簡(jiǎn)稱“想定II”),以智能體對(duì)智能體的方式進(jìn)行了測(cè)試。為了實(shí)現(xiàn)對(duì)抗的多樣性,我們引入了多個(gè)平臺(tái)內(nèi)置的AI模型作為對(duì)手,包括人機(jī)混合練習(xí)AI-激進(jìn)型、人機(jī)混合練習(xí)AI-保守型、人機(jī)混合基準(zhǔn)AI-靈活型以及人機(jī)混合基準(zhǔn)AI-保守型,分別控制紅、藍(lán)方形成了八種不同的對(duì)抗方案。
在每一種仿真方案中,本文均執(zhí)行了十次獨(dú)立的重復(fù)實(shí)驗(yàn),并詳細(xì)記錄了智能體在每次對(duì)決中的勝負(fù)情況。與不同智能體對(duì)抗勝率統(tǒng)計(jì)如表4所示。
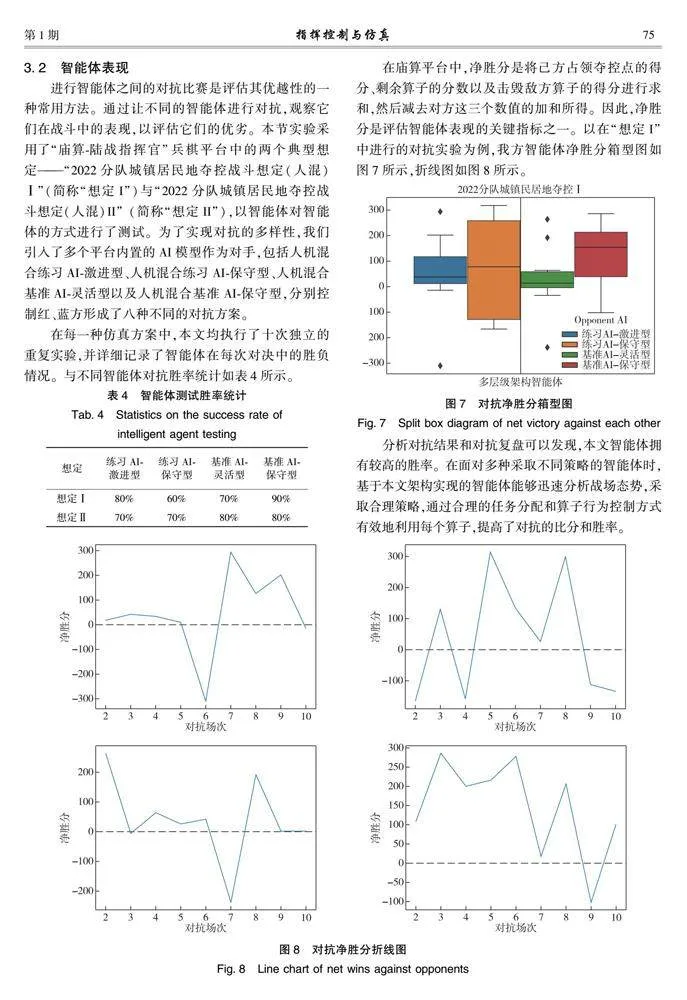
在廟算平臺(tái)中,凈勝分是將己方占領(lǐng)奪控點(diǎn)的得分、剩余算子的分?jǐn)?shù)以及擊毀敵方算子的得分進(jìn)行求和,然后減去對(duì)方這三個(gè)數(shù)值的加和所得。因此,凈勝分是評(píng)估智能體表現(xiàn)的關(guān)鍵指標(biāo)之一。以在“想定I”中進(jìn)行的對(duì)抗實(shí)驗(yàn)為例,我方智能體凈勝分箱型圖如圖7所示,折線圖如圖8所示。
分析對(duì)抗結(jié)果和對(duì)抗復(fù)盤可以發(fā)現(xiàn),本文智能體擁有較高的勝率。在面對(duì)多種采取不同策略的智能體時(shí),基于本文架構(gòu)實(shí)現(xiàn)的智能體能夠迅速分析戰(zhàn)場(chǎng)態(tài)勢(shì),采取合理策略,通過合理的任務(wù)分配和算子行為控制方式有效地利用每個(gè)算子,提高了對(duì)抗的比分和勝率。
綜上所述,實(shí)驗(yàn)證明了本文提出的面向兵棋游戲的多層級(jí)智能體架構(gòu)具有較高的實(shí)用性,與現(xiàn)有的基準(zhǔn)AI對(duì)抗具有較高的勝率。
4 結(jié)束語(yǔ)
本文提出了基于“意圖-任務(wù)-行動(dòng)”的三層智能體架構(gòu),并使用有限狀態(tài)機(jī)、聯(lián)盟博弈、行為樹等方法構(gòu)建了智能體。在實(shí)驗(yàn)中,智能體展現(xiàn)出了優(yōu)越的性能,證明了這種多元化技術(shù)整合架構(gòu)的有效性和可行性。實(shí)驗(yàn)結(jié)果揭示了智能體在復(fù)雜游戲環(huán)境中的適應(yīng)性和競(jìng)爭(zhēng)力,同時(shí)也突顯了其在策略制定和決策執(zhí)行方面的優(yōu)越性。我們的研究為兵棋游戲的AI設(shè)計(jì)提供了新的視角,展示了如何通過技術(shù)和方法的融合來克服單一技術(shù)可能遇到的局限性。此外,我們的智能體架構(gòu)為未來研究者提供了一個(gè)堅(jiān)實(shí)的基礎(chǔ),可以在此基礎(chǔ)上進(jìn)一步探索和優(yōu)化。未來的工作可以集中在更深入地理解各種技術(shù)之間的相互作用,將新技術(shù)應(yīng)用到架構(gòu)之中,以及如何在不斷變化的游戲動(dòng)態(tài)中維持和提升智能體的性能。
參考文獻(xiàn):
[1] 孫李程,馬宏賓.從兵棋推演看人工智能發(fā)展[J].軍事文摘,2024(11):66-70.SUN L C, MA H B. Development of artificial intelligence from war games[J]. Military Abstracts,2024(11):66-70.
[2] 胡曉峰, 榮明. 作戰(zhàn)決策輔助向何處去——“深綠” 計(jì)劃的啟示與思考[J]. 指揮與控制學(xué)報(bào), 2016, 2(1): 22-25.HU X F, RONG M. Where do operation decision support systems go: inspiration and thought on deep green plan[J]. Journal of Command and Control, 2016, 2(1): 22-25.
[3] 胡曉峰, 賀筱媛, 陶九陽(yáng). Alpha Go 的突破與兵棋推演的挑戰(zhàn)[J]. 科技導(dǎo)報(bào), 2017, 35(21): 49-60.HU X F, HE X Y, TAO J Y. Alpha Gos break-through and challenges of war gaming[J]. Science & Technology Review, 2017, 35(21): 49-60.
[4] 聶凱, 曾科軍, 孟慶海, 等. 人機(jī)對(duì)抗智能技術(shù)最新進(jìn)展及軍事應(yīng)用[J]. 兵器裝備工程學(xué)報(bào), 2021, 42(6): 6-11, 26.NIE K, ZENG K J, MENG Q H, et al. Recent advances in intelligent technologies of human-computer gaming and its military applications[J]. Journal of Ordnance Equipment Engineering, 2021, 42(6): 6-11, 26.
[5] SALES D O, CORREA D O, FERNANDES L C, et al. Adaptive finite state machine based visual autonomous navigation system[J]. Engineering Applications of Artificial Intelligence, 2014(29): 152-162.
[6] QUINLAN J R. Generating production rules from decision trees[C]. International Joint Conference on Artificial Intelligence, 1987(87): 304-307.
[7] NICOLAU M, PEREZ-LIEBANA D, ONEILL M, et al. Evolutionary behavior tree approaches for navigating platform games[J]. IEEE Transactions on Computational Intelligence and AI in Games, 2017, 9(3): 227-238.
[8] 尤岳, 黃昱申, 陳科. 無(wú)人潛航器交戰(zhàn)行為分層建模方法[J]. 數(shù)字海洋與水下攻防, 2023, 6(5): 622-628.YOU Y, HUANG Y S, CHEN K. A hierarchical modeling method of UUV combat actions[J]. Digital Ocean & Underwater Warfare, 2023, 6(5): 622-628.
[9] 崔文華, 李東, 唐宇波, 等. 基于深度強(qiáng)化學(xué)習(xí)的兵棋推演決策方法框架[J]. 國(guó)防科技, 2020, 41(2): 113-121.CUI W H, LI D, TANG Y B, et al. Framework of wargaming decision-making methods based on deep reinforcement learning[J]. National Defense Technology, 2020, 41(2): 113-121.
[10]VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019(575): 350-354.
(責(zé)任編輯:許韋韋)
